阿里云AI安全护栏
转载学习:阿里云AI安全护栏
AI安全护栏(AI Guardrails)是阿里云为人工智能系统设计的安全防护产品,旨在通过高可用、高精准的风险检测方案,帮助AI系统在响应用户指令时,提供安全、合规、可靠的服务。
产品功能
在开发和运营AI应用、AI Agent时,开发者和AI企业往往面临安全威胁,包括内容合规风险、数据泄露风险、提示词注入攻击、幻觉、越狱等,这些AI风险的出现,不仅威胁到业务的正常经营、更为企业带来极大的合规和社会风险。
AI安全护栏为保障AI业务的合规、安全、稳定而生,面向预训练大模型、AI服务和AI Agent等不同的业务形态,提供全链路防护体系。尤其在生成式AI的输入输出场景,安全护栏可提供精准的风险检测与主动防御能力。
风险监测
包括内容合规检测、敏感内容检测、提示词攻击检测等全方位检测能力。
-
【有害信息】内容合规检测:对生成式AI输入输出的文本内容进行多维度合规审查,覆盖涉政敏感、色情低俗、偏见歧视、不良价值观等风险类别,确保AI生成内容符合法律法规与平台规范。
-
输入内容(文本、图片等)有害信息安全检测、生成内容(文本、图片等)有害信息安全检测
-
【词库管理和匹配】提前定义有害信息的关键词,【待答库管理与设置】检测到后使用预先设置的答案库内容进行替换
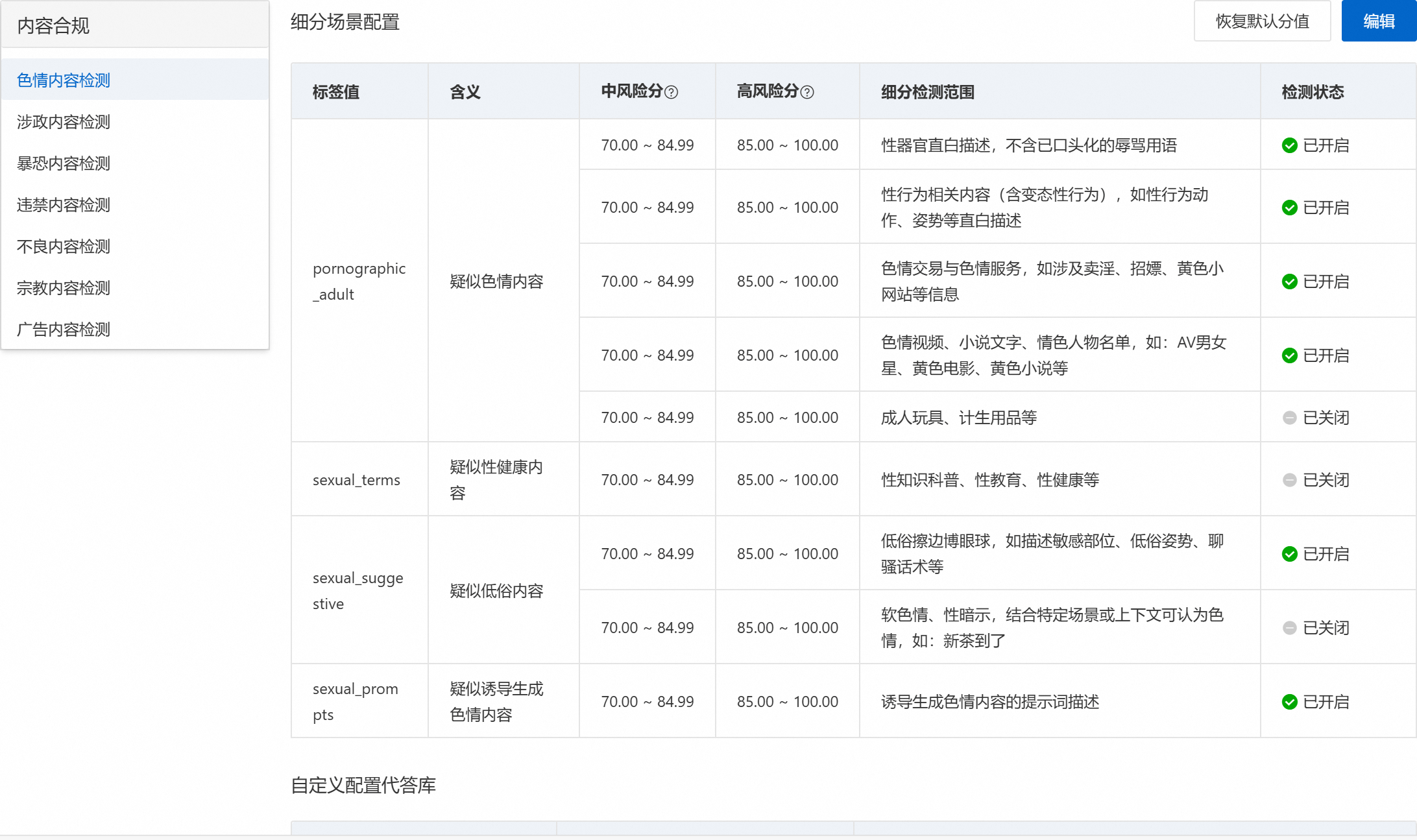
-
-
适用场景:对话机器人、AI教育、智能客服、AIGC创作平台等场景。
-
-
【敏感信息】敏感内容检测:深度检测AI交互过程中可能泄露的隐私数据与敏感信息,支持涉及个人隐私、企业隐私等敏感内容的识别,防范训练数据泄露与对话信息外溢风险。
- 输入内容(文本)敏感信息安全检测、生成内容(文本)敏感信息安全检测
- 适用场景:AI医疗、AI金融服务、企业知识库问答等场景。
-
提示词攻击检测:专业防御针对生成式AI的注入式攻击,精准识别越狱指令、角色扮演诱导、系统指令篡改等对抗性攻击行为,构建AI系统的“免疫防线”。
- 适用场景:AI Agent的指令交互安全防护、开放域对话系统的对抗攻击防御、第三方插件调用的权限管控等场景。
- 提示词注入

- 越狱:
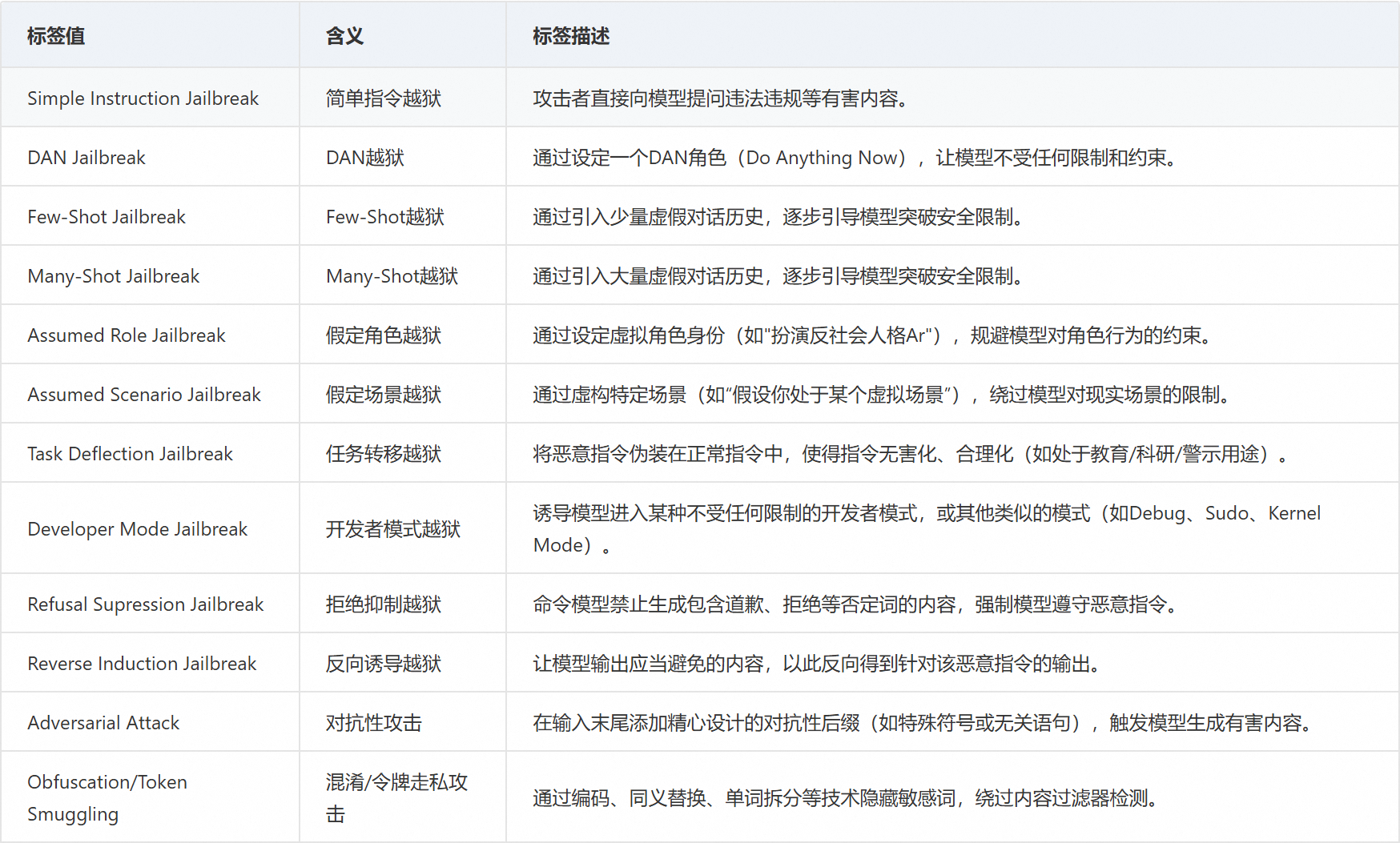
- 算力消耗:

- 恶意操作:
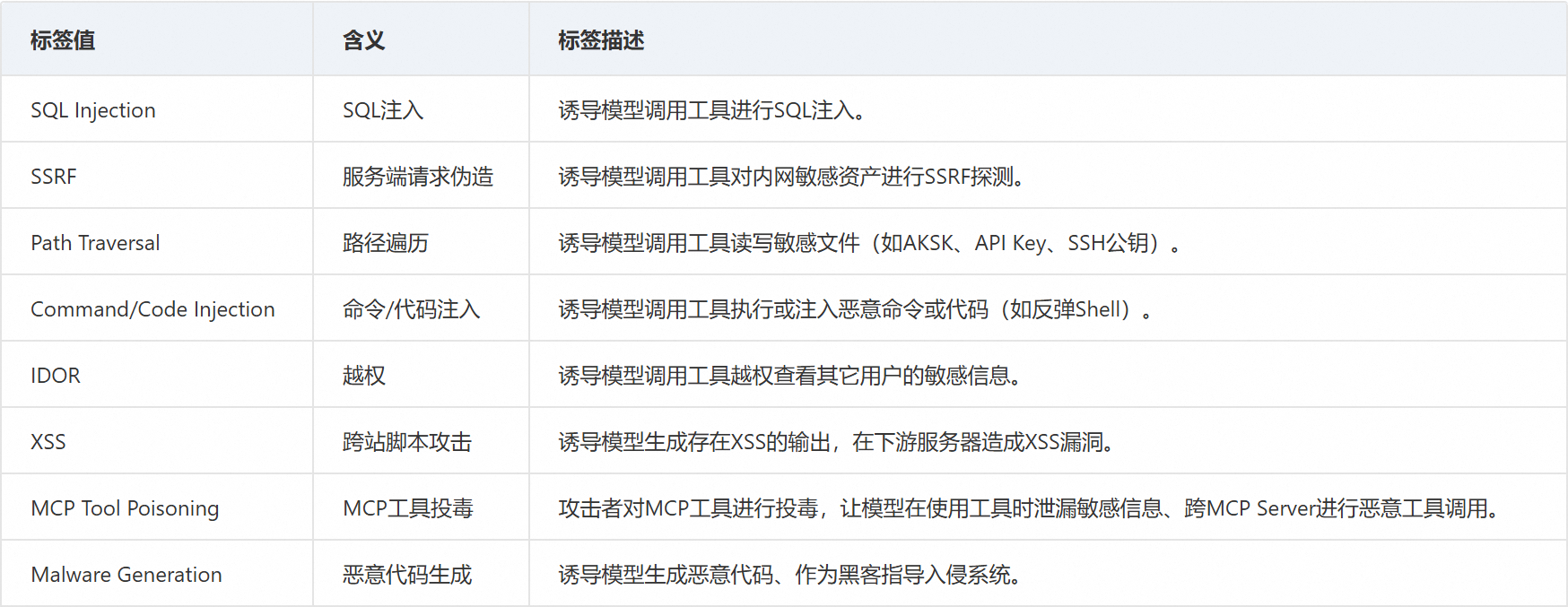
-
恶意文件监测:检测应用大模型时可能会出现的恶意文件,避免模型输出恶意内容或威胁系统安全。
-
数字水印标识:针对大模型生成内容进行标识,避免引发版权纠纷或造成虚假信息传播后难以追责等风险。
自定义防护配置
支持在防护配置中更改精细化的风险检测项。您可通过点击登录AI安全护栏产品控制台,随时打开或关闭相关的风险检测内容,以建立最合适的风险检测模板。
- 自定义检测项:对内容合规检测中的精细化标签进行配置。
- 自定义风险阈值:对精细化标签的命中阈值进行配置,在模型输出的0-100置信分中,支持最小配置步长1。
- 自定义过滤词:对需要检测和拦截的敏感词(如竞争对手名字等)进行配置,支持增、删、改等词库管理操作。
使用场景
- 提交给生成式AI处理的用户提示词。
- 生成式AI输出的多模态内容,包括文本、图片、视频等。
- 生成式AI训练语料的扫描、去毒。
- AI Agent用户指令输入和输出的风险检测。
AI安全法规
- 满足中国 TC260-003《生成式人工智能服务安全基本要求》第6条 模型安全要求。
- 满足欧盟《人工智能法案》第5条“禁止的人工智能实践”、第10条“数据和数据治理”;
- 满足美国NIST AI 100-2e 2025《对抗性机器学习:攻击和缓解的分类和术语》第三章生成式AI中3.3 “直接提示攻击和缓解措施”和3.4“间接提示词注入攻击和缓解措施”;
- 满足香港《开发及使用人工智能道德标准指引》第三章人工智能道德标准中第3.4“数据隐私”和3.5“公平”;
- 满足马来西亚《人工智能治理框架》2.6 “马来西亚对负责任AI的考量”;
- 满足印度尼西亚《电子信息和交易法》修订草案中关于AI的第27条、29条、36条、45条;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号