本文是《打破国外垄断,开发中国人自己的编程语言》系列文章的第1篇。本系列文章的主要目的是教大家学会如何从零开始设计一种编程语言(marvel语言),并使用marvel语言开发一些真实的项目,如移动App、Web应用等。marvel语言可以通过下面3种方式运行:
1. 解释执行
2. 编译成Java Bytecode,利用JVM执行
3. 编译成二进制文件,本地执行(基于LLVM)
阅读本系列文章将是“最残酷的头脑风暴,大家做好准备了吗”
本文是《打破国外垄断,开发中国人自己的编程语言》系列文章的第1篇。本系列文章的主要目的是教大家学会如何从零开始设计一种编程语言(marvel语言),并使用marvel语言开发一些真实的项目,如移动App、Web应用等。marvel语言可以通过下面3种方式运行:
1. 解释执行
2. 编译成Java Bytecode,利用JVM执行
3. 编译成二进制文件,本地执行(基于LLVM)
本系列文章实现的marvel语言并不像很多《自己动手》系列一样,做一个玩具。marvel语言是一个工业级的编程语言,与kotlin、Java等语言是同一个级别,设计之初是为了试验编程语言的新特性。我们团队开发的超平台开发系统UnityMarvel内嵌的Ori语言的部分特性也是来源于Marvel。关于UnityMarvel的细节后面会专门写文章介绍。这里先讨论编译器的问题。
1. 如果系统软件受到制约,有没有可能突出重围呢?
我们知道,现在中美贸易战如火如荼,可能以后使用国外很多软件,尤其是系统软件,都会有一些问题。这就需要我们在一些关键领域有自己可以控制的技术和软件,例如,操作系统、编程语言、数据库、科学计算软件等。其实这些种类的软件中,大多都属于基础软件,只有操作系统和编程语言(以及相关的IDE)可以称为是系统软件。
这里先说说基础软件和系统软件的区别。基础软件是指很多软件都依赖的软件,例如,流行的程序库(如tensorflow、pytorch等)、数据库(如MySQL、Oracle等)。但大多数基础软件的一个共同特点是只服务于特定领域,例如,你不可能用MySQL开发一款游戏,也不可能用tensorflow开发移动App。而在基础软件中有一小类,它们是通用的,几乎适合于各个领域,我们将这类软件称为系统软件。它们是整个IT领域的基础架构。没有它们,整个IT领域将不复存在。例如,目前,只有操作系统和编译器符合这两个特征。大家可以想想,没有了关系型数据库,还有其他类型的数据库可以使用,没有了tensorflow,IT领域也不会停止运转。但没有了Windows、macOS、Linux、C语言、Java语言这些技术,世界将会怎样,将会重新退回到工业文明时代。 所以系统软件是基础软件的一个子集,而且必不可少。如果将基础软件和其他软件比作星球,那么系统软件就是星核。
在系统软件中,编译器是最容易突破的。因为编译器(编程语言)的生态相比操作系统来说,更容易建立。这是因为目前有很多虚拟机可以选择,例如,最常用的是JVM,当然,还有微软的.net core等技术。 如果我们的编程语言可以基于JVM,那么就意味着可以利用Java语言的所有生态,如果我们的编程语言可以用更容易的方式调用其他语言(如C++、Go等),在某种程度上,也就可以直接使用这些编程语言的生态。当然,还有更先进的超生态技术(UnityMarvel的Ori语言正是基于超生态技术的),总之,作为一种新的编程语言,利用其他的生态是最廉价的方式,当然,在语言发展的过程中,也可以逐渐建立自己的生态(相当于骑驴找马),这也是一种策略。所以如果想突破,编译器(编程语言)是最容易的一个。当然,如果拥有自己可以控制的编程语言,可以为后期的操作系统提供支援,例如,利用超生态技术,在建立新操作系统之前,就为该操作系统提前建立生态(这一点以后专门撰文阐述)。
2. 开发编程语言需要哪些知识
现在进入到最关键的部分了,开发一种编程语言到底需要哪些知识呢?其实需要的知识还是蛮多的。最基础的要求是必须至少会一种编程语言。如C、C++、Java、C#、Go、Python等。当然,推荐会3种以上的编程语言,因为我们是在设计编程语言,不是在设计普通的软件。在设计编程语言时,需要进行横向比较,也就是需要参考其他的编程语言,因为任何新技术都不可能100%完全凭空产生,这些新技术都会或多或少地留下其他同类技术的影子,编程语言也不例外。例如,UnityMarvel内嵌的Ori语言就是参考了数十种编程语言,以及加入了自己的新技术而最终形成的。
除了要了解大量的编程语言外,还有很多与业务有关的知识需要掌握。主要的知识结构(不仅仅这些,后面用到了再详细讲)如下:
(1)了解大量的编程语言(推荐3种以上)
(2)编译原理的基础知识
(3)算法能力
(4)编译器前端生成器
(5)学习能力
(6)想象力
尽管开发编程语言并不会像大学学的编译原理一样从0开始构造一个编译器,但编译原理的基础知识还是要掌握的,不了解编译原理的同学,赶紧上B站、西瓜视频、油管去补课,后期我也会结合marvel语言做相关的视频课程,大家可以关注哦!
算法就不必说了,编译器里面充斥着各种算法,编译器的算法密度几乎超过了绝大多数应用。任何形式的算法都可能涉及到,最基础的数据结构必须掌握,其他的算法,能学多少就学多少,多多益善。这个没有固定的教程,也是需要不断在实践中学习。
开发编译器的基本步骤如下图所示。
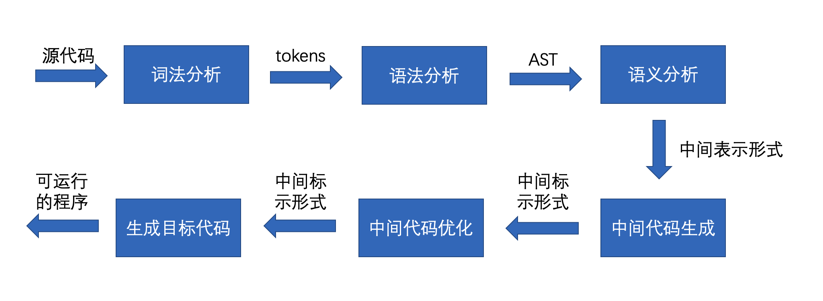
首先说明一点,并不是所有的编译器都严格按照这些步骤进行,有可能会将多个步骤合成一个步骤(例如,语法分析和语义分析合成一步,最后输出AST),也有可能将一步分成多个步骤,或者再增加一些与业务相关的步骤。
对于工业级编译器来说,并不会从0开始实现词法和语法分析器,并不是这东西有多难,而是如果完全手工编写代码,要添加或修改一个新语法,那简直就是一场噩梦,因为要修改非常多的地方,而且一旦出错,非常不好找原因(因为代码过于复杂)。由于词法分析和语法分析有规律可循,所以出现了很多通过文法生成词法分析器和语法分析器的工具,由于词法分析与语法分析是编译器前端的重要组成部分,所以这类工具通常称为“编译器前端生成器”。比较著名的包括lex、yacc、javacc、antlr等。其中lex是专门用来生成词法分析器的,yacc用来生成语法分析器的,javacc可以同时生成词法和语法分析器、antlr也同样可以生成词法分析器和语法分析器。不过lex和yacc只支持C语言,javacc只支持Java语言。而antlr支持多种编程语言,例如Java、C++、JavaScript、Go、C#、Swift等。本系列文章也使用了antlr的最新版本antlr4来实现编译器的前端(词法分析器和语法分析器)。
这几种工具都是依赖于文法生成词法分析器和语法分析器的,例如,在antlr4中,如果要识别加减乘除四则运算,只需要编写下面的文法即可。
expr: expr op=('*'|'/') expr | expr op=('+'|'-') expr
文法是不是很简单呢?但如果要编写完善的代码,可能需要上百行才能实现(我们团队实现的Ori语言,利用antlr4生成的词法和语法分析器,总共6万行Go语言代码,我们自己编写了大概4万行Go代码,整个编译器有超过10万行代码,3/5是自动生成的,2/5是自己编写的)。而且文法还标识了优先级,antlr4规定,写在前面的文法的优先级高于写在后面的文法的优先级。我们知道,对于四则运算来说,是先乘除,后加减,所以expr op=('*'|'/') expr 应该在expr op=('+'|'-') expr 前面,倒过来是不行了。如果要加更复杂的运算,例如,平方、开方、幂等,只需要修改这个文法即可,是不是很简单呢?
前面说的前4点是硬知识,也有很多教程可以学习,但最后两点:学习能力和想象力,就要完全靠自己的天赋了。因为前面4点能让你做出一个看着还不错的编译器,但最后两点能决定你做的编译器有多强大。
实现一个编程语言,所涉及到的知识要比实现编译器难度更大。因为如果实现编译器,并且是已经存在的编程语言,由于语法已经确定,所以只需要实现出来即可。但编程语言不同,一切需要重新设计,尤其是在涉及到新语法时,非常困难,需要了解的知识相当多,所以需要拥有快速学习能力,可以在短时间内学会并掌握任何知识和技术。另外,想象力更重要,因为设计一款新的编程语言,有些东西可能不仅仅局限于IT领域,也不仅仅局限于自己所从事的技术领域,例如。在Ori语言中,拥有一些创新的语法,需要同时适应类似JavaScript的单线程模式和Java的多线程模式。因此,拥有多维度的想象力才是最终取得胜利的关键。
3. 自己设计的编程语言会流行吗
我经常在网上看到很多同学在问,为什么中国没有自己流行的编程语言(尽管有易语言,但由于是中文编程,所以注定不会全球流行,国内也并不算流行)呢?BAT等大厂为何不开发一个呢? 然后有人回答,开发编程语言容易,关键是生态,还有人回答,BAT是因为没有必要,因为编程语言没有和KPI挂钩,也有些人回答,开发一款编程语言,火起来很难。 其实这些都可能是原因,但主要原因其实就是需求没有与行动挂钩,或者说,现在的编程语言已经足够满足需求了,没有必要再开发一款新的编程语言,而且这些大厂的盈利压力都很大,当然,还有技术积累的问题。
其实编程语言有很多种,有一种就是像Java、C#、C++一样的通用编程语言,这类语言什么都能做,是一种图灵完备的编程语言。还有另外一种编程语言,如SQL、VBA、ABAP(SAP的内嵌语言),这类属于领域编程语言,他们也可能是图灵完备的,也可能不是图灵完备的。通常使用这类编程语言完成某些特定的工作,如SQL操作数据库,VBA操作Office、ABAP操作SAP数据等。其实在国内有很多公司内部已经提供了类似的领域语言,只是非常专业,功能单一,绝大多数人不清楚而已。
至于自己开发出来的编程语言是否会流行,其实你们想太多了。编程语言是为了解决实际问题而存在的,不是为了流行而存在的。就像衣服,最初的用途是为了保暖,而不是时尚,当大多数人都使用自己生产的衣服保暖,那他就是流行款了!所以让编程语言解决实际问题才是优先要考虑,至于以后是否会流行,自己说了不算!
像我们团队开发的UM系统,其实原来压根就没打算自己开发编程语言,想直接使用JavaScript,不过后来发现,JavaScript太动态了,使用JavaScript根本没有办法做一款完美的IDE,而且功能有限,并且混乱。还有就是JS是动态语言,如果将其转换为静态语言,会以牺牲性能为代价,而且无法有效融合单线程和多线程的特性,并且还无法与UM IDE融为一体,所以没办法,才开发一款自己的编程语言Ori,并且融合了数十种编程语言的优秀特性,而且加入了更先进的特性(如内嵌SQL、虚拟组件、虚拟数据库、支持跨平台的语法、客户端服务端一体化、柔性热更新等),当然,这些特性需要与UM IDE配合才能使用。
4. 开发编程语言,从这里起航:配置Antlr4环境
如果一上来就开发编程语言,估计大家就开始晕了,所以我们先从最简单的开始,就是先来编写一个可以解析加减乘除表达式的编译器。我们使用了antlr4来生成词法分析器和语法分析器,所以先要配置一下antlr4的开发环境。
由于antlr4使用Java开发,所以不管用什么编程语言设计编译器,JDK必须安装,并且还需要一款强大的Java IDE,这里推荐Intellij IDEA。我们只使用Intellij IDEA的最基础功能,所以CE(社区版)版足够了,这个版本是免费的。
在安装完Intellij IDEA CE后,到下面的页面下载antlr4工具相关的库。
进入页面,找到下面的部分,点击第1个链接下载即可。
下载完antlr4的工具包后,找到其中的Java运行时库,并用Intellij IDEA CE创建一个Java工程,然后直接将Antlr4 Java运行时库复制到工程的lib目录中(没有lib目录可以建立一个),如下图所示。
然后在lib目录的右键菜单中点击“Mark Directory as”>“Sources Root”菜单项,将lib编程源代码目录,这样Intellij IDEA CE就会搜索lib目录中的所有库。当然,可以直接在模块中引用antlr4的库,不过将antlr4 运行时库与工程放到一起,这样如果将工程复制到其他机器上,就不会由于antlr4的运行库没有复制而导致无法运行了。

然后需要安装Intellij IDEA CE的Antlr插件。进入插件安装页面,如果没有安装antlr插件,选择Marketplace标签页,输入antlr搜索插件,通常第一个就是。点击右侧的install按钮即可安装。如果已经安装,Antlr插件会出现在Installed页面中,如下图所示。

安装完Antlr插件后,新创建一个文件,将文件扩展名设置为g4,就会看到文件前面的图标变成了红色,里面有一个A字母,这就是Antlr4的标识,如下图所示。

5. Antlr4的Hello World
现在我们开始进入激动人心的时刻了,用Antlr4亲手做我们的第一个编译器:解析四则运算表达式的计算器。不过在完成这个编译器之前,一定要了解一下Antlr4。
下面先给出一个可以识别以hello开头的词组的识别程序的文法。首先创建一个名为Hello.g4的文件,并输入下面的代码:
grammar Hello;
r : 'hello' ID ;
ID : [a-z]+ ;
WS : [ \t\r\n]+ -> skip ;
大家先不需要管这些代码是什么意思,只需要照猫画虎输入即可。
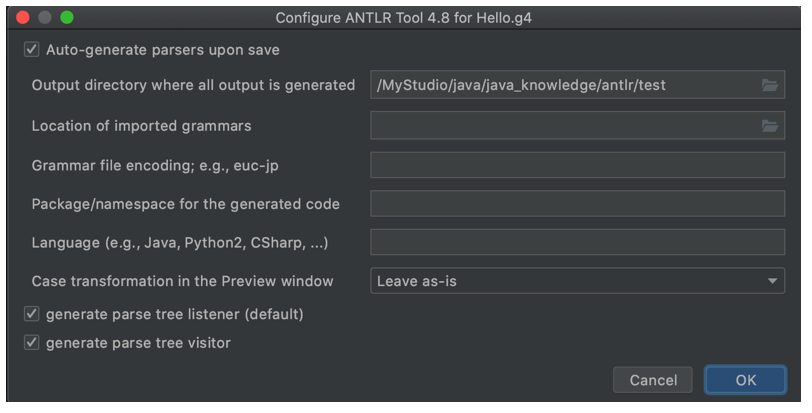
然后在Hello.g4右键菜单点击“Configure ANTLR”菜单项,会弹出如下图的对话框,设置第一个文本输入框,指定生成目录,这里指定与Hello.g4相同的目录。Hello.g4生成的文件都会放在这个目录中。
然后点击Hello.g4右键菜单的“Generate ANTLR Recognizer”菜单项,会自动生成一堆文件,如下图所示。注意:Java文件都隐藏了扩展名。
Hello.java和MyHelloVisitor.java是后来创建的,其他文件都是自动生成的。其中HelloLexer.java是词法分析器、HelloParser.java是语法分析器,其他文件后面再说。
大家可以打开这两个文件,看到每一个文件的内容都有上百行,这要是人工编写,会累死人,而使用Antlr4,只需要4行文法就搞定。如果要添加或修改原来的语法,只需要修改Hello.g4文件,然后再重新生成一遍即可。
现在有一个问题,怎么用Hello.g4生成的一堆文件呢?或者换种问法,生成的这些文件有什么用呢?
Hello.g4生成的这些文件的主要目的就是进行词法分析和语法分析,那么如何用呢?使用有如下两种方式:
1. 用grun工具测试
2. 用Java代码调用词法分析器和语法分析器,编写完整的编译器
现在先来说说grun工具。其实并没有grun这个东西,grun是一个别名,真实的工具在是antlr-4.8-complete.jar中的 org.antlr.v4.gui.TestRig类,在macOS或Linux下,可以使用alias命令起一个别名,官方叫grun,所以这里就沿用了官方的叫法。如果在windows下,可以创建一个grun.cmd文件。
起别名的完整命令如下:
alias grun='java -classpath .:/System/Volumes/Data/sdk/compilers/antlr4-4.8/antlr-4.8-complete.jar org.antlr.v4.gui.TestRig'
现在就可以使用grun测试我们的程序了。
首先要说明一点,grun测试的是.class文件,不是.java文件,所以在测试之前,要在终端中切换到.class文件所在的目录。Intellij IDEA CE默认的.class目录是out/production目录,如下图所示。在一开始,前面生成的.java文件并没有编译,读者可以随便找个Java程序运行下,这时Intellij IDEA CE会编译所有还没有编译的.java文件,我们会发现,刚才生成的所有.java文件都生成了同名的.class文件。

读者可以直接在操作系统的终端进入.class所在的目录,或者通过Intellij IDEA CE下方的Terminal也可以输入命令行,如下图所示。
现在来做我们的第一个测试:
首先输入下面的命令(先不需要管命令是什么意思):
grun Hello r -tokens
然后输入下面的内容:
hello world
如果读者在macOS或Linux下,按Ctrl+D,如果在Windows下,按Ctrl+Z输入结束符号,会输出如下图的内容:
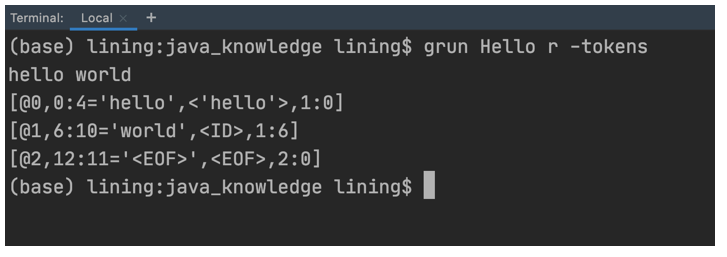
现在来解释一下grun Hello r -tokens是什么意思。Hello表示Hello.g4中grammar后面的部分,也就是Hello。r是文法产生式等号左侧的符号(非终结符),也就是r : 'hello' ID ;中的r。 -tokens表示列出所有的tokens。
那么什么是token呢? 其实token是词法分析器的输出,同时,token将作为语法分析器的输入,而AST(抽象语法树)则是语法分析器的输出。
token就是编程语言中不可再分的单元,相当于编程语言的原子。看下面的程序:
这是一个非常简单的条件语句,那么在这两行代码中,有多少个token呢?根据token不可分割的原则,包含如下的token:
上面用逗号(,)分隔的符号都是token,例如,if是关键字,将作为一个整体对待,在解析代码时,肯定不会将if拆开,10是一个整数,也将作为一个整体对待,肯定不会将其拆成1和0。
那么Hello的输出结果意味着什么呢?我们输入了hello world,根据语法规则。任何字符串都需要以hello开头,所以hello将作为一个token(相当于前面条件语句的if关键字,这里hello是一个关键字)。而后面可以是任意字符串,但与hello之间至少要有一个空格。所以hello world符合Hello的语法规则,hello abc也同样符合,而helloabc就不符合了,因为hello和abc之间没有任何分隔符,根据最长匹配原则,Antlr4会选择最长的字符串进行匹配,所以匹配的是helloabc,而不是hello。
现在我们的实验也做完了,可能很多读者还是一头雾水,不过不要紧,我们再详细讲一下Antlr4到底是怎么分析的。
Antlr4采用了自顶向下递归的分析方式。自顶向下就是先将整个编程语言源文件看成一个整体,这就是入口点,也就是Hello.g4中的r。这个入口点起任何名字都可以,只要不和其他的文法标识重名即可。然后从这个入口点开始,就可以用递归的方式写文法了。文法用于从上到下推导,左侧是文法标识,右侧是文法的产生式。例如,要识别下面一组字符串:
hello world
hello abc
hello Bill
hello 李宁
很明显,这4行文本都是以hello开头,后面跟着任意的字符串,中间用空格分隔。所以我们的文法应该是以hello开头,后面跟一个标识,用ID表示。文法如下:
在Antlr4中,每一个文法都要用分号(;)结尾,如果是固定的字符串,如关键字,用单引号括起来。如'hello'。
ID表示任意的标识符,也是终结符。所谓终结符,是指不能再继续往下推导的符号(相当于树的叶子节点)。在Antlr4中,终结符标识用由首字母大写的字符串表示,如ID。而非终结符(可以继续往下推导)用首字母小写的字符串表示,如r。
现在是自顶向下分析的第1步,第2步是处理ID。文法如下:
ID的产生式不包含任何的非终结符,也就是再也无法继续推导了。[a-z]是一种简写,也就是a到z共26个小写字母中的任何一个,后面的加号(+)表示至少要有一个小写字母。
到现在为止,自顶向下分析的过程已经完成了,分为两步,第一步将整个字符串看做一个整体,并且将其分解为hello和后面的任意字符串。第二部来处理这个任意字符串。这里规定,这个任意字符串只能由小写字母组成。
不过现在还有一个问题,Antlr4怎么知道hello和world之间需要有空格或其他空白符分隔呢?其实这就涉及到Hello.g4的最后一行代码了:WS : [ \t\r\n]+ -> skip ; 这行代码设置了一个skip通道(通道会在后面的文章中详细讲解),用于忽略指定的字符,这些被忽略的字符,将作为token的分隔符,这里面指定了4个分隔符:空格、制表符(\t)、回车符(\r)、换行符(\n)。也就是说,下面的形式也是可以的:
ok,现在Hello.g4的语法规则已经讲的差不多了,里面涉及到了一些概念,在后面的文章中会详细讲解。现在来总结一下:
Antlr4的文法文件是以g4作为扩展名,第一行代码必须以grammar开头,后面跟着语法名,如Hello,该名字必须与g4文件名一致。每一行代码都必须用分号(;)分隔。然后就是若干文法产生式了。例如,Ori语言的最顶端文法是这样的。
grammar Ori;
program : sourceElements? EOF
sourceElement : statement
statement
:
importStatement
| sqlStatement
| dollarMemberStatement
| classDeclarationStatement
| interfaceDeclarationStatement
| functionDeclarationStatement
| variableStatement
| ifStatement
| iterationStatement
| continueStatement
| breakStatement
| returnStatement
| withStatement
| switchStatement
| throwStatement
| tryStatement
| blockStatement
| expressionStatement
| commentStatement
;
program是Ori语言的入口点,然后Ori语言将整个语言分成若干源代码元素(sourceElements?),后面的问号表示可选,也就是说,Ori语言的源代码文件可以是空文件。EOF是文件结束符。这里讲每一个源代码元素对应一条statement(语句),这里之所以不直接使用statement,而是使用sourceElement,是因为以后可能会进行扩展,这时只需要修改sourceElement即可(目前sourceElement等于statement),而一条语句包括多种,如ImportStatement、sqlStatement(内嵌SQL)、classDeclarationStatement(类声明)等。然后就继续往下分,如sqlStatement还会包含sqlInsert、sqlUpdate等。以此类推,直到不可再分为止。这就是自顶向下分析的基本方法,其实这就是分治法的一种表现,尽管编程语言看着很复杂,一个大型系统可能会有上百万甚至更多行代码,但如果将编程语言从顶向下分析,涉及到的语句种类也不过几十种而已。Ori语言的文法文件也就1000多行,包括词法文件部分,也就2000行出头。用2000行代码,就可以完全描述一种图灵完备的编程语言,真是perfect。而这2000行代码,生成的Go语言代码超过了60000行。
现在再回到grun工具上来。其实grun的功能很强大,除了可以作为测试工具外,还可以显示Antlr4生成的AST,看一下自顶向下分析的流程。
首先准备一个hello.txt文件,并输入hello world。然后在终端输入下面的命令(读者要将hello.txt文件的路径改成自己机器上的路径):
grun Hello r -gui < /MyStudio/java/java_knowledge/antlr/test/hello.txt
然后就会弹出如下图的窗口,右侧显示了AST的树状结构。Antlr4制作编译器的过程就是先根据源代码生成AST,然后对AST进行遍历(根据语言的特性,会遍历1到n遍),遍历完后,就会生成中间代码、以及最终的二进制文件。所以AST起到了承前启后的作用。

6. 如何用程序进行词法和语法分析
尽管已经了解了Antlr4的基本使用方法,但到现在为止,还没有用Java编写过一行代码呢?现在我就来演示如何用Java调用上一节生成的词法分析器和语法分析器。
下面先给出实现代码:
首先创建一个MyHelloVisitor.java文件,并输入下面的代码:
import org.antlr.v4.runtime.tree.AbstractParseTreeVisitor;
public class MyHelloVisitor extends AbstractParseTreeVisitor<String> implements HelloVisitor<String> {
@Override public String visitR(HelloParser.RContext ctx) {
System.out.println(ctx.getText());
System.out.println(ctx.ID().getText());
return visitChildren(ctx);
}
}
然后再创建一个Hello.java文件,并输入下面的代码:
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTree;
public class Hello {
public static void main(String[] args) throws Exception {
// 读取源代码文件,这里选择直接从字符串读取
CharStream input = CharStreams.fromString("hello world");
// 创建词法分析器对象
HelloLexer lexer = new HelloLexer(input);
// 获取词法分析器输出的tokens
CommonTokenStream tokens = new CommonTokenStream(lexer);
// 创建语法分析器对象,并将词法分析器输出的tokens作为语法分析器的输入
HelloParser parser = new HelloParser(tokens);
// 开始分析程序,这也是生成AST的过程
ParseTree tree = parser.r(); // 文法的入口点r会转换为一个方法,调用该方法,就会自顶向下递归分析源代码
// 创建Visitor对象
MyHelloVisitor hello = new MyHelloVisitor();
// 开始遍历AST
hello.visit(tree);
}
}
现在运行Hello.java,如果在Run窗口输出如下图的内容,说明运行成功了。

现在来解释一下前面的代码。这里先要知道Antlr4是如何遍历AST的。Antlr4有如下两种方式遍历AST:
(1)listener
(2)visitor
第一种方式更灵活,但不容易使用。visitor不灵活,但容易使用。本例使用了第2种方式来遍历AST,但本系列文章的大多数代码主要使用listener来遍历AST。listener方式会在后面的文章中详细介绍,这里主要介绍visitor。其实这两种遍历AST的方式的原理类似,都是遇到了一个节点,就会调用相应的回调方法,然后将必要的信息作为参数传入回调方法,用户可以在回调方法中完成代码生成、数据处理、中间代码优化等工作。那么这些回调方法放在哪里呢?这就要说到前面创建的MyHelloVisitor类。该类实现了HelloVisitor接口,该接口是根据Hello.g4文件自动生成的,代码如下:
import org.antlr.v4.runtime.tree.ParseTreeVisitor;
public interface HelloVisitor<T> extends ParseTreeVisitor<T> {
T visitR(HelloParser.RContext ctx);
}
我们可以看到,该接口中只有一个方法,就是visitR,该方法是遍历到r节点调用的回调方法。
如果文法文件很大时,会生成相当多的回调方法,例如,Ori语言的文法就生成了数百个回调方法,这些回调方法并不一定都用到,在这种情况下,并不需要实现所有的回调方法,所以Antlr4在生成回调接口文件的同时,还生成了一个默认实现类,如本例的HelloBaseVisitor,默认实现类已经默认实现了所有的回调方法,我们的Visitor类只需要从该类继承,就只需要实现必要的回调方法即可。
import org.antlr.v4.runtime.tree.AbstractParseTreeVisitor;
public class HelloBaseVisitor<T> extends AbstractParseTreeVisitor<T> implements HelloVisitor<T> {
@Override public T visitR(HelloParser.RContext ctx) { return visitChildren(ctx); }
}
本例的MyHelloVisitor类继承了HelloBaseVisitor类,并覆盖了visitR方法,输出了r节点的文本和ID的文本。
对于Hello类来说,就是最终的调用代码了。通常一个用Antlr4实现的编译器,需要经过如下几步:
(1)读取源代码文件(或直接从字符串获取源代码)
(2)创建词法分析器(输入是单个字符、输出是tokens)
(3)创建语法分析器(输入是tokens、输出是AST)
(4)开始遍历AST
这4步已经在Hello类中做了详细的注释,大家可以自行查看。
7. 弄一个可以解析表达式的计算器
前面已经给出了一个完整的Antlr4案例,不过这个案例太简单了,没什么实际的用途,本节会利用Antlr4实现一个有实际价值的计算器程序。该程序可以解析过个表达式,表达式包含加减乘除运算,每一个表达式占一行,用分号(;)结尾。
先给出文法:Calc.g4
grammar Calc;
// 下面是语法
prog: stat+ ;
stat: expr ';' # printExpr
| ID '=' expr ';' # assign
| NEWLINE # blank
;
expr: expr op=('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| INT # int
| ID # id
| '(' expr ')' # parens
;
// 下面是词法
MUL : '*' ;
DIV : '/' ;
ADD : '+' ;
SUB : '-' ;
ID : [a-zA-Z]+ ; // 匹配标识符
INT : [0-9]+ ; // 匹配整数
WS : [ \t]+ -> skip ; // 忽略空白符
NEWLINE:'\r'? '\n' ; // 空行
现在生成Calc.g4 的相关文件。先看一下生成的CalcVisitor.java文件,代码如下:
import org.antlr.v4.runtime.tree.ParseTreeVisitor;
public interface CalcVisitor<T> extends ParseTreeVisitor<T> {
T visitProg(CalcParser.ProgContext ctx);
T visitPrintExpr(CalcParser.PrintExprContext ctx);
T visitAssign(CalcParser.AssignContext ctx);
T visitBlank(CalcParser.BlankContext ctx);
T visitParens(CalcParser.ParensContext ctx);
T visitMulDiv(CalcParser.MulDivContext ctx);
T visitAddSub(CalcParser.AddSubContext ctx);
T visitId(CalcParser.IdContext ctx);
T visitInt(CalcParser.IntContext ctx);
}
CalcVisitor有9个回调方法,从文法上看,有多少个文法,就应该有多少个回调方法。在Calc.g4中,除了第一个文法(prog:stat+;)外,其他的文法都起了别名,如printExpr,assign等。所以这些文法对应的回调方法都是以别名作为后缀的,然后前面加上visit。其实这9个方法,分别经过了AST的9个非叶子节点后(如果有的话),被分别调用。
例如,现在测试这个表达式(将表达式放置expr.calc文件中):1+3 * 4 - 12 /5;
grun Calc prog -gui < /MyStudio/java/java_knowledge/antlr/Calc/expr.calc
执行上面的命令,会显示如下图的AST。

要计算上述表达式,就需要遍历这棵AST。例如,当遍历到prog节点时,就会调用visitProg方法,通过该方法的参数可以获取prog节点的直接子节点的信息(就是左右两个stat节点)。当遇到减法表达式时,就会调用visitAddSub方法,以此类推。
现在看一下EvalVisitor类的实现。该类的实现原理是当直接计算两个值时,如3 * 5、4 - 1,就分别由visitMulDivhe visitAddSub方法计算,并通过返回值返回计算结果。如果遇到变量(Calc支持变量),需要首先将变量放到一个Map中,然后在获取该变量时,会从Map读取。Map相当于一个符号表。
import java.util.HashMap;
import java.util.Map;
public class EvalVisitor extends CalcBaseVisitor<Integer> {
/** "memory" for our calculator; variable/value pairs go here */
Map<String, Integer> memory = new HashMap<String, Integer>();
boolean error = false;
/** ID '=' expr NEWLINE */
// 初始化变量的操作(赋值操作)
@Override
public Integer visitAssign(CalcParser.AssignContext ctx) {
String id = ctx.ID().getText(); // id is left-hand side of '='
int value = visit(ctx.expr()); // compute value of expression on right
memory.put(id, value); // store it in our memory
return value;
}
/** expr NEWLINE */
// 输出表达式的计算结果
@Override
public Integer visitPrintExpr(CalcParser.PrintExprContext ctx) {
Integer value = visit(ctx.expr()); // evaluate the expr child
System.out.println(value); // print the result
return 0; // return dummy value
}
/** INT */
// 将字符串形式的整数转换为整数类型
@Override
public Integer visitInt(CalcParser.IntContext ctx) {
return Integer.valueOf(ctx.INT().getText());
}
/** ID */
@Override
public Integer visitId(CalcParser.IdContext ctx) {
String id = ctx.ID().getText();
// 从Map中获取变量的值
if ( memory.containsKey(id) ) {
return memory.get(id);
} else {
// 引用了不存在的变量,输出错误信息
System.err.println(String.format("变量<%s> 不存在!",id));
error = true;
}
return 0;
}
/** expr op=('*'|'/') expr */
// 计算乘法和除法
@Override
public Integer visitMulDiv(CalcParser.MulDivContext ctx) {
int left = visit(ctx.expr(0)); // get value of left subexpression
int right = visit(ctx.expr(1)); // get value of right subexpression
if ( ctx.op.getType() == CalcParser.MUL ) return left * right;
return left / right; // must be DIV
}
// 计算加法和减法
/** expr op=('+'|'-') expr */
@Override
public Integer visitAddSub(CalcParser.AddSubContext ctx) {
int left = visit(ctx.expr(0)); // get value of left subexpression
int right = visit(ctx.expr(1)); // get value of right subexpression
if ( ctx.op.getType() == CalcParser.ADD ) return left + right;
return left - right; // must be SUB
}
/** '(' expr ')' */
// 处理括号表达式
@Override
public Integer visitParens(CalcParser.ParensContext ctx) {
return visit(ctx.expr()); // return child expr's value
}
}
最后看一下主程序(MarvelCalc)的源代码。
import org.antlr.v4.runtime.ANTLRInputStream;
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTree;
import java.io.FileInputStream;
import java.io.InputStream;
public class MarvelCalc {
public static void main(String[] args) throws Exception {
// 从文件读取源代码
String inputFile = null;
if ( args.length>0 ) {
inputFile = args[0];
} else {
System.out.println("语法格式:MarvelCalc inputfile");
return;
}
InputStream is = System.in;
if ( inputFile!=null ) is = new FileInputStream(inputFile);
CharStream input = CharStreams.fromStream(is);
CalcLexer lexer = new CalcLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
CalcParser parser = new CalcParser(tokens);
ParseTree tree = parser.prog(); // 分析源代码
EvalVisitor eval = new EvalVisitor();
eval.visit(tree);
}
}
在expr.calc文件中输入下面的内容:
1+3 * 4 - 12 /6;
x = 40;
y = 13;
x * y + 20 - 42/6;
z = 12;
x + 5 * z - y;
并使用下面的命令行执行计算器程序,或在IDE中将expr.calc作为参数允许MarvelCalc。
java MarvelCalc expr.calc
会得到下面的结果:
我们可以看到,在expr.calc文件中,有3个可以计算的表达式,其中最后两个表达式使用了变量,而输出结果就是这3个表达式的计算结果。从Calc.g4中也可以看出。语句一共有如下3种:
(1) 输出表达式(包括运算、id和常量)
(2)赋值表达式(创建变量)
(3)空行
从EvalVisitor类的实现可以看出,只有输出表达式才会输出结果,其他的表达式只是在内部计算,生成内部结果,如向Map中存储变量和值。
OK,到现在为止,我们已经创建了一个非常实用的计算器程序,不过这个程序仍然很简单,在后面的文章中,将会不断利用新学到的知识完成更复杂的编译器程序,直到可以实现Marvel语言为止。
下载本文完整源代码,请关注微信公众号「极客起源」,更多精彩内容期待您的光临!






 浙公网安备 33010602011771号
浙公网安备 33010602011771号