根据kafka的零拷贝机制来确定集群需要多大内存
1、首先要大概知道非0拷贝机制

传统的读取文件数据并发送到网络的步骤如下: (1)操作系统将数据从磁盘文件中读取到内核空间的页面缓存; (2)应用程序将数据从内核空间读入用户空间缓冲区; (3)应用程序将读到数据写回内核空间并放入socket缓冲区; (4)操作系统将数据从socket缓冲区复制到网卡接口,此时数据才能通过网络发送。
很明显,传统非0拷贝读取磁盘一次,经过4次网络拷贝(IO);
如果读取10亿次,意味经过40亿次频繁的IO处理
2、kafka的0拷贝技术
kafka的0拷贝技术充分利用了操作系统内核OSCache
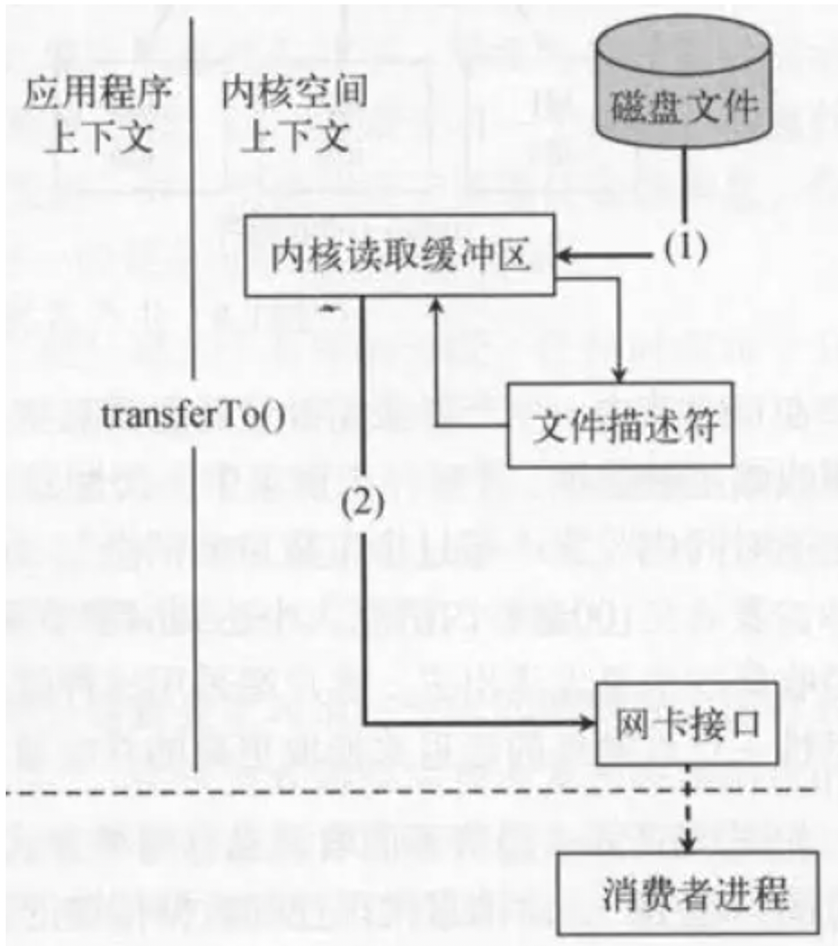
这样原来的一次读取操作,只经历了2次拷贝(IO);
假如现在有5个消费者 , 要读取10亿次磁盘文件:
原来的非0拷贝:5 * 10亿 * 4 = 200亿次网络拷贝(IO)
0拷贝技术:1 次 + 10亿次
很明显,随着消费者次数的增多,读取次数的增多,占用IO的频繁是很明显的
3、估算kafka服务器需要的内存
每天全量日志100亿条 , 根据2-8原则 。高峰期大概会产生约80亿条数据量
一般的高峰期是在早上8-10点 下午的6-7点 晚上的9-10点 这个时间大概就是4个小时
意味着80亿/4*3600秒 = 55万/秒 , 每条数据大概在1KB大小 也就是每秒大概约5G大小的日志
假如线上一共100个topic 来对接这个日质量, 每个topic有5个分区,2个副本,那意味着总共要存储1000份 ;
kafka的每一个分区是一个目录,目录里面存储的是segment(默认1G);
那么高峰期每秒5G日志,假如均摊到100个topic上 , 意味着kafka集群在高峰期大概每秒产生了:5G/100 = 0.05G(每个topic上要分摊这些), 每个topic5个分区2个副本 那就是说,其实最终要存储的大概是 : 0.05*5*2 = 0.5G(每个topic每秒存储的 数据大小)
意味着2s就会产生一个segment文件(1G)
kafka在读取数据使用的是0拷贝技术,是通过linux的OSCache内核缓冲区来完成的;所以说要想让你的kafka性能达到最好,那么只要给OSCache足够大的内存,KAFKA性能就会达到非常好
当然真实情况是考虑你们能承受的最大延迟是多少. 比如:5s的 延迟
那意味着5s内每个topic会产生:5s*0.5G = 2.5G大小
100个topic * 每个topic延迟5s的量2.5G(5s后,缓存区数据刷盘) = 250G
现在7台机器,那么250G/7 大概每台机器用在OSCache上的内存36G.
然后在算上给kafka的JVM使用的内存(5G~10G足够了)
终上所述每天全量日志100亿条数据量情况下, 每台机器给kafka预留的内存大概:41G ~ 46G

 浙公网安备 33010602011771号
浙公网安备 33010602011771号