摘要:
Whose Job is AI It’s common for management teams to assume that data scientists inherently know which problems to solve for the company. However, this 阅读全文
posted @ 2024-12-25 21:35
wlu
阅读(67)
评论(0)
推荐(0)
摘要:
B-CIDS AI-Readiness: A company is AI-ready when it can smoothly progress from AI concept to implementation and benefit realization, and do so consiste 阅读全文
posted @ 2024-12-25 15:27
wlu
阅读(45)
评论(0)
推荐(0)
摘要:
The Machine Learning Development Life Cycle Introduction Quote: "There are things known and there are things unknown, and in between are the doors of 阅读全文
posted @ 2024-12-25 11:23
wlu
阅读(253)
评论(0)
推荐(0)
摘要:
decision making ≈ data driven decision making Data-driven decision-making refers to leveraging aggregated and summarized data to drive critical decisi 阅读全文
posted @ 2024-12-25 10:39
wlu
阅读(59)
评论(0)
推荐(0)
摘要:
AI Eliminates Inefficiencies AI can significantly reduce inefficiencies in various sectors by automating tedious and time-consuming tasks. For instanc 阅读全文
posted @ 2024-12-25 09:50
wlu
阅读(37)
评论(0)
推荐(0)
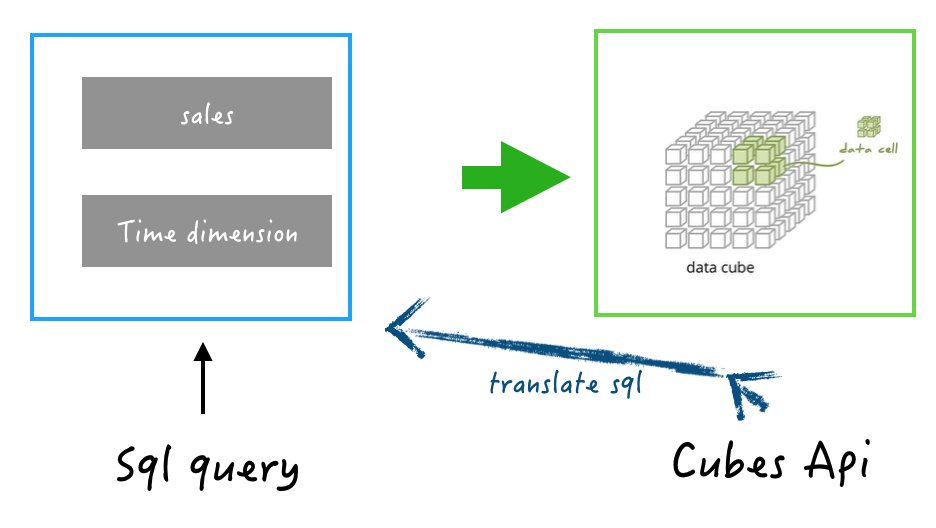 Cubes可以作为Kylin多维数据查询服务:
例如对0-4这几个销售点,我们要统计2012年每个季度的结果:
http://localhost:5000/cube/KYLIN_SALES/aggregate?drilldown=year.QUATER|site&cut=year.YEAR_BEG_DT:date'2012\-01\-01'|site:0-4
Cubes可以作为Kylin多维数据查询服务:
例如对0-4这几个销售点,我们要统计2012年每个季度的结果:
http://localhost:5000/cube/KYLIN_SALES/aggregate?drilldown=year.QUATER|site&cut=year.YEAR_BEG_DT:date'2012\-01\-01'|site:0-4
 Presto可以作为数据仓库,能够连接多种数据库和NoSql,同时查询性能很高;
Superset提供了Presto连接,方便数据可视化和dashboard生成。
基于Presto和superset搭建数据分析平台。
Presto可以作为数据仓库,能够连接多种数据库和NoSql,同时查询性能很高;
Superset提供了Presto连接,方便数据可视化和dashboard生成。
基于Presto和superset搭建数据分析平台。 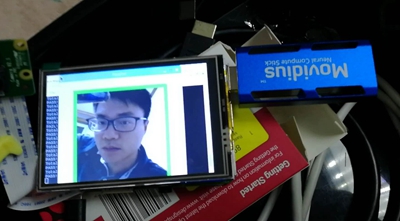 本文将描述基于raspberry 3B + movidius作为硬件平台,TensorFlow facenet作为模型实现人脸识别。
本文将描述基于raspberry 3B + movidius作为硬件平台,TensorFlow facenet作为模型实现人脸识别。  浙公网安备 33010602011771号
浙公网安备 33010602011771号