web DevOps / disk lvm / disk partition / disk mount / disk io / MBR / GPT / KB / MB / TB / PB / EB / ZB / YB / BB
s
- 磁盘大小单位
1B(Byte 字节)=8bit,
1KB (Kilobyte 千字节)=1024B,
1MB (Megabyte 兆字节 简称“兆”)=1024KB,
1GB (Gigabyte 吉字节 又称“千兆”)=1024MB,
1TB (Trillionbyte 万亿字节 太字节)=1024GB,其中1024=2^10 ( 2 的10次方),
1PB(Petabyte 千万亿字节 拍字节)=1024TB,
1EB(Exabyte 百亿亿字节 艾字节)=1024PB,
1ZB (Zettabyte 十万亿亿字节 泽字节)= 1024 EB,
1YB (Yottabyte 一亿亿亿字节 尧字节)= 1024 ZB,
1BB (Brontobyte 一千亿亿亿字节)= 1024 YB
-
1.1 Linux中新硬盘经历哪些步骤才能存储文档? 识别硬盘--->划分分区--->格式化--->挂载使用 1.2 分区模式分为哪两种? MSDOS(MBR) GPT 1.3 MBR常见的分区类型有那三种? 主分区 扩展分区 逻辑分区 1.4 fdisk命令如何划分新的分区,指令是? n 1.5 parted命令指定分区模式与划分新分区的指令分别是什么? mktable mkpart 1.6 刷新分区表命令是什么? partprobe 1.7 格式化分区命令是什么?格式化ext4文件系统的命令?格式化xfs文件系统的命令? mkfs.ext4 mkfs.xfs 1.8 格式化交换分区的命令是什么?启用交换分区的命令是什么?如何查看交换分区成员? mkswap swapon swapon 1.9 查看文件系统类型的命令是什么? blkid 1.10 如何在开机状态下,检测/etc/fstab文件中是否书写正确,命令是? mount -a swapon -a 1.11 如何挂载一个iso镜像文件?镜像文件它的类型是什么? mount -o loop iso9660 1.12 查看磁盘的使用情况命令是什么? df -h 1.13 开机挂载配置文件是什么? /etc/fstab 1.14 开机挂载配置文件六个字段分别为什么? 设备名 挂载点 文件系统类型 参数 0 0
- 逻辑卷管理
-
[root@r8-clone1 ~]# pv pvchange pvck pvcreate pvdisplay pvmove pvremove pvresize pvs pvscan [root@r8-clone1 ~]# vg vgcfgbackup vgconvert vgextend vgmerge vgrename vgcfgrestore vgcreate vgimport vgmknodes vgs vgchange vgdisplay vgimportclone vgreduce vgscan vgck vgexport vgimportdevices vgremove vgsplit [root@r8-clone1 ~]# lv lvchange lvdisplay lvmconfig lvmdump lvmsadc lvremove lvs lvconvert lvextend lvmdevices lvm_import_vdo lvmsar lvrename lvscan lvcreate lvm lvmdiskscan lvmpolld lvreduce lvresize
[root@r8-clone1 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
vda 252:0 0 50G 0 disk
├─vda1 252:1 0 1G 0 part /boot
└─vda2 252:2 0 49G 0 part
├─rl-root 253:0 0 45G 0 lvm /
└─rl-swap 253:1 0 4G 0 lvm [SWAP]
vdb 252:16 0 80G 0 disk
├─vdb1 252:17 0 10G 0 part
├─vdb2 252:18 0 10G 0 part
├─vdb3 252:19 0 10G 0 part
├─vdb4 252:20 0 1K 0 part
├─vdb5 252:21 0 20G 0 part
└─vdb6 252:22 0 20G 0 part
[root@r8-clone1 ~]# vgcreate systemvg /dev/vdb[1-2] # 创建卷组名称 systemvg
Physical volume "/dev/vdb1" successfully created.
Physical volume "/dev/vdb2" successfully created.
Volume group "systemvg" successfully created
[root@r8-clone1 ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/vda2 rl lvm2 a-- <49.00g 0
/dev/vdb1 systemvg lvm2 a-- <10.00g <10.00g
/dev/vdb2 systemvg lvm2 a-- <10.00g <10.00g
[root@r8-clone1 ~]# vgs
VG #PV #LV #SN Attr VSize VFree
rl 1 2 0 wz--n- <49.00g 0
systemvg 2 0 0 wz--n- 19.99g 19.99g
[root@r8-clone1 ~]# lvcreate -L 16G -n vo systemvg # systemvg卷组名称,vo表示逻辑卷名称,-L 表示大小,n表示名称 ,建立逻辑卷(LV)格式:lvcreate -L 大小G -n 逻辑卷名字 卷组名称
Logical volume "vo" created.
[root@r8-clone1 ~]# vgs # 查看卷组信息
VG #PV #LV #SN Attr VSize VFree
rl 1 2 0 wz--n- <49.00g 0
systemvg 2 1 0 wz--n- 19.99g 3.99g
[root@r8-clone1 ~]# lvs # 查看逻辑卷信息
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
root rl -wi-ao---- <45.04g
swap rl -wi-ao---- <3.96g
vo systemvg -wi-ao---- 16.00g
[root@r8-clone1 ~]# pvs # 查看逻辑卷信息
PV VG Fmt Attr PSize PFree
/dev/vda2 rl lvm2 a-- <49.00g 0
/dev/vdb1 systemvg lvm2 a-- <10.00g 0
/dev/vdb2 systemvg lvm2 a-- <10.00g 3.99g
[root@r8-clone1 ~]# ll /dev/systemvg/vo # 名称的快捷方式
lrwxrwxrwx. 1 root root 7 9月 11 10:33 /dev/systemvg/vo -> ../dm-2
[root@r8-clone1 ~]# ls /dev/dm-0
/dev/dm-0
[root@r8-clone1 ~]# ls /dev/dm-1
/dev/dm-1
[root@r8-clone1 ~]# ls /dev/dm-2
/dev/dm-2
[root@r8-clone1 ~]# ll /dev/rl/root
lrwxrwxrwx. 1 root root 7 9月 11 09:05 /dev/rl/root -> ../dm-0
[root@r8-clone1 ~]# ll /dev/rl/swap
lrwxrwxrwx. 1 root root 7 9月 11 09:05 /dev/rl/swap -> ../dm-1
[root@r8-clone1 ~]# mkfs.xfs /dev/systemvg/vo # 格式化文件系统类型
[root@r8-clone1 ~]# echo "/dev/systemvg/vo /mylv xfs defaults 0 0" >> /etc/fstab # 添加挂载盘到启动项
[root@r8-clone1 ~]# mkdir /mylv
[root@r8-clone1 ~]# mount -a # 没有输出表示挂载ok
[root@r8-clone1 ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 1.8G 0 1.8G 0% /dev
tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs 1.9G 9.4M 1.9G 1% /run
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
/dev/mapper/rl-root 46G 6.1G 39G 14% /
/dev/vda1 1014M 255M 760M 26% /boot
tmpfs 374M 32K 374M 1% /run/user/1000
/dev/mapper/systemvg-vo 16G 147M 16G 1% /mylv
[root@r8-clone1 ~]# more /etc/fstab # 查看挂载盘配置
# /etc/fstab
# Created by anaconda on Mon Sep 4 01:10:39 2023
#
# Accessible filesystems, by reference, are maintained under '/dev/disk/'.
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info.
#
# After editing this file, run 'systemctl daemon-reload' to update systemd
# units generated from this file.
#
/dev/mapper/rl-root / xfs defaults 0 0
UUID=f7fbc437-5896-47c6-9964-64c7f8bf3523 /boot xfs defaults 0 0
/dev/mapper/rl-swap none swap defaults 0 0
/dev/systemvg/vo /mylv xfs defaults 0 0
[root@r8-clone1 ~]# blkid /dev/mapper/systemvg-vo #查看文件系统类型
/dev/mapper/systemvg-vo: UUID="225bd91c-27c4-4904-be9c-fa33d1db7123" BLOCK_SIZE="512" TYPE="xfs"
[root@r8-clone1 ~]# lvextend -L 18G /dev/systemvg/vo # 文件系统,新扩增到18G
Size of logical volume systemvg/vo changed from 16.00 GiB (4096 extents) to 18.00 GiB (4608 extents).
Logical volume systemvg/vo successfully resized.
[root@r8-clone1 ~]# lvs | grep vo
vo systemvg -wi-ao---- 18.00g
[root@r8-clone1 ~]# df -h # 这里原有16G可使用空间,剩余2G空间没加上,原因是还没刷新空间
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 1.8G 0 1.8G 0% /dev
tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs 1.9G 9.4M 1.9G 1% /run
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
/dev/mapper/rl-root 46G 6.1G 39G 14% /
/dev/vda1 1014M 255M 760M 26% /boot
tmpfs 374M 32K 374M 1% /run/user/1000
/dev/mapper/systemvg-vo 16G 147M 16G 1% /mylv
[root@r8-clone1 ~]# xfs_growfs /dev/systemvg/vo # 刷新文件使用空间为18G
[root@r8-clone1 ~]# df -h /mylv # 更新为18G
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/systemvg-vo 18G 161M 18G 1% /mylv
- 逻辑卷管理、逻辑卷扩展、文件系统刷新、逻辑卷删除、VDO
- 逻辑卷补充
| 序号 | 项目 | 描述 | 备注 |
| 1 |
逻辑卷支持缩减 |
xfs文件系统:不支持缩减 ext4文件系统:支持缩减 |
|
| 2 |
卷组划分空间的单位 PE |
默认1个PE的大小为4M,PE Size 4.00 MiB | 可设1MB |
| 3 | [root@r8-clone1 ~]# vgdisplay systemvg #显示卷组的详细信息 | ||
| 4 |
- 逻辑卷的删除
[root@localhost ~]# lvremove /dev/systemvg/vo # 删除逻辑卷的前提:不能删除正在挂载使用的逻辑卷
Logical volume systemvg/vo contains a filesystem in use.
[root@localhost ~]# umount /mylv # 要先卸载挂载盘
[root@localhost ~]# lvremove /dev/systemvg/vo
Do you really want to remove active logical volume systemvg/vo? [y/n]: y
Logical volume "vo" successfully removed
[root@localhost ~]# lvs # 查看当前系统的所逻辑卷
[root@localhost ~]# vim /etc/fstab # 仅删除vo开机自动挂载
[root@localhost ~]# lvremove /dev/systemvg/lvredhat # 删除指定逻辑卷
Do you really want to remove active logical volume systemvg/lvredhat? [y/n]: y
Logical volume "vo" successfully removed
[root@svr1 ~]# lvs # 查看逻辑卷 , 删除卷组的前提:基于此卷组创建的所有逻辑卷,要全部删除
[root@svr1 ~]# vgremove systemvg # 删除卷组
[root@svr1 ~]# vgs # 查看当前系统的所有卷组信息
[root@svr1 ~]# pvremove /dev/vdb{1,2,3,5,6} # 删除物理卷,4为1kb逻辑,没有做vg,不需删除
[root@svr1 ~]# pvs # 查看当前系统的所有物理卷信息-
GPT:分区模式
- 全局唯一标识分区表
- 突破固定大小64字节的分区表限制
- 可以支持4个以上的主分区,最大支持18EB 容量 1EB = 1024PB = 1024×1024 TB
[root@r8-clone ~]# df -T -h # 查看文件系统类型 文件系统 类型 容量 已用 可用 已用% 挂载点 devtmpfs devtmpfs 1.8G 0 1.8G 0% /dev tmpfs tmpfs 1.9G 0 1.9G 0% /dev/shm tmpfs tmpfs 1.9G 9.3M 1.9G 1% /run tmpfs tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup /dev/mapper/rl-root xfs 46G 6.1G 39G 14% / /dev/vdb2 xfs 2.0G 47M 2.0G 3% /mypart2 /dev/vdb5 xfs 2.0G 47M 2.0G 3% /mypart5 /dev/vdb1 ext4 2.0G 6.0M 1.8G 1% /mypart1 /dev/vda1 xfs 1014M 255M 760M 26% /boot tmpfs tmpfs 374M 12K 374M 1% /run/user/42 tmpfs tmpfs 374M 0 374M 0% /run/user/0 /dev/vdd1 xfs 2.0G 47M 2.0G 3% /mypart6
- lsblk 查看挂载盘 + 挂载使用情况
[root@r8-clone ~]# lsblk # lsblk 查看挂载盘 + 挂载使用情况 NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 1024M 0 rom vda 252:0 0 50G 0 disk ├─vda1 252:1 0 1G 0 part /boot └─vda2 252:2 0 49G 0 part ├─rl-root 253:0 0 45G 0 lvm / └─rl-swap 253:1 0 4G 0 lvm [SWAP] vdb 252:16 0 20G 0 disk ├─vdb1 252:17 0 2G 0 part /mypart1 ├─vdb2 252:18 0 2G 0 part /mypart2 ├─vdb3 252:19 0 2G 0 part ├─vdb4 252:20 0 1K 0 part ├─vdb5 252:21 0 2G 0 part /mypart5 ├─vdb6 252:22 0 2G 0 part └─vdb7 252:23 0 10G 0 part vdc 252:32 0 20G 0 disk vdd 252:48 0 20G 0 disk ├─vdd1 252:49 0 2G 0 part /mypart6 ├─vdd2 252:50 0 2G 0 part ├─vdd3 252:51 0 2G 0 part ├─vdd4 252:52 0 2G 0 part ├─vdd5 252:53 0 2G 0 part └─vdd6 252:54 0 10G 0 part vde 252:64 0 20G 0 disk [root@r8-clone ~]# cat /etc/fstab # 查看挂载环境 # # /etc/fstab # Created by anaconda on Mon Sep 4 01:10:39 2023 # # Accessible filesystems, by reference, are maintained under '/dev/disk/'. # See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info. # # After editing this file, run 'systemctl daemon-reload' to update systemd # units generated from this file. # /dev/mapper/rl-root / xfs defaults 0 0 UUID=f7fbc437-5896-47c6-9964-64c7f8bf3523 /boot xfs defaults 0 0 /dev/mapper/rl-swap none swap defaults 0 0 /dev/vdb1 /mypart1 ext4 defaults 0 0 /dev/vdb2 /mypart2 xfs defaults 0 0 /dev/vdb5 /mypart5 xfs defaults 0 0 /dev/vdd1 /mypart6 xfs defaults 0 0
- swap 交换空间的增加和减少配置
[root@r8-clone ~]# lsblk # 查看磁盘空间情况,指定盘为swap [root@r8-clone ~]# mkswap /dev/vdd2 # 格式化文件交换系统 [root@r8-clone ~]# blkid /dev/vdd2 # 查看文件系统类型,是否为swap [root@r8-clone ~]# swapon # 查看你交换组成员信息 [root@r8-clone ~]# swapon /dev/vdd2 # 启用交换分区 [root@r8-clone ~]# swapon # 查看你交换组成员信息 [root@r8-clone ~]# free -h # 查看交换空间总共大小 [root@r8-clone ~]# swapoff /dev/vdd2 # 停用交换分区 [root@r8-clone ~]# swapon # 查看交换空间组成员信息 [root@r8-clone ~]# free -h # 查看交换空间总共的大小
- virsh
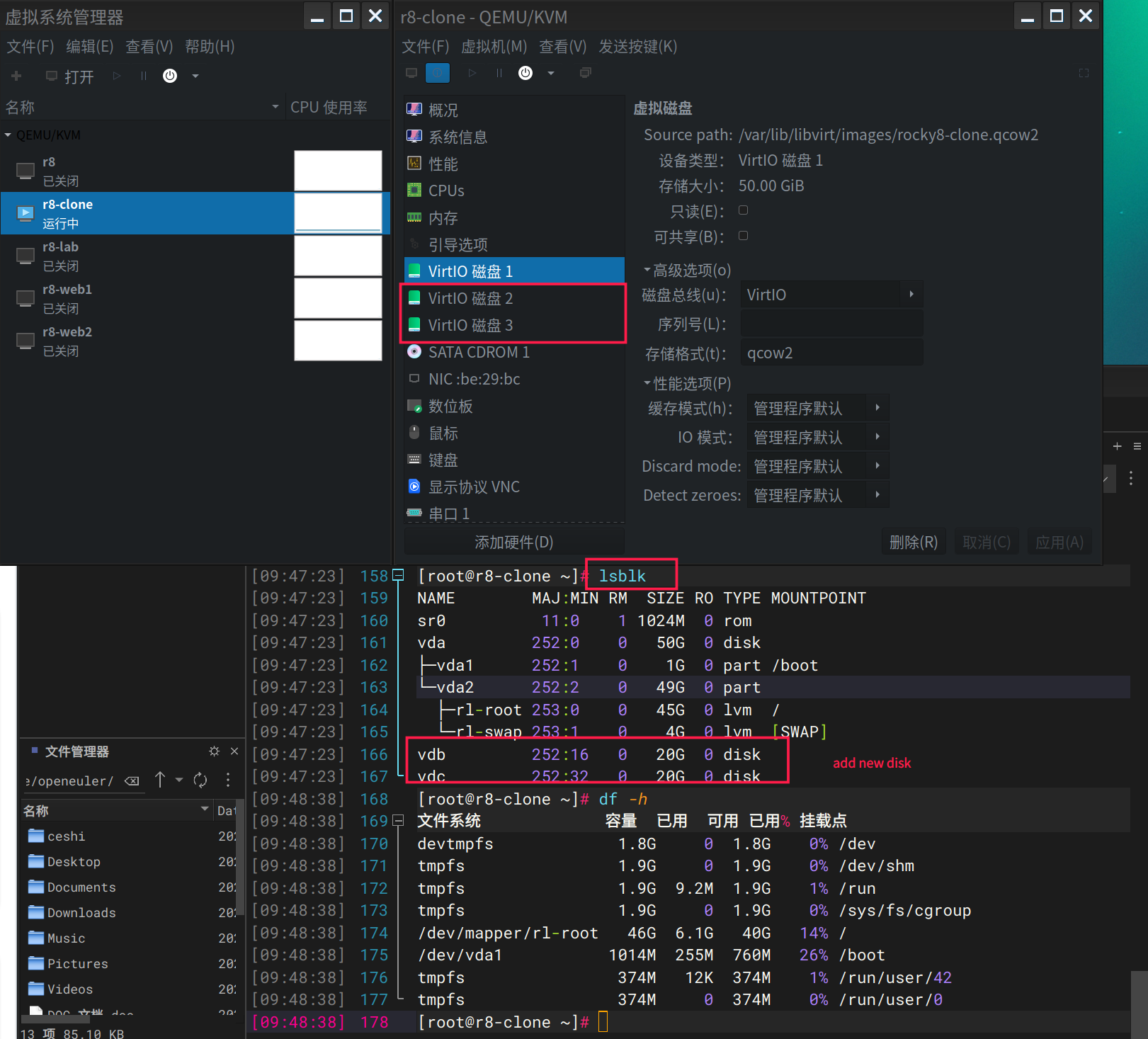
- 下图分区了3个主分区 ,1个扩展分区,3个逻辑分区,格式化了2块盘并挂载
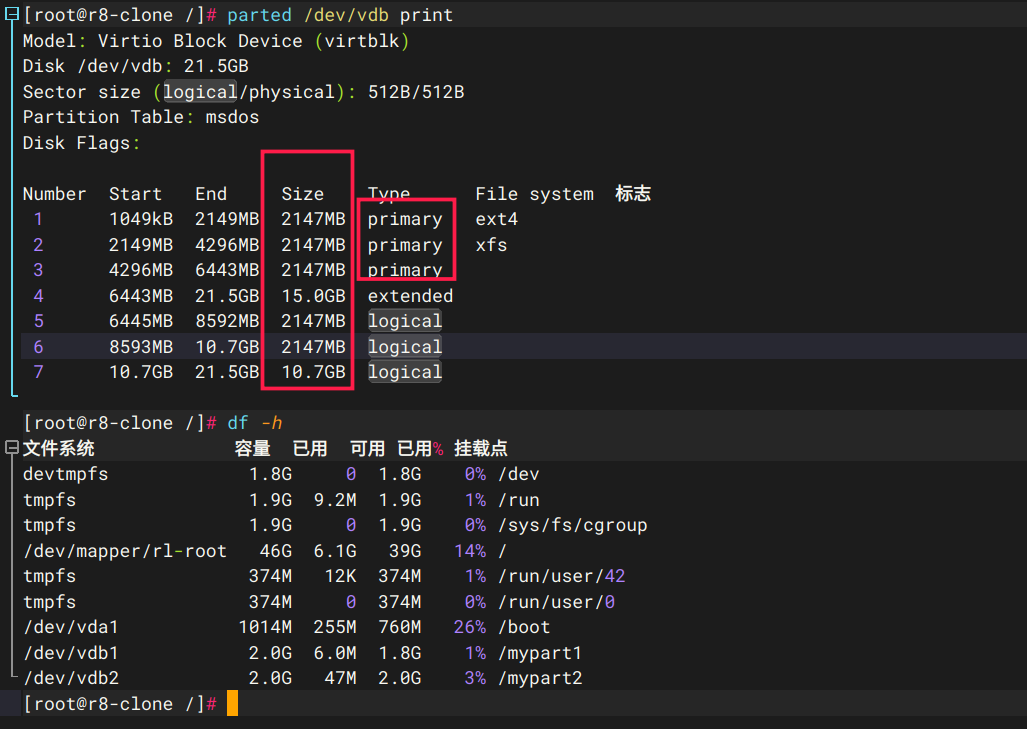
LVM逻辑分区的优缺点与步骤 , https://www.cnblogs.com/tianfen/p/11050916.html
一、LVM简介
1. 什么是LVM?
LVM是 Logical Volume Manager(逻辑卷管理)的简写
2. 为什么使用LVM?
LVM通常用于装备大量磁盘的系统,但它同样适于仅有一、两块硬盘的小系统。
-----小系统使用LVM的益处:传统的文件系统:一个文件系统对应一个分区,直观,但不易改变,不同的分区相对独立,无相互联系,各分区空间常常利用不平衡,空间不能充分利用。当一个文件系统/分区已满时,无法对其扩充,只能采用重新分区/建立文件系统,非常麻烦,或把分区中的数据移到另一个更大的分区中;或采用符号连接的方式使用其它分区的空间。如果要把硬盘上的多个分区合并在一起使用,只能采用再分区的方式,这个过程需要数据的备份与恢复。采用LVM:硬盘的多个分区由LVM统一为卷组管理,可以方便的加入或移走分区以扩大或减小卷组的可用容量,充分利用硬盘空间;文件系统建立在逻辑卷上,而逻辑卷可根据需要改变大小(在卷组容量范围内)以满足要求,可以跨分区。
----大系统使用LVM的益处:在使用很多硬盘的大系统中,使用LVM主要是方便管理、增加了系统的扩展性。用户/用户组的空间建立在LVM上,可以随时按要求增大,或根据使用情况对各逻辑卷进行调整。当系统空间不足而加入新的硬盘时,不必把用户的数据从原硬盘迁移到新硬盘,而只须把新的分区加入卷组并扩充逻辑卷即可。同样,使用LVM可以在不停服务的情况下。把用户数据从旧硬盘转移到新硬盘空间中去。
3 优点:可随时按需求改变逻辑卷大小,充分利用硬盘空间。
二、LVM原理
传统文件系统,比如这个盘只有300G,那么建立在这个300G上面的文件系统最多只能用到300G,但是有了LVM这个功能后,我们建立文件系统的盘就不是建立在物理盘上,而是建立在一个叫LV逻辑卷上面,这个卷是一个逻辑概念不是物理盘,空间可能大于一个物理盘,也可能小于一个物理盘。而且这个LV逻辑卷的空间可以扩展和缩小,这样就给上层的文件系统提供了更好的支持。
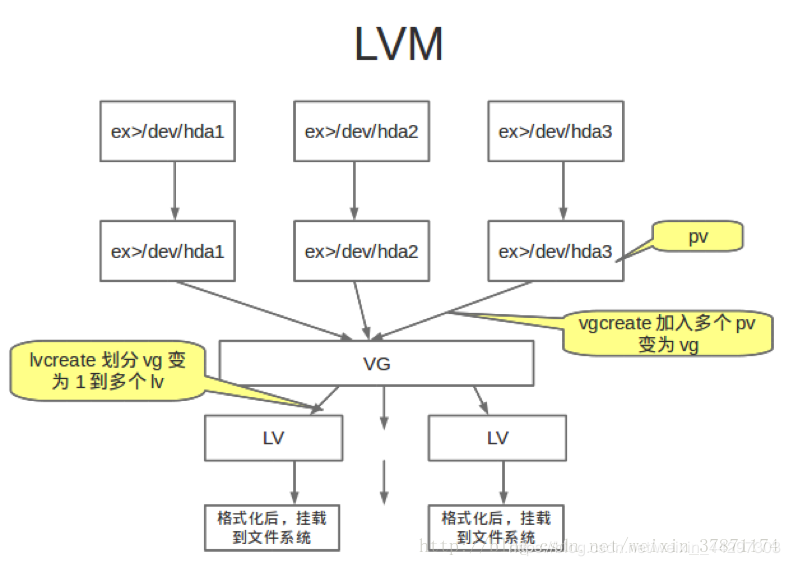
需要理解的几个概念:
PV(Physical Volume):物理空间的意思,其实就是指一个分区(如/dev/sdb1 )或者是一个盘(如/dev/sdb)
VG(Volume Group):相当于一个Pool,由多个PV组成的pool
LV(Logical Volume):用来建立一个文件系统的空间,这个空间来源于VG,大小随意,可以扩展。(比如/dev/mapper/rhel-root这个目录其实是一个文件系统挂载点,这个点就是承载在一个LV上,这个文件系统的大小就是这个LV的大小。 )
原理图:
三、LVM实验
1)创建PV,VG,LV的指令

创建物理卷
pvcreate /dev/vdb1 ##创建物理卷/dev/vdb1
创建物理卷组
vgcreate vg0 /dev/vdb1 ##创建物理卷组vg0
创建逻辑卷
lvcreate -L 300M -n lv0 vg0 ##在vg0卷组上创建名为lv0,大小为300M的逻辑卷
(-L指定创建的LV大小,-l指定创建的LV的PE数量,-n是LV的名字)
2)创建一个逻辑卷(操作展示)
[root@localhost ~]# fdisk /dev/vda
将分区类型改为LVM:

创建步骤:
[root@localhost ~]# pvcreate /dev/vdb1 ##创建物理卷
[root@localhost ~]# vgcreate vgbox /dev/vdb1
[root@localhost ~]# lvcreate -L 499G -n lgbox vgbox ##在卷组vgbox上创建名为lgbox,大小为499G的逻辑卷
[root@localhost ~]# mkfs.ext4 /dev/vgbox/lgbox ##格式化逻辑卷并改系统格式为ext4
[root@localhost ~]# mount /dev/vgbox/lgbox /data ##挂载【linux下的文件系统需要被挂载后才能使用】
[root@localhost ~]# vim /etc/fstab #添加对应的挂载信息
/dev/vgbox/lgbox /data ext4 defaults 0 0
[root@localhost ~]# mount -a #加载挂载点,然后df -h即可看到挂载信息了
[root@localhost ~]# df -h
监控命令: watch -n 1 ‘pvs;echo ===;vgs;echo ===;lvs;echo ===;df -h /data/’
3)扩容
a)xfs系统中的扩容:
情况一:vg足够扩展
[root@localhost ~]# lvextend -L 500M /dev/vg0/lv0 ##扩展逻辑卷空间到500M
[root@localhost ~]# xfs_growfs /dev/vg0/lv0 ##扩展文件系统
1
2
情况二:vg不够拉伸,得先扩大设备再扩大系统
扩大设备:
[root@localhost ~]# pvcreate /dev/vdb2 ##创建物理卷/dev/vdb2
[root@localhost ~]# vgextend vg0 /dev/vdb2 ##将新的物理卷vdb2添加到现有的卷组vg0
扩展逻辑卷
[root@localhost ~]# lvextend -L 1500M /dev/vg0/lv0 ##增加逻辑卷空间到1500M
[root@localhost ~]# xfs_growfs /dev/vg0/lv0
b)ext4系统的扩容
[root@localhost ~]# umount /mnt ##先卸载
[root@localhost ~]# mkfs.ext4 /dev/vg0/lv0 ##格式化逻辑卷 ,并改系统为ext4
[root@localhost ~]# mount /dev/vg0/lv0 /mnt/ ##挂载
[root@localhost ~]# lvextend -L 1800M /dev/vg0/lv0 ##增加逻辑卷空间
Extending logical volume lv0 to 1.76 GiB Logical volume lv0 successfully resized
[root@localhost ~]# resize2fs /dev/vg0/lv0 ##更新逻辑卷信息
4)缩减逻辑卷空间
[root@localhost ~]# umount /mnt ##先卸载
[root@localhost ~]# e2fsck -f /dev/vg0/lv0 ##扫描逻辑卷上的空余空间
[root@localhost ~]# resize2fs /dev/vg0/lv0 1000M ##设备文件减少到1000M
[root@localhost ~]# lvreduce -L 1000M /dev/vg0/lv0 ##将逻辑卷减少到1000M
[root@localhost ~]# mount /dev/vg0/lv0 /mnt ##挂载
5)缩减vg:(迁移到闲置设备)
[root@localhost ~]# pvmove /dev/vdb1 /dev/vdb2 ##将vdb1的空间数据转移到vdb2
/dev/vdb1: Moved: 88.0%
/dev/vdb1: Moved: 100.0% ##转移数据成功
[root@localhost ~]# vgreduce vg0 /dev/vdb1 ##将/dev/vdb1分区从vg0卷组中移除
Removed "/dev/vdb1" from volume group "vg0"
[root@localhost ~]# pvremove /dev/vdb1 ##把/dev/vdb1分区从系统中删除
Labels on physical volume "/dev/vdb1" successfully wiped
注意:将vdb1的空间数据转移到vdb2时,要确保vdb2的足够的空间能将vdb1的数据转移,否则需要先将vdb1缩减。
6)LVM快照创建
[root@localhost ~]# touch /mnt/file{1..5}
[root@localhost ~]# lvcreate -L 50M -n lv0backup -s /dev/vg0/lv0 ##建立一个50M的快照
[root@localhost ~]# mount /dev/vg0/lv0backup /mnt ##挂载快照
[root@localhost ~]# cd /mnt
[root@localhost mnt]# ls
[root@localhost mnt]# rm -fr * ##删除所有文件
[root@localhost mnt]# cd
[root@localhost ~]# umount /mnt
[root@localhost ~]# lvremove /dev/vg0/lv0backup ##删除快照
[root@localhost ~]# lvcreate -L 50M -n lv0backup -s /dev/vg0/lv0 ##重建快照
[root@localhost ~]# mount /dev/vg0/lv0backup /mnt ##挂载快照
[root@localhost ~]# ls /mnt ##又可以看到之前建立的文件
结论: LVM的快照可以将某一时刻的信息记录到快照区中,因此,可以利用这一特点对数据做完全备份。
7)删除设备[root@localhost ~]# umount /mnt ##卸载
[root@localhost ~]# df
[root@localhost ~]# lvremove /dev/vg0/lv0backup ##删除快照
[root@localhost ~]# lvremove /dev/vg0/lv0 ##删除逻辑卷
[root@localhost ~]# vgremove vg0 ##删除物理卷组
[root@localhost ~]# pvremove /dev/vdb{1..2} ##删除物理卷
总结
LVM虽然很好用,但是因为在硬件上使用纯软件方式进行管理,所以误删除数据恢复更加困难,LVM缩减分区大小风险较大,并不推荐使用LVM对磁盘分区进行管理。
参考链接:https://blog.csdn.net/weixin_44297303/article/details/87065544
RedHat Linux LVM LVM - 很好很强大 ,http://www.iteye.com/topic/283065
LVM (Logic Volume Management,逻辑卷管理),是传统商业Unix就带有的一项高级磁盘管理工具,异常强大。后来LVM移植到了Linux操作系统上,尽管不像原 来Unix版本那么强大,但瘦死的骆驼比马大,Linux的LVM仍然非常强大,可以在生产运行系统上面直接在线扩展硬盘分区,可以把分区umount以 后收缩分区大小,还可以在系统运行过程中把一个分区从一块硬盘搬到另一块硬盘上面去等等,简直就像变魔术,而且这一切都可以在一个繁忙运行的系统上面直接 操作,不会对你的系统运行产生任何影响,很安全。
还是拿JavaEye的网站服务器随便举个小例子吧。话说今天晚上我登录JavaEye网站服务器随便这么一查看磁盘使用状况:
- df -h
df -h竟然发现/home分区的磁盘消耗的很快
- Filesystem Size Used Avail Use% Mounted on
- /dev/mapper/system-home 40G 32G 8G 80% /home
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/system-home 40G 32G 8G 80% /home有点出乎意料,已经使用了80%,如果用光了,可就有点麻烦了,所以为了安全,把/home分区扩大5GB,多给它点硬盘空间,敲入两条shell命令
- lvextend -L +5G /dev/system/home
- resize_reiserfs -s +5G /dev/system/home
lvextend -L +5G /dev/system/home
resize_reiserfs -s +5G /dev/system/home 先把逻辑卷扩大5GB,再把上面的reiserfs文件系统扩大5GB,前后耗时不超过3秒钟。再df -h查看一下:
- Filesystem Size Used Avail Use% Mounted on
- /dev/mapper/system-home 45G 32G 13G 71% /home
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/system-home 45G 32G 13G 71% /home哈哈,/home立刻多了5GB,搞定收工,这是不是很像变戏法,我没停任何服务,没重起服务器,大家没有任何感觉,就一切搞定,说实话我也一直 觉得LVM很cool,所以我一直是LVM+Reiserfs的忠实拥趸。有兴趣学习LVM的同学可以下载后面的附件,这可是我珍藏多年的LVM秘籍!
另外强烈推荐Daniel Robbins在IBM DW网站上面关于LVM的系列文章:
通用线程: 学习 Linux LVM,第 1 部分
通用线程:学习 Linux LVM,第 2部分
另外,在大规模的生产系统上面,文件系统的管理是一个错综复杂的工作,如果你对这个方面的知识很感兴趣,你可以继续了解一下 EVMS(Enterprise Volume Management System,企业级文件卷管理系统)。EVMS 为 Linux 下的所有存储技术提供了统一的、可扩展的、基于插件的 API。这意味着什么?它意味着由于 EVMS,您可以使用单个工具来对磁盘分区、创建 LVM 对象以及甚至创建 Linux 软件 RAID 卷。并且可以使用这一工具以强有力的方式合并这些技术。还是推荐看Daniel Robbins的文章:
通用线程: 高级文件系统实现者指南,第 12 部分 EVMS 简介
通用线程: 高级文件系统实现者指南,第 13 部分EVMS 详情
BTW:Daniel Robbins在IBM DW所有的文章都值得一读,特别是《通用线程: 高级文件系统实现者指南》这个系列。
- lvm_whitepaper.zip (335.8 KB)
RedHat Linux Disk mount / 翟翔(13110508)
磁盘状态为加载过,分两种情况:
A、虚拟机删除,数据盘未删除;
B、虚拟机迁移,原物理机上数据盘未删除。
umount 的时候报错:device is busy
http://liuyu.blog.51cto.com/183345/64044
umount: /mnt/usbdisk: device is busy
No automatic removal. Please use umount /mnt/usbdisk
linux分区知识与大磁盘的分区,http://www.iteye.com/topic/521107
MBR ,主引导记录 (Master Boot Record),也就是我们常见的分区方法,不过管理员外的最终用户很少知道它的存在,MBR 分区的标准决定了 MBR 只支持在2TB以下 (超过 2TB 的只能管理 2TB) 的硬盘中创建4个分区表项,要获得更多分区,需要次级结构–扩展分区。扩展分区可以再次被分成一个或多个逻辑磁盘,也就是普通情况下的C盘以外的盘,或说 第一个分区以外的部分,有些情况下 Windows 里的C盘可能会是一个逻辑分区。
EFI ,可扩展固件接口 (Extensible Firmware Interface),由英特尔 (Intel) 公司提出的一种替代 BIOS 的升级方案。 EFI 的位置很特殊,它不像是 BIOS 那样自己即是固件又是接口,EFI 只是一个接口,位于操作系统与平台固件之间,感觉像是公司、CEO、CEO秘书之间的关系一样,由CEO (操作系统) 下任务,CEO秘书 (EFI) 负责把任务分配下发到公司各部门经理 (平台固件),经理们又把任务下发到具体的小组 (各类硬件) 去完成。
GPT ,全局唯一标识磁盘分区表 (GUID Partition Table),GUID,全局唯一标识符 (Globally Unique Identifier) 。GUID 分区表 (GPT) 是作为 Extensible Firmware Interface (EFI) 计划的一部分引入的。当然,你也可以在 BIOS 的PC中使用 GPT 分区,虽然 GPT 来自以 EFI 计划,但并不依赖于 EFI。GPT 相对于以往 PC 普遍使用的主引导记录 (MBR) 分区方案更加灵活。比如可以超过 MBR 分区表项4个的限制,在 GPT 规范里对分区的数量几乎是没有限制的,大家在网上可以查到的128个实际上是 Windows 系统 (支持 GPT 的 Windows) 做出的限制。 GPT 对可管理磁盘大小也超过了 MBR 的2TB (1TB = 1024GB) 而达到了 18EB (1EB = 1024TB) 。在 MBR 分区方案中操作系统的引导是通过放在磁盘最开始 (第一扇区) 里的 MBR (这里的 MBR 是指主引导记录,而不是主引导记录分区方案,两者是同名的。我的猜测是为了与 GPT 分区方案区分,使用了主引导记录引导方式的名字 MBR 来命名此种分区方案,我查不到确切的资料正明我的猜测是否正确,只能大家努力区分一下了。) 。把重要的信息 (如分区信息、目录等) 放在某个扇区里是 MBR 分区方案的方法,而 GPT 把这个信息放到了分区里,Intel的解释是这样可以更加明确更加安全。 GPT 分区为了保护自己不受 MBR 方案下磁盘管理软件的危害,在磁盘的最开始位置 (第一个扇区) 建立了一个保护分区 (Protective MBR),这种分区的类型标识为 0xEE。苹果系统 (Mac OS X) 下这个保护分区大小为 200MB,这个分区在 Window NT 磁盘管理器里名字叫做 GPT 保护分区。这个分区可以让不能识别 GPT 的磁盘管理软件把 GPT 磁盘看成一个未知格式的分区,而不是错误地当成一个未分区的磁盘。
以下信息出自:维基百科
ext3
块尺寸 最大文件尺寸 最大文件系统尺寸
1KiB 16GiB 2TiB
2KiB 256GiB 8TiB
4KiB 2TiB 16TiB
8KiB 16TiB 32TiB
ext4
Extents
ext4引进了Extent档案储存方式,以取代ext2/3使用的block mapping方式。Extent指的是一连串的连续实体block,这种方式可以增加大型档案的效率并减少分裂档案。ext4支援的单一Extent, 在单一block为4KB的系统中最高可达128MB[1]。单一inode中可储存4笔Extent;超过四笔的Extent会以Htree方式被索 引。
最大文件尺寸 16 TiB (for 4k block filesystem)
最大卷容量 1 EiB
xfs
最大可支持的文件大小为263 = 9 x 1018 = 9 exabytes,最大文件系统尺寸为18 exabytes。
ReiserFS
最大文件尺寸 8 TiB
最大卷容量 16 TiB
Linux LVM-逻辑卷管理 / Apache Traffic Server / ATS Cache Server , http://wiki.cns*****.com/pages/viewpage.action?pageId=17403026
Linux LVM-逻辑卷管理
场景:
CDN节点上安装完ats(Apache Trafficserver)后,配置ats,需要指定一个大的磁盘用来存放cache。根据服务器的分区情况,分两种操作
1、查看磁盘分区:
http://dl2.iteye.com/upload/attachment/0101/0028/30f34a85-0583-397c-a399-07cae20a40ef.png

存在一个独立的大磁盘分区挂载到/cache 目录,此时只需要将ats的cache目录配置为: /cache 350G
2、查看磁盘分区
http://dl2.iteye.com/upload/attachment/0101/0032/5917480e-7a89-35ff-a33b-e2d2925cc46d.png

不存在足够大的分区(400G左右)供ats存放缓存
我们只能选择一个裸盘 供ats使用,默认我们选择 /dev/sda2
问题:但是使用/dev/sda2的服务器发生了问题,服务器运行一段时间后,系统down掉,解决方法:只能重装系统。
分析问题:
分析后,定位原因:
fdisk -l # fdisk -l 可以列出所有的分区,包括没有挂上的分区和usb设备,
http://dl2.iteye.com/upload/attachment/0101/0036/df8e7a47-3b58-399c-afd7-2498a1e13fb4.png

我们选择使用的 /dev/sda2 是 Id为8e,即分区的类型是 Linux LVM
=============
对Linux LVM的说明:
LVM的全称为Logical Volume Manager,它是Linux环境下对磁盘分区进行管理的一种机制,
LVM是建立在硬盘和分区之上的一个逻辑层,来提高磁盘分区管理的灵活性。
通过LVM系统管理员可以轻松管理磁盘分区,如:将若干个磁盘分区连接为一个整块的卷组(volume group),形成一个存储池。
管理员可以在卷组上随意创建逻辑卷组(logical volumes),并进一步在逻辑卷组上创建文件系统
在以往的Linux系统中(比Redhat AS4更早的版本),默认是不支持LVM逻辑卷管理的
当磁盘连接到服务器后,使用fdisk将其划分为主分区和扩展分区
随后直接把分区进行格式化,生成诸如/dev/sda1、/dev/sda2之类的分区
这些分区可以直接用mount命令挂载到目录来使用
当应用了LVM后,磁盘分区类型为Linux LVM的/dev/sda1、/dev/sda2这样的分区会被LVM认为是一整个VG,即卷组
这样的卷组是不能直接挂载的,需要由LVM转换成类似/dev/mapper/这样的VG卷组,每个VG又包含LV(逻辑卷),想要使用他们只需要将逻辑卷挂载到目录
==================
解决方法:
使用卷组查看命令vgdisplay查看卷组情况
http://dl2.iteye.com/upload/attachment/0101/0040/9b6b943f-79fb-3561-be19-a5a3a6d0ec2f.png

卷组名为:systemvg
可用大小:475G
步骤:
1、创建逻辑卷LV(Logical Volumes),命名为:cachelv,所属的卷组VG(Volume Groups)为systemvg,-L指定逻辑分区大小为400G
lvcreate -n cachelv -L 400G systemvg
2、创建文件系统
mkfs.ext4 /dev/systemvg/cachelv
3、挂载
mount /dev/systemvg/cachelv /cache
4、添加到 fstab #用fstab可以自动挂载各种文件系统格式的硬盘、分区、可移动设备和远程设备等
vi /etc/fstab
/dev/systemvg/cachelv /cache ext4 defaults 0 0
以上操作完成后,df -h 查看:

将ats的cache目录指定为 /cache 就ok了
“苏*宁公有云”项目
http://eitp.cns*****.com/itp-web-in/resourcepool/resourceInfoRead.htm?employeeid=13073414
需求描述:
1、整合苏宁上游的服务提供者和下游最终用户,打造新的价值链和生态系统。
2、与竞品京东云、阿里云等竞争,积极扩大苏宁的用户群,提升苏宁的技术实力。
3、通过公有云项目,积极参与到开源技术领域,扩大苏宁在技术行业的影响力。
解决方案描述:
1. 搭建基于Cloudstack的公有云平台,使用KVM作为虚拟化层支撑。
2. 搭建苏宁公有云平台作为自助式管理门户,提供服务。
LVM数据丢失,替换数据盘
http://wiki.cns*****.com/pages/viewpage.action?pageId=19368510
Cloudstack资料收集
Cloudstack运维及优化
Openstack部署运维
Openstack技术调研
Openstack业界动态
苏*宁私有云支撑
File Lists
苏宁公有云支撑
CS问题对应列表
RDS 问题对应列表
对象存储问题列表
系统相关
LVM数据丢失,替换数据盘 ,http://wiki.cns*****.com/pages/viewpage.action?pageId=19368510
一、缘由
在linux虚机通过LVM将数据盘拓展到了opt目录,在数据盘损坏以后,使用新的数据盘替换损坏的数据盘。
二、操作
1.卸载源数据盘、添加新数据盘
2.创建PV:pvcreate /dev/vdc
lvremove /dev/systemvg/optlv
vgreduce --removemissing systemvg
vgextend systemvg /dev/vdc
lvcreate /dev/systemvg/optlv
lvcreate -n optlv -L 79G systemvg
mkfs.ext4 /dev/systemvg/optlv
mount /dev/systemvg/optlv /opt/
3.最后重启服务器验证
小结一下linux 2.6内核的四种IO调度算法
http://jackyrong.iteye.com/blog/898938
在LINUX 2.6中,有四种关于IO的调度算法,下面综合小结一下:
linux IO调度算法 ,http://www.cnblogs.com/cutepig/p/3403711.html
1) NOOP (电梯式调度程序)
NOOP算法的全写为No Operation。该算法实现了最最简单的FIFO队列,所有IO请求大致按照先来后到的顺序进行操作。之所以说“大致”,原因是NOOP在FIFO的基础上还做了相邻IO请求的合并,并不是完完全全按照先进先出的规则满足IO请求。NOOP假定I/O请求由驱动程序或者设备做了优化或者重排了顺序(就像一个智能控制器完成的工作那样)。在有些SAN环境下,这个选择可能是最好选择。Noop 对于 IO 不那么操心,对所有的 IO请求都用 FIFO 队列形式处理,默认认为 IO 不会存在性能问题。这也使得 CPU 也不用那么操心。当然,对于复杂一点的应用类型,使用这个调度器,用户自己就会非常操心。
2) Deadline scheduler (截止时间调度程序)
DEADLINE在CFQ的基础上,解决了IO请求饿死的极端情况。除了CFQ本身具有的IO排序队列之外,DEADLINE额外分别为读IO和写IO提供了FIFO队列。读FIFO队列的最大等待时间为500ms,写FIFO队列的最大等待时间为5s。FIFO队列内的IO请求优先级要比CFQ队列中的高,,而读FIFO队列的优先级又比写FIFO队列的优先级高。优先级可以表示如下:
FIFO(Read) > FIFO(Write) > CFQ
deadline 算法保证对于既定的 IO 请求以最小的延迟时间,从这一点理解,对于 DSS 应用应该会是很适合的。
3) Anticipatory scheduler (预料I/O调度程序)
CFQ和DEADLINE考虑的焦点在于满足零散IO请求上。对于连续的IO请求,比如顺序读,并没有做优化。为了满足随机IO和顺序IO混合的场景,Linux还支持ANTICIPATORY调度算法。ANTICIPATORY的在DEADLINE的基础上,为每个读IO都设置了6ms
的等待时间窗口。如果在这6ms内OS收到了相邻位置的读IO请求,就可以立即满足
Anticipatory scheduler(as) 曾经一度是 Linux 2.6 Kernel 的 IO scheduler 。Anticipatory 的中文含义是”预料的, 预想的”, 这个词的确揭示了这个算法的特点,简单的说,有个 IO 发生的时候,如果又有进程请求 IO 操作,则将产生一个默认的 6 毫秒猜测时间,猜测下一个 进程请求 IO 是要干什么的。这对于随即读取会造成比较大的延时,对数据库应用很糟糕,而对于 Web Server 等则会表现的不错。这个算法也可以简单理解为面向低速磁盘的,因为那个”猜测”实际上的目的是为了减少磁头移动时间。
4)CFQ (完全公平排队I/O调度程序)
CFQ算法的全写为Completely Fair Queuing。该算法的特点是按照IO请求的地址进行排序,而不是按照先来后到的顺序来进行响应。
在传统的SAS盘上,磁盘寻道花去了绝大多数的IO响应时间。CFQ的出发点是对IO地址进行排序,以尽量少的磁盘旋转次数来满足尽可能多的IO请求。在CFQ算法下,SAS盘的吞吐量大大提高了。但是相比于NOOP的缺点是,先来的IO请求并不一定能被满足,可能会出现饿死的情况。
Completely Fair Queuing (cfq, 完全公平队列) 在 2.6.18 取代了 Anticipatory scheduler 成为 Linux Kernel 默认的 IO scheduler 。cfq 对每个进程维护一个 IO 队列,各个进程发来的 IO 请求会被 cfq 以轮循方式处理。也就是对每一个 IO 请求都是公平的。这使得 cfq 很适合离散读的应用(eg: OLTP DB)。我所知道的企业级 Linux 发行版中,SuSE Linux 好像是最先默认用 cfq 的.
查看和修改IO调度器的算法非常简单。假设我们要对sda进行操作,如下所示:
cat /sys/block/sda/queue/scheduler
echo “cfq” > /sys/block/sda/queue/scheduler
总结:
1 CFQ和DEADLINE考虑的焦点在于满足零散IO请求上。对于连续的IO请求,比如顺序读,并没有做优化。为了满足随机IO和顺序IO混合的场景,Linux还支持ANTICIPATORY调度算法。ANTICIPATORY的在DEADLINE的基础上,为每个读IO都设置了6ms的等待时间窗口。如果在这6ms内OS收到了相邻位置的读IO请求,就可以立即满足。
IO调度器算法的选择,既取决于硬件特征,也取决于应用场景。
在传统的SAS盘上,CFQ、DEADLINE、ANTICIPATORY都是不错的选择;对于专属的数据库服务器,DEADLINE的吞吐量和响应时间都表现良好。然而在新兴的固态硬盘比如SSD、Fusion IO上,最简单的NOOP反而可能是最好的算法,因为其他三个算法的优化是基于缩短寻道时间的,而固态硬盘没有所谓的寻道时间且IO响应时间非常短。
2 对于数据库应用, Anticipatory Scheduler 的表现是最差的。Deadline 在 DSS 环境表现比 cfq 更好一点,而 cfq 综合来看表现更好一些。这也难怪 RHEL 4 默认的 IO 调度器设置为 cfq. 而 RHEL 4 比 RHEL 3,整体 IO 改进还是不小的。
IO调度器的总体目标是希望让磁头能够总是往一个方向移动,移动到底了再往反方向走,这恰恰就是现实生活中的电梯模型,所以IO调度器也被叫做电梯. (elevator)而相应的算法也就被叫做电梯算法.而Linux中IO调度的电梯算法有好几种,一个叫做as(Anticipatory),一个叫做 cfq(Complete Fairness Queueing),一个叫做deadline,还有一个叫做noop(No Operation).具体使用哪种算法我们可以在启动的时候通过内核参数elevator来指定.
一)I/O调度的4种算法
1)CFQ(完全公平排队I/O调度程序)
特点:
在最新的内核版本和发行版中,都选择CFQ做为默认的I/O调度器,对于通用的服务器也是最好的选择.
CFQ试图均匀地分布对I/O带宽的访问,避免进程被饿死并实现较低的延迟,是deadline和as调度器的折中.
CFQ对于多媒体应用(video,audio)和桌面系统是最好的选择.
CFQ赋予I/O请求一个优先级,而I/O优先级请求独立于进程优先级,高优先级的进程的读写不能自动地继承高的I/O优先级.
工作原理:
CFQ为每个进程/线程,单独创建一个队列来管理该进程所产生的请求,也就是说每个进程一个队列,各队列之间的调度使用时间片来调度,
以此来保证每个进程都能被很好的分配到I/O带宽.I/O调度器每次执行一个进程的4次请求.
2)NOOP(电梯式调度程序)
特点:
在Linux2.4或更早的版本的调度程序,那时只有这一种I/O调度算法.
NOOP实现了一个简单的FIFO队列,它像电梯的工作主法一样对I/O请求进行组织,当有一个新的请求到来时,它将请求合并到最近的请求之后,以此来保证请求同一介质.
NOOP倾向饿死读而利于写.
NOOP对于闪存设备,RAM,嵌入式系统是最好的选择.
电梯算法饿死读请求的解释:
因为写请求比读请求更容易.
写请求通过文件系统cache,不需要等一次写完成,就可以开始下一次写操作,写请求通过合并,堆积到I/O队列中.
读请求需要等到它前面所有的读操作完成,才能进行下一次读操作.在读操作之间有几毫秒时间,而写请求在这之间就到来,饿死了后面的读请求.
3)Deadline(截止时间调度程序)
特点:
通过时间以及硬盘区域进行分类,这个分类和合并要求类似于noop的调度程序.
Deadline确保了在一个截止时间内服务请求,这个截止时间是可调整的,而默认读期限短于写期限.这样就防止了写操作因为不能被读取而饿死的现象.
Deadline对数据库环境(ORACLE RAC,MYSQL等)是最好的选择.
4)AS(预料I/O调度程序)
特点:
本质上与Deadline一样,但在最后一次读操作后,要等待6ms,才能继续进行对其它I/O请求进行调度.
可以从应用程序中预订一个新的读请求,改进读操作的执行,但以一些写操作为代价.
它会在每个6ms中插入新的I/O操作,而会将一些小写入流合并成一个大写入流,用写入延时换取最大的写入吞吐量.
AS适合于写入较多的环境,比如文件服务器
AS对数据库环境表现很差.
查看当前系统支持的IO调度算法
dmesg | grep -i scheduler
[root@localhost ~]# dmesg | grep -i scheduler
io scheduler noop registered
io scheduler anticipatory registered
io scheduler deadline registered
io scheduler cfq registered (default)
查看当前系统的I/O调度方法:
cat /sys/block/sda/queue/scheduler
noop anticipatory deadline [cfq]
临地更改I/O调度方法:
例如:想更改到noop电梯调度算法:
echo noop > /sys/block/sda/queue/scheduler
想永久的更改I/O调度方法:
修改内核引导参数,加入elevator=调度程序名
vi /boot/grub/menu.lst
更改到如下内容:
kernel /boot/vmlinuz-2.6.18-8.el5 ro root=LABEL=/ elevator=deadline rhgb quiet
重启之后,查看调度方法:
cat /sys/block/sda/queue/scheduler
noop anticipatory [deadline] cfq
已经是deadline了
四)I/O调度程序的测试
本次测试分为只读,只写,读写同时进行.
分别对单个文件600MB,每次读写2M,共读写300次.
1)测试磁盘读:
[root@test1 tmp]# echo deadline > /sys/block/sda/queue/scheduler
[root@test1 tmp]# time dd if=/dev/sda1 f=/dev/null bs=2M count=300
300+0 records in
300+0 records out
629145600 bytes (629 MB) copied, 6.81189 seconds, 92.4 MB/s
real 0m6.833s
user 0m0.001s
sys 0m4.556s
[root@test1 tmp]# echo noop > /sys/block/sda/queue/scheduler
[root@test1 tmp]# time dd if=/dev/sda1 f=/dev/null bs=2M count=300
300+0 records in
300+0 records out
629145600 bytes (629 MB) copied, 6.61902 seconds, 95.1 MB/s
real 0m6.645s
user 0m0.002s
sys 0m4.540s
[root@test1 tmp]# echo anticipatory > /sys/block/sda/queue/scheduler
[root@test1 tmp]# time dd if=/dev/sda1 f=/dev/null bs=2M count=300
300+0 records in
300+0 records out
629145600 bytes (629 MB) copied, 8.00389 seconds, 78.6 MB/s
real 0m8.021s
user 0m0.002s
sys 0m4.586s
[root@test1 tmp]# echo cfq > /sys/block/sda/queue/scheduler
[root@test1 tmp]# time dd if=/dev/sda1 f=/dev/null bs=2M count=300
300+0 records in
300+0 records out
629145600 bytes (629 MB) copied, 29.8 seconds, 21.1 MB/s
real 0m29.826s
user 0m0.002s
sys 0m28.606s
结果:
第一 noop:用了6.61902秒,速度为95.1MB/s
第二 deadline:用了6.81189秒,速度为92.4MB/s
第三 anticipatory:用了8.00389秒,速度为78.6MB/s
第四 cfq:用了29.8秒,速度为21.1MB/s
2)测试写磁盘:
[root@test1 tmp]# echo cfq > /sys/block/sda/queue/scheduler
[root@test1 tmp]# time dd if=/dev/zero f=/tmp/test bs=2M count=300
300+0 records in
300+0 records out
629145600 bytes (629 MB) copied, 6.93058 seconds, 90.8 MB/s
real 0m7.002s
user 0m0.001s
sys 0m3.525s
[root@test1 tmp]# echo anticipatory > /sys/block/sda/queue/scheduler
[root@test1 tmp]# time dd if=/dev/zero f=/tmp/test bs=2M count=300
300+0 records in
300+0 records out
629145600 bytes (629 MB) copied, 6.79441 seconds, 92.6 MB/s
real 0m6.964s
user 0m0.003s
sys 0m3.489s
[root@test1 tmp]# echo noop > /sys/block/sda/queue/scheduler
[root@test1 tmp]# time dd if=/dev/zero f=/tmp/test bs=2M count=300
300+0 records in
300+0 records out
629145600 bytes (629 MB) copied, 9.49418 seconds, 66.3 MB/s
real 0m9.855s
user 0m0.002s
sys 0m4.075s
[root@test1 tmp]# echo deadline > /sys/block/sda/queue/scheduler
[root@test1 tmp]# time dd if=/dev/zero f=/tmp/test bs=2M count=300
300+0 records in
300+0 records out
629145600 bytes (629 MB) copied, 6.84128 seconds, 92.0 MB/s
real 0m6.937s
user 0m0.002s
sys 0m3.447s
测试结果:
第一 anticipatory,用了6.79441秒,速度为92.6MB/s
第二 deadline,用了6.84128秒,速度为92.0MB/s
第三 cfq,用了6.93058秒,速度为90.8MB/s
第四 noop,用了9.49418秒,速度为66.3MB/s
3)测试同时读/写
[root@test1 tmp]# echo deadline > /sys/block/sda/queue/scheduler
[root@test1 tmp]# dd if=/dev/sda1 f=/tmp/test bs=2M count=300
300+0 records in
300+0 records out
629145600 bytes (629 MB) copied, 15.1331 seconds, 41.6 MB/s
[root@test1 tmp]# echo cfq > /sys/block/sda/queue/scheduler
[root@test1 tmp]# dd if=/dev/sda1 f=/tmp/test bs=2M count=300
300+0 records in
300+0 records out
629145600 bytes (629 MB) copied, 36.9544 seconds, 17.0 MB/s
[root@test1 tmp]# echo anticipatory > /sys/block/sda/queue/scheduler
[root@test1 tmp]# dd if=/dev/sda1 f=/tmp/test bs=2M count=300
300+0 records in
300+0 records out
629145600 bytes (629 MB) copied, 23.3617 seconds, 26.9 MB/s
[root@test1 tmp]# echo noop > /sys/block/sda/queue/scheduler
[root@test1 tmp]# dd if=/dev/sda1 f=/tmp/test bs=2M count=300
300+0 records in
300+0 records out
629145600 bytes (629 MB) copied, 17.508 seconds, 35.9 MB/s
测试结果:
第一 deadline,用了15.1331秒,速度为41.6MB/s
第二 noop,用了17.508秒,速度为35.9MB/s
第三 anticipatory,用了23.3617秒,速度为26.9MS/s
第四 cfq,用了36.9544秒,速度为17.0MB/s
五)ionice
ionice可以更改任务的类型和优先级,不过只有cfq调度程序可以用ionice.
有三个例子说明ionice的功能:
采用cfq的实时调度,优先级为7
ionice -c1 -n7 -ptime dd if=/dev/sda1 f=/tmp/test bs=2M count=300&
采用缺省的磁盘I/O调度,优先级为3
ionice -c2 -n3 -ptime dd if=/dev/sda1 f=/tmp/test bs=2M count=300&
采用空闲的磁盘调度,优先级为0
ionice -c3 -n0 -ptime dd if=/dev/sda1 f=/tmp/test bs=2M count=300&
ionice的三种调度方法,实时调度最高,其次是缺省的I/O调度,最后是空闲的磁盘调度.
ionice的磁盘调度优先级有8种,最高是0,最低是7.
注意,磁盘调度的优先级与进程nice的优先级没有关系.
一个是针对进程I/O的优先级,一个是针对进程CPU的优先级.
Anticipatory I/O scheduler 适用于大多数环境,但不太合适数据库应用
Deadline I/O scheduler 通常与Anticipatory相当,但更简洁小巧,更适合于数据库应用
CFQ I/O scheduler 为所有进程分配等量的带宽,适合于桌面多任务及多媒体应用,默认IO调度器
Default I/O scheduler
问题一:
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sdi 82.40 8.90 67.00 5.30 8641.20 56.80 240.61 0.08 1.09 0.93 6.76
上面sdi是一块SSD盘,SSD又不是机械盘,怎么会有rrqm这些合并值呢?
我的理解是内核把这些指标统一对待了? 意思是这些指标对SSD不适用
问题二:
SSD的%util参数很低,但是明显感觉SSD性能到瓶颈了,难道说%util参数也是打酱油的?
end

 浙公网安备 33010602011771号
浙公网安备 33010602011771号