
pyspider 数据存入Mysql--Python3
一、不写入Mysql
以爬取哪儿网为例。
以下为脚本:
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://travel.qunar.com/travelbook/list.htm', callback=self.index_page, validate_cert=False)
@config(age=100 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('li > .tit > a').items():
self.crawl(each.attr.href, callback=self.detail_page, validate_cert=False, fetch_type='js')
next = response.doc('.next').attr.href
self.crawl(next, callback=self.index_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('#booktitle').text(),
"date": response.doc('.when .data').text(),
"day": response.doc('.howlong .data').text(),
"who": response.doc('.who .data').text(),
"text": response.doc('#b_panel_schedule').text(),
"image": response.doc('.cover_img').text(),
}
这个脚本里只是单纯的将结果打印在pyspider 的web ui中,并没有存到其它地方。
二、存入Mysql中
插入数据库的话,需要我们在调用它之前定义一个save_in_mysql函数。 并且需要将连接数据库等初始化放在__init__函数中。
注: pymysql.connect('localhost', '账号', '密码', '数据库', charset='utf8')
# 连接数据库
def __init__(self):
self.db = pymysql.connect('localhost', 'root', 'root', 'qunar', charset='utf8')
def save_in_mysql(self, url, title, date, day, who, text, image):
try:
cursor = self.db.cursor()
sql = 'INSERT INTO qunar(url, title, date, day, who, text, image) \
VALUES (%s, %s , %s, %s, %s, %s, %s)' # 插入数据库的SQL语句
print(sql)
cursor.execute(sql, (url, title, date, day, who, text, image))
print(cursor.lastrowid)
self.db.commit()
except Exception as e:
print(e)
self.db.rollback()
然后在detail_page中调用save_in_mysql函数:
@config(priority=2)
def detail_page(self, response):
url = response.url
title = response.doc('title').text()
date = response.doc('.when .data').text()
day = response.doc('.howlong .data').text()
who = response.doc('.who .data').text()
text = response.doc('#b_panel_schedule').text()[0:100].replace('\"', '\'', 10)
image = response.doc('.cover_img').attr.src
# 插入数据库
self.save_in_mysql(url, title, date, day, who, text, image)
return {
"url": response.url,
"title": response.doc('title').text(),
"date": response.doc('.when .data').text(),
"day": response.doc('.howlong .data').text(),
"who": response.doc('.who .data').text(),
"text": response.doc('#b_panel_schedule').text(),
"image": response.doc('.cover_img').attr.src
}
三、完整代码、数据库建设及运行结果 (代码可直接跑)
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2019-07-02 21:37:08
# Project: qunar
from pyspider.libs.base_handler import *
import pymysql
class Handler(BaseHandler):
crawl_config = {
}
# 连接数据库
def __init__(self):
self.db = pymysql.connect('localhost', 'root', 'root', 'qunar', charset='utf8')
def save_in_mysql(self, url, title, date, day, who, text, image):
try:
cursor = self.db.cursor()
sql = 'INSERT INTO qunar(url, title, date, day, who, text, image) \
VALUES (%s, %s , %s, %s, %s, %s, %s)' # 插入数据库的SQL语句
print(sql)
cursor.execute(sql, (url, title, date, day, who, text, image))
print(cursor.lastrowid)
self.db.commit()
except Exception as e:
print(e)
self.db.rollback()
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://travel.qunar.com/travelbook/list.htm', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('li > .tit > a').items():
self.crawl(each.attr.href, callback=self.detail_page, fetch_type='js')
next_url = response.doc('.next').attr.href
self.crawl(next_url, callback=self.index_page)
@config(priority=2)
def detail_page(self, response):
url = response.url
title = response.doc('title').text()
date = response.doc('.when .data').text()
day = response.doc('.howlong .data').text()
who = response.doc('.who .data').text()
text = response.doc('#b_panel_schedule').text()[0:100].replace('\"', '\'', 10)
image = response.doc('.cover_img').attr.src
# 存入数据库
self.save_in_mysql(url, title, date, day, who, text, image)
return {
"url": response.url,
"title": response.doc('title').text(),
"date": response.doc('.when .data').text(),
"day": response.doc('.howlong .data').text(),
"who": response.doc('.who .data').text(),
"text": response.doc('#b_panel_schedule').text(),
"image": response.doc('.cover_img').attr.src
}
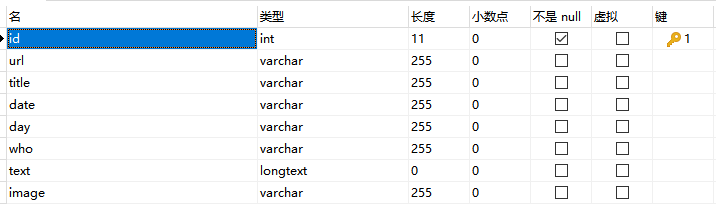
数据库建设:
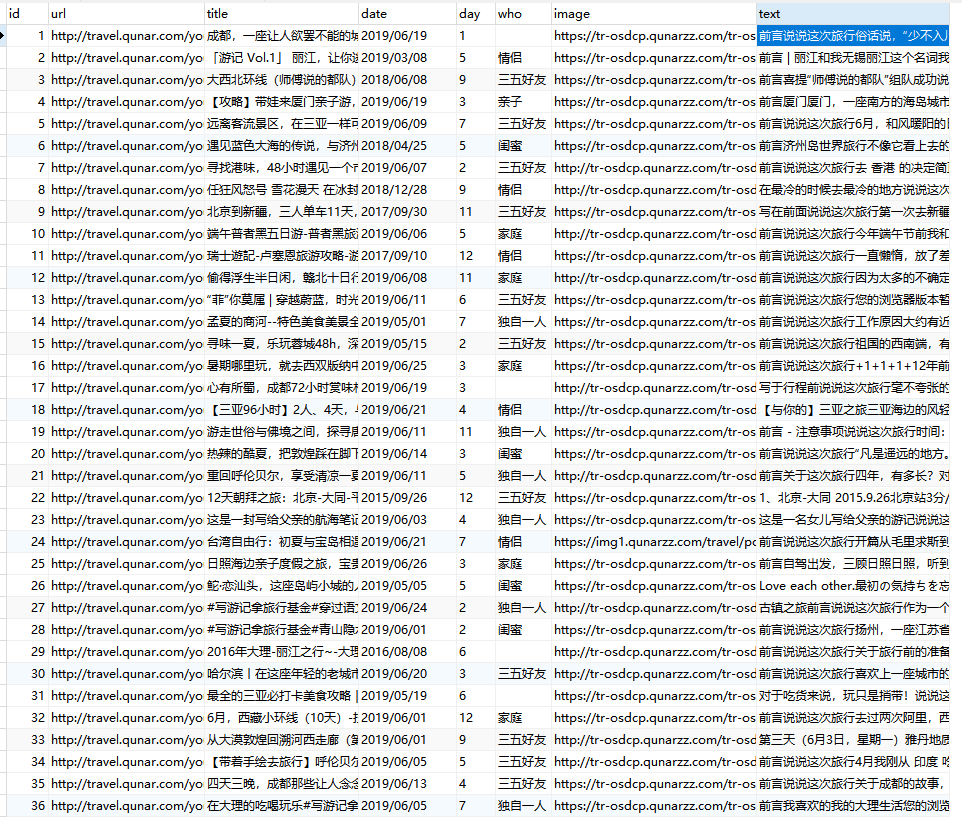
结果:
Only action can relieve the uneasiness.
