
Zabbix自定义监控项(模板)
虽然Zabbix提供了很多的模板(简单理解为监控项的集合),在zabbix界面点击share按钮就可以直接跳到模板大全的官方网站,但是由于模板内的监控项数量太多不好梳理且各种模板质量参差不齐,还是建议针对自己要监控的主机或产品自定义模板(Linux服务器主机的监控使用默认模板就可以)。
之前一篇笔记描述了如何安装和配置zabbix架构,详见:Zabbix-3.4简介及安装配置 ,本文分四个小节描述如何自定义监控项:
- 文章概述
- 自定义模板的步骤
- 如何配置告警
- 监测数据的可视化
一、文章概述
什么是模板?模板就是一系列定义好了的监控项+触发器的集合,例如zabbix定义了Linux OS的监控模板,可以监控Linux的系统状况。官网也提供了很多常见模板的下载。
我把zabbix的模板大致分三类:
- zabbix自带的内置模板,这类模板不但有官方定义的item key和trigger,还内置了获取item value的命令。最典型的就是Linux OS的监控,这个模板的大多数监控项无需你自己配置监控信息的获取命令,即插即用。
- zabbix提供的常用模板,此类模板zabbix只是为你定义好了监控项的key和key的数据类型(key只有unsigned number,float,character,log,text五种类型),并未提供内置的item value获取功能,需要你手动为这些key编写获取监控信息的命令。
- 自定义的模板,此类模板是完全由用户自己创建的模板,你可以自定义个性化的key名字和返回类型,并通过特定的命令或脚本或应用提供的接口去获取监控信息。
个人推荐的是针对特定的产品自己创建特定的模板,这样才能实现灵活定制。你可以选择import网上提供的各种模板,也可以将自己搞的模板export出去供他人使用。
本文以监控mysql QPS为例,自己定义一个mysql的监控模板(zabbix有mysql的监控模板,本例只是为了示例)。
二、自定义模板步骤
1.创建模板
模板名称自定义为MySQL_MONITOR,隶属的主机组选择Templates/Databases就好(或都不选择),属于哪个主机组不影响使用,模板是对任意主机组内的主机可用的。
而且主机组不止可以表示主机的集合,也可以用于表示模板的集合,你可以创建一个名为DATABASE_TEMPLATES的虚拟主机组,专门用于存放自己编写的各种数据库的模板,例如mysql,mongo,oracle等的监控模板。
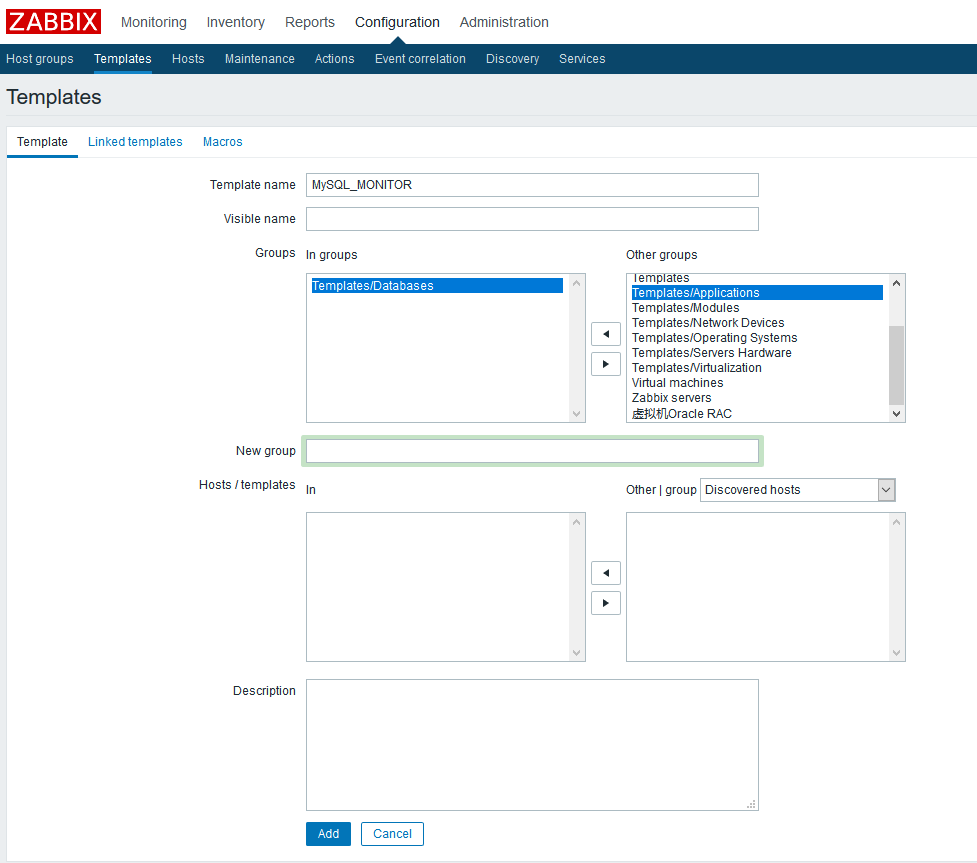
2.创建模板内的监控项
下面就是建好的模板,可以看到模板主要包含items,trigger等对象,其他的暂不需要太多关注。

由于我们就是用于监控mysql的,因此这个模板内没必要建applications(applications是用于对items分组的),直接建个item,这里只需要定义个name和key以及type就好了:
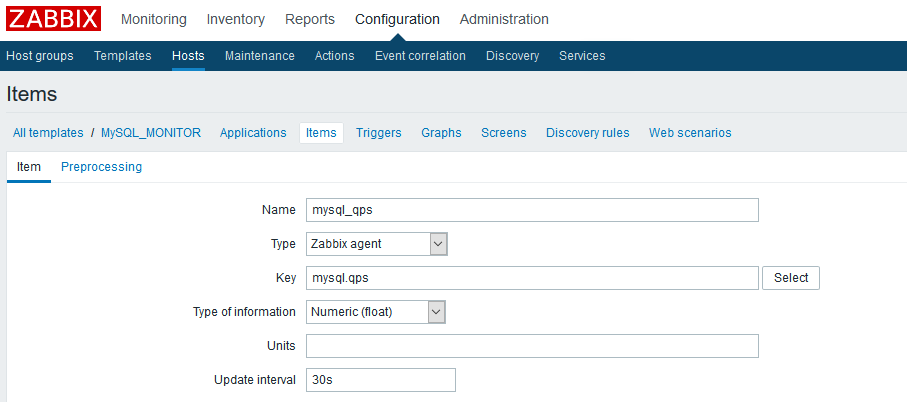
type一般选择zabbix agent或zabbix agent(active),现在一般后者居多因为可以进行active check减少server压力,只需要在agent端配相关的active check项即可。
特别提示:如果你的server端版本远高于agent端,那么建议item的类型选择zabbix agent,主动式的item可能会有BUG(遇到过获取的数据异常的问题),即便确认高版本服务端兼容低版本客户端,但保险起见还是版本一致的好。
此时在看MySQL_MONITOR模板就会发现多了一个监控项(item)。
3.获取监控值
监控项已经建好了,怎么从客户端获取监控信息呢?首先需要修改agent端的配置文件并重启agentd:
vi zabbix_agentd.conf
UserParameter=mysql.qps,mysql -uleo -pleo -e "show global status like 'Queries'"|grep Queries|awk '{print $2}'
UserParameter的格式是固定的,有以下两种:
UserParameter=key,command
UserParameter=key[*],command
其中第一种很好理解,key就是你定义的监控项key,本例中就是mysql.qps,command就是获取监控信息的命令,本例中就是mysql -uleo -pleo -e "show global status like 'Queries'"|grep Queries|awk '{print $2}'
第二种是第一种格式的进阶版,允许你为command提供输入参数,这里都是位置传参的可以定义从$1-$9的9个参数,这种格式的好处在于你可以使用一个接受位置传参的脚本获取多个监控值,而不用为每个监控项都写一个获取监控值的脚本。
4.为主机添加监控项
监控项设置好之后,只需要把监控项加入主机即可,这样就可以实现对主机对应item的监控。
一般来说可以直接在主机界面create item,但是本例为了方便演示如何集成监控项到模板使用的是template,因此直接把模板应用到主机即可。注意下图要点击add然后update才能更新主机所用的模板们。
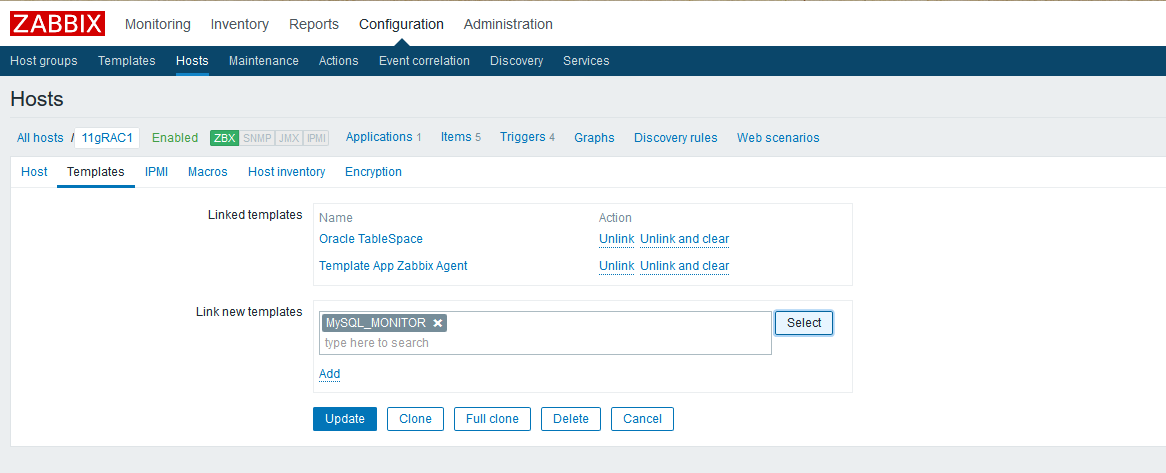
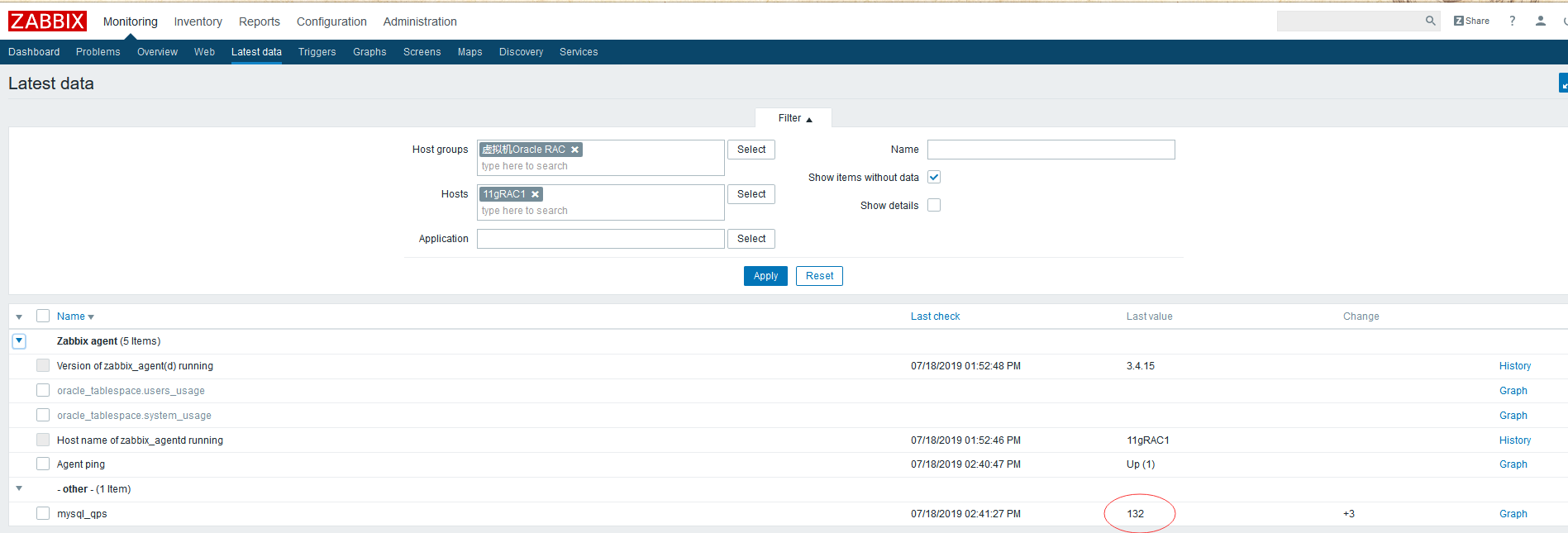
5.查看监控数据
如果获取监控值的脚本或命令运行正常,且返回值与key type一致,那么现在在仪表板的latest data就可以看到监控的值了:
6.完善监控项
当前监控的mysql qps其实只是queries并没有p(er)s(econd),如果用queries/uptime得到的也只是一个平均QPS,而我们一般想要监测的都是类似于过去30s平均qps这种更有意义的值,如果要用脚本或者程序脚本来获取的话工作量就大了,而用zabbix很简单。
我们去item的界面进行修改(如果很熟悉要监控的产品的话其实创建模板时就可以为item设置preprocessing):
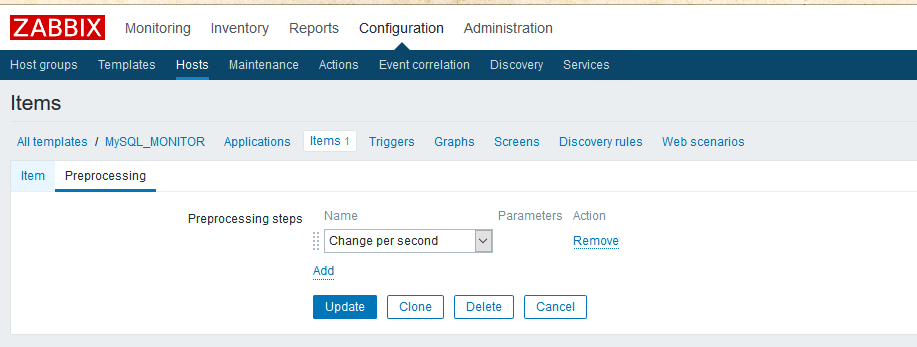
只需要对获取的监控值做预处理就可以了,我们选择change per second,zabbix server就会自动将持续获取的监控值们进行处理,得到一个每秒均值,由于我们的qps收集间隔是30s,最终得到的qps就是过去30s数据库的平均qps。
现在再去看latest data看到的就是qps的30秒平均值了,更多地数据预处理步骤的解释可以参考官网链接:https://www.zabbix.com/documentation/3.4/manual/config/items/item
三、告警配置
在第二步中描述的是如何设置模板及监控项,那么在监控项超过阈值之后如何进行告警呢?涉及的zabbix组件主要有3个:trigger,action,media type,此外还涉及到user实体。
1.如何设置触发器?
我们直接在模板中添加触发器,触发器的触发条件可以是一个监控项超过阈值或多个监控项超过阈值的逻辑联合条件,本例只演示mysql.qps超过阈值的告警。

红色箭头标出的就是需要注意的地方,其中severity可以选择告警的严重性(没其他作用,仅仅是标示这个告警有多重要的),本例选择当监控值超过0.2时就告警......使用expression constructor还可以实现条件的逻辑联合,例如AND,OR等。
2.查看告警效果
默认告警信息是直接显示在dashboard的,我们到mysql里噼里啪啦一顿操作把qps拉上来,然后去仪表板看下:
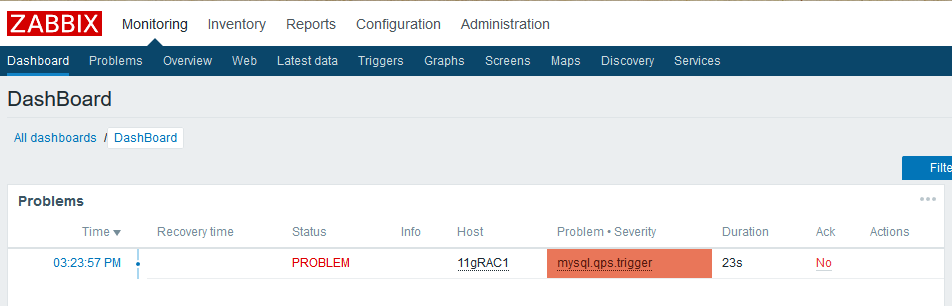
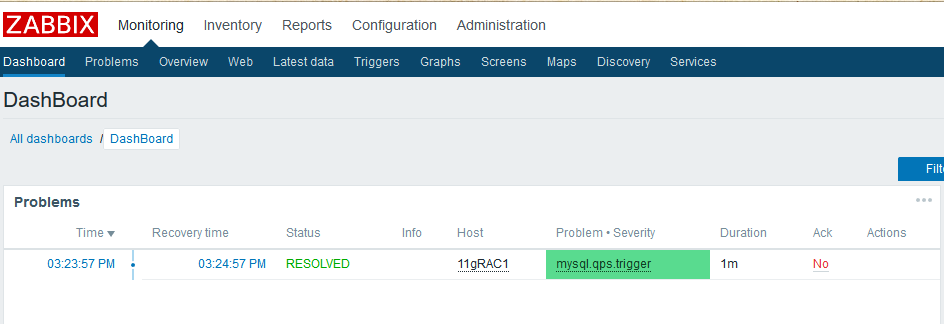
可以看到告警信息了,他会告诉你这个告警持续的时间,如果问题被解决,那么告警会变为绿色,并在仪表板显示一段时间后消失:
3.设置邮件告警
默认告警只显示到仪表板,如果想要实现短信或邮件告警还需要额外配置组件。
3.1创建media type并添加到user
默认zabbix自带了email,jabber,sms媒体类型,你只需要在Administration-Media types下进入Email项,填写好SMTP的相关信息,并根据SMTP服务器的类型选好验证模式即可,不过我这里为了加一种media type来演示,选择新建脚本类型的media type,使用linux自带的sendmail或者自己编写SendMail.sh脚本来发送邮件。
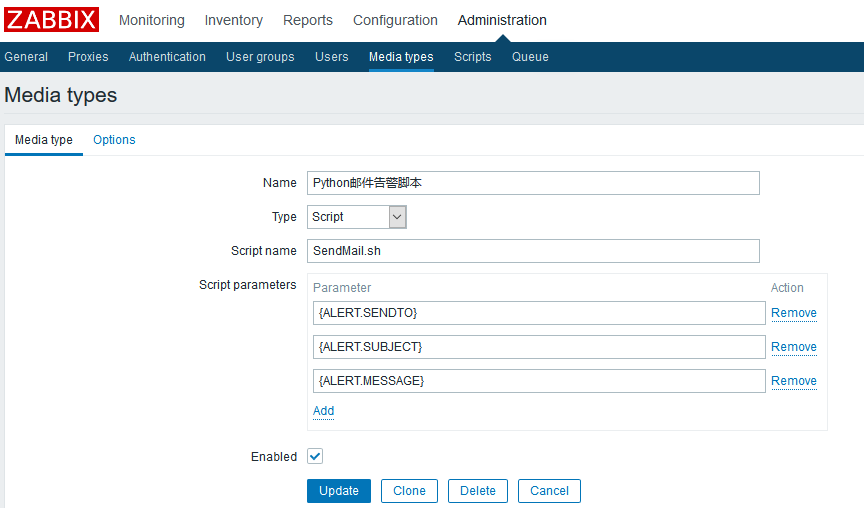
上述的3个参数是zabbix预定义的3个宏,有这3个宏足够了,我们在使用脚本发送邮件时只需要按顺序把脚本的输入参数设置为这3个参数即可。如果你用的邮件发送脚本的参数不是此顺序,那么用shell再包装一层即可,确保脚本输入参数是这3个。
Ps:Zabbix内置的完整宏列表参见:https://www.zabbix.com/documentation/3.4/manual/appendix/macros/supported_by_location
关于宏使用的一些提示:
- 获取trigger被触发时的item value可以使用宏{ITEM.LASTVALUE},如果触发器内有多个item的触发条件,那么可以使用{ITEM.LASTVALUE<1-9>}定位具体是哪个item,1-9是指item在trigger中出现的顺序,最多9个,例如{ITEM.LASTVALUE1}
- 内置宏并非在所有情况下可用,曾经遇到过官网支持的版本下某些内置宏获取不到值的BUG,例如3.4版本时{TRIGGER.SEVERITY}宏在trigger name中不可用,但是在邮件中可用,后来猜测是因为SEVERITY本身是trigger的一个属性,在trigger未实例化之前不能调用自身的属性。如果在action中调用trigger的各种宏就不会出错了。
- 除了正常的内置宏外,zabbix还支持用户自定义宏和底层的发现规则宏(LLD),分别为{$MACRO}和{#MACRO}的表示格式,其中:
关于用户自定义宏的创建参照https://www.zabbix.com/documentation/3.4/manual/config/macros/usermacros
模板的discovery rules的本质其实是一个子模板,其中定义了一系列的item、trigger、graph等对象的prototypes。这些prototypes(即原型)都是使用发现规则宏定义的,本质上是用宏变量代替要监控的具体对象。例如常规的监控项可以将key命名为linux.fs[/root]来监控/root目录,但是如果要监控N多目录呢,我们要建N个item吗?不,有了discovery rules和[low level]discovery macros(LLD)我们就可以只定义一个discovery rules,prototypes所引用的具体目录可以用宏{#FSNAME}来代替,即linux.fs[{#FSNAME}]这样一个item prototypes就可以满足所有目录的监控,我们只需要使用提前定义好的脚本获取一系列的键值对,其中键就是我们的LLD宏,而值就是获取的一系列要监控的目录名,脚本输出需要如下所示:
{
"data":[
{ "{#FSNAME}":"/", "{#FSTYPE}":"rootfs" },
{ "{#FSNAME}":"/sys", "{#FSTYPE}":"sysfs" },
{ "{#FSNAME}":"/proc", "{#FSTYPE}":"proc" },
{ "{#FSNAME}":"/dev", "{#FSTYPE}":"devtmpfs" },
{ "{#FSNAME}":"/dev/pts", "{#FSTYPE}":"devpts" },
{ "{#FSNAME}":"/lib/init/rw", "{#FSTYPE}":"tmpfs" },
{ "{#FSNAME}":"/dev/shm", "{#FSTYPE}":"tmpfs" },
{ "{#FSNAME}":"/home", "{#FSTYPE}":"ext3" },
{ "{#FSNAME}":"/tmp", "{#FSTYPE}":"ext3" },
{ "{#FSNAME}":"/usr", "{#FSTYPE}":"ext3" },
{ "{#FSNAME}":"/var", "{#FSTYPE}":"ext3" },
{ "{#FSNAME}":"/sys/fs/fuse/connections", "{#FSTYPE}":"fusectl" }
]
}
这样discovery rules的prototypes就会遍历{#FSNAME},自动为所有检测到的目录创建item、trigger、graph等。
接下来继续说为用户添加media type:
在media type创建完毕后需要为user添加媒体类型,其中NIWAHD(Not classified,Information,Warning,Average,High,Disaster )是问题严重程度的英文首字母,邮件告警发送的email地址也是在user实体这里配置的:

3.2创建action
建好了media type,并为用户添加上就完事了吗?不,那只是提供了邮件发送的功能和通道,为了实现监测值异常告警还需要添加action,所谓action就是当触发器被触发时,告警不止显示在仪表板,还会通过邮件告警媒介将特定的信息发送给指定的user实体。
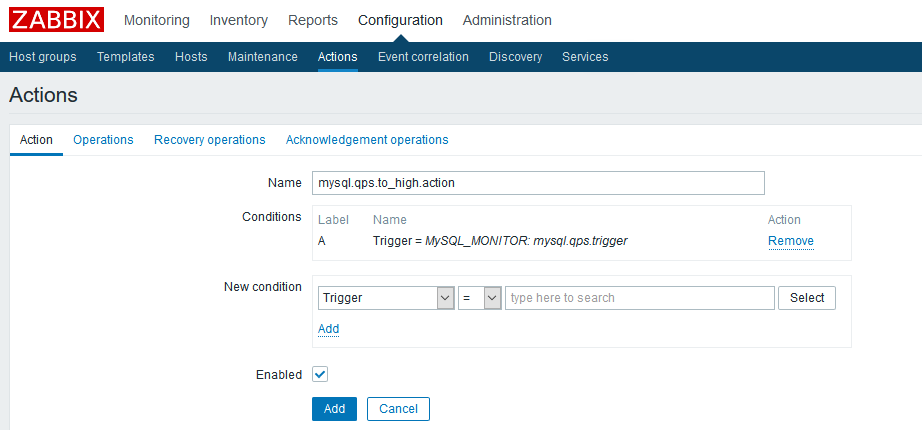
一个功能完整的action可以按上图的小标题分3部分(第4个忽略):action condition,operations和recovery operations,分表表示动作触发的条件,触发后的具体操作,问题恢复时的操作。
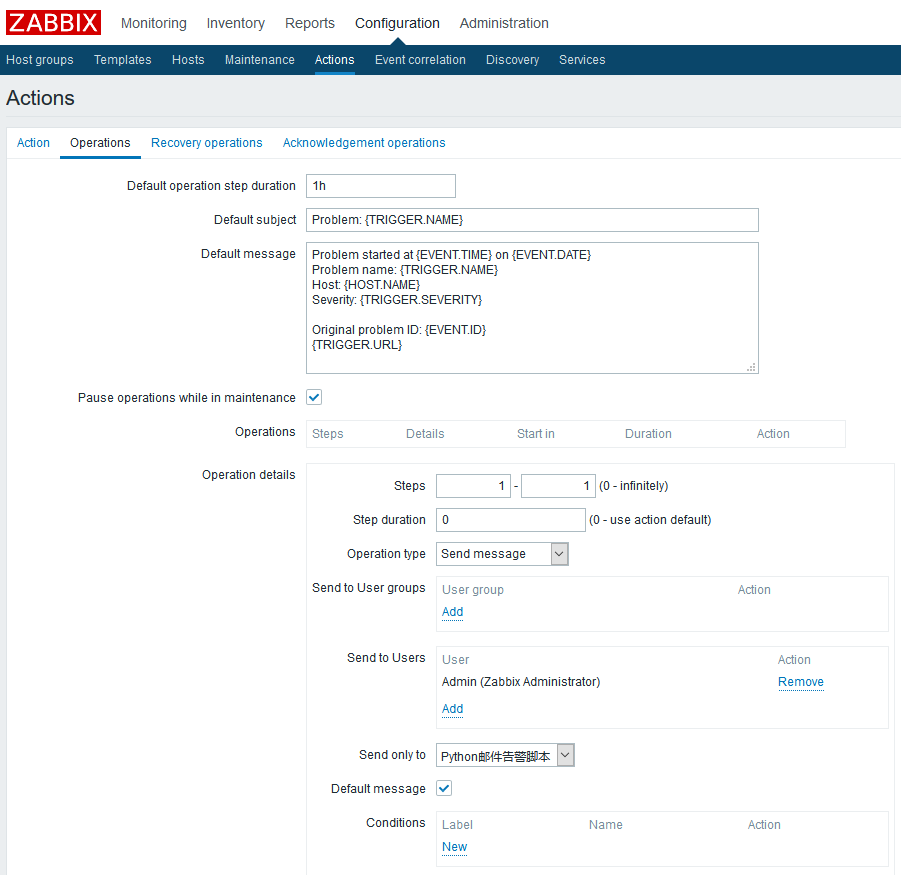
上边的message可以自定义的更丰富些,可以用中文编写,配置完之后需要点击add按钮添加,本图只是展示如何配置。其中{}括起来的都是zabbix的宏。
拓展:关于operations中的steps(操作步骤)和step duration(操作步长)
步长是操作步骤的执行间隔,而step(操作步骤)是在operation details中定义的,step数字只是代表执行的优先度。
例如你可以建多个operations,每个都是step 1,那么当告警触发时这些step为1的操作就会被全部即时执行,你还可以在一个operation中将steps设为1-3,那么这个operation就会每隔一个操作步长执行一次共执行3次停止。
你还可以设置了step1、step3,那么执行完step1之后就会经过两个步长的时间继续执行step3,每个步骤都可以自定义不同的操作和操作步长(自定义的操作步长为0表示默认使用统一的操作步长1h)。
需要注意的是action并没有执行周期,即一个触发器类型的action只会执行一次,如果需要在问题解决之前每隔一段时间发出一次告警只能通过将action的operation step设为1-0来解决(0表示无限次数即每隔1小时执行一次action operation)。
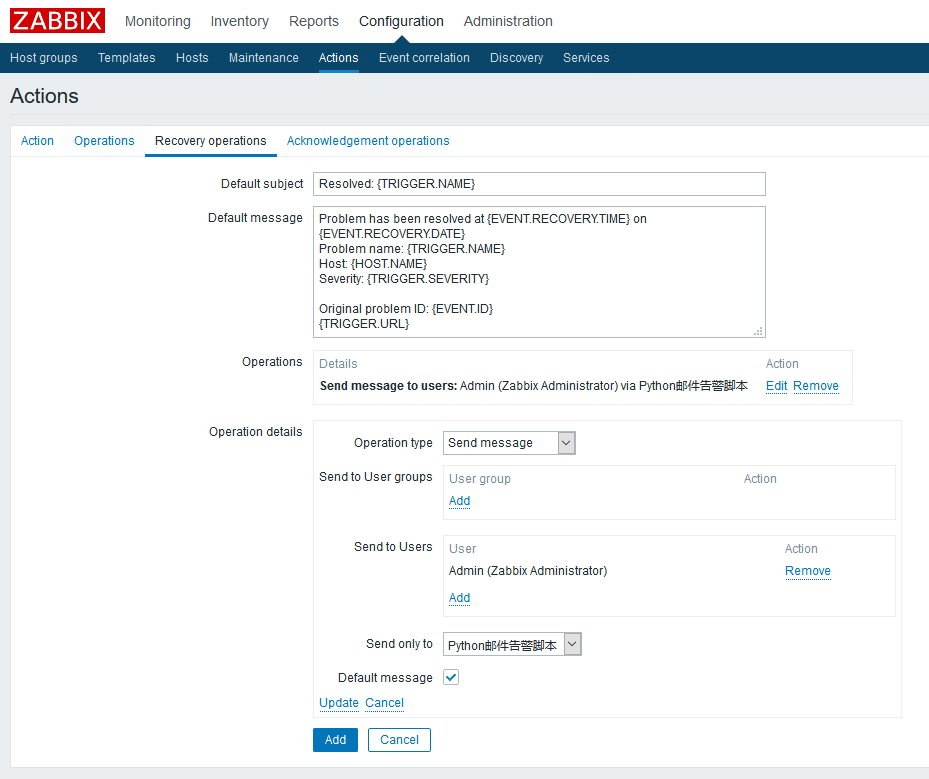
至此action配置完毕,只要下次触发器被触发,告警就不会只出现在dashboard了,邮件告警也会被发送至指定用户。
四、数据可视化
为了更好的观察监控数据的变化趋势,我们需要用图表来展示数据,zabbix提供了这方面的功能。
虽然可以在latest data中通过点击每个监控项的graph按钮查看数据的图表,但是这种方式看起来很麻烦,且只能查看单一监控项的变化图表,而定制的graph比较灵活。
为了更好地观察数据我们要在模板中添加graph组件:
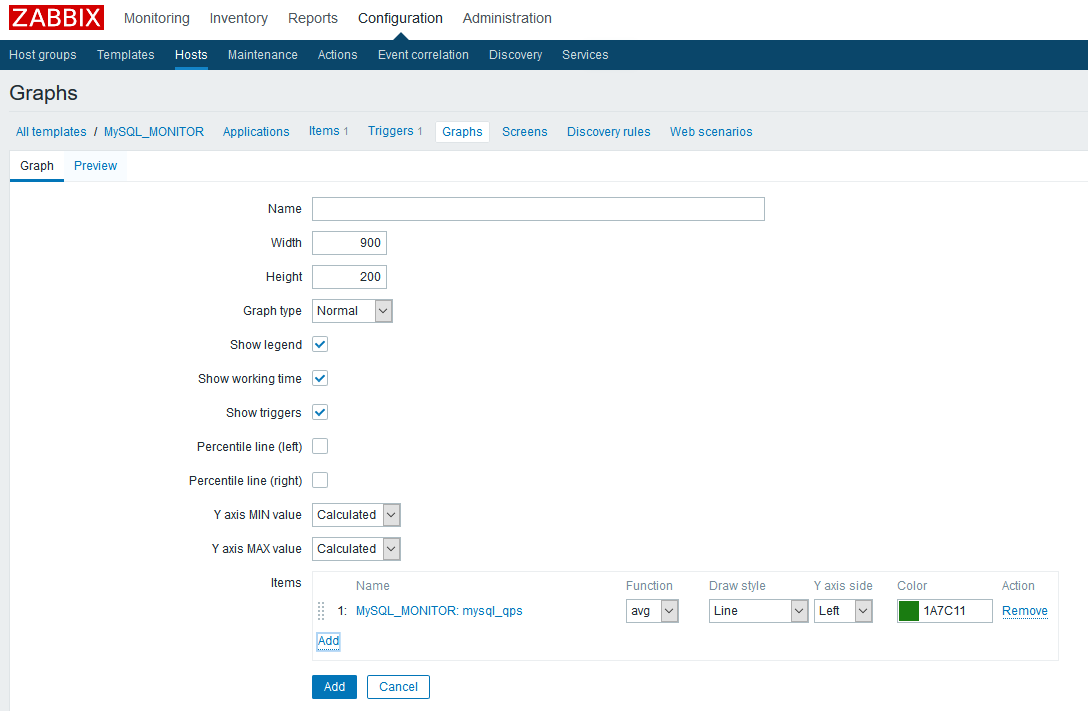
graph type的4种选项分别表示普通线型图,柱状图,饼状图和爆炸饼状图,添加items可以实现在一副图中显示多个监控项的历史值,本例只有一个监控项如上所示。
建好graph之后就可以在dashboard中添加graph了:
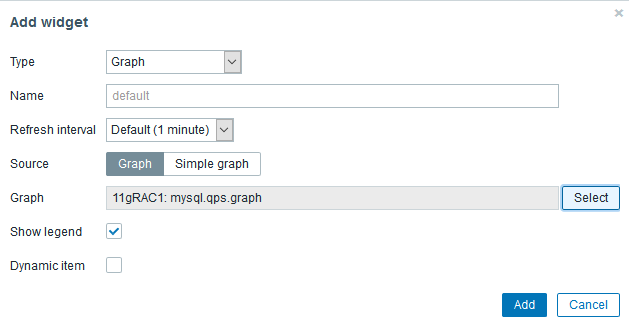
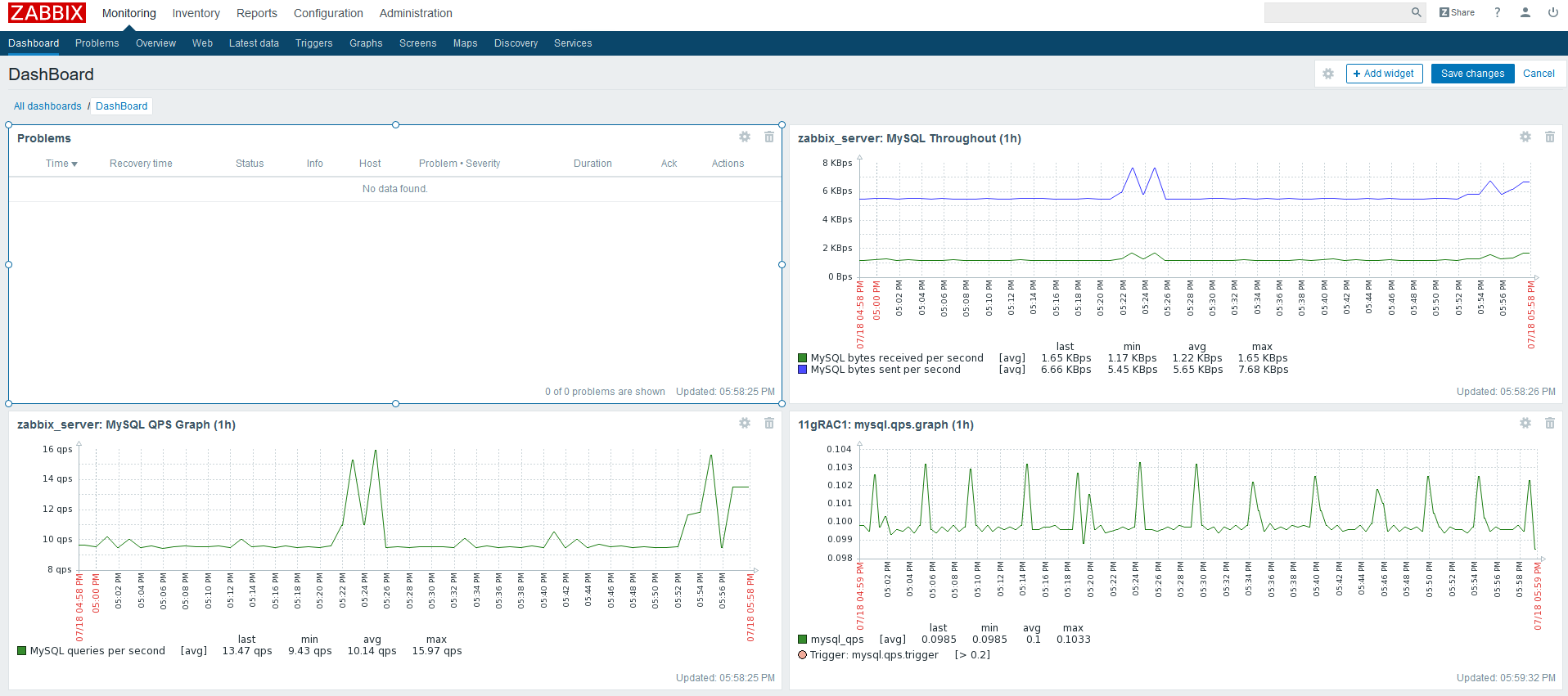
下边第四个窗口就是我新加的展示窗口:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号