
HyperLoglog算法在Uv实时统计中的应用
1 传统的Uv实时统计方法以及其缺点
给定时间段条件下,实时统计Uv就是统计不重复的访客数。
最简单的方法就是把用户唯一id存储到集合中,每次有新访客,就把向集合新增元素。
但是当数据量千万级别的时候,无论是内存中,还是redis等外部系统中,集合新增元素的效率都很低。
2 HyperLoglog
在不追求绝对准确的情况下,使用概率算法算是一个不错的解决方案。
概率算法不直接存储数据集合本身,通过一定的概率统计方法预估基数值,这种方法可以大大节省内存。
怎么理解HyperLoglog算法呢,
下面是通过mapWithState算子计算单词数的官方示例
...
val stateDstream = wordDstream.mapWithState(
StateSpec.function(mappingFunc).initialState(initialRDD))
val mappingFunc = (word: String, one: Option[Int], state: State[Int]) => {
val sum = one.getOrElse(0) + state.getOption.getOrElse(0)
val output = (word, sum)
state.update(sum)
output
}
...
如果这的word代表访客唯一id,那如何统计每天的访客数(DAU)呢?
这里引入Java版本的HLL,来实现大数据背景下的uv实时统计。
maven依赖:
<dependency>
<groupId>com.clearspring.analytics</groupId>
<artifactId>stream</artifactId>
<version>2.9.5</version>
</dependency>
核心逻辑:
import com.clearspring.analytics.stream.cardinality.HyperLogLog;
//rdd类型为RDD[(String,String)], means (dateStr, id)
//设置超时为一天
val stateDstream = visitorDstream.mapWithState(
StateSpec.function(mappingFuncHLL).timeout(Seconds(86400))
)
private val mappingFuncHLL = (key: String, one: Option[Set[String]], state: State[HyperLogLog]) => {
val defaultRes = new HyperLogLog(14)
if (state.isTimingOut()) {
(key, defaultRes)
} else {
var uv = state.getOption().getOrElse(defaultRes)
one.foreach(it => {
it._1.foreach(uv.offer(_))
state.update(uv)
})
(key, uv)
}
}
3 性能评估
在Redis里,每个HyperLogLog Key只需占用十几k的内存,就可以估算接近2^64个不同元素的基数。
Redis HyperLogLog测试给出了不同规模数据集下的误差。
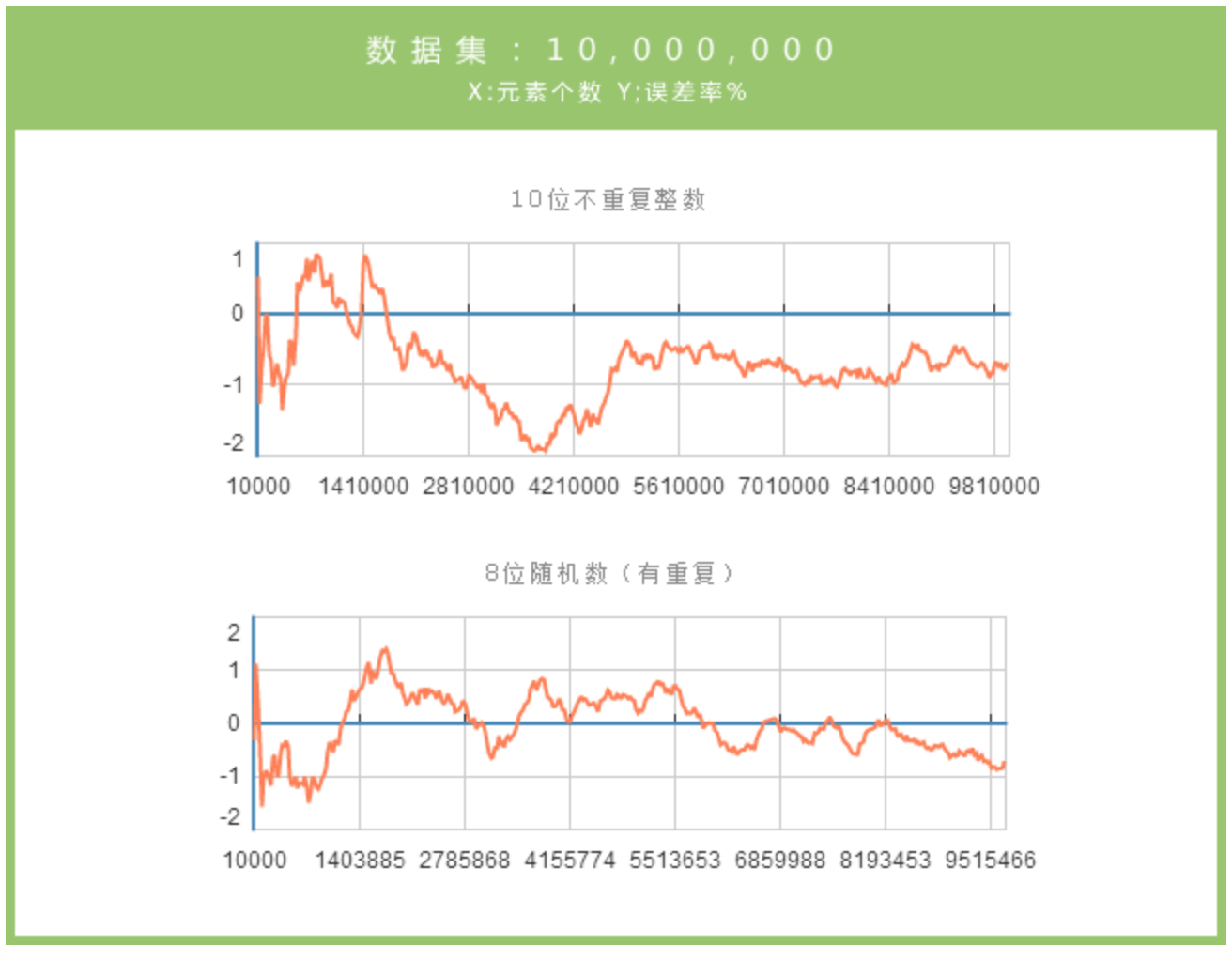
千万级数据集下,随机数误差基本低于 1.5%, 完全不重复情况下误差也不超过 2%。能满足大部分情况下的需求。
4 讨论
4.1 bitmap
bitmap可以理解为通过一个bit数组来存储特定数据的一种数据结构,每一个bit位都能独立包含信息,bit是数据的最小存储单位,因此能大量节省空间,也可以将整个bit数据一次性load到内存计算。
如果定义一个很大的bit数组,基数统计中每一个元素对应到bit数组的其中一位,例如bit数组1001010代表实际数组[2, 4, 7]。
新加入一个元素,只需要将已有的bit数组和新加入的数字做按位或 (or)(or)计算。bitmap中1的数量就是集合的基数值。
bitmap有一个很明显的优势是可以轻松合并多个统计结果,只需要对多个结果求异或就可以。也可以大大减少存储内存,
可以做个简单的计算,如果要统计1亿个数据的基数值,大约需要内存: 100000000/8/1024/1024 \approx≈ 12M
bitmap对于内存的节约量是显而易见的,但是要做到每个元素唯一对应bit数组中固定一位需要一个良好的哈希算法。
我们希望有一个理想的哈希函数hash,能够保证对于元素e, 得到唯一的数字loc = hash(e), loc就是元素e在bit数组中的下标或位置。
怎么得到接近理想的,足够好的哈希函数,这是另一个问题。
4.2 B树
B树最大的优势是插入和查找效率很高,如果用B树存储要统计的数据,可以快速判断新来的数据是否已经存在,并快速将元素插入B树。要计算基数值,只需要计算B树的节点个数。 将B树结构维护到内存中,可以快速统计和计算,
但是B树的问题是只是加快了查找和插入效率,并没有节省存储内存。例如要同时统计几万个链接的UV,每个链接的访问量都很大,如果把这些数据都维护到内存中,实在是够呛。
4.3 HLL的原理
see also [1]
References
作者:kakashis
联系方式:fengshenjiev[AT]gmail.com
本文版权归作者所有,欢迎转载,演绎或用于商业目的,但是必须说明本文出处(包含链接)。

