基础 IO (Linux学习笔记)
基础IO
1.重谈文件
- 空文件在磁盘也要占据空间
- 文件 = 内容 + 属性
- 文件操作 = 对文件内容+对属性 or 对文件内容加属性
- 标定一个文件,必须使用文件路径加文件名【唯一性】
- 如果没有指明对应得文件路径,默认是在当前路径下进行文件访问
- 当写了一个跟文件操作有关得程序,编译后,文件有没有被操作呢?没有,所以本质是进程对文件的操作
- 一个文件要被访问,肯定要先被打开
所以
一个文件被用户进程首次打开即被执行了Open操作,会把文件的FCB调入内存,而不会把文件内容读到内存中,只有进程希望获取文件内容的时候才会读入文件内容
2. C文件接口
C语言,C++,java,python,php,go等语言都有文件操作接口,函数都不一样,对应的库函数都不一样
文件在哪里---->磁盘-,磁盘是硬件---->怎么访问磁盘----->OS进行操作----->要访问磁盘都绕不过OS
----->所以使用OS提供的系统接口来访问文件
所以不管语言是什么,底层还是对操作系统的一个系统调用接口来进行封装的,底层只有一个OS
2.1C语言文件操作
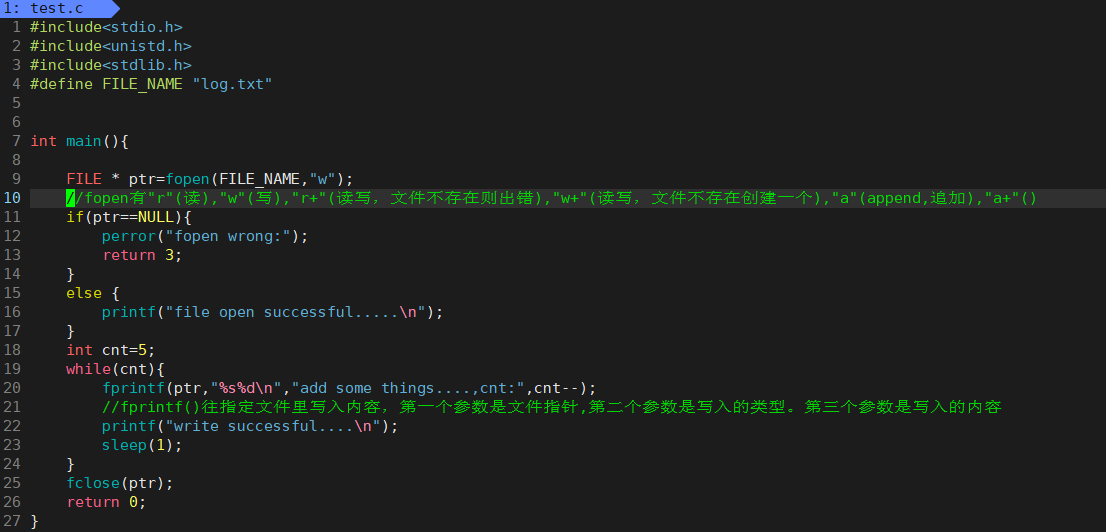
C语言打开文件的函数是
fopen(FILE *src,char* used)函数
src是文件指针,used是要进行的操作方式
其中操作操作方式有
"r"(读),"w"(写),"r+"(读写,文件不存在出错),"w+"(读写,文件不存在创建),"a"(append,加),"a+"()
往文件里写内容是用
fprintf (文件指针,写入类型,写入内容);
细节问题:
以w方式打开文件,每次调用fopen()会把文件清空,然后再开始读写
2.2 系统文件I/O接口
系统调用接口是
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int open(const char *pathname,int flags);
int open(const char *pathname,int flags,mode_t mode);
2.2.1 int open(const char *pathname,int flags);
参数:
*pathname : 文件的路径
flags : 标记位
返回值:
失败返回-1,成功返回文件描述符(数组下标)
这里的flags标记位,利用位图的思想来进行对应不同的操作,然后用宏代表这个数据
例如
#define O_WRONLY (1<<0) //以只写方式打开文件
#define O_creat (1<<3) //打开文件,如果没有改文件,则在当前路径下创建一个名称为传参的文件
#define O_TRUNE (1<<4) //每次清空文件内容
...
判断哪些位置有1,则执行哪些操作,所以flags传的是标记位
对于第一个系统调用
int open(const char *pathname,int flags);
//eg:
int fd1=open("log.txt",O_WRONLY | O_CREAT);
如果按这种方式来进行文件访问,如果没有改文件,那么就创建一个,但是这个函数创建出来的文件的权限是乱码,前提情况是没有改文件的时候,才会发生这种情况

所以第一个函数是适合保证有指定的文件存在是调用的
2.2.3 int open(const char *pathname,int flags,mode_t mode);
因为第一个创建的时候没有权限,所以这个mode是一个16进制的默认权限码,调用的时候传入的就是要创建文件的默认权限码,然后创建过程需要 &~umask的码

2.3 open函数返回值
既然文件操作的本质是 : **进程 **+ 被打开文件 的 关系

进程可以打开多个文件吗?,可以------->系统中肯定有着大量的被打开的文件------>被打开的文件一定要被操作系统管理起来------->如何管理?先描述再组织------->操作系统为了管理被打开的文件必定要创建对应的内核数据结构-------> struct file {} ( 包含了文件的属性 )
所以有,对于一个进程,在内存中,肯定也有其他被打开的文件在内存中,所以怎么样找到属于自己当前进程的被打开文件呢?
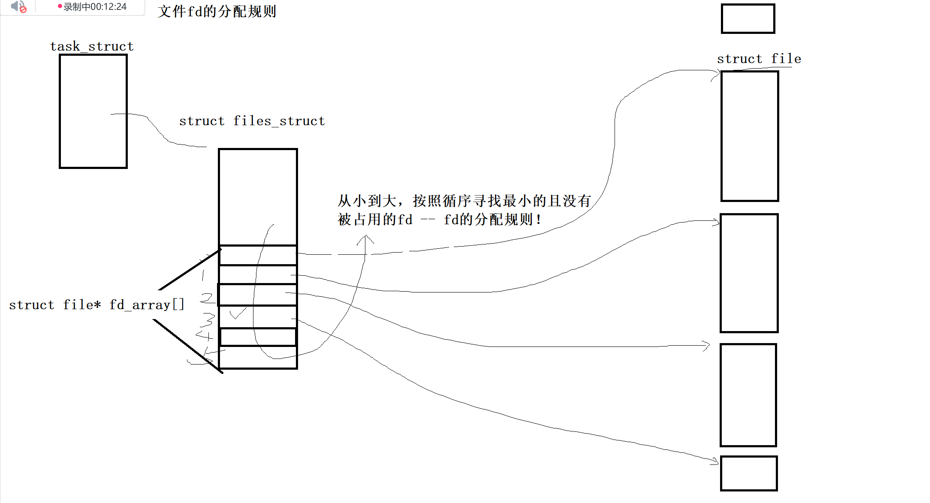
① struct file是文件的结构体,磁盘加载到内容=存中,为每一个文件创建属于自己被打开文件的结构体struct file ,属于一个进程的文件会按属性用*file利用指针的方式链接起来
②进程都有pcb即task_struct{} ,PCB里有一个 struct files_struct *files ,这个东西是一个指针,指向一个叫做files_strcut的结构体
③files_struct里包含了一个数组,这个数组是 struct file* fd_arrar[] ,这个是一个指针数组,数组里的每个指针即指向了一个①里每个文件的结构体,那么就连起来了,这个数组的下标就是文件描述符fd,即open函数的返回值
所以一个通过系统调用文件被打开,通过磁盘加载到内存中,然后创建属于这个文件的file结构体,然后再把这个*file指针加入到文件符描述表中,通过下标来进行系统调用,所以文件描述符本质就是数组的索引值(下标)

所以C语言的库函数是通过调用系统函数open()
然后open()函数返回fd
然后C函数再去找PCB里的*file指针
通过fd来访问对应的被打开文件
2.4 fd隐藏的下标

所以被打开的文件的fd是从3开始的
3. 重定向
3.1文件fd的分配规则
已知文件被进程所打开,需要找到task_struct{}中的 file_struct *files ,进而找到一个包含*file fd_array[]的结构体,然后根据这个指针数组找到数组所对应的下标fd
fd的分配规则:
从下标0开始往后找,找到空位值,填进去指针,指向文件的file结构体,每个文件都有一个file结构体
3.2 进程文件重定向
每个进程一开始都有三个隐藏的被打开文件:即
- stdin 标准输入
- stdout 标准输出
- stderror 标准错误
这三个是每个进程默认有的,所以fd的下标从3开始
这些是系统默认定好的,例如系统只会在1号(stdout)里打印出来东西,即printf()会往fd为1号的文件里打,然后再通过缓冲区打印到显示器
但是我们如果先把1号的文件即(stdout)给关闭,然后再创建一个文件,那么这个文件的fd按顺序分配就是1了,那么系统的printf()等输出则将输出到这个文件中了


在这个过程中,我们把fd为1号的指向改变了,就是一个重定向
在以上过程中,每次需要我们手动去关闭1号才能再发生重定向,这种删除后然后再创建的方式很不友好,有更简便的如下
有这么一个函数
int dup2(int **oldfd**,int **newfd** );
能让我们创建的fd的重定向
eg:
int fd=open(……..);//打开一个文件
dup(fd,1); //将原来1号位置的指向变成了fd指向的文件
把fd的内容>1的内容 ,1的内容变成fd的
3.3 父子进程之间的重定向
对于一个父进程,打开子进程后,因为进程拥有独立性,所以子进程的文件描述符表不是跟父进程公用的,是跟PCB一样,按照子进程的模板来创建的
原因 :如果父子进程公用一个文件描述符表,如果子进程发生了重定向,那么就会影响父进程,因为进程具有独立性,所以不能共享一个,但是子进程指向的0 1 2号 fd是指向的同一个
4. 如何理解Linux下一切皆文件
对于我们用的鼠标,键盘,显示器,网卡对应得软件层是驱动程序
在Linux下,对于所有的文件,定义了一个strcut file{}的结构体,这个结构体里有
变量的定义,函数指针的定义,这些函数指针就包括读函数,写函数,等诸多函数,因为每个文件的功能不一样,对应的操作不一样,以及每个文件的类型也不一样,需要的时候就去你对应的驱动等文件里找函数的实现,所以这就利用多态的思想
对于Linux系统而言,不管你是什么文件,都有着一样的定义,使用的时候去你文件里找对应的实际操作函数,即函数的实现,在strcut file{}中定义了函数定义,所以Linux下一切皆文件
eg:
struct file{
int flags;
int kind;
char * name;//定义变量
int (*write)();//写函数的声明
int (*read)();//读函数的声明
}
例如:
1.对于一个键盘设备,当作文件来看,键盘只具有读的操作,不需要写的操作那么就把写函数定义为空的函数,不执行
2.对于一个网卡,需要读和写,所以他的实现则需要写相应读函数和写函数的实现,让函数指针去指向然后去实现

这就多态的思想
5. 缓冲区
5.1 缓冲区的本质
缓冲区的本质就是一段内存,缓冲区其实是C语言(或者其他语言来申请的)
当我们向外设进行I/O的时候,向文件读取内容或者写入就是I/O因为外设相对内存CPU执行速度较慢,所以便产生了缓冲区的概念,先把输入/输出结果放到缓冲区里,然后再从缓冲区里读取,在空闲的时候CPU还能去执行其他的任务
所以缓冲区的出现,大大的节省系统的I/O时间
5.2 缓冲区的刷新策略
常见的刷新策略有:
- 立即刷新-------无缓冲
- 行刷新 --------行缓冲
- 缓冲区满-------全缓冲
对于行缓冲是给显示器用的,因为人的读取习惯就是按行读取,所以对于stdout或者显示器一般采用的是行缓冲
对于全缓冲是给磁盘文件的,则是对于磁盘读写文件时候的策略
还有两种刷新方式
- 用户强制刷新:调用fflush()函数
- 进程退出刷新缓冲区
5.2 缓冲区的位置
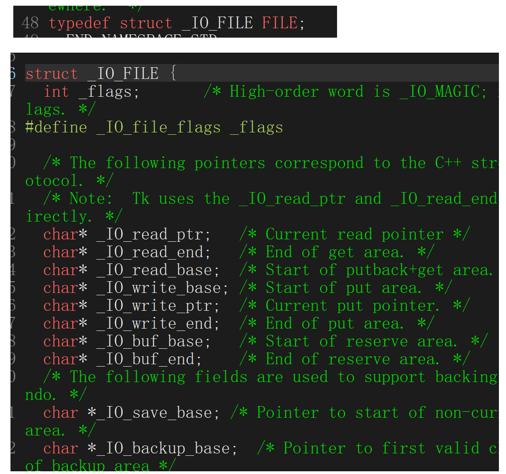
在C语言里,打开一个文件对应的结构体是Struct FILE{},这个FILE里包含了fd和一个buffer数组,数据先放入buffer数组里,根据不同的刷新策略在给系统调用然后再写入某些文件中
所以如果直接用fd进行系统调用写入,不会产生缓冲区,如果使用语言的库函数调用,则会用缓冲区
所以缓冲区不在内核中,而在我们语言结构体里,随着结构体的创建,所以buffer的本质就是一段内存
stdout,stdin,stderr---->c语言FILE*------>FILE结构体------>fd,.......,一个缓冲区
所以我们可以调用C函数fflush() 自主刷新
6. 文件系统
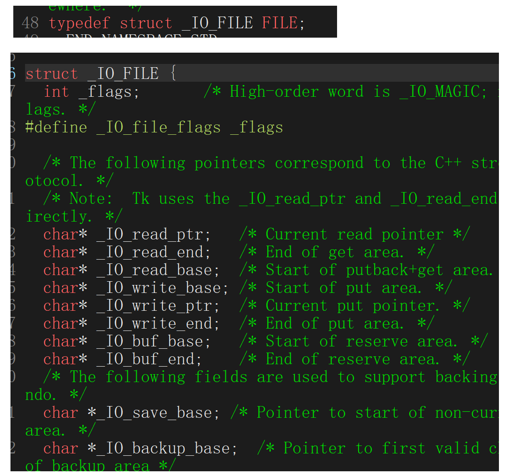
6.1 磁盘的物理结构
磁盘是计算机中唯一一个机械结构+外设,所以他的访问相对较慢一些
个人日常一般用不到磁盘,都被主流的ssd(固态硬盘)所替代了
磁盘现在大部分用于企业级用户等等
磁盘的组成:由一摞磁片,每个磁片的盘面都有一个磁头,磁头往盘面写内容,磁头与盘面的距离非常非常近,但是不接触
写入磁盘的方法:写的内容其实就是二进制,在机械中表达二进制的方式是带电和不带电,所以磁头可以给磁盘的地方让他带电或者不带即可表达二进制
6.2 磁盘的存储结构
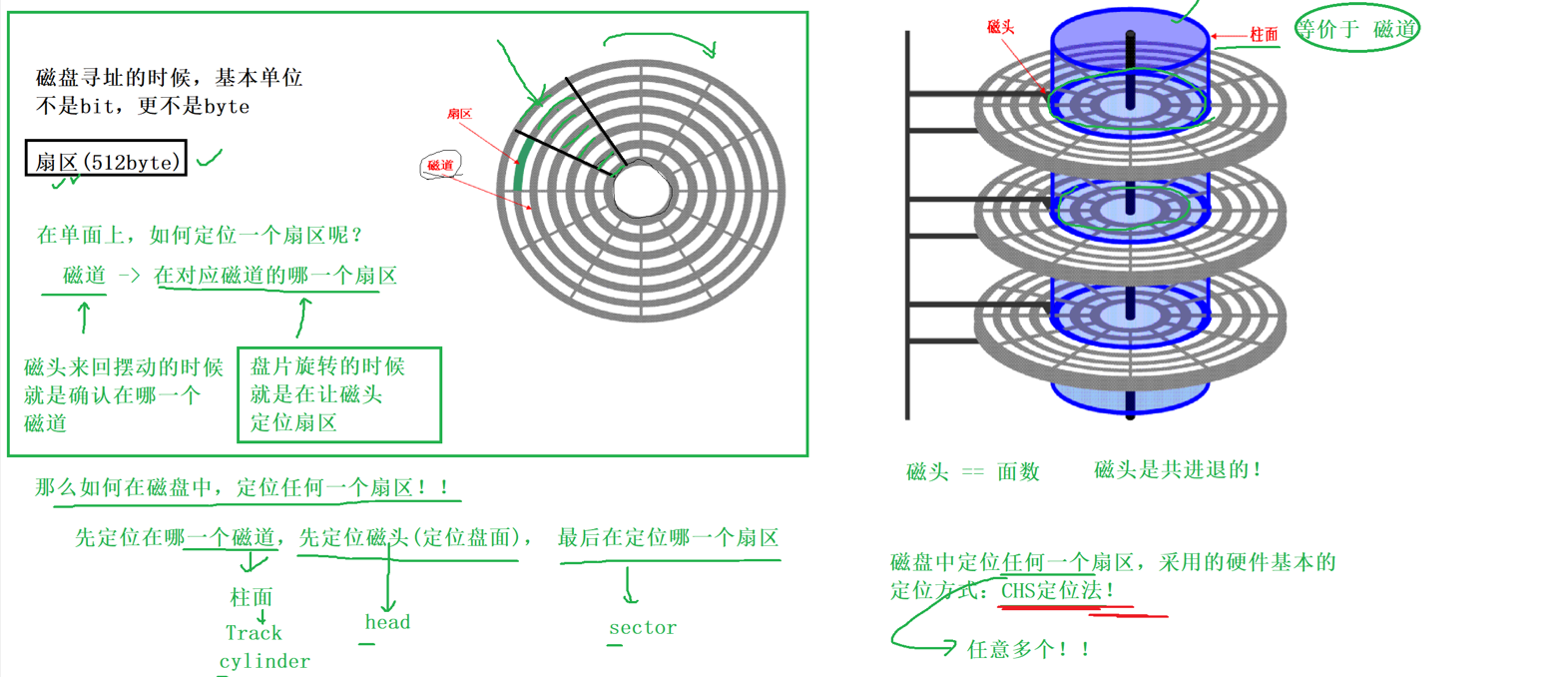
6.3 磁盘的逻辑结构
磁盘可以比作一个蚊香或者磁带,然后我们可以捋直,就是一个线性表的结构了
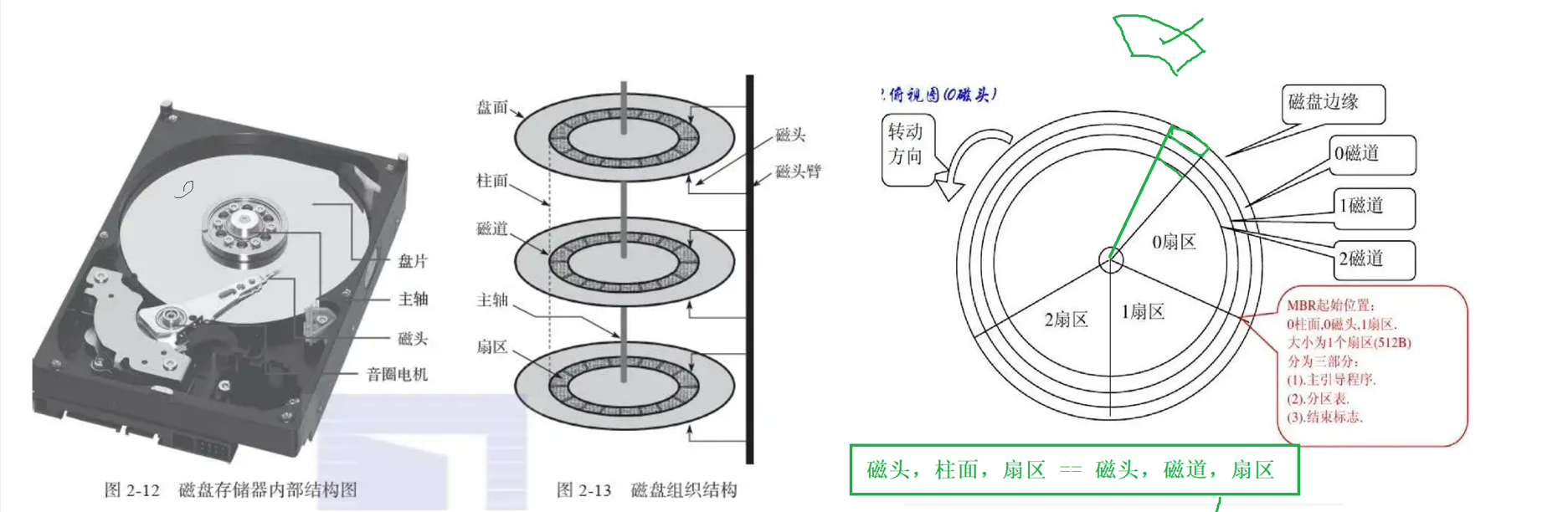
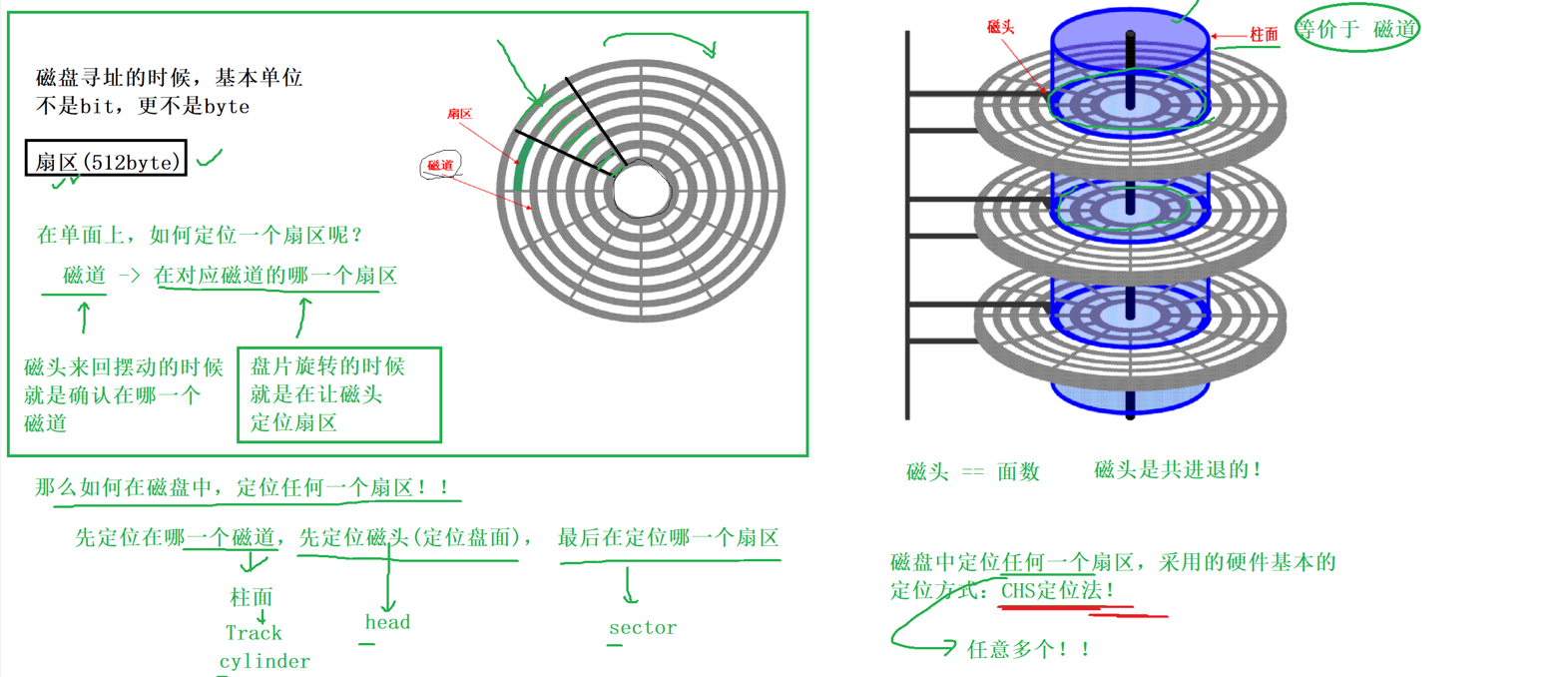
虽然一个扇区是512字节,但是依旧很小,OS进行的文件定制可以同时读写多个扇区,1K,2k,3k,4k等
由科学证明得出每次进行4K效率最高
内存就被划分了按4K大的空间-----页框
可执行程序/文件就是多个按照4K大小组成的块-----页框
那么怎么管理整个磁盘呢?
假设一个磁盘空间为500GB,这个空间很大,那么我们可以纷成多块,例如5块
每一块就是100GB,但是100GB依旧很大,我们可以分为5G每块,即分成20块区域
这就是分而治之的思想,我们管好这5GB,其他的区域照这个管理方式去进行即可
对于这5个G,也可以进行区域划分成多个组
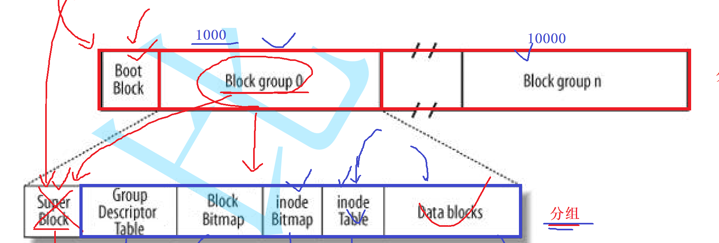
super Block:记录此 filesystem 的整体信息,包括inode/block的总量、使用量、剩余量, 以及文件系统的格式与相关信息等;一般有多个,因为需要备份,防止丢失
Group Descriptor Table: 块组描述表 ----->对应了分组的属性信息
Block Bitmap : 记录使用与未使用的 block 号码,并在进行文件添加修改时候对应的修改 block 的使用状况
inode Bitmap : 记录使用与未使用的 inode 号码,并在进行文件添加修改时候对应的修改 inode 的使用状况
inode Table (inode表) : 保存了所有的(使用+未使用)的inode,以及文件的属性
Data blocks : 数据块
文件=内容+属性
文件的内容 在Data blocks里存储的
文件的属性 在indoe里存储的
- 每个文件都有一个inode
- inode为了区分彼此,每个inode有不同的ID
- 查找一个文件的时候统一只用inode编号查的
- inode的前缀在每个组是不一样的

那么怎么根据inode来查找对应的文件呢?
struct inode{
int ID;
uid;
gid;
size;
......
int bolcks[15];//有一个数组,这个数组每个元素指向Data
}
在inode里有一个数组,这个数组每个元素存着对应的Data blocks的块号,所以按顺序往下读写
我们可以知道,即使是15个Data block也很小

所以当空间大的时候单纯的15个block是不够的,需要用到多级索引的办法,在这个数组从13号位置开始就是指向了一个Data blocks的区域,这个区域里的内容是一个指向其他Data blocks编号的表,所以可以扩大使用空间,如果空间还不够那么就继续用三级索引,这样下来,空间其实非常大了

当一个文件被删除时候,其实数据没有被删除,一个文件被删除,那么他对应的inode bitmap被置为0,inode table变成未使用,其实就是删除了映射关系,原来的数据块因为没有了限制,所以可以被新的文件当作新的数据块所使用
对于一个目录,目录存放的Data blocks的内容其实就是一个inode和文件名一一对应的映射关系,存放在了目录下,所以一般查找文件是用文件名查找的,这就是为什么同一个目录下不能有相同的文件名
细节问题:其实在电脑开机时候,文件系统inode的位图等都预加载到内存中了,因为删一个文件,需要把磁盘对应的inodebitmap置为0,但是我们不能直接与外设打交道,根据冯诺依曼体系,所以都是通过内存来打交道的
7. 软硬链接
软硬链接的区别:有没有独立的
inode
7.1硬链接
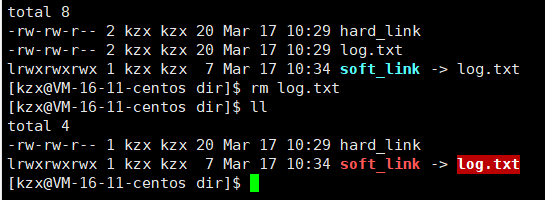
- 建立硬链接:
ln 源文件名 硬链接文件名
在以上文件系统中,可以理解:
在磁盘中查找一个文件是通过inode的,那么对于一个目录下的文件,这个目录下存的其实是文件名和inode的映射关系
那么我们可以创建多个映射关系到同一个inode中,也就是多个映射关系,在这个目录里并没有创建新的文件以及新的inode,只是在这个目录的Data block里创建了一个新的映射关系而已
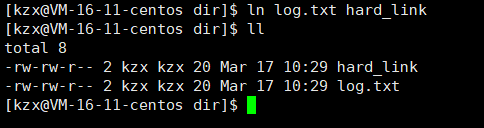

如上图就是一个硬链接,两个文件的inode是一样的,其实就是在目录下创建了一个较hard_link与这个文件inode的映射关系
- 硬链接的引用计数 : 可以看到上边有个数字2,这个就是有多少个文件链接到了他,就是有多少个映射到了同一个inode,这个引用计数原理跟智能指针原理类似
- 当一个文件被删除,实际上是当一个inode的引用计数为0时(即不在有映射关系),此时才会在文件系统中把相应的位图置为0
- 当一个文件的硬链接数为0时,这个文件才被删除
7.2软链接
- 建立软链接:
ln -s sourceFile LinkName
ln是link的缩写,-s后边跟源文件(sourceFile) ,LinkName代表链接的命名名字
软链接会产生新的inode即代表他是一个新文件,这个文件里的内容实际上就是软链接对应的文件名和路径,就是每次去指定路径下找到对应的文件名,如果把那个文件删掉,那么软链接就失效了
- 断开软链接:
unlink 软连接名称