常用模块【四】正则表达式
一 正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式是用来匹配字符串非常强大的工具,在其他编程语言中同样有正则表达式的概念,Python同样不例外,利用了正则表达式,我们想要从返回的页面内容提取出我们想要的内容就易如反掌了。
正则表达式的大致匹配过程是:
1.依次拿出表达式和文本中的字符比较,
2.如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。
3.如果表达式中有量词或边界,这个过程会稍微有一些不同。
| 符号 | 说明 | 实例 |
|---|---|---|
| . | 表示任意字符,如果说指定了 DOTALL 的标识,就表示包括新行在内的所有字符。 | 'abc' >>>'a.c' >>>结果为:'abc' |
| ^ | 表示字符串开头。 | 'abc' >>>'^abc' >>>结果为:'abc' |
| $ | 表示字符串结尾。 | 'abc' >>>'abc$' >>>结果为:'abc' |
| *, +, ? | '*'表示匹配前一个字符重复 0 次到无限次,'+'表示匹配前一个字符重复 1次到无限次,'?'表示匹配前一个字符重复 0 次到1次 |
'abcccd' >>>'abc*' >>>结果为:'abccc' 'abcccd' >>>'abc+' >>>结果为:'abccc' 'abcccd' >>>'abc?' >>>结果为:'abc' |
| *?, +?, ?? | 前面的*,+,?等都是贪婪匹配,也就是尽可能多匹配,后面加?号使其变成惰性匹配即非贪婪匹配 |
'abc' >>>'abc*?' >>>结果为:'ab' 'abc' >>>'abc??' >>>结果为:'ab' 'abc' >>>'abc+?' >>>结果为:'abc' |
| {m} | 匹配前一个字符 m 次 | 'abcccd' >>>'abc{3}d' >>>结果为:'abcccd' |
| {m,n} | 匹配前一个字符 m 到 n 次 | 'abcccd' >>> 'abc{2,3}d' >>>结果为:'abcccd' |
| {m,n}? | 匹配前一个字符 m 到 n 次,并且取尽可能少的情况 | 'abccc' >>> 'abc{2,3}?' >>>结果为:'abcc' |
| \ | 对特殊字符进行转义,或者是指定特殊序列 | 'a.c' >>>'a\.c' >>> 结果为: 'a.c' |
| [] | 表示一个字符集,所有特殊字符在其都失去特殊意义,只有: ^ - ] \ 含有特殊含义 | 'abcd' >>>'a[bc]' >>>结果为:'ab' |
| | | 或者,只匹配其中一个表达式 ,如果|没有被包括在()中,则它的范围是整个正则表达式 | 'abcd' >>>'abc|acd' >>>结果为:'abc' |
| ( … ) | 被括起来的表达式作为一个分组. findall 在有组的情况下只显示组的内容 | 'a123d' >>>'a(123)d' >>>结果为:'123' |
| (?#...) | 注释,忽略括号内的内容 特殊构建不作为分组 | 'abc123' >>>'abc(?#fasd)123' >>>结果为:'abc123' |
| (?= … ) | 表达式’…’之前的字符串,特殊构建不作为分组 | 在字符串’ pythonretest ’中 (?=test) 会匹配’ pythonre ’ |
| (?!...) | 后面不跟表达式’…’的字符串,特殊构建不作为分组 | 如果’ pythonre ’后面不是字符串’ test ’,那么 (?!test) 会匹配’ pythonre ’ |
| (?<= … ) | 跟在表达式’…’后面的字符串符合括号之后的正则表达式,特殊构建不作为分组 | 正则表达式’ (?<=abc)def ’会在’ abcdef ’中匹配’ def ’ |
| (?:) | 取消优先打印分组的内容 | 'abc' >>>'(?:a)(b)' >>>结果为'[b]' |
| ?P<> | 指定Key | 'abc' >>>'(?P<n1>a)>>>结果为:groupdict{n1:a} |
1 正则表达式特殊序列
| 特殊表达式序列 | 说明 |
|---|---|
| \A | 只在字符串开头进行匹配。 |
| \b | 匹配位于开头或者结尾的空字符串 |
| \B | 匹配不位于开头或者结尾的空字符串 |
| \d | 匹配任意十进制数,相当于 [0-9] |
| \D | 匹配任意非数字字符,相当于 [^0-9] |
| \s | 匹配任意空白字符,相当于 [ \t\n\r\f\v] |
| \S | 匹配任意非空白字符,相当于 [^ \t\n\r\f\v] |
| \w | 匹配任意数字和字母,相当于 [a-zA-Z0-9_] |
| \W | 匹配任意非数字和字母的字符,相当于 [^a-zA-Z0-9_] |
| \Z | 只在字符串结尾进行匹配 |
1 import re 2 # . 通配符 3 print(re.findall("d..h","asdfghjkl")) 4 # ^ 以什么开头 5 print(re.findall("^dh","dhasdfghjkl")) 6 # $ 以什么结尾 7 print(re.findall("dh$","dhasdfghjkldh")) 8 # * [0,∞ ] 9 print(re.findall("dha*","dhasdfghjkldh")) 10 # + [1,∞ ] 11 print(re.findall("dh+","dhasdfghjkldh")) 12 # ? [0,1] 13 print(re.findall("ghx?","dhasdfghxxxx")) 14 # {0,}==* {1,}==+ {0,1}==? 15 print(re.findall("ghx{4}","dhasdfghxxxx")) #重复x 4次 16 print(re.findall("ghx{1,4}","dhasdfghxx")) #重复x 1到4次 17 #注意,前面的*,+,?等都是贪婪匹配,也就是尽可能的匹配,后面加?号使其变成惰性匹配 18 print(re.findall("ghx*?","dhasdfghxx")) #按最少的去匹配 19 print(re.findall("ghx+?","dhasdfghxx")) #按最少的去匹配 20 #---------------------------------------------------------------------------- 21 #元字符之字符集[] 中口号中最少有一个,字符集中只有\,^,-是特殊符号 22 # [] 相当于或 23 print(re.findall("g[hz]","dhghafgzxx")) 24 # - 25 print(re.findall("[a-z]","dhghafgzxx")) 26 print(re.findall("g[a-z]*","dhghafgzxx")) 27 print(re.findall("g[0-9]*","g8dhghafgzxx")) 28 # 字符集中的 ^ 相当于非 29 print(re.findall("g[^a-z]","sadffg54172"))
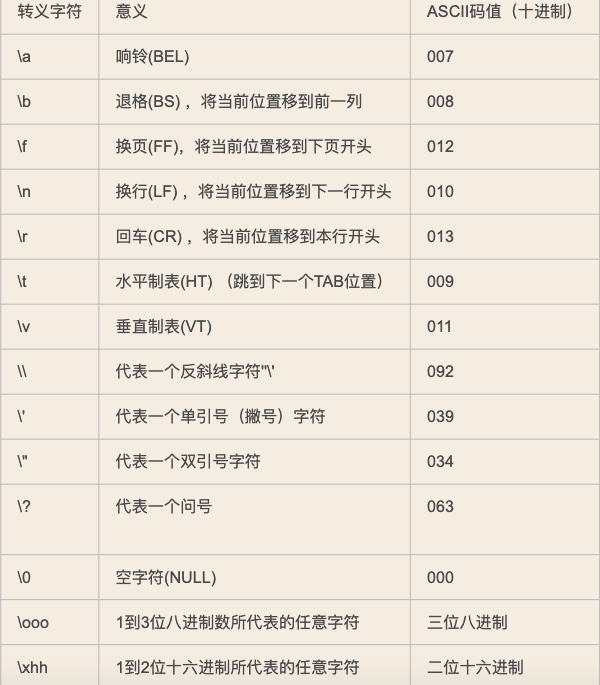
2 转义字符
3 re模块下的方法
正则表达式是对字符串的最简约的规则的表述。python也有专门的正则表达式模块re.
| 正则表达式函数 | 释义 |
| re.match() | 从头开始匹配,匹配失败返回None,匹配成功可通过group(0)返回匹配成功的字符串 |
| re.search() | 扫描整个字符串,并返回第一个匹配的字符串 |
| re.sub() | 对符合要求的所有子串进行替换 |
| re.findall() | 以列表形式返回所有符合条件的子串 |
| re.split() | 以模式作为切分符号切分字符串,并返回列表 |
| re.finditer() | 找到 RE 匹配的所有子串,并把它们作为一个迭代器返回 |
| re.compile() | 把那些经常使用的正则表达式编译成正则表达式对象 |
| re.group() | 返回被 RE 匹配的字符串 |
| re.start() | 返回匹配开始的位置 |
| re.end() | 返回匹配结束的位置 |
| re.span() | 返回一个元组包含匹配 (开始,结束) 的位置 |
正则练习


1 - re.fandall 2 #返回所有满足条件的匹配结果,再放列表里 3 4 print(re.findall("[a-z]","dhghafgzxx")) 5 6 7 - re.search 8 # re.search 匹配字符串里面的,只要找到一个就不再往后面找了 9 10 # ?P<name> 固定格式 name是分组的名称 11 # 注意res是一个对象 12 # 通过调用group方法取出对象中的结果 13 res = re.search("(?P<name>[a-z]+)(?P<age>\d+)", "szx18alex38") 14 print(res.group("age")) 15 16 17 - re.match 18 #从头开始匹配,匹配失败返回None,匹配成功可通过group(0)返回匹配成功的字符串 19 20 print(re.match('\d+' ,'1342abcccd' ).group()) #1342 21 22 23 - re.split 24 #先按"a"分割得到""和"bcd",在对""和"bcd"分别按"b"进行分割 25 26 print(re.split('[ab]' ,'abcd' )) #['', '', 'cd'] 27 28 29 -re.sub 30 #替换 2表示替换几次 31 32 print(re.sub('\d','A' ,'1342abcccd',2)) 33 34 35 - re.subn 36 #把结果做成一个元祖,第一个是匹配的内容,第二个是匹配的次数 37 38 print(re.subn('\d','A' ,'1342abcccd',2)) 39 40 - re.compile 41 #把那些经常使用的正则表达式编译成正则表达式对象 42 43 com = re.compile('\d+') 44 print(com.findall("eubc114")) 45 46 - re.finditer 47 #找到 RE 匹配的所有子串,并把它们作为一个迭代器返回 48 rec = re.finditer("\d","eubc114") 49 for i in rec: 50 print(i) 51 52 53 #分组提取() 优先提取分组的值 54 print(re.findall("www\.(baidu|163)\.com","www.baidu.com")) #['baidu'] 55 print(re.findall("www\.(?:baidu|163)\.com","www.baidu.com"))#['www.baidu.com']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号