Kuberentes-入门
什么是Kubernetes
Kubernetes是一个跨主机集群的开源容器调度平台,它可以自动化应用的部署、扩展和操作,提供以容器为中心的基础架构。
Kubernetes项目由Google公司在2014年启动,kubernetes建立在Google公司超过十余年的运维经验基础之上,Google所有的应用都运行在容器上。
Kubernetes的特点
Kubernetes是一种用于在一组主机上运行和协同容器化应用程序的系统,旨在提供可预测性、可扩展性与高可用性的方法来完全管理容器化应用程序和服务的生命周期的平台。用户可以定义应用程序的运行方式,以及与其他应用程序或外部世界交互的途径,并能实现服务的扩容和缩容,执行平滑滚动更新,以及在不同版本的应用程序之间调度流量以测试功能或回滚有问题的部署。Kubernetes提供了接口和可组合的平台原语,使得用户能够以高度的灵活性和可靠性定义及管理应用程序。简单总结起来,它具有以下几个重要特性。
- 自动装箱
建构于容器之上,基于资源依赖及其他约束自动完成容器部署且不影响其可用性,并通过调度机制混合关键型应用和非关键型应用的工作负载于同一节点以提升资源利用率。
- 自我修复(自愈)
支持容器故障后自动重启、节点故障后重新调度容器,以及其他可用节点、健康状态检查失败后关闭容器并重新创建等自我修复机制。
- 水平扩展
支持通过简单明了或UI手动水平扩展,以及基于CPU等资源负载率的自动水平扩展机制。
- 服务发现和负载均衡
Kubernetes通过其附加组件之一的KubeDNS(或CoreDNS)为系统内置了服务发现功能,它会为每个Service配置DNS名称,并允许集群内的客户端直接使用此名称发出访问请求,而Service则通过iptables或ipvs内建了负载均衡机制。
- 自动发布和回滚
Kuberntes支持“灰度”更新应用程序或其配置信息,它会监控更新过程中应用程序的健康状态,以确保它不会同一时刻杀掉所有实例,而此过程中一旦有故障发生,就会立即自动执行回滚操作。
- 密钥和配置管理
Kubernetes的ConfigMap实现了配置数据与Docker镜像解耦,需要时,仅对配置做出变更而无需重新构建Docker镜像,这为应用开发部署带来了很大的灵活性。此外,对于应用所依赖的一些敏感数据,如用户名和密码、令牌、密钥等信息,Kubernetes专门提供了Secret对象为其解耦,既便利了应用的快速开发和交付,又提供了一定程度上的安全保障。
- 存储编排
Kubernetes支持Pod对象按需自动挂载不同类型的存储系统,这包括节点本地存储、公有云服务商的云存储(如AWS和GCP等),以及网络存储系统(例如,NFS、ISCSI、GlusterFS、Ceph、Cinder和Flocker等)。
- 批量处理执行
除了服务型应用,kubernetes还支持批处理作业及CI(持续集成),如果需要,一样可以实现容器故障后恢复。
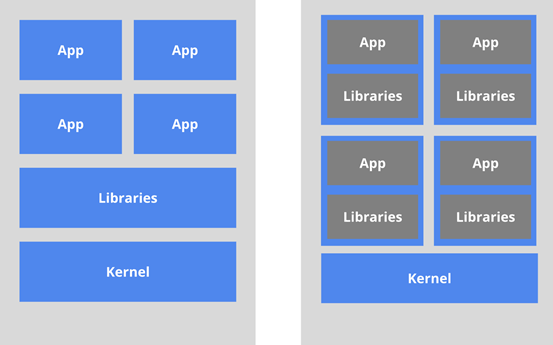
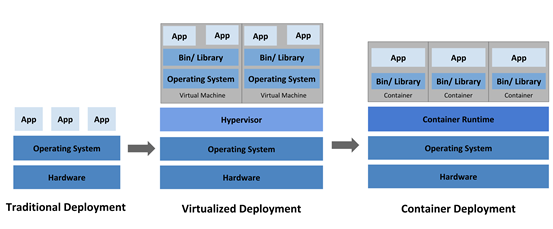
传统部署、虚拟化部署、容器部署
Kubernetes基本概念和术语
Master
Master是集群的网关和中枢,负责诸如为用户和客户端暴露API、跟踪其他服务器的健康状态、以最优调度工作负载,以及编排其他组件之间的通信等任务,它是用户或客户端与集群之间的核心联络点,并负责Kubernetes系统的大多数集中式管控逻辑。
Node
Node是Kubernetes集群的工作节点,负责接收来自Master的工作指令病根据指令相应地创建或销毁Pod对象,以及调整网络规则以合理地路由和转发流量等。
Node节点可以在运行期间动态增加到Kubernetes集群中,前提是这个节点上已经正确安装、配置和启动了上述关键进程,在默认情况下Kubelet会向Master注册自己,这也是Kubernetes推荐的Node管理方式。一旦Node被纳入集群管理范围,kubelet进程就会定时向Master节点回报自身的情报,例如操作系统、Docker版本、机器的CPU和内存情况,以及当前有哪些Pod在运行等,这样Master可以获知每个Node的资源使用情况,并实现高效均衡的资源调度策略。而某个Node超过指定时间不上报信息时,会被Master判定为”失联”,Node的状态被标记为不可用(Not Ready),随后Master会触发”工作负载大转移”的自动流程。
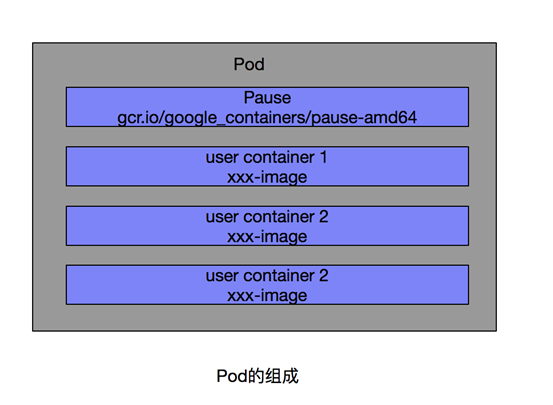
Pod
Pod是Kubernetes的最重要也是最基本的概念,如下图所示,是Pod的组成示意图,我们看到每个Pod都有一个特殊的被称为“根容器”的Pause容器对应的镜像属于Kubernetes平台的一部分,除了Pause容器,每个Pod还包含一个或多个紧密相关的用户业务容器。
为什么Kubernetes会设计出一个全新的Pod概念并且Pod有这样特殊的组成结构?
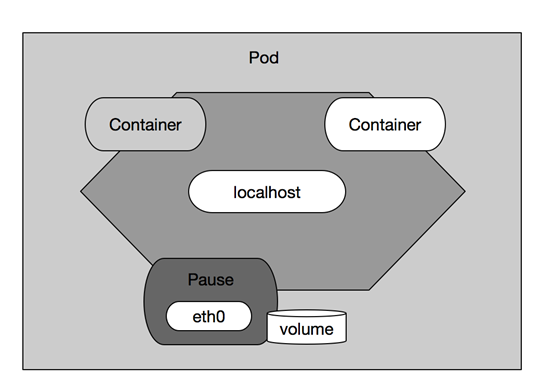
原因之一:在一组容器作为一个单元的情况下,我们难以对“整体”简单地进行判断及有效地进行行动。比如,一个容器死亡了,此时算是整体死亡么?是N/M的死亡率么?引入业务无关并且不易死亡的Pause容器作为Pod的根容器,以它的状态代表整个容器组的状态,就简单、巧妙地解决了这个难题。
原因之二:Pod里的多个业务容器共享Pause容器的IP,共享Pause容器挂载的Volume,这样既简化了密切关联的业务容器之间的通信问题,也很好地解决了它们之间的文件共享的问题。
Kubernetes为每个Pod都分配了唯一的IP地址,称之为Pod IP,一个Pod里的多个容器共享Pod IP地址。Kubernetes要求底层网络支持集群内任意两个Pod之间的TCP/IP直接通信,这通常采用虚拟二层网络技术来实现,例如Flannel、Openvswitch等,因此我们需要牢记一点:在Kubernetes里,一个Pod里的容器与另外主机上的Pod容器能够直接通信。
Pod有两种类型:普通的Pod机静态Pod(static Pod),后者比较特殊,它并不存在Kubernetes的etcd存储里,而是存在某个具体的Node上的一个具体文件中,并且只在此Node上启动运行。而普通的Pod一旦被创建,就会被放入到etcd中存储,随后会被Kubernetes Master调度到某个具体的Node上并进行绑定(Binding),随后该Pod被对应的Node上的Kubelet进程实例化成一组相关的Docker容器并启动起来。在默认情况下,当Pod里的某个容器停止时,Kubernetes会自动检测到这个问题并且重新启动这个Pod(重启Pod里的所有容器),如果Pod所在的Node宕机,则会将这个Node上的所有Pod重新调度到其他节点上。Pod、容器与Node的关系如下图所示:
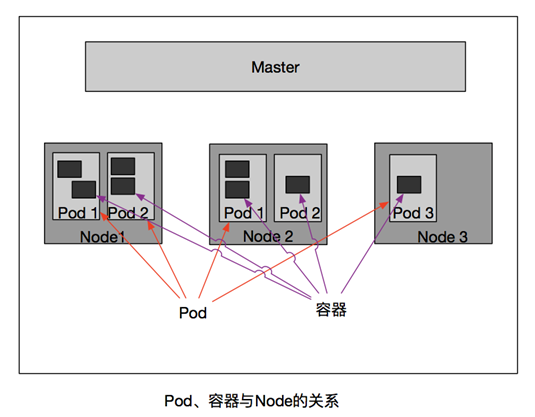
Label(标签)
资源标签
标签(Label)是将资源进行分类的标识符,资源标签其实就是一个键值型(key/values)数据。标签旨在指定对象(如Pod、Service、RC等)辨识性的属性,一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到仁义数量的资源对象上去,Label通常在资源对象定义时确定,也可以在对象创建后动态添加或删除,这些属性仅对用户存在特定的意义。
Label Selector(标签选择器)
标签选择器(Selector)全称为“Label Selector”,它是一种根据Label来过滤符合条件的资源对象的机制。
Pod控制器
尽管Pod是Kubernetes的最小调度单元,但用户通常不会直接部署及管理Pod对象,而是要借助于另一类抽象——控制器(Controller)对其进行管理。用于工作负载的控制器是一种管理Pod生命周期的资源抽象,它们是Kubernetes上的一类对象,而非单个资源对象,包括ReplicationController、ReplicaSet、Deployment、Statefulset、Job等。
服务资源(Service)
Service是建立在一组Pod对象之上的资源抽象,它通过标签选择器选定一组Pod对象,并为这组Pod对象定义一个统一的固定访问入口(通常是一个IP地址),若Kubernetes集群存在DNS附件,它就会在Service创建时为其自动配置一个DNS名称以便客户端进行服务发现。到达Service IP的请求将贝负载均衡至其后的端点——各个Pod对象之上,因此Service从本质上来讲是一个四层代理服务。另外,Service还可以将集群外部流量引入到集群中来。
存储卷(Volume)
存储卷(Volume)是独立于容器文件系统之外的存储空间,常用于扩展容器的存储空间为它提供持久存储能力。Kubernetes集群上的存储大体可分为临时卷、本地卷和网络卷。临时卷和本地卷都位于Node本地,一旦Pod被调度至其他Node,此种类型的存储卷将无法访问到,因此临时卷和本地卷通常用于数据缓存,持久化的数据则需要放置于持久卷(persistent volume)之上。
Name和NameSpace
名称(Name)是Kubernetes集群中资源对象的标识符,它们的作用域通常是名称空间(namespace),因此名称空间是名称的额外的限定机制。在同一个名称空间中,同一类型资源对象的名称必须具有唯一性。名称空间通常用于实现租户或项目的资源隔离,从而形成逻辑分组,创建的Pod和Service等资源对象都属于名称空间级别,未指定时,它们都属于默认的名称空间“default”。
Annotation
Annotaion(注解)是另一种附加在对象之上的键值类型的数据,但它拥有更大的数据容量。Annotation常用于将各种非标示型元数据(metadata)附加到对象上,但它不能用于表示和选择对象,通常也不会被kubrnetes直接使用,其主要目的是方便工具或用户的阅读及查找等。
Ingress
Kubernetes将Pod对象和外部网络环境进行了隔离,Pod和Service等对象间的通信都使用其内部专用地址进行,如若需要开放某些Pod对象提供给外部用户访问,则需要为其请求流量打开一个通往Kubernetes集群内部的通道,除了Service之外,Ingress也是这类通道的实现方式之一。
Kubernetes集群组件
一个典型的Kubernetes集群由多个工作节点(worker node)和一个集群控制平面(Control plane,即Master),以及一个集群状态存储系统(etcd)组成。其中Master节点负责整个集群的管理工作,为集群提供管理接口,并监控和编排集群中的各个工作节点。各节点负责以Pod的形式运行容器,因此,各节点需要事先配置好容器运行依赖到的所有服务和资源,如容器运行时环境等。Kubrnetes的系统架构如下图所示:
Master节点主要由apiserver、controller-manager和scheduler三个组件,以及一个用于集群状态存储的etcd存储服务组成,而每个Node节点则主要包含kubelet、kube-proxy及容器引擎(Docker是最为常用的实现)等组件。此外,完整的集群服务还依赖于一些附加组件,如KubeDNS等。
Master组件
- API Server
API Server负责输出RESTful风格的kubernetes API,它是发往集群的所有REST操作命令的接入点,并负责接收、校验并响应所有的REST请求,结果状态被持久存储于etcd中。因此,API Server是整个集群的网关。
- 集群状态存储(Cluster State Store)
Kubernetes集群的所有状态信息都需要持久化存储系统etcd中,不过,etcd是由CoreOS基于Raft协议开发的分布式键值存储,可用于服务发现、共享配置以及一致性保障(如数据库主节点选择、分布式锁等)。因此,etcd是独立的服务组件,并不隶属于kubernetes集群自身。
etcd不仅能够提供键值数据存储,而且还为其提供了监听(watch)机制,用于监听和推送变更。Kubernetes集群系统中,etcd中的键值发生变化时会通知到API Server,并由其通过watch API向客户端输出。基于watch机制,kubernetes集群的各组件实现了高效协同。
- 控制器管理器(Controller Manager)
Kubernetes中,集群级别的大多数功能都是由几个被称为控制器的进程执行实现的,这几个进程被集成于kube-controller-manager守护进程中。由控制器完成的功能主要包括生命周期功能和API业务逻辑,具体如下。
-
- 生命周期功能:包括Namespace创建和生命周期、Event垃圾回收、Pod终止相关的垃圾回收、级联垃圾回收及Node垃圾回收等。
- API业务逻辑:例如,由ReplicaSet执行的Pod扩展等。
- 调度器(Scheduler)
Kubernetes是用于部署和管理大规模容器应用的平台,根据集群规模的不同,其托管运行的容器很可能会数以千计甚至更多。API Server确认Pod对象的创建请求之后,便需要由Scheduler根据集群内各节点的可用资源状态,以及要运行的容器的资源需求作出调度决策,其工作逻辑如下图所示。另外,Kubernetes还支持用户自定义调度器。
Node组件
Node负责提供运行容器的各种依赖环境,并接受Master的管理。每个Node主要由以下几个组件构成。
- Node的核心代理程序kubelet
Kubelet是运行于工作节点之上的守护进程,它从API Server接受关于Pod对象的配置信息并确保它们处于期望的状态(desired state)。Kubelete会在API Server上注册当前工作节点,定期向Master回报节点资源使用情况,并通过cAdvisor监控容器和节点的资源占用状况。
- 容器运行时环境
每个Node都要提供一个容器运行时(Container Runtime)环境,它负责下载镜像并运行容器。Kubelet并未固定链接至某容器运行时环境,而是以插件的方式载入配置的容器环境。这种方式清晰地定义了各组件的边界。目前,kubernetes支持的容器运行环境至少包括Docker、RKT、cri-o和Fraki等。
- Kube-proxy
每个工作节点都需要运行一个kube-proxy守护进程,它能够按需要为Service资源对象生成iptables或ipvs规则,从而捕获访问当前Service的ClusterIP的流量并将其转发至挣钱的后端Pod对象。
核心附件
Kubernetes集群还依赖于一组称为“附件”(add-ons)的组件以提供完整的功能,它们通常是由第三方提供的特定应用程序,且托管运行于Kubernetes集群之上。
下面列出的几个附件各自为集群从不同角度引用了所需的核心功能。
- KubeDNS:在Kubernetes集群中调度运行提供DNS服务的Pod,同一集群中的其他Pod可使用此DNS服务解决主机名。Kubernetes 自1.11版本开始默认使用CoreDNS项目为集群提供服务注册和服务发现的动态名称解析服务,之前的版本中用到的是kube-dns项目,而SkyDNS则是更早一代的项目。
- Kubernetes Dashboard:Kubernetes集群的全部功能都要基于Web的UI,来管理集群中的应用甚至是集群自身。
- Heapster:容器和节点的性能监控与分析系统,它收集并解析多种指标数据,如资源利用率、生命周期事件等。新版本的Kubernetes中,其功能会逐渐由Prometheus结合其他组件所取代。
- Ingress Controller:Service是一种工作于传统层的负载均衡器,而Ingress是在应用层实现的HTTP(S)负载均衡机制。不过,Ingress资源自身并不能进行“流量穿透”,它仅是一组路由规则的集合,这些规则需要通过Ingress控制器(Ingress Controller)发挥作用。目前,此类的可用项目有Nignx、Traefik、Envoy及HaProxy等。
kubernetes安装与配置
- minikube
Minikube是一个工具,可以在本地快速运行一个单点的Kubernetes或日常开发的用户使用。
部署地址:https://kubernetes.io/docs/setup/minikube/
- kubeadm (证书默认是1年,到期后更改比较麻烦)
kubeadm也是一个工具,提供kubeadm init和kubeadm join用于快速部署Kubernetes集群。
部署地址:https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/
- 二进制
推荐,从官方下载发行版的二进制包,手动部署每个组件,组成Kubernetes集群。
下载地址:https://github.com/kubernetes/kubernetes/releases
基础环境要求
- 每台服务器内存至少2GB
- CPU至少2C
- 集群中所有机器的网络彼此均能相互连接(内网或公网都可以)
- 节点之中不可以有重复的主机名、MAC 地址或 product_uuid
- 开启主机上的一些特定端口
- 禁用 Swap 交换分区。为了保证 kubelet 正确运行,您必须禁用交换分区。
4.1.1 确保每个节点上MAC地址和product_uuid的唯一性
- 可以使用命令ip link 或 ifconfig -a来获取网络接口的MAC地址
- 查看product_uuid使用命令
cat /sys/class/dmi/id/product_uuid
4.1.2 检查所需端口
- Master节点
|
协议 |
方向 |
端口范围 |
作用 |
使用者 |
|
TCP |
Inbound |
6443 |
Kubernetes API server |
ALL |
|
TCP |
Inbound |
2379~2380 |
Etcd server client API |
Kube-apiserver,etcd |
|
TCP |
Inbound |
10250 |
Kubelet API |
Self,Control plane |
|
TCP |
Inbound |
10251 |
Kube-scheduler |
Self |
|
TCP |
Inbound |
10252 |
Kube-controller-manager |
Self |
- Node节点
|
协议 |
方向 |
端口范围 |
作用 |
使用者 |
|
TCP |
Inbound |
10250 |
Kubelet API |
Self,Control plane |
|
TCP |
Inbound |
30000-32767 |
NodePort Services |
ALL |
- 推荐配置
|
软硬件 |
最低配置 |
推荐配置 |
|
CPU和内存 |
Master: 至少2Core和4G内存 Node:至少4core和16GB |
Master:4Core和16GB内存 Node:应根据需要运行的容器数量进行配置 |
|
Linux操作系统 |
Kernel版本要求在3.10及以上 |
CentOS 7 |
|
Docker |
1.9版本及以上 |
|
|
etcd |
2.0版本及以上 |
|
安装Docker
官方文档:https://docs.docker.com/install/linux/docker-ce/centos/
yum -y install yum-utils device-mapper-persistent-data lvm2 rpm -ivh http://mirrors.aliyun.com/epel/epel-release-latest-7.noarch.rpm yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo yum -y install docker-ce
内核参数优化
由于iptables被绕过导致网络请求被错误路由,需要设net.bridge.bridge-nf-call-iptables 为1
cat <<EOF > /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF sysctl --system
配置加速器
systemctl start docker systemctl status docker systemctl stop docker systemctl status docker cat > /etc/docker/daemon.json <<EOF { "registry-mirrors": ["https://registry.docker-cn.com"], "exec-opts": ["native.cgroupdriver=systemd"], "log-driver": "json-file", "log-opts": { "max-size": "100m" }, "storage-driver": "overlay2", "storage-opts": [ "overlay2.override_kernel_check=true" ] } EOF systemctl daemon-reload systemctl enable docker systemctl start docker systemctl status docker
使用Kubeadm工具快速安装Kubernetes集群
官方文档:https://v1-14.docs.kubernetes.io/docs/home/
配置kubernetes yum源
- 国内
cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 EOF
- 关闭selinux和firewalld
setenforce 0 sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config systemctl disable firewalld
部署Master节点
官方文档:https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
-
安装kubeadm
yum list kubelet kubeadm kubectl --showduplicates|sort -r #查看版本 yum install kubectl-1.14.3-0 kubelet-1.14.3-0 kubeadm-1.14.3-0 --disableexcludes=kubernetes -y systemctl enable --now kubelet
-
下载相关镜像
##############################方法一################################ docker pull runcc/pause:3.1 docker tag runcc/pause:3.1 k8s.gcr.io/pause:3.1 docker pull runcc/kube-scheduler:v1.14.3 docker tag runcc/kube-scheduler:v1.14.3 k8s.gcr.io/kube-scheduler:v1.14.3 docker pull runcc/kube-apiserver:v1.14.3 docker tag runcc/kube-apiserver:v1.14.3 k8s.gcr.io/kube-apiserver:v1.14.3 docker pull runcc/kube-controller-manager:v1.14.3 docker tag runcc/kube-controller-manager:v1.14.3 k8s.gcr.io/kube-controller-manager:v1.14.3 docker pull runcc/flannel:v0.11.0-amd64 docker tag runcc/flannel:v0.11.0-amd64 quay.io/coreos/flannel:v0.11.0-amd64 docker pull runcc/coredns:1.3.1 docker tag runcc/coredns:1.3.1 k8s.gcr.io/coredns:1.3.1 docker pull runcc/etcd:3.3.10 docker tag runcc/etcd:3.3.10 k8s.gcr.io/etcd:3.3.10 docker pull runcc/kubernetes-dashboard-amd64:v1.10.1 docker tag runcc/kubernetes-dashboard-amd64:v1.10.1 k8s.gcr.io/kubernetes-dashboard-amd64:v1.10.1 docker pull runcc/kube-proxy:v1.14.3 docker tag runcc/kube-proxy:v1.14.3 k8s.gcr.io/kube-proxy:v1.14.3 docker pull runcc/nginx-ingress-controller:0.25.0 docker tag runcc/nginx-ingress-controller:0.25.0 quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.25.0 docker rmi -f runcc/kube-proxy:v1.14.3 runcc/kube-apiserver:v1.14.3 runcc/kube-controller-manager:v1.14.3 runcc/kube-scheduler:v1.14.3 runcc/flannel:v0.11.0-amd64 runcc/coredns:1.3.1 runcc/etcd:3.3.10 runcc/pause:3.1 runcc/kubernetes-dashboard-amd64:v1.10.1 ##############################方法二################################# docker load --input coredns.tar docker load --input flannel.tar docker load --input pause.tar docker load --input kube-scheduler.tar docker load --input etcd.tar docker load --input kube-apiserver.tar docker load --input kube-proxy.tar docker load --input kube-controller-manager.tar docker load --input kubernetes-dashboard-amd64.tar #####################################################################
-
初始化主节点
kubeadm init --kubernetes-version=v1.14.3 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.56.175:6443 --token zomlkl.pmmryp5bk4yd1ln6 \ --discovery-token-ca-cert-hash sha256:866c32ee4147d0df38e465302b6f4919f6ea3375f2a57fdaed0cf23f29bffa79 mkdir -p $HOME/.kube cp -i /etc/kubernetes/admin.conf $HOME/.kube/config [root@k8smaster ~]# kubectl get componentstatus NAME STATUS MESSAGE ERROR controller-manager Healthy ok scheduler Healthy ok etcd-0 Healthy {"health":"true"} [root@k8smaster ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8smaster Ready master 13m v1.14.3 [root@k8smaster ~]# kubectl get namespaces NAME STATUS AGE default Active 16m kube-node-lease Active 16m kube-public Active 16m kube-system Active 16m
- 部署flannel网络
https://github.com/coreos/flannel
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
Node节点加入集群
- 安装相关程序
yum install kubectl-1.14.3-0 kubelet-1.14.3-0 kubeadm-1.14.3-0 --disableexcludes=kubernetes -y
-
加入集群
kubeadm join 192.168.56.175:6443 --token zomlkl.pmmryp5bk4yd1ln6 \ --discovery-token-ca-cert-hash sha256:866c32ee4147d0df38e465302b6f4919f6ea3375f2a57fdaed0cf23f29bffa79 systemctl enable kubelet systemctl start kubelet
- Master上查看集群信息
[root@k8smaster ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8smaster Ready master 31m v1.14.3 k8snode01 Ready <none> 2m16s v1.14.3 k8snode02 Ready <none> 81s v1.14.3 [root@k8smaster ~]# kubectl version Client Version: version.Info{Major:"1", Minor:"14", GitVersion:"v1.14.3", GitCommit:"5e53fd6bc17c0dec8434817e69b04a25d8ae0ff0", GitTreeState:"clean", BuildDate:"2019-06-06T01:44:30Z", GoVersion:"go1.12.5", Compiler:"gc", Platform:"linux/amd64"} Server Version: version.Info{Major:"1", Minor:"14", GitVersion:"v1.14.3", GitCommit:"5e53fd6bc17c0dec8434817e69b04a25d8ae0ff0", GitTreeState:"clean", BuildDate:"2019-06-06T01:36:19Z", GoVersion:"go1.12.5", Compiler:"gc", Platform:"linux/amd64"} [root@k8smaster ~]# kubectl cluster-info Kubernetes master is running at https://192.168.56.175:6443 KubeDNS is running at https://192.168.56.175:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
以二进制文件方式安装Kubernetes集群
官方文档:https://v1-14.docs.kubernetes.io/zh/docs/setup/release/
制作CA证书
https://kubernetes.io/docs/setup/best-practices/certificates/
-
安装cfssl
mkdir -p /opt/kubernetes/{cfg,bin,ssl,log} wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 chmod +x cfssl-certinfo_linux-amd64 cfssljson_linux-amd64 cfssl_linux-amd64 mv cfssl_linux-amd64 /opt/kubernetes/bin/cfssl mv cfssljson_linux-amd64 /opt/kubernetes/bin/cfssljson mv cfssl-certinfo_linux-amd64 /opt/kubernetes/bin/cfssl-certinfo ln -s /opt/kubernetes/bin/cfssl /usr/local/bin/cfssl ln -s /opt/kubernetes/bin/cfssljson /usr/local/bin/cfssljson ln -s /opt/kubernetes/bin/cfssl-certinfo /usr/local/bin/cfssl-certinfo
-
创建用来生成CA文件的json配置文件
cat > ca-config.json <<EOF { "signing": { "default": { "expiry": "8760h" }, "profiles": { "kubernetes": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "8760h" } } } } EOF
-
创建用来生成CA证书签名请求(CSR)的JSON配置文件
cat > ca-csr.json <<EOF { "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "BeiJing", "L": "BeiJing", "O": "k8s", "OU": "System" } ] } EOF
-
生成CA证书(ca.pem)和密钥(CA-key.pem)
cfssl gencert -initca ca-csr.json | cfssljson -bare ca ls ca* ca-config.json ca.csr ca-key.pem ca.pem ca-csr.json
- 分发证书至其他节点
scp ca.csr ca.pem ca-key.pem ca-config.json root@k8snode01:/opt/kubernetes/ssl/
scp ca.csr ca.pem ca-key.pem ca-config.json root@k8snode02:/opt/kubernetes/ssl/
ETCD数据库集群部署
- 下载etcd软件包
https://github.com/etcd-io/etcd/releases/tag/v3.2.12 wget https://github.com/coreos/etcd/releases/download/v3.2.18/etcd-v3.2.18-linux-amd64.tar.gz tar xf etcd-v3.2.18-linux-amd64.tar.gz cd etcd-v3.2.18-linux-amd64 cp etcd etcdctl /opt/kubernetes/bin/ ln -s /opt/kubernetes/bin/etcd /usr/local/src/etcd ln -s /opt/kubernetes/bin/etcdctl /usr/local/bin/etcdctl
-
创建etcd证书签名请求
cat etcd-csr.json { "CN": "etcd", "hosts": [ "127.0.0.1", "192.168.56.175", "192.168.102.60", "192.168.102.62" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "BeiJing", "L": "BeiJing", "O": "k8s", "OU": "System" } ] }
- 生成etcd证书和私钥
cfssl gencert -ca=/opt/kubernetes/ssl/ca.pem -ca-key=/opt/kubernetes/ssl/ca-key.pem -config=/opt/kubernetes/ssl/ca-config.json -profile=kubernetes etcd-csr.json | cfssljson -bare etcd ls etcd* etcd.csr etcd-csr.json etcd-key.pem etcd.pem cp etcd* /opt/kubernetes/ssl/ # 分发证书 scp etcd.csr etcd.pem etcd-csr.json etcd-key.pem root@k8snode01:/opt/kubernetes/ssl/ scp etcd.csr etcd.pem etcd-csr.json etcd-key.pem root@k8snode02:/opt/kubernetes/ssl/
- 设置etcd配置文件
cat > /opt/kubernetes/cfg/etcd.conf <<EOF #[member] ETCD_NAME="etcd-node1" ETCD_DATA_DIR="/var/lib/etcd/default.etcd" #ETCD_SNAPSHOT_COUNTER="10000" #ETCD_HEARTBEAT_INTERVAL="100" #ETCD_ELECTION_TIMEOUT="1000" ETCD_LISTEN_PEER_URLS="https://192.168.56.175:2380" ETCD_LISTEN_CLIENT_URLS="https://192.168.56.175:2379,https://127.0.0.1:2379" #ETCD_MAX_SNAPSHOTS="5" #ETCD_MAX_WALS="5" #ETCD_CORS="" #[cluster] ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.56.175:2380" # if you use different ETCD_NAME (e.g. test), # set ETCD_INITIAL_CLUSTER value for this name, i.e. "test=http://..." ETCD_INITIAL_CLUSTER="etcd-node1=https://192.168.56.175:2380,etcd-node2=https://192.168.56.176:2380,etcd-node3=https://192.168.56.177:2380" ETCD_INITIAL_CLUSTER_STATE="new" ETCD_INITIAL_CLUSTER_TOKEN="k8s-etcd-cluster" ETCD_ADVERTISE_CLIENT_URLS="https://192.168.56.175:2379" #[security] CLIENT_CERT_AUTH="true" ETCD_CA_FILE="/opt/kubernetes/ssl/ca.pem" ETCD_CERT_FILE="/opt/kubernetes/ssl/etcd.pem" ETCD_KEY_FILE="/opt/kubernetes/ssl/etcd-key.pem" PEER_CLIENT_CERT_AUTH="true" ETCD_PEER_CA_FILE="/opt/kubernetes/ssl/ca.pem" ETCD_PEER_CERT_FILE="/opt/kubernetes/ssl/etcd.pem" ETCD_PEER_KEY_FILE="/opt/kubernetes/ssl/etcd-key.pem" EOF
- 创建etcd系统服务
cat > /etc/systemd/system/etcd.service <<EOF [Unit] Description=Etcd Server After=network.target [Service] Type=simple WorkingDirectory=/var/lib/etcd EnvironmentFile=-/opt/kubernetes/cfg/etcd.conf # set GOMAXPROCS to number of processors ExecStart=/bin/bash -c "GOMAXPROCS=$(nproc) /opt/kubernetes/bin/etcd" Type=notify [Install] WantedBy=multi-user.target EOF
-
重新加载系统服务
systemctl daemon-reload systemctl enable etcd 在所有节点上创建etcd存储目录并启动etcd mkdir /var/lib/etcd systemctl start etcd systemctl status etcd
- 验证集群
etcdctl --endpoints=https://192.168.56.175:2379 \ --ca-file=/opt/kubernetes/ssl/ca.pem \ --cert-file=/opt/kubernetes/ssl/etcd.pem \ --key-file=/opt/kubernetes/ssl/etcd-key.pem cluster-health member b5e368575cf2efa is healthy: got healthy result from https://192.168.56.175:2379 member 529a36ed665687e5 is healthy: got healthy result from https://192.168.56.176:2379 member 704a3f4c3f74c5d6 is healthy: got healthy result from https://192.168.56.177:2379 cluster is healthy
部署Master节点
下载软件包生成CSR
- 准备软件包
wget https://dl.k8s.io/v1.14.3/kubernetes-server-linux-amd64.tar.gz tar xf kubernetes-server-linux-amd64.tar.gz cd kubernetes/server/bin/ cp kube-apiserver /opt/kubernetes/bin/ cp kube-controller-manager /opt/kubernetes/bin/ cp kube-scheduler /opt/kubernetes/bin/
- 创建生成CSR的JSON配置文件
cat <<EOF > kubernetes-csr.json { "CN": "kubernetes", "hosts": [ "127.0.0.1", "192.168.56.175", "10.1.0.1", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster", "kubernetes.default.svc.cluster.local" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "BeiJing", "L": "BeiJing", "O": "k8s", "OU": "System" } ] } EOF
- 生成kubernetes证书和私钥
cfssl gencert -ca=/opt/kubernetes/ssl/ca.pem \ -ca-key=/opt/kubernetes/ssl/ca-key.pem \ -config=/opt/kubernetes/ssl/ca-config.json \ -profile=kubernetes kubernetes-csr.json | cfssljson -bare kubernetes cp kubernetes*.pem /opt/kubernetes/ssl/
-
创建kube-apiserver使用的客户端令牌文件
head -c 16 /dev/urandom | od -An -t x | tr -d ' ' 45edef2a65af8c35d8a77101891cfa26 cat <<EOF > /opt/kubernetes/ssl/bootstrap-token.csv 45edef2a65af8c35d8a77101891cfa26,kubelet-bootstrap,10001,"system:kubelet-bootstrap" EOF
- 创建基于HTTP BASE认证,用户名/密码认证配置
cat <<EOF > /opt/kubernetes/ssl/basic-auth.csv admin,admin,1 readonly,readonly,2 EOF
部署Kubernetes API服务
cat <<EOF > /usr/lib/systemd/system/kube-apiserver.service [Unit] Description=Kubernetes API Server Documentation=https://github.com/GoogleCloudPlatform/kubernetes After=network.target [Service] ExecStart=/opt/kubernetes/bin/kube-apiserver \ --admission-control=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,ResourceQuota,NodeRestriction \ --bind-address=192.168.56.175 \ --insecure-bind-address=127.0.0.1 \ --authorization-mode=Node,RBAC \ --runtime-config=rbac.authorization.k8s.io/v1 \ --kubelet-https=true \ --anonymous-auth=false \ --basic-auth-file=/opt/kubernetes/ssl/basic-auth.csv \ --enable-bootstrap-token-auth \ --token-auth-file=/opt/kubernetes/ssl/bootstrap-token.csv \ --service-cluster-ip-range=10.1.0.0/16 \ --service-node-port-range=20000-40000 \ --tls-cert-file=/opt/kubernetes/ssl/kubernetes.pem \ --tls-private-key-file=/opt/kubernetes/ssl/kubernetes-key.pem \ --client-ca-file=/opt/kubernetes/ssl/ca.pem \ --service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \ --etcd-cafile=/opt/kubernetes/ssl/ca.pem \ --etcd-certfile=/opt/kubernetes/ssl/kubernetes.pem \ --etcd-keyfile=/opt/kubernetes/ssl/kubernetes-key.pem \ --etcd-servers=https://192.168.56.175:2379,https://192.168.56.176:2379,https://192.168.56.177:2379 \ --enable-swagger-ui=true \ --allow-privileged=true \ --audit-log-maxage=30 \ --audit-log-maxbackup=3 \ --audit-log-maxsize=100 \ --audit-log-path=/opt/kubernetes/log/api-audit.log \ --event-ttl=1h \ --v=2 \ --logtostderr=false \ --log-dir=/opt/kubernetes/log Restart=on-failure RestartSec=5 Type=notify LimitNOFILE=65536 [Install] WantedBy=multi-user.target EOF
- 启动API Server服务
systemctl daemon-reload systemctl enable kube-apiserver systemctl start kube-apiserver systemctl status kube-apiserver
部署Controller Manager
cat <<EOF > /usr/lib/systemd/system/kube-controller-manager.service [Unit] Description=Kubernetes Controller Manager Documentation=https://github.com/GoogleCloudPlatform/kubernetes [Service] ExecStart=/opt/kubernetes/bin/kube-controller-manager \ --address=127.0.0.1 \ --master=http://127.0.0.1:8080 \ --allocate-node-cidrs=true \ --service-cluster-ip-range=10.1.0.0/16 \ --cluster-cidr=10.2.0.0/16 \ --cluster-name=kubernetes \ --cluster-signing-cert-file=/opt/kubernetes/ssl/ca.pem \ --cluster-signing-key-file=/opt/kubernetes/ssl/ca-key.pem \ --service-account-private-key-file=/opt/kubernetes/ssl/ca-key.pem \ --root-ca-file=/opt/kubernetes/ssl/ca.pem \ --leader-elect=true \ --v=2 \ --logtostderr=false \ --log-dir=/opt/kubernetes/log Restart=on-failure RestartSec=5 [Install] WantedBy=multi-user.target EOF
- 启动Controller Manager
systemctl daemon-reload systemctl enable kube-controller-manager systemctl start kube-controller-manager systemctl status kube-controller-manager
4.3.3.4 部署kubernetes Scheduler
cat <<EOF > /usr/lib/systemd/system/kube-scheduler.service [Unit] Description=Kubernetes Scheduler Documentation=https://github.com/GoogleCloudPlatform/kubernetes [Service] ExecStart=/opt/kubernetes/bin/kube-scheduler \ --address=127.0.0.1 \ --master=http://127.0.0.1:8080 \ --leader-elect=true \ --v=2 \ --logtostderr=false \ --log-dir=/opt/kubernetes/log Restart=on-failure RestartSec=5 [Install] WantedBy=multi-user.target EOF
- 启动服务
systemctl daemon-reload systemctl enable kube-scheduler systemctl start kube-scheduler systemctl status kube-scheduler
部署kubectl命令行工具
- 准备二进制命令包
cd /usr/local/src/kubernetes/client/bin
cp kubectl /opt/kubernetes/bin/
- 创建admin证书签名请求
cat <<EOF > admin-csr.json { "CN": "admin", "hosts": [], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "BeiJing", "L": "BeiJing", "O": "system:masters", "OU": "System" } ] } EOF
- 生成admin证书和私钥
cfssl gencert -ca=/opt/kubernetes/ssl/ca.pem \ -ca-key=/opt/kubernetes/ssl/ca-key.pem \ -config=/opt/kubernetes/ssl/ca-config.json \ -profile=kubernetes admin-csr.json | cfssljson -bare admin ls -l admin* admin.csr admin-csr.json admin-key.pem admin.pem mv admin*.pem /opt/kubernetes/ssl/
- 设置集群参数
kubectl config set-cluster kubernetes \ --certificate-authority=/opt/kubernetes/ssl/ca.pem \ --embed-certs=true \ --server=https://192.168.56.175:6443 Cluster "kubernetes" set.
- 设置客户端认证参数
kubectl config set-credentials admin \ --client-certificate=/opt/kubernetes/ssl/admin.pem \ --embed-certs=true \ --client-key=/opt/kubernetes/ssl/admin-key.pem User "admin" set.
- 设置上下文参数
kubectl config set-context kubernetes \ --cluster=kubernetes \ --user=admin Context "kubernetes" created.
- 设置默认上下文
kubectl config use-context kubernetes Switched to context "kubernetes".
- 使用kubectl工具
kubectl get cs NAME STATUS MESSAGE ERROR controller-manager Healthy ok scheduler Healthy ok etcd-1 Healthy {"health":"true"} etcd-2 Healthy {"health":"true"} etcd-0 Healthy {"health":"true"}
部署node节点
- 准备二进制命令包
cd /usr/local/src/kubernetes/server/bin/ cp kubelet kube-proxy /opt/kubernetes/bin/ scp kubelet kube-proxy k8snode01:/opt/kubernetes/bin/ scp kubelet kube-proxy k8snode02:/opt/kubernetes/bin/
- 创建角色绑定
kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap clusterrolebinding "kubelet-bootstrap" created
- 创建buelet kubeconfig文件,设置集群参数
kubectl config set-cluster kubernetes \ --certificate-authority=/opt/kubernetes/ssl/ca.pem \ --embed-certs=true \ --server=https://192.168.56.175:6443 \ --kubeconfig=bootstrap.kubeconfig Cluster "kubernetes" set.
- 设置客户端认证参数
kubectl config set-credentials kubelet-bootstrap \ --token=45edef2a65af8c35d8a77101891cfa26\ --kubeconfig=bootstrap.kubeconfig User "kubelet-bootstrap" set.
- 设置上下文参数
kubectl config set-context default \ --cluster=kubernetes \ --user=kubelet-bootstrap \ --kubeconfig=bootstrap.kubeconfig Context "default" created.
- 设置上下文参数
kubectl config set-context default \ --cluster=kubernetes \ --user=kubelet-bootstrap \ --kubeconfig=bootstrap.kubeconfig Context "default" created.
- 选择默认上下文
kubectl config use-context default --kubeconfig=bootstrap.kubeconfig Switched to context "default". cp bootstrap.kubeconfig /opt/kubernetes/cfg scp bootstrap.kubeconfig k8snode01:/opt/kubernetes/cfg scp bootstrap.kubeconfig k8snode02:/opt/kubernetes/cfg
安装kubernetes-dashboard
wget https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml cat <<EOF > kubernetes-dashboard.yaml # Copyright 2017 The Kubernetes Authors. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # ------------------- Dashboard Secret ------------------- # apiVersion: v1 kind: Secret metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard-certs namespace: kube-system type: Opaque --- # ------------------- Dashboard Service Account ------------------- # apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system --- # ------------------- Dashboard Role & Role Binding ------------------- # kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kubernetes-dashboard-minimal namespace: kube-system rules: # Allow Dashboard to create 'kubernetes-dashboard-key-holder' secret. - apiGroups: [""] resources: ["secrets"] verbs: ["create"] # Allow Dashboard to create 'kubernetes-dashboard-settings' config map. - apiGroups: [""] resources: ["configmaps"] verbs: ["create"] # Allow Dashboard to get, update and delete Dashboard exclusive secrets. - apiGroups: [""] resources: ["secrets"] resourceNames: ["kubernetes-dashboard-key-holder", "kubernetes-dashboard-certs"] verbs: ["get", "update", "delete"] # Allow Dashboard to get and update 'kubernetes-dashboard-settings' config map. - apiGroups: [""] resources: ["configmaps"] resourceNames: ["kubernetes-dashboard-settings"] verbs: ["get", "update"] # Allow Dashboard to get metrics from heapster. - apiGroups: [""] resources: ["services"] resourceNames: ["heapster"] verbs: ["proxy"] - apiGroups: [""] resources: ["services/proxy"] resourceNames: ["heapster", "http:heapster:", "https:heapster:"] verbs: ["get"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: kubernetes-dashboard-minimal namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: kubernetes-dashboard-minimal subjects: - kind: ServiceAccount name: kubernetes-dashboard namespace: kube-system --- # ------------------- Dashboard Deployment ------------------- # kind: Deployment apiVersion: apps/v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system spec: replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: k8s-app: kubernetes-dashboard template: metadata: labels: k8s-app: kubernetes-dashboard spec: containers: - name: kubernetes-dashboard image: k8s.gcr.io/kubernetes-dashboard-amd64:v1.10.1 ports: - containerPort: 8443 protocol: TCP args: - --auto-generate-certificates # Uncomment the following line to manually specify Kubernetes API server Host # If not specified, Dashboard will attempt to auto discover the API server and connect # to it. Uncomment only if the default does not work. # - --apiserver-host=http://my-address:port volumeMounts: - name: kubernetes-dashboard-certs mountPath: /certs # Create on-disk volume to store exec logs - mountPath: /tmp name: tmp-volume livenessProbe: httpGet: scheme: HTTPS path: / port: 8443 initialDelaySeconds: 30 timeoutSeconds: 30 volumes: - name: kubernetes-dashboard-certs secret: secretName: kubernetes-dashboard-certs - name: tmp-volume emptyDir: {} serviceAccountName: kubernetes-dashboard # Comment the following tolerations if Dashboard must not be deployed on master tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule --- # ------------------- Dashboard Service ------------------- # kind: Service apiVersion: v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system spec: type: NodePort ports: - port: 443 targetPort: 8443 selector: k8s-app: kubernetes-dashboard --- apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kube-system EOF kubectl create -f kubernetes-dashboard.yaml kubectl create clusterrolebinding login-on-dashboard-with-cluster-admin --clusterrole=cluster-admin --user=admin
- 查看token令牌
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}')
kubectl命令行工具基本用法
|
命令 |
命令类型 |
功能说明 |
|
create |
基础命令(初级) |
通过文件或标准输入创建资源 |
|
expose |
基于rc、service、deployment或pod创建Service资源 |
|
|
run |
通过创建Deployment在集群中运行指定的镜像 |
|
|
set |
设置指定资源的特定属性 |
|
|
get |
基础命令(中级) |
显示一个或多个资源 |
|
explain |
打印资源文档 |
|
|
edit |
编辑资源 |
|
|
delete |
基于文件名、stdin、资源或名字,以及资源和选择器删除资源 |
|
|
rollout |
部署命令 |
管理资源的滚动更新 |
|
rolling-update |
对ReplicatonController执行滚动升级 |
|
|
scale |
伸缩Deployment、ReplicaSet、RC或Job的规模 |
|
|
autoscale |
对Deployment、ReplicaSet或RC进行自动伸缩 |
|
|
certificate |
集群管理命令 |
配置数字证书资源 |
|
cluster-info |
打印集群信息 |
|
|
top |
打印资源(CPU/Memory/Storage)使用率 |
|
|
cordon |
将指定Node设定为“不可用”(unschedulable)状态 |
|
|
uncordon |
将指定node设定为“可用”(schedulable)状态 |
|
|
drain |
“排干”指定的node的负载以进入“维护”模式 |
|
|
taint |
为Node声明污点及标准行为 |
|
|
describe |
排错及调试命令 |
显示指定的资源或资源组的详细信息 |
|
logs |
显示一个pod内某容器的日志 |
|
|
attach |
附加终端至一个运行中的容器 |
|
|
exec |
在容器中执行指定命令 |
|
|
port-forward |
将本地的一个或多个端口转发至指定的Pod |
|
|
proxy |
创建能够访问Kubernetes API Server的代理 |
|
|
cp |
在容器间复制文件或目录 |
|
|
auth |
打印授权信息 |
|
|
apply |
高级命令 |
基于文件或stdin将配置应用于资源 |
|
patch |
使用策略合并补丁更新资源字段 |
|
|
replace |
基于文件或stdin替换一个资源 |
|
|
convert |
为不同的API版本转换配置文件 |
|
|
label |
设置命令 |
更新指定资源的label |
|
annotate |
更新资源的annotation |
|
|
completion |
输出指定的shell(如bash)的补全码 |
|
|
version |
|
打印Kubernetes服务端和客户端的版本信息 |
|
api-versions |
|
以“group/version”格式打印服务器支持的API版本信息 |
|
config |
|
配置Kubeconfig文件的内容 |
|
plugin |
|
运行命令行插件 |
|
help |
|
打印任一命令的帮助信息 |
Kubectl命令还包含了多种不同的输出格式(如下表所示),它们为用户提供了非常灵活的自定义输出机制,如输出YAML或JSON格式等。
|
输出格式 |
格式说明 |
|
-o wide |
显示资源的额外信息 |
|
-o name |
仅打印资源的名称 |
|
-o yaml |
YAML格式化输出API对象信息 |
|
-o json |
JSON格式化输出API对象信息 |
|
-o go-template |
以自定义的go模版格式化输出API对象信息 |
|
-o custom-columns |
自定义要输出的字段 |
此外,kubectl命令还有许多通用的选项,这个可以使用“kubectl options”命令来获取。
下面列举几个比较常用命令。
- -s或—server:指定API Server的地址和端口。
- --kubeconfig:使用的kubeconfig文件路径,默认为~/.kube/config。
- --namespace:命令执行的目标名称空间。
管理Pod资源对象
Pod定义详解
YAML格式的Pod定义文件的完整内容如下:
apiVersion: v1 kind: Pod metadata: name: string namespace: string labels: - name: string annotations: - name: string spec: containers: - name: string image: string imagePullPolicy: [Always | Never | IfNotPresent] command: [string] args: [string] workingDir: string volumeMounts: - name: string mountPath: string readOnly: boolean ports: - name: string containerPort: int hostPort: int protocol: string env: - name: string value: string resource: limits: cpu: string memory: string livenessProbe: exec: command: [string] httpGet: path: string port: number host: string scheme: string - name: string value: string tcpSocket: port: number initialDelaySeconds: 0 timeoutSeconds: 0 periodSeconds: 0 successThreshold: 0 failureThreshold: 0 securityContext: privileged: false restartPolicy: [Always | Never | OnFailure] nodeSelector: object imagePullSecrets: - name: string hostNetwork: false volumes: - name: string emptyDir: {} hostPath: path: string secret: secretName: string items: - key: string path: string configMap: name: string items: - key: string path: string
Pod定义文件模版中各属性详细说明
|
属性名称 |
取值类型 |
是否必选 |
取值说明 |
|
version |
String |
Required |
版本号,例如:v1 |
|
kind |
String |
Required |
Pod |
|
metadata |
Object |
Required |
元数据 |
|
metadata.name |
String |
Required |
Pod的名称 |
|
metadata.namespace |
String |
Required |
Pod所属的命名空间,默认值为default |
|
metadata.labels[] |
List |
|
自定义标签列表 |
|
metadata.annotation[] |
List |
|
自定义注解列表 |
|
Spec |
Object |
Required |
Pod中容器的详细定义 |
|
spec.containers[] |
List |
Required |
Pod中容器列表 |
|
spec.containers[].name |
String |
Required |
容器的名称 |
|
spec.containers[].image |
String |
Required |
容器的镜像名称 |
|
spec.containers[].imagePullPolicy |
String |
|
镜像拉取策略,可选值包括:Always、Never、IfNotPresent,默认值为Always. (1)Always:表示每次都尝试重新拉取镜像。 (2)IfNotPresent:表示如果本地有该镜像,则使用本地的镜像,本地不存在时拉取镜像。 (3)Never:表示使用本地镜像。另外,如果包含如下设置,系统将默认设置imagePullPolicy=Always,如下所述: (1)不设置imagePullPolicy,也未指定镜像的tag; (2) 不设置imagePullPolicy,镜像tag为latest; (3)启用名为AlwaysPullImages的准入控制器(Admission Controller) |
|
spec.containers[].command[] |
List |
|
容器的启动命令列表,如果不指定,则使用镜像打包时使用的启动命令 |
|
spec.containers[].args[] |
List |
|
容器的启动命令参数列表 |
|
spec.containers[].workingDir |
String |
|
容器的工作目录 |
|
spec.containers[].volumeMounts[] |
List |
|
挂载到容器内部的存储卷配置 |
|
spec.containers[].volumeMounts[].mountPath |
String |
|
存储卷在容器内Mount的绝对路径,应少于512个字符 |
|
spec.containers[].volumeMounts[].readOnly |
Boolean |
|
是否为只读模式,默认为读写模式 |
|
spec.containers[].ports[] |
List |
|
容器需要暴露的端口号列表 |
|
spec.containers[].ports[].name |
String |
|
端口的名称 |
|
spec.containers[].ports[].containerPort |
Int |
|
容器需要监听的端口号 |
|
spec.containers[].ports[].hostPort |
Int |
|
容器所在主机需要监听的端口号,默认与containerPort相同,设置hostPort时,同一台宿主机将无法启动该容器的第2副本 |
|
spec.containers[].ports[].protocol |
String |
|
端口协议,支持TCP和UDP,默认值为TCP |
|
spec.containers[].env[] |
List |
|
容器运行前需设置的环境变量列表 |
|
spec.containers[].env[].name |
String |
|
环境变量的名称 |
|
spec.containers[].env[].value |
String |
|
环境变量的值 |
|
spec.containers[].resources |
Object |
|
资源限制和资源请求的设置 |
|
spec.containers[].resources.limits |
Object |
|
资源限制的设置 |
|
spec.containers[].resources.limits.cpu |
String |
|
CPU限制,单位为core数,将用于docker run –cpu-shares参数 |
|
spec.containers[].resource.limits.memory |
String |
|
内置限制,单位可以为MiB、GiB等,将用于docker run –memory参数 |
|
spec.containers[].resources.requests |
Object |
|
资源限制的设置 |
|
spec.containers[].resources.requests.cpu |
String |
|
CPU请求,单位为core数,容器启动的初始可用数量 |
|
spec.containers[].resources.requests.memory |
String |
|
内存请求,单位可以为MiB、GiB等,容器启动的初始话可用数量 |
|
spec.volumes[] |
List |
|
在该Pod上定义的共享存储卷列表 |
|
spec.volumes[].name |
String |
|
共享存储卷的名称,在一个Pod中每个存储卷定义一个名称,容器定义部分的containers[].volumeMounts[].name将应用该共享存储卷的名称。 Volume的类型包括:emptyDir、hostPath、gcePersistentDisk、awsElasticBlockStore、gitRepo、secret、nfs、iscsi、glusterfs、persistentVolumeClain、rbd、flexVolume、cinder、cephfs、flocker、downwardAPI、fs、azureFile、configmap、vsphereVolume,可以定义多个Volume,每个Volume的name保持惟一。
|
Pod的基本用法
- 一个Pod中启动一个Docker容器
apiVersion: v1 kind: Pod metadata: name: nginx labels: name: frontend spec: containers: - name: nginx image: nginx env: - name: GET_HOSTS_FROM value: env ports: - containerPort: 80
这个nginx Pod在成功启动后,将启动1个Docker容器。
- 一个Pod中启动多个docker容器
apiVersion: v1 kind: Pod metadata: name: redis-php labels: name: redis-php spec: containers: - name: frontend image: frontend ports: - containerPort: 80 - name: redis image: redis ports: - containerPort: 6379
属于同一个Pod的多个容器之间相互访问时仅需要通过localhost就可以通信。
-
创建该Pod
kubectl create -f xxxxx-pod.yaml
-
查看已经创建的Pod
kubectl get pods
-
查看Pod的详细信息
kubectl describe pod xxx-pod
静态Pod
静态Pod是由kubelet进行管理的仅存在于特定Node上的Pod。它们不能通过API Server进行管理,无法与ReplicationController、Deployment或者DaemonSet进行关联,并且kubelet无法对它们进行健康检查。静态Pod总是由kubelet创建,并且总在kubelet所在的node上运行。
创建静态Pod有两种方式:配置文件方式和HTTP方式
- 配置文件方式
首先,需要设置kubelet的启动参数“--config”,指定kubelet需要监控的配置文件所在的目录,kubelet会定期扫描该目录,并根据该目录下的.yaml或.json文件进行创建操作。
假设配置目录为/etc/kubelet.d/,配置启动参数为--config=/etc/kubelet.d/,然后重启kubelet服务。
在目录/etc/kubelet.d中放入static-web.yaml文件,内容如下:
apiVersion: v1 kind: Pod metadata: name: static-web labels: name: static-web spec: containers: - name: static-web image: nginx ports: - name: web containerPort: 80
等一会,查看本季中已经启动的容器。到Master上查看Pod列表,可以看到到这个static pod。
由于静态Pod无法通过API Server直接管理,所以在Master上尝试删除这个Pod时,会使其变成Pending状态,且不会被删除。
删除该Pod的操作只能是到其所在Node上将其定义文件static-web.yaml从/etc/kubelet.d/目录下删除。
rm /etc/kubelet.d/static-web.yaml
(2)HTTP方式
通过设置kubelet的启动参数“--manifest-url”,kubelet将会定期从该URL地址下载Pod的定义文件,并以.yaml或.json文件的格式进行解析,然后创建Pod。其实现方式与配置文件方式是一致的。
Pod容器共享Volume
同一个Pod中的多个容器能够共享Pod级别的存储卷Volume。Volume可以被定义为各种类型,多个容器各自进行挂载操作,将一个Volume挂载为容器内部需求的目录,如下图所示:
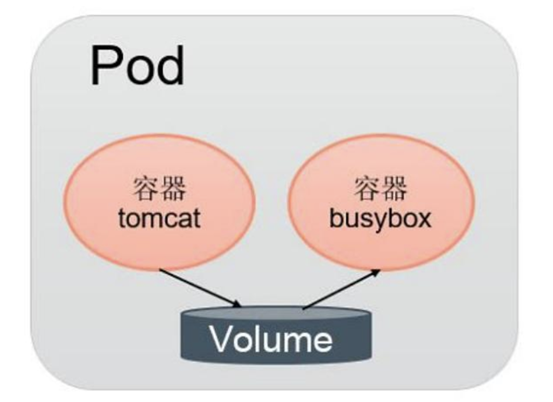
在下面的例子中,在Pod包两个容器:tomcat和busybox,在Pod级别设置Volume“app-logs”,用于tomcat向其中写日志文件,busybox读日志文件。
配置文件pod-volume-applogs.yaml的内容如下:
apiVersion: v1 kind: Pod metadata: name: volume-pod spec: containers: - name: tomcat image: tomcat ports: - containerPort: 8080 volumeMounts: - name: app-logs mountPath: /usr/local/tomcat/logs - name: busybox image: busybox command: ["sh","-c","tail -f /logs/catalina*.log"] volumeMounts: - name: app-logs mountPath: /logs volumes: - name: app-logs emptyDir: {}
Pod的配置管理
应用部署的一个最佳实践是将应用所需的配置信息与程序进行分离,这样可以使应用程序被更好地复用,通过不同的配置也能实现更灵活的功能。将应用打包为容器镜像后,可以通过环境变量或者外挂文件的方式在创建容器时进行配置注入,但在大规模容器集群的环境中,对多个容器进行不同的配置将变得非常复杂。从Kubernetes 1.2开始提供了一种统一的应用配置管理方案——ConfigMap。
ConfigMap概述
ConfigMap供容器使用的典型用法如下:
(1)生成容器内的环境变量。
(2)设置容器启动命令的启动参数(需设置为环境变量)。
(3)以Volume的形式挂载为容器内部的文件或目录。
ConfigMap以一个或多个key:value的形式保存在kubernetes系统中供应用使用,即可以用于表示一个完整配置文件的内容(例如: server.xml=<?xml..>..)
可以通过YAML配置文件或者直接使用kubectl create configmap命令行的方式来创建ConfigMap。
创建ConfigMap资源对象
(1)通过YAML配置文件方式创建
cm-appvars.yaml apiVersion: v1 kind: ConfigMap metadata: name: cm-appvars data: apploglevel: info appdatadir: /var/data
- 执行kubectl create命令创建该ConfigMap:
kubectl create -f cm-appvars.yaml
- 查看创建好的ConfigMap
kubectl get configmap kubectl describe configmap cm-appvars kubectl get configmap cm-appvars -o yaml
(2) 通过kubectl命令行方式创建
在Pod中使用ConfigMap
(1)通过环境变量方式使用ConfigMap
(2)通过volumeMount使用ConfigMap
使用ConfigMap的限制条件
使用ConfigMap的限制条件如下:
- ConfigMap必须在Pod之前创建。
- ConfigMap受NameSpace限制,只有处于相同NameSpace中的Pod才可以引用它。
- ConfigMap中配置管理还未能实现。
- kubelet只支持可以被API Server管理的Pod使用ConfigMap。kubelet在本地Node上通过--manifest-url或--config自动创建的静态Pod将无法引用ConfigMap。
- 在Pod对ConfigMap进行挂载(volumeMount)操作时,在容器内部只能挂载为“目录”,无法挂载为“文件”。在挂载到容器内部后,在目录下将包含ConfigMap定义的每个item,如果在该目录下原来还有其他文件,则容器内的该目录将被挂载的ConfigMap覆盖。如果应用程序需要保留原来的其他文件,则需要进行额外的处理。可以将ConfigMap挂载到容器内部的临时目录,再通过启动脚本将配置文件复制或者链接到(cp或link命令)应用所用的实际配置目录下。
Pod生命周期和重启策略
Pod在整个生命周期中被系统定义为各种状态,熟悉Pod的各种状态对于理解如何设置Pod的调度策略、重启策略是很有必要的。
- Pod的状态
|
状态值 |
描述 |
|
Pending |
API Server已经创建该Pod,但在Pod内还有一个或多个容器的镜像没有创建,包括正在下载镜像的过程。 |
|
Running |
Pod内所有容器均已创建,且至少有一个容器处于运行状态、正在启动状态或正在重启状态。 |
|
Succeeded |
Pod内所有容器均成功执行后退出,且不会再重启 |
|
Failed |
Pod内所有容器均已退出,但至少有一个容器推出为失败状态 |
|
Unknown |
由于某种原因无法获取该Pod的状态,可能由于网络通信不畅导致 |
Pod的重启策略(RestartPolicy)应用于Pod内的所有容器,并且仅在Pod所处的Node上由kubelet进行判断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet将根据RestartPolicy的设置来进行相应的操作。
Pod的重启策略包括Always、OnFailure和Never,默认值为Always。
- Alays:当容器失败时,由kubelet自动重启该容器。
- OnFailure:当容器终止运行且退出码不为0时,由kubelet自动重启该容器。
- Never:不论容器运行状态如何,kubelet都不会重启该容器。
Kubelet重启失败容器的时间间隔以sync-frequency乘以2n来计算,例如1、2、4、8倍等,最长延时5min,并且在成功重启后的10min后重置该时间。
Pod的重启策略与控制方式息息相关,当前可用于管理Pod的控制器包括ReplicationController、Job、DaemonSet及直接通过kubelet管理(静态Pod)。每种控制器对Pod的重启策略要求如下。
- RC和DaemonSet:必须设置为Always,需要保证该容器持续运行。
- Job:OnFailure或Never,确保容器执行完成后不再重启。
- kubelet:在Pod失效时自动重启它,不论将RestartPolicy设置为什么值,也不会对Pod进行健康检查
Pod状态转换场景
|
Pod包含的容器数 |
Pod当前的状态 |
发生事件 |
Pod的结果状态 |
||
|
RestartPolicy=Always |
RestartPolicy=OnFailure |
RestartPolicy=Never |
|||
|
包含1个容器 |
Running |
容器成功退出 |
Running |
Succeeded |
Succeeded |
|
包含1个容器 |
Running |
容器失败退出 |
Running |
Running |
Failed |
|
包含两个容器 |
Running |
1个容器失败退出 |
Running |
Running |
Running |
|
包含两个容器 |
Running |
容器被OOM杀掉 |
Running |
Running |
Failed |
Pod健康检查和服务可用性检查
Kubernetes对Pod的健康状态可以通过两类探针检查:LivenessProbe和ReadinessProbe,kubelet定期执行这两类探针来诊断容器的健康状况。
(1)LivenessProbe探针:用于判断容器是否存活(Running状态),如果LivenessProbe探针探测到容器不健康,则kubelet将杀掉该容器,并根据容器的重启策略做相应的处理。如果一个容器不包含LivenessProbe探针,那么kubelet人为该容器的LivenessProbe探针返回的值永远是Success。
(2)ReadinessProbe探针:用于判断容器服务是否可用(Ready状态),达到Ready状态的Pod才可以接受请求。对于Service管理的Pod,Service与Pod Endpoint的关联关系也将基于Pod是否Ready进行设置。如果在运行过程中Ready状态变为False,则系统自动将其从Service的后段Endpoint列表中隔离出去,后续再把恢复到Ready状态的Pod加回后段Endpoint列表。这样就能保证客户端再访问Service时不会被转发到服务不可用的Pod实例上。
LivenessProbe和ReadinessProbe均可配置以下三种实现方式。
(1)ExecAction:在容器内部执行一个命令,如果该命令的反回码为0,则表明容器健康。
(2)TCPSocketAction:通过容器的IP地址和端口号执行TCP检查,如果能够建立TCP连接,则表明容器健康
(3)HTTPGetAction:通过容器的IP地址、端口号及路径调用HTTP Get方法,如果响应的状态码大于等于200且小于400,则认为容器健康。
Pod控制器
ReplicationController
ReplicationController(简称RC)是Kubernetes较早实现的Pod控制器,用于确保Pod资源的不间断运行。不过,Kubernetes后来设计了ReplicaSet及其更高一级的控制器Deployment来取ReplicationController,并表示在后来的版本中可能会废弃RC。因此,这里不再对ReplicationController做过多的介绍。
ReplicaSet控制器
Kubernetes较早期的版本中仅有ReplicationController一种类型的Pod控制器,后来的版本中陆续引入了更多的控制器实现,这其中就包括用来取代ReplicationController的新一代实现ReplicaSet。事实上,除了额外支持基于集合(set-based)的标签选择器,以及它的滚动更新(Rolling-Update)机制要基于更高级的控制Deployment实现之外,目前的ReplicaSet的其余功能基本上与ReplicationController相同。
ReplicaSet概述
ReplicaSet(简称RS)是Pod控制器类型的一种实现,用于确保由其管控的Pod对象副本数在任一时刻都能精确满足期望的数量。ReplicaSet控制器资源启动后会查找集群中匹配其标签选择器的Pod资源对象,当前活动的数量与期望的数量不吻合时,多则删除,少则通过Pod模版创建以补足,等Pod资源副本数量符合期望值后即进入下一轮和解循环。
ReplicaSet的副本数量、标签选择器甚至是Pod模版都可以随时按需进行修改,不过仅改动期望的副本数量会对现存的Pod副本产生直接影响。修改标签选择器可能会使得现有的Pod副本的标签变得不再匹配,此时ReplicaSet控制器要做的不过是不再计入它们而已。另外,在创建完成后,ReplicaSet也不会关注Pod对象中的实际内容,因此Pod模版的改动也只会对后来新建的Pod副本产生影响。
相比较于手动创建和管理Pod资源来说,ReplicaSet能够实现以下功能。
- 确保Pod资源对象的数量精确反映期望值:ReplicaSet需要确保由其控制运行的Pod副本数量精确吻合配置中定义的期望值,否则就会自动补足所缺或终止所余。
- 确保Pod健康运行:探测到由其管控的Pod对象因其所在的工作节点故障而不可用时,自动请求由调度器于其他工作节点创建缺失的Pod副本。
- 弹性伸缩:业务规模因各种原因时常存在明显波动,在波峰或波谷期间,可以通过ReplicaSet控制器动态调整相关Pod资源对象的数量。此外,在必要时还可以通过HPA(HroizontalPodAutoscaler)控制器实现Pod资源规模的自动伸缩。
创建ReplicaSet
# 查看ReplicaSet 文档
kubectl explain ReplicaSet
示例:rs-example.yaml
apiVersion: extensions/v1beta1 kind: ReplicaSet metadata: name: rs-example spec: replicas: 2 selector: matchLabels: app: rs-demo template: metadata: labels: app: rs-demo spec: containers: - name: myapp image: nginx:1.14.1 ports: - name: http containerPort: 80
使用如下命令创建:
kubectl apply -f rs-example.yaml
replicaset.extensions/rs-example created
查看创建的Pod资源
kubectl get pods -l app=rs-demo NAME READY STATUS RESTARTS AGE rs-example-82l88 1/1 Running 0 91s rs-example-x42t4 0/1 ContainerCreating 0 91s kubectl get pods -l app=rs-demo -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES rs-example-82l88 1/1 Running 0 4m41s 10.244.1.34 k8snode01 <none> <none> rs-example-x42t4 1/1 Running 0 4m41s 10.244.1.35 k8snode01 <none> <none>
查看ReplicaSet控制器资源的相关状态
kubectl get replicaset rs-example -o wide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR rs-example 2 2 2 3m5s myapp nginx:1.14.1 app=rs-demo
6.2.3 ReplicaSet管控下的Pod对象
(1)缺失Pod副本
任何原因导致的相关Pod对象丢失,都会由ReplicaSet控制器自动补足。
示例:手动删除上面列出的一个Pod对象,命令如下
kubectl delete pods rs-example-82l88
再次列出相关Pod对象的信息,可以看到被删除的rs-example-82l88进入了终止进程过程,而新的Pod对象rs-example-j5cn2正在被rs-example控制器创建
kubectl get pods -l app=rs-demo -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES rs-example-82l88 0/1 Terminating 0 66s 10.244.1.36 k8snode01 <none> <none> rs-example-j5cn2 0/1 ContainerCreating 0 4s 10.244.1.37 k8snode01 <none> <none> rs-example-x42t4 1/1 Running 0 7m29s 10.244.1.35 k8snode01 <none> <none>
强行修改隶属于控制器rs-example的某Pod资源(匹配于标签控制器)的标签,会导致它不再被控制器作为副本技术,这也将出发控制器的Pod对象副本缺失补足机制。如将rs-example-j5cn2的标签app的值置空:
kubectl label pods rs-example-j5cn2 app= --overwrite
pod/rs-example-j5cn2 labeled
查看rs-example相关的Pod对象信息,发现rs-example-j5cn2已经消失不见,并且正在创建新的对象副本。
kubectl get pods -l app=rs-demo -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES rs-example-mrzgt 0/1 ContainerCreating 0 1s <none> k8snode01 <none> <none> rs-example-x42t4 1/1 Running 0 14m 10.244.1.35 k8snode01 <none> <none>
由此可见,修改Pod资源的标签即可将其从控制器的管控之下移出,当然,修改后的标签如果又能被其他控制器资源的标签选择器所命中,则此时它又成了隶属于另一控制器的副本。如果修改其标签后的Pod对象不再隶属于任何控制器,那么它就将成为自主式Pod,与此前手动直接创建的Pod对象的特性相同,即误删除或所在的工作节点故障都会造成其永久性的消失。
(2)多出Pod副本
一旦被标签选择器匹配到的Pod资源数量因任何原因超出期望值,多余的部分都将被控制器自动删除。
示例:为frontend-98c486888-l42gz手动为其添加“app:rs-demo”标签
cat pod-example.yaml apiVersion: v1 kind: Pod metadata: name: pod-example spec: containers: - name: myapp image: nginx:1.14.1 kubectl create -f pod-example.yaml pod/pod-example created kubectl label pods pod-example app=rs-demo pod/pod-example labeled
###MAC 使用iterm2 向多个窗口发送命令 ⌘(command) + ⇧(shift) + i,可以勾选 Suppress this message permanently 取消告警,并 OK 确认。这时每个窗口右上角都会出现图标(如下图所示)。
关闭该功能的方式是再次输入快捷键 ⌘(command) + ⇧(shift) + i 即可###

再次列出相关的Pod资源,可以看到rs-example控制器启动了删除多余Pod的操作,pod-example正处于终止过程中:
kubectl get pods -l app=rs-demo -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod-example 0/1 Terminating 0 35s 10.244.1.42 k8snode01 <none> <none> rs-example-mrzgt 1/1 Running 0 31m 10.244.1.38 k8snode01 <none> <none> rs-example-x42t4 1/1 Running 0 45m 10.244.1.35 k8snode01 <none> <none>
这就意味着,任何自主式的或本隶属于其他控制器的Pod资源其标签变动的结果一旦匹配到了其他的副本数足额的控制器,就会导致这类Pod资源被删除。
(3)查看Pod资源变动的相关事件
通过“kubectl descibe replicasets”命令可打印出ReplicaSet控制器的详细状态,从命令结果中“event”一段也可以看出,rs-example执行了Pod资源的创建和删除操作,为的就是确保其数量的精确性。
kubectl describe replicasets/rs-example Name: rs-example Namespace: default Selector: app=rs-demo Labels: app=rs-demo Annotations: kubectl.kubernetes.io/last-applied-configuration: {"apiVersion":"extensions/v1beta1","kind":"ReplicaSet","metadata":{"annotations":{},"name":"rs-example","namespace":"default"},"spec":{"re... Replicas: 2 current / 2 desired Pods Status: 2 Running / 0 Waiting / 0 Succeeded / 0 Failed Pod Template: Labels: app=rs-demo Containers: myapp: Image: nginx:1.14.1 Port: 80/TCP Host Port: 0/TCP Environment: <none> Mounts: <none> Volumes: <none> Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulCreate 57m replicaset-controller Created pod: rs-example-6r9ws Normal SuccessfulCreate 57m replicaset-controller Created pod: rs-example-x42t4 Normal SuccessfulCreate 51m replicaset-controller Created pod: rs-example-82l88 Normal SuccessfulCreate 50m replicaset-controller Created pod: rs-example-j5cn2 Normal SuccessfulCreate 43m replicaset-controller Created pod: rs-example-mrzgt Normal SuccessfulDelete 11m (x3 over 20m) replicaset-controller Deleted pod: pod-example
更新ReplicaSet控制器
ReplicaSet控制器的核心组成部分是标签选择器、副本数量及Pod模版,但更新操作一般是围绕replicas和remplate两个字段值进行的,毕竟改变标签选择器的需求几乎不存在。改动Pod模版的定义对已经创建完成的活动对象无效,但在用户逐个手动关闭其旧版本的Pod资源后就能以新代旧,实现控制器下应用版本的滚动升级。另外,修改副本的数量也就意味着应用规模的扩展(提升期望的副本数量)或收缩(降低期望的副本数量)。
(1)更改Pod模版:升级应用
ReplicaSet控制器的Pod模版可随时按需修改,但它仅影响这之后由其新建的Pod对象,对已有的副本不会产生作用。大多数情况下,用户需求改变的通常是模版中的容器镜像文件及其相关的配置以实现应用的版本升级。下面的示例清单文件(rs-example-v2.yaml)中的内容与之前版本(rs-example.yaml)的唯一不同之处也仅在于镜像文件的改动:
cat rs-example-v2.yaml apiVersion: extensions/v1beta1 kind: ReplicaSet metadata: name: rs-example spec: replicas: 2 selector: matchLabels: app: rs-demo template: metadata: labels: app: rs-demo spec: containers: - name: myapp image: nginx:1.15.5 ports: - name: http containerPort: 80
对新版本的清单文件执行“kubectl apply”或“kubectl replace”命令即可完成rs-example控制器资源的修改操作
kubectl replace -f rs-example-v2.yaml
replicaset.extensions/rs-example replaced
不过,控制器rs-example管控的现存Pod对象使用的仍然是原来版本中定义的镜像:
kubectl get pods -l app=rs-demo -o custom-columns=Name:metadata.name,Image:spec.containers[0].image Name Image rs-example-mrzgt nginx:1.14.1 rs-example-x42t4 nginx:1.14.1
此时,手动删除控制器现有的Pod对象(或删除与其匹配的控制器标签选择器的标签),并由控制器基于新的Pod模版自动创建出足额的Pod副本,即可完成一次应用的升级。新旧更替的过程支持如下两类操作方式。
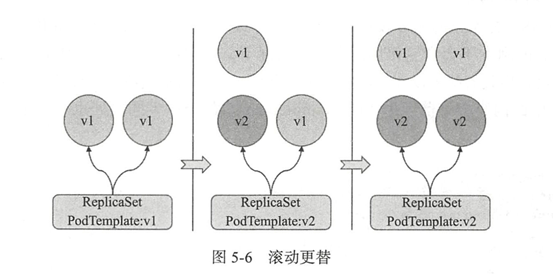
- 一次性删除控制器相关的所有Pod副本或更改相关的标签:剧烈更替,可能会导致Pod中的应用短时间不可访问(如下图所示);生产实践中,此种做法不可取。
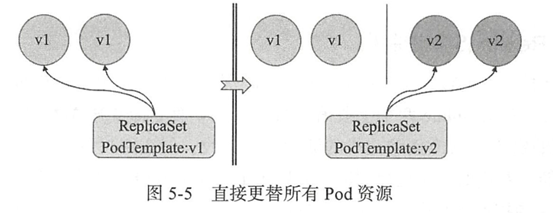
- 分批次删除旧有的Pod副本或更改其标签(待控制器补足后再删除另一批):滚动更替,更替期间新旧版本共存
例如,这里采用第一种方式进行操作,一次性删除rs-example相关的所有Pod副本:
kubectl delete pods -l app=rs-demo pod "rs-example-mrzgt" deleted pod "rs-example-x42t4" deleted
再次列出rs-example控制器相关的Pod及其容器镜像版本时可以发现,使用新版本镜像的Pod已经创建完成:
kubectl get pods -l app=rs-demo -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES rs-example-6xwzm 0/1 ContainerCreating 0 11s <none> k8snode01 <none> <none> rs-example-mrzgt 0/1 Terminating 0 75m 10.244.1.38 k8snode01 <none> <none> rs-example-wd85l 0/1 ContainerCreating 0 11s <none> k8snode01 <none> <none> rs-example-x42t4 0/1 Terminating 0 89m 10.244.1.35 k8snode01 <none> <none> kubectl get pods -l app=rs-demo -o custom-columns=Name:metadata.name,Image:spec.containers[0].image Name Image rs-example-6xwzm nginx:1.15.5 rs-example-wd85l nginx:1.15.5
更高级别的Pod控制器Deployment能够自动实现更完善的滚动更新和回滚,并提供自定义更新策略的接口。
(2)扩容和缩容
改动ReplicaSet控制器对象配置中期望的Pod副本数量(replicas字段)会由控制器实时做出响应,从而实现应用规模的水平伸缩。replicas的修改及应用规模的伸缩,它支持从资源清单文件中获取新的目标副本数量,也可以直接在命令行通过“--replicas”选项进行读取,例如将rs-example控制器的Pod副本数量提升至5个:
kubectl scale replicasets rs-example --replicas=5 replicaset.extensions/rs-example scaled
由下面显示的rs-example资源的状态可以看出,将其Pod资源副本数量扩展至5个的操作已经成功完成:
kubectl get replicasets rs-example NAME DESIRED CURRENT READY AGE rs-example 5 5 5 98m
收缩规模的方式与扩展相同,只需要明确指定目标副本数量即可。例如:
kubectl scale replicasets rs-example --replicas=3 replicaset.extensions/rs-example scaled kubectl get replicasets rs-example NAME DESIRED CURRENT READY AGE rs-example 3 3 3 98m
另外,kubectl scale命令还支持在现有Pod副本数量符合指定的值时才执行扩展操作,这近需要为命令使用“--current-replicas”选项即可。例如,下面的命令表示如果rs-example目前的Pod副本数量为2,就将其扩展至4个:
kubectl scale replicasets rs-example --current-replicas=2 --replicas=4 error: Expected replicas to be 2, was 3
但由于rs-example控制器现存的副本数量是3个,因此上面的扩展操作未执行并返回了错误提示。
注意:如果ReplicaSet控制器管控的是有状态的应用,例如主从架构的Redis集群,那么上诉这些升级、降级、扩展和收缩的操作都需要清新编排和参与才能进行,不过,这也在一定程度上降低Kubernetes容器编排的价值和意义。好在,它提供了StatefulSet资源来应对这种需求,因此,ReplicaSet通常仅用于管理无状态的应用,如HTTP服务程序等。
删除ReplicaSet控制器资源
使用kubectl delete命令删除Replicaet对象时默认会一并删除其管控的各Pod对象。考虑到这些Pod资源未必由其创建,或者即便由其创建却也并非其自身的组成部分,故而可以为命令使用“--cascade=false”选项,取消级联,删除相关的Pod对象,这在Pod资源后续可能会再次用到时尤为有用。例如,删除rs控制器rs-example
kubectl delete replicasets rs-example --cascade=false replicaset.extensions "rs-example" deleted kubectl get pods -l app=rs-demo -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES rs-example-6xwzm 1/1 Running 0 24m 10.244.1.43 k8snode01 <none> <none> rs-example-lmt9x 1/1 Running 0 15m 10.244.1.47 k8snode01 <none> <none> rs-example-wd85l 1/1 Running 0 24m 10.244.1.44 k8snode01 <none> <none>
删除操作完成后,此前由rs-example控制器管控的各Pod对象仍处于活动状态,但它们变成了自主式Pod资源,用户需要自行组织和维护好它们。
尽管ReplicaSet控制器功能强大,但在实践中,它却并非是用户直接使用的控制器,而是要由更高一级抽象的Deployment控制器对象来调用。
Deployment控制器
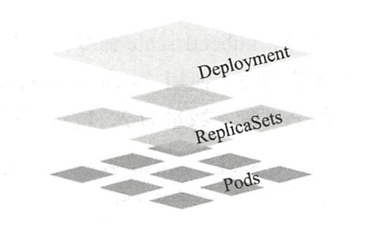
Deployment(简称为deploy)是Kubernetes控制器的又一种实现,它构建于ReplicaSet控制器之上,可为Pod和ReplicaSet资源提供声明式更新。相比较而言,Pod和ReplicaSet是较低级别的资源,它们很少被直接使用。Deployment、ReplicaSet和Pod的关系如下图所示:
Deployment控制器资源的主要职责同样是为了保证Pod资源的健康运行,其大部分功能可通过调用ReplicaSet控制器来实现,同时还增添了部分特性。
- 事件和状态查看:必要时可以查看Deployment对象升级的详细进度和状态。
- 回滚:升级操作完成后发现问题时,支持使用回滚机制将应用返回到前一个或由用户指定的历史记录中的版本上。
- 版本记录:对Deployment对象的每一次操作都予以保存,以供后续可能执行的回滚操作使用。
- 暂停和启动:对于每一次升级,都能够随时暂停和启动。
- 多种自动更新方案:一是Recreate,即重建更新机制,全面停止、删除旧有的Pod后用新版本替代;另一个是RollingUpdate,即滚动升级机制,逐步替换旧有的Pod至新的版本
创建Deployment
Deployment是标准的Kubernetes API资源,它构建于ReplicaSet资源之上,于是其spec字段中嵌套使用的字段包含了ReplicaSet控制器支持的replicas、selector、template和minReadySeconds,它也正是利用这些信息完成了其二级资源ReplicaSet对象的创建。下面是一个Deployment控制器资源的配置清单示例:
cat myapp-deploy.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: myapp-deploy spec: replicas: 3 selector: matchLabels: app: myapp template: metadata: labels: app: myapp spec: containers: - name: myapp image: nginx:1.14.1 ports: - containerPort: 80 name: http
创建deployment控制器资源对象
kubectl apply -f myapp-deploy.yaml --record
deployment.extensions/myapp-deploy created
使用“kubectl get deployment”命令可以列出创建的Deployment对象myapp-deploy及其相关的信息。
kubectl get deployments myapp-deploy NAME READY UP-TO-DATE AVAILABLE AGE myapp-deploy 3/3 3 3 19s
Deployment控制器会自动创建相关的ReplicaSet控制器资源。并以“[DEPLOYMENT-NAME]-[POD-TEMPLATE-HASH-VALUE]”格式为其命名,其中的hash值由Deployment控制器自动生成。由Deployment创建的ReplicaSet对象会自动使用相同的标签选择器。因此,可使用类似如下的命令查看其相关的信息:
kubectl get replicasets -l app=myapp NAME DESIRED CURRENT READY AGE myapp-deploy-7948db888d 3 3 3 54s
相关的Pod对象的信息可以用相似的命令进行获取。下面的命令结果中,Pod对象的名称遵循ReplicaSet控制器的命名格式,它以ReplicaSet控制器的名称前缀,后跟5为随机字符:
kubectl get pods -l app=myapp NAME READY STATUS RESTARTS AGE myapp-deploy-7948db888d-8jm8n 1/1 Running 0 8m42s myapp-deploy-7948db888d-sd5m9 1/1 Running 0 8m42s myapp-deploy-7948db888d-t2klx 1/1 Running 0 8m42s
更新策略
如前所述,ReplicaSet控制器的应用更新需要手动分成多步并以特定的次序进行,过程繁杂且容器出错,而Deployment却只需要有用户指定在Pod模版中腰改动的内容,例如容器镜像文件的版本,余下的步骤可交由其自动完成。同样,更新应用程序的规模也只需修改期望的副本数量,余下的事情交给deployment控制器即可。
Deployment控制器详细信息中包含了其更新策略的相关配置信息,如myapp-deploy控制器资源“kubectl describe”命令中输出的StrategyType、RollindUpdateStrategy自动等:
kubectl describe deployments myapp-deploy Name: myapp-deploy Namespace: default CreationTimestamp: Thu, 25 Jul 2019 17:08:50 +0800 Labels: app=myapp Annotations: deployment.kubernetes.io/revision: 1 kubectl.kubernetes.io/last-applied-configuration: {"apiVersion":"extensions/v1beta1","kind":"Deployment","metadata":{"annotations":{"kubernetes.io/change-cause":"kubectl apply --filename=m... kubernetes.io/change-cause: kubectl apply --filename=myapp-deploy.yaml --record=true Selector: app=myapp Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable StrategyType: RollingUpdate MinReadySeconds: 0 RollingUpdateStrategy: 1 max unavailable, 1 max surge Pod Template: Labels: app=myapp Containers: myapp: Image: nginx:1.14.1 Port: 80/TCP Host Port: 0/TCP Environment: <none> Mounts: <none> Volumes: <none> Conditions: Type Status Reason ---- ------ ------ Available True MinimumReplicasAvailable OldReplicaSets: <none> NewReplicaSet: myapp-deploy-7948db888d (3/3 replicas created) Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ScalingReplicaSet 16m deployment-controller Scaled up replica set myapp-deploy-7948db888d to 3
Deployment控制器支持两种更新策略:滚动更新(rolling update)和重新创建(recreate),默认为滚动更新。重新创建更新类似于前文中ReplicaSet的第一种更新方法,即首先删除现有的Pod对象,而后由控制器基于新的模版重新创建出新版本资源对象。通常,只应该在应用的新旧版本不兼容(如依赖的后端数据库的schema不同且无法兼容)时运行时才会使用recreate策略,因为它会导致应用替换期间暂时不可用,好处在于它不存在中间状态,用户访问到的要么是应用的新版本,要么是旧版本。
滚动升级是默认的更新策略,它在删除一部分旧版本的Pod资源的同时,补充创建一部分新版本的Pod对象进行应用升级,其优势是升级期间,容器中应用提供的服务不会中断,但要求应用程序能够应对新旧版本同时工作的情形,例如新旧版本兼容同一个数据库方案等。不过,更新操作期间,不同的客户端得到的响应内容可能会来自不同版本的应用。
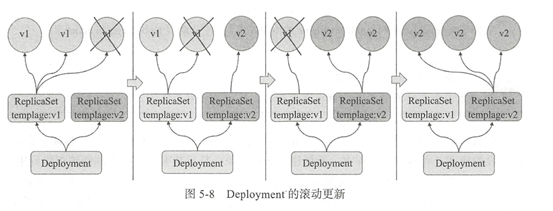
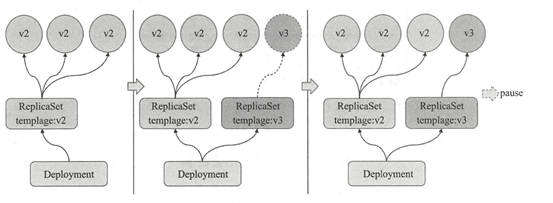
Deployment控制器的滚动更新操作并非在同一个ReplicaSet控制器对象下删除并创建Pod资源,而是将它们分置于两个不同的控制器之下:旧控制器的Pod对象数量不断减少的同时,新控制器的Pod对象数量不断增加,直到旧控制器不再拥有Pod对象,而新的控制器的副本数量变得完全符合期望值为止,如下图所示:
滚动更新时,应用升级期间还要确保可用的Pod数量不低于某阈值以确保可以持续处理客户端的服务请求,变动的方法和Pod对象的数量范围将通过spec.startegy.rollingUpdate.maxSurge和spec.strategy.rollingUpdate.maxUnavailable两个熟悉协同进行定义,它们功用如下图所示:

- maxSurge:指定升级期间存在的总Pod对象数量最多可超出期望值的个数,其值可以是0或正整数,也可以是一个期望值的百分比;例如,如果期望值为3,当前的熟悉值为1,则表示Pod对象的总数不能超过4个。
- maxUnavaiable:升级期间正常可用的Pod副本数(包括新旧版本)最多不能低于期望数值的个数,其值可以是0或正整数,也可以是一个期望值的百分比;默认值为1,该值意味着如果期望值是3,则升级期间至少要有两个Pod对象处于正常提供服务的状态。
升级Deployment
修改Pod模版相关的配置参数便能完成deployment控制器资源的更新。由于是声明式的配置,因此对Deployment控制器资源的修改尤其适合使用apply和patch命令来进行;当然,如果仅是修改容器镜像,“set image”命令更为易用。
接下来通过更新此前创建的Deployment控制器deploy-example来了解更新操作过程的执行细节,为了使得升级过程更易于观测,这里先使用“kubectl patch”命令为其spec.minReadySeconds字段定义一个等待时长,例如5s:
kubectl patch deployments myapp-deploy -p '{"spec": {"minReadySeconds": 5}}' deployment.extensions/myapp-deploy patched (no change)
patch命令的补丁形式为JSON格式,以-p选项指定,上面命令中的'{"spec": {"minReadySeconds": 5}}'表示设置spec.minReadySeconds属性的值。若要改变myapp-deploy中的myapp容器的镜像,也可以使用patch命令,如'{"spec": {"containers": ["name":"myapp","image":"nginx:1.15.5"]}}',不过,修改容器镜像有更为简单的专用命令“set image”。
注意:修改Deployment控制器的minReadySeconds、replicas和strategy等字段的值并不会处罚Pod资源的更新操作,因为它们不属于模版的内嵌字段,对现存的Pod对象不产生任何影响。
接着,使用“nginx:1.15.5”镜像文件修改Pod模版中的myapp容器,启动Deployment控制器的滚动更新过程:
kubectl set image deployments myapp-deploy myapp=nginx:1.15.5 deployment.extensions/myapp-deploy image updated
“kubectl rollout status”命令可用于打印滚动更新过程中的状态信息:
kubectl rollout status deployment myapp-deploy deployment "myapp-deploy" successfully rolled out
另外,还可以使用“kubectl get deployments myapp-deploy --watch”命令监控其更新过程中Pod对象的变动过程:
kubectl get deployments myapp-deploy --watch NAME READY UP-TO-DATE AVAILABLE AGE myapp-deploy 3/3 3 3 62m
滚动更新时,myapp-deploy控制器会创建一个新的ReplicaSet控制器对象来管控新版本的Pod对象,升级完成后,旧版本的ReplicaSet会保留在历史记录中,但其此前的管控Pod对象将会被删除。
kubectl get replicasets -l app=myapp NAME DESIRED CURRENT READY AGE myapp-deploy-7948db888d 0 0 0 49m myapp-deploy-b58578665 3 3 3 43s
Pod状态已经处于READY状态,在集群内任一能使用kubectl的节点访问以上Pod中的web服务,命令如下:
curl -I $(kubectl get pods myapp-deploy-b58578665-cqb9h -o go-template={{.status.podIP}}) HTTP/1.1 200 OK Server: nginx/1.15.5 Date: Thu, 25 Jul 2019 10:01:46 GMT Content-Type: text/html Content-Length: 612 Last-Modified: Tue, 02 Oct 2018 14:49:27 GMT Connection: keep-alive ETag: "5bb38577-264" Accept-Ranges: bytes
金丝雀发布
Deployment控制器还支持自定义控制更新过程中的滚动节奏,如“暂停”(pause)或“继续”(resume)更新操作,尤其是借助于前文讲到的maxSurge和maxUnavailable属性还能实现更为精巧的过程控制。比如,待第一批新的Pod资源创建完成后立即暂停更新过程,此时,仅存在一小部分新版本的应用,主体部分还是旧的版本。然后,再根据用户特征精心刷选出小部分用户的请求路由至新版本的Pod应用,并持续观察其是否能稳定地按期望的方法运行。确定没有问题后再继续完成余下的Pod资源的滚动更新,否则立即回滚更新操作。这便是所谓的金丝雀发布(Canary Release)。如下图所示:
为了尽可能低降低对现有系统及容量的影响,金丝雀发布过程通常建议采用“先添加、在删除,且可用Pod资源对象综述不低于期望值”的方式进行。首次添加的Pod对象数量取决于其接入的第一批请求的规则及单个Pod的承载能力,视具体需求而定,为了能够更简单地说明问题,接下来才有首批添加1个Pod资源的方式,将Deployment控制器的maxSurge熟悉的值设置为1,并将maxUnavailable属性的值设置为0:
kubectl patch deployments myapp-deploy -p '{"spec": {"strategy": {"rollingUpdate": {"maxSurge": 1, "maxUnavailable": 0}}}}' deployment.extensions/myapp-deploy patched
接下来,启动myapp-deploy控制器的更新过程,在修改相应容器的镜像版本后立即暂停更新进度,它会在启动第一批新版本Pod对象的创建操作之后转为暂停状态。需要注意的是,这里之所以能够在第一批更新启动后就暂停,有赖于此前为maxReadySeconds属性设置的时长,因此用户要在更新命令启动后的此时长指定的时间范围内启动暂停操作,其执行过程如下图所示。
kubectl set image deployments myapp-deploy myapp=nginx:1.15.7 && kubectl rollout pause deployments myapp-deploy deployment.extensions/myapp-deploy image updated deployment.extensions/myapp-deploy paused
通过其状态查看命令可以看到,才创建完一个新版本的Pod资源后滚动更新操作“暂停”
kubectl rollout status deployments myapp-deploy Waiting for deployment "myapp-deploy" rollout to finish: 1 out of 3 new replicas have been updated...
[root@k8smaster src]# kubectl get pods -l app=myapp NAME READY STATUS RESTARTS AGE myapp-deploy-7bc684b5cf-9fc8p 1/1 Running 0 43s myapp-deploy-b58578665-cqb9h 1/1 Running 0 40m myapp-deploy-b58578665-qlms5 1/1 Running 0 40m myapp-deploy-b58578665-qr57l 1/1 Running 0 40m [root@k8smaster src]# curl -I $(kubectl get pods myapp-deploy-7bc684b5cf-9fc8p -o go-template={{.status.podIP}}) HTTP/1.1 200 OK Server: nginx/1.15.7 Date: Thu, 25 Jul 2019 10:39:05 GMT Content-Type: text/html Content-Length: 612 Last-Modified: Tue, 27 Nov 2018 12:31:56 GMT Connection: keep-alive ETag: "5bfd393c-264" Accept-Ranges: bytes [root@k8smaster src]# curl -I $(kubectl get pods myapp-deploy-b58578665-cqb9h -o go-template={{.status.podIP}}) HTTP/1.1 200 OK Server: nginx/1.15.5 Date: Thu, 25 Jul 2019 10:40:20 GMT Content-Type: text/html Content-Length: 612 Last-Modified: Tue, 02 Oct 2018 14:49:27 GMT Connection: keep-alive ETag: "5bb38577-264" Accept-Ranges: bytes [root@k8smaster src]# curl -I $(kubectl get pods myapp-deploy-b58578665-qlms5 -o go-template={{.status.podIP}}) HTTP/1.1 200 OK Server: nginx/1.15.5 Date: Thu, 25 Jul 2019 10:40:30 GMT Content-Type: text/html Content-Length: 612 Last-Modified: Tue, 02 Oct 2018 14:49:27 GMT Connection: keep-alive ETag: "5bb38577-264" Accept-Ranges: bytes [root@k8smaster src]# curl -I $(kubectl get pods myapp-deploy-b58578665-qr57l -o go-template={{.status.podIP}}) HTTP/1.1 200 OK Server: nginx/1.15.5 Date: Thu, 25 Jul 2019 10:40:42 GMT Content-Type: text/html Content-Length: 612 Last-Modified: Tue, 02 Oct 2018 14:49:27 GMT Connection: keep-alive ETag: "5bb38577-264" Accept-Ranges: bytes
相关的Pod列表也可能显示旧版本的ReplicaSet的所有Pod副本仍在正常运行,新版本的ReplicaSet也包含一个Pod副本,但最多不超过期望值1个,myapp-deploy原有的期望值为3,因此总数不超过4个。此时,通过Service或Ingress资源及香港路由策略等设定,可可能将一部分用户的流量引入到这些Pod之上进行发布验证。运行一段时间后,如果确认没有问题,即可使用“kubectl rollout resume”命令继续此前的滚动更新过程:
kubectl rollout resume deployments myapp-deploy deployment.extensions/myapp-deploy resumed [root@k8smaster ~]# kubectl get pods -l app=myapp NAME READY STATUS RESTARTS AGE myapp-deploy-7bc684b5cf-9fc8p 1/1 Running 0 4m1s myapp-deploy-b58578665-cqb9h 1/1 Running 0 43m myapp-deploy-b58578665-qlms5 1/1 Running 0 43m myapp-deploy-b58578665-qr57l 1/1 Running 0 43m [root@k8smaster ~]# kubectl get pods -l app=myapp NAME READY STATUS RESTARTS AGE myapp-deploy-7bc684b5cf-9fc8p 1/1 Running 0 4m8s myapp-deploy-7bc684b5cf-v5kkq 1/1 Running 0 3s myapp-deploy-b58578665-cqb9h 1/1 Running 0 44m myapp-deploy-b58578665-qlms5 1/1 Running 0 44m [root@k8smaster ~]# kubectl get pods -l app=myapp NAME READY STATUS RESTARTS AGE myapp-deploy-7bc684b5cf-9fc8p 1/1 Running 0 4m9s myapp-deploy-7bc684b5cf-v5kkq 1/1 Running 0 4s myapp-deploy-b58578665-cqb9h 1/1 Running 0 44m myapp-deploy-b58578665-qlms5 1/1 Running 0 44m [root@k8smaster ~]# kubectl get pods -l app=myapp NAME READY STATUS RESTARTS AGE myapp-deploy-7bc684b5cf-9fc8p 1/1 Running 0 4m10s myapp-deploy-7bc684b5cf-v5kkq 1/1 Running 0 5s myapp-deploy-b58578665-cqb9h 1/1 Running 0 44m myapp-deploy-b58578665-qlms5 1/1 Running 0 44m [root@k8smaster ~]# kubectl get pods -l app=myapp NAME READY STATUS RESTARTS AGE myapp-deploy-7bc684b5cf-9fc8p 1/1 Running 0 4m11s myapp-deploy-7bc684b5cf-v5kkq 1/1 Running 0 6s myapp-deploy-b58578665-cqb9h 1/1 Running 0 44m myapp-deploy-b58578665-qlms5 1/1 Running 0 44m [root@k8smaster ~]# kubectl get pods -l app=myapp NAME READY STATUS RESTARTS AGE myapp-deploy-7bc684b5cf-9fc8p 1/1 Running 0 4m12s myapp-deploy-7bc684b5cf-v5kkq 1/1 Running 0 7s myapp-deploy-b58578665-cqb9h 1/1 Running 0 44m myapp-deploy-b58578665-qlms5 1/1 Running 0 44m [root@k8smaster ~]# kubectl get pods -l app=myapp NAME READY STATUS RESTARTS AGE myapp-deploy-7bc684b5cf-9fc8p 1/1 Running 0 4m14s myapp-deploy-7bc684b5cf-j2bnd 0/1 ContainerCreating 0 1s myapp-deploy-7bc684b5cf-v5kkq 1/1 Running 0 9s myapp-deploy-b58578665-cqb9h 1/1 Running 0 44m myapp-deploy-b58578665-qlms5 0/1 Terminating 0 44m [root@k8smaster ~]# kubectl get pods -l app=myapp NAME READY STATUS RESTARTS AGE myapp-deploy-7bc684b5cf-9fc8p 1/1 Running 0 4m16s myapp-deploy-7bc684b5cf-j2bnd 1/1 Running 0 3s myapp-deploy-7bc684b5cf-v5kkq 1/1 Running 0 11s myapp-deploy-b58578665-cqb9h 1/1 Running 0 44m myapp-deploy-b58578665-qlms5 0/1 Terminating 0 44m [root@k8smaster ~]# kubectl get pods -l app=myapp NAME READY STATUS RESTARTS AGE myapp-deploy-7bc684b5cf-9fc8p 1/1 Running 0 4m17s myapp-deploy-7bc684b5cf-j2bnd 1/1 Running 0 4s myapp-deploy-7bc684b5cf-v5kkq 1/1 Running 0 12s myapp-deploy-b58578665-cqb9h 1/1 Running 0 44m myapp-deploy-b58578665-qlms5 0/1 Terminating 0 44m [root@k8smaster ~]# kubectl get pods -l app=myapp NAME READY STATUS RESTARTS AGE myapp-deploy-7bc684b5cf-9fc8p 1/1 Running 0 4m18s myapp-deploy-7bc684b5cf-j2bnd 1/1 Running 0 5s myapp-deploy-7bc684b5cf-v5kkq 1/1 Running 0 13s myapp-deploy-b58578665-cqb9h 1/1 Running 0 44m myapp-deploy-b58578665-qlms5 0/1 Terminating 0 44m [root@k8smaster ~]# kubectl get pods -l app=myapp NAME READY STATUS RESTARTS AGE myapp-deploy-7bc684b5cf-9fc8p 1/1 Running 0 4m19s myapp-deploy-7bc684b5cf-j2bnd 1/1 Running 0 6s myapp-deploy-7bc684b5cf-v5kkq 1/1 Running 0 14s myapp-deploy-b58578665-cqb9h 1/1 Running 0 44m myapp-deploy-b58578665-qlms5 0/1 Terminating 0 44m [root@k8smaster ~]# kubectl get pods -l app=myapp NAME READY STATUS RESTARTS AGE myapp-deploy-7bc684b5cf-9fc8p 1/1 Running 0 4m20s myapp-deploy-7bc684b5cf-j2bnd 1/1 Running 0 7s myapp-deploy-7bc684b5cf-v5kkq 1/1 Running 0 15s myapp-deploy-b58578665-cqb9h 1/1 Terminating 0 44m myapp-deploy-b58578665-qlms5 0/1 Terminating 0 44m [root@k8smaster ~]# kubectl get pods -l app=myapp NAME READY STATUS RESTARTS AGE myapp-deploy-7bc684b5cf-9fc8p 1/1 Running 0 4m21s myapp-deploy-7bc684b5cf-j2bnd 1/1 Running 0 8s myapp-deploy-7bc684b5cf-v5kkq 1/1 Running 0 16s myapp-deploy-b58578665-cqb9h 0/1 Terminating 0 44m myapp-deploy-b58578665-qlms5 0/1 Terminating 0 44m [root@k8smaster ~]# kubectl get pods -l app=myapp NAME READY STATUS RESTARTS AGE myapp-deploy-7bc684b5cf-9fc8p 1/1 Running 0 4m22s myapp-deploy-7bc684b5cf-j2bnd 1/1 Running 0 9s myapp-deploy-7bc684b5cf-v5kkq 1/1 Running 0 17s myapp-deploy-b58578665-qlms5 0/1 Terminating 0 44m [root@k8smaster ~]# kubectl get pods -l app=myapp NAME READY STATUS RESTARTS AGE myapp-deploy-7bc684b5cf-9fc8p 1/1 Running 0 4m24s myapp-deploy-7bc684b5cf-j2bnd 1/1 Running 0 11s myapp-deploy-7bc684b5cf-v5kkq 1/1 Running 0 19s myapp-deploy-b58578665-qlms5 0/1 Terminating 0 44m [root@k8smaster ~]# kubectl get pods -l app=myapp NAME READY STATUS RESTARTS AGE myapp-deploy-7bc684b5cf-9fc8p 1/1 Running 0 4m26s myapp-deploy-7bc684b5cf-j2bnd 1/1 Running 0 13s myapp-deploy-7bc684b5cf-v5kkq 1/1 Running 0 21s
回滚Deployment控制器下的应用发布
Deployment控制器的回滚操作可使用“kubectl rollout undo”命令完成,例如,下面命令可将myapp-deploy回滚至此前的版本:
kubectl rollout undo deployments myapp-deploy
deployment.extensions/myapp-deploy rolled back
如果要恢复到指定的历史版本,在“kubectl rollout undo”命令上使用“--to-revision”选择指定revivion号码即可回滚到历史特定的版本。示例:如下是myapp-deploy包含的revivsion历史记录:
kubectl rollout history deployments myapp-deploy deployment.extensions/myapp-deploy REVISION CHANGE-CAUSE 1 kubectl apply --filename=myapp-deploy.yaml --record=true 3 kubectl apply --filename=myapp-deploy.yaml --record=true 4 kubectl apply --filename=myapp-deploy.yaml --record=true
若要回滚到号码为1的revivsion记录,则使用如下命令即可完成:
kubectl rollout undo deployments myapp-deploy --to-revision=1 deployment.extensions/myapp-deploy rolled back [root@k8smaster src]# kubectl get pods -l app=myapp -o custom-columns=Name:metadata.name,Image:spec.containers[0].image Name Image myapp-deploy-7948db888d-5rxf5 nginx:1.14.1 myapp-deploy-7948db888d-8dcpc nginx:1.14.1 myapp-deploy-7948db888d-sswqs nginx:1.14.1 myapp-deploy-b58578665-9zkgq nginx:1.15.5 myapp-deploy-b58578665-qlrkd nginx:1.15.5 [root@k8smaster src]# kubectl get pods -l app=myapp -o custom-columns=Name:metadata.name,Image:spec.containers[0].image Name Image myapp-deploy-7948db888d-5rxf5 nginx:1.14.1 myapp-deploy-7948db888d-8dcpc nginx:1.14.1 myapp-deploy-7948db888d-sswqs nginx:1.14.1 myapp-deploy-b58578665-9zkgq nginx:1.15.5 myapp-deploy-b58578665-qlrkd nginx:1.15.5 [root@k8smaster src]# kubectl get pods -l app=myapp -o custom-columns=Name:metadata.name,Image:spec.containers[0].image Name Image myapp-deploy-7948db888d-5rxf5 nginx:1.14.1 myapp-deploy-7948db888d-8dcpc nginx:1.14.1 myapp-deploy-7948db888d-sswqs nginx:1.14.1 myapp-deploy-b58578665-9zkgq nginx:1.15.5 myapp-deploy-b58578665-qlrkd nginx:1.15.5 [root@k8smaster src]# kubectl get pods -l app=myapp -o custom-columns=Name:metadata.name,Image:spec.containers[0].image Name Image myapp-deploy-7948db888d-5rxf5 nginx:1.14.1 myapp-deploy-7948db888d-8dcpc nginx:1.14.1 myapp-deploy-7948db888d-sswqs nginx:1.14.1
回滚操作中,其revision记录中的信息会发生变动,回滚操作会被当作一次滚动更新追加到历史记录中,而被回滚的条目则会被删除。需要注意的是,如果此前的滚动更新过程处于“暂停”状态,那么回滚操作就需要先将Pod模版的版本改回到之前的版本,然后“继续”更新,否则,其将一直处于暂停状态而无法回滚。
扩容和缩容
通过修改.spec.replicas即可修改Deployment控制器中Pod资源的副本数量,它将实时作用于控制器并直接生效。Deployment控制器是声明式配置,replicas熟悉的值可直接修改资源配置文件,然后使用“kubectl apply”进行应用,也可以使用“kubectl edit”对其进行实时修改。而前一种方式能够将修改结果予以长期留存。
DaemonSet控制器
DaemonSet是Pod控制器的又一种实现,用于在集群中的全部节点上同时运行一份指定的Pod资源副本,后续新加入集群的工作节点也会自动创建一个相关的Pod对象,当从集群移除节点时,此类Pod对象也将被自动回收而无需重建。管理员也可以使用节点选择器及节点标签指定仅在部分具有控制器特征的节点上运行指定的Pod对象。
DaemonSet是一种特殊的控制器,它有特定的应用场景,通常运行哪些执行系统级操作任务的应用,其应用场景具体如下:
- 运行集群存储的守护进程,如在各个节点上运行glusterd或ceph。
- 在各个节点上运行日志收集守护进程,如fluentd和logstash。
- 在各个节点上运行监控系统的代理守护进程,如Prometheus Node Exporter、collectd、Datadog agent、New Relic agent或Ganglia gmod等。
当然,既然是需要运行于集群内的每个节点或部分节点,于是很多场景中也可以把应用直接运行为工作节点上的系统守护进程,不过,这样一来就失去了运用Kubernetes管理所带来的便携性。另外,也只有必须将Pod对象运行于固定的几个节点并且需要先于其他Pod启动时,才有必要使用DaemonSet控制器,否则就应该使用Deployment控制器。
创建DaemonSet资源对象
DaemonSet不支持使用replicas,毕竟DaemonSet并不是基于期望的副本数来控制Pod资源数量,而是基于节点数量,但template是必选字段。
下面的资源清单文件(filebeat-ds.yaml)示例中定义了一个名为filebeat-ds的DaemonSet控制器,它将在每个节点上运行一个filebeat进程以收集容器相关的日志数据:
cat filebeat-ds.yaml apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: filebeat-ds labels: app: filebeat spec: selector: matchLabels: app: filebeat template: metadata: labels: app: filebeat name: filebeat spec: containers: - name: filebeat image: store/elastic/filebeat:7.1.0
通过清单文件创建DaemonSet资源的命令与其他资源的创建并无二致:
kubectl apply -f filebeat-ds.yaml
daemonset.extensions/filebeat-ds created
使用“kubectl describe”命令查看DaemonSet对象的详细信息:
kubectl describe daemonsets filebeat-ds Name: filebeat-ds Selector: app=filebeat Node-Selector: <none> Labels: app=filebeat Annotations: deprecated.daemonset.template.generation: 1 kubectl.kubernetes.io/last-applied-configuration: {"apiVersion":"extensions/v1beta1","kind":"DaemonSet","metadata":{"annotations":{},"labels":{"app":"filebeat"},"name":"filebeat-ds","names... Desired Number of Nodes Scheduled: 1 Current Number of Nodes Scheduled: 1 Number of Nodes Scheduled with Up-to-date Pods: 1 Number of Nodes Scheduled with Available Pods: 0 Number of Nodes Misscheduled: 0 Pods Status: 0 Running / 1 Waiting / 0 Succeeded / 0 Failed Pod Template: Labels: app=filebeat Containers: filebeat: Image: store/elastic/filebeat:7.1.0 Port: <none> Host Port: <none> Environment: <none> Mounts: <none> Volumes: <none> Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulCreate 19s daemonset-controller Created pod: filebeat-ds-bmscz
查看filebeat-ds控制器创建的Pod对象
kubectl get pods -l app=filebeat -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES filebeat-ds-bmscz 1/1 Running 0 5m54s 10.244.1.77 k8snode01 <none> <none>
更新DaemonSet对象
DaemonSet支持RollingUpdate(滚动更新)和OnDelete(删除时更新)两种更新策略,滚动更为为默认的更新策略,工作逻辑类似于Deployment控制,不过仅支持使用maxUnavailabe属性定义最大不可用Pod资源副本数(默认值为1),而删除时更新的方法则是在删除相应的Pod资源后并重建更新为新版本。
示例:降级此前创建的filebeat-ds中的Pod模版中的镜像,使用“kubectl set image”命令即可实现:
kubectl set image daemonsets filebeat-ds filebeat=store/elastic/filebeat:7.2.0 daemonset.extensions/filebeat-ds image updated
可以通过filebeat-ds控制器的详细信息中的Events字段等来了解滚动更新的操作过程。
kubectl describe daemonsets filebeat-ds Name: filebeat-ds Selector: app=filebeat Node-Selector: <none> Labels: app=filebeat Annotations: deprecated.daemonset.template.generation: 3 kubectl.kubernetes.io/last-applied-configuration: {"apiVersion":"extensions/v1beta1","kind":"DaemonSet","metadata":{"annotations":{},"labels":{"app":"filebeat"},"name":"filebeat-ds","names... Desired Number of Nodes Scheduled: 1 Current Number of Nodes Scheduled: 1 Number of Nodes Scheduled with Up-to-date Pods: 1 Number of Nodes Scheduled with Available Pods: 1 Number of Nodes Misscheduled: 0 Pods Status: 1 Running / 0 Waiting / 0 Succeeded / 0 Failed Pod Template: Labels: app=filebeat Containers: filebeat: Image: store/elastic/filebeat:7.2.0 Port: <none> Host Port: <none> Environment: <none> Mounts: <none> Volumes: <none> Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulCreate 18m daemonset-controller Created pod: filebeat-ds-bmscz
Job控制器
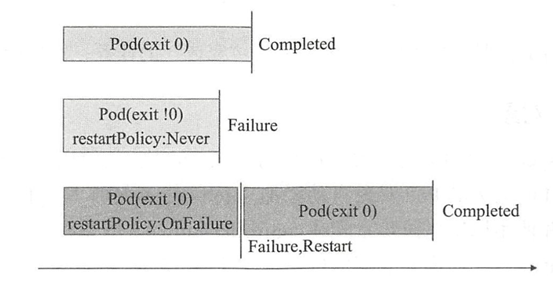
与Deployment及DaemonSet控制器管理的守护进程类的服务应用不同的是,Job控制器用于调配Pod对象运行一次性任务,容器中的进程在正常运行结束后不会对其进行重启,而是将Pod对象置于“Completed”(完成)状态。若容器中的进程因错误终止,则需要依配置确定重启与否,未运行完成的Pod对象因其所在的节点故障而意外终止后会被重新调度。Job控制器的Pod对象的状态转换如下图所示:
实践中,有的作业任务可能需要运行不止一次,用户可以配置它们以串行或并行的方式运行。总结起来,这种类型的Job控制器对象有两种,具体如下:
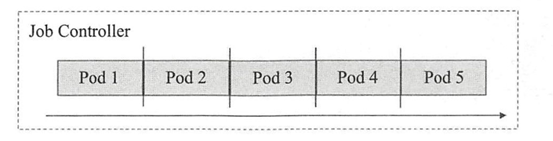
- 单工作队列(work queue)的串行式Job:
即以多个一次性的作业方式穿行执行多次作业,直至满足期望的次数,如下图所示,这次Job也可以理解为并行度为1的作业执行方式,在某个时刻仅存在一个Pod资源对象。
- 多工作队列的并行式Job:
这种方式可以设置工作队列数,即作业数,每个队列仅负责运行一个作业,如下图所示:
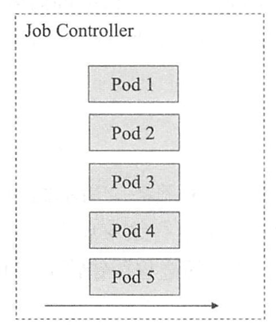
也可以用有限的工作队列运行较多的作业,即工作队列数少于总作业数,相当于运行多个串行作业队列。
如下图所示:
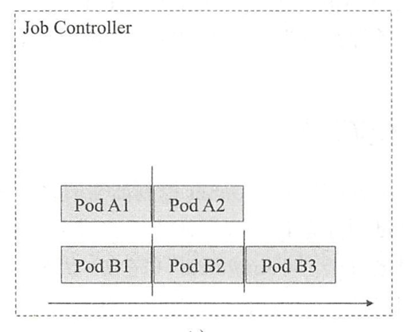
工作队列数即为同时可运行的Pod资源数。
Job控制器常用于管理那些运行一段时间便可“完成”的任务,例如计算或备份操作。
创建Job对象
Job控制器的spec字段内嵌的必要字段仅为template,它的使用方式与Deployment等控制器并无不同。Job会为其Pod对象自动添加“job-name=JOB_NAME”和“controller-uid=UID”标签,并使用标签选择器完成对controller-uid标签的关联。需要注意的是,Job位于API群组“batch/v1”之内。下面的资源清单文件(job-example.yaml)中定义了一个Job控制器:
使用“kubectl create”或“kubectl apply”命令完成创建后即可查看相关的任务状态
CronJob控制器
Service和Ingress
Service是Kuberntes和核心资源类型之一,通常可看作微服务的一种实现。事实上它是一种抽象:通过规则定义出由多个Pod对象组合而成的逻辑集合,以及访问这组Pod的策略。Service关联Pod资源的规则要借助于标签选择器来完成。
Service资源及其实现模型
Service资源概述
由Deployment等控制器管理的Pod对象中断后会新建的资源对象所取代,而扩缩容后的应用则会带来Pod对象群体的变动,随之变化的还有Pod的IP地址访问接口等,这也是编排系统之上的应用程序必然要面临的问题。例如,如下图
中的Nginx Pod作为客户端访问tomcat Pod中的应用时,IP的变动或应用规模的缩减会导致客户端访问错误,而Pod规模的扩容又会使得客户端无法有效地使用新增的Pod对象,从而影响达成扩展之目的。为此,kubernetes特地设计了Service资源来解决此类问题。
Service资源基于标签选择器将一组Pod定义成了一个逻辑组合,并通过自己的IP地址和端口调度代理请求至组内的Pod对象之上,如下图所示:
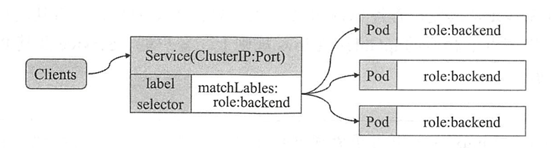
它向客户端隐藏了真实的、处理用户请求的Pod资源,使得客户端的请求看上去就像由Service直接处理并进行相应的一样。
Service对象的IP地址也称为Cluster IP,它位于为Kubernetes集群配置指定专用IP地址的范围之外,而且是一种虚拟IP地址,它在Service对象创建后即保持不变,并且能够被同一集群中的Pod资源所访问。Service端口用于接受客户端请求并将其转发至后端的Pod中应用的相应端口之上,因此,这种代理机制也称为“端口代理”(prot proxy)或四层代理,它工作于TCP/IP协议栈的传输层。
通过其标签选择器匹配到的后端Pod资源不止一个时,Service资源能够以负载均衡的方式进行浏览调度,实现了请求流量的分发机制。Service与Pod对象之间的关联关系通过标签选择器以松耦合的方式建立,它可以先于Pod对象创建而不会发生错误,于是,创建Service与Pod资源的任务可由不同的用户分别完成,例如,服务器架构的设计和创建由运维工程师进行,而填充其实现的Pod资源的任务则可交由开发者进行。Service控制器与Pod之间的关系如下图所示:
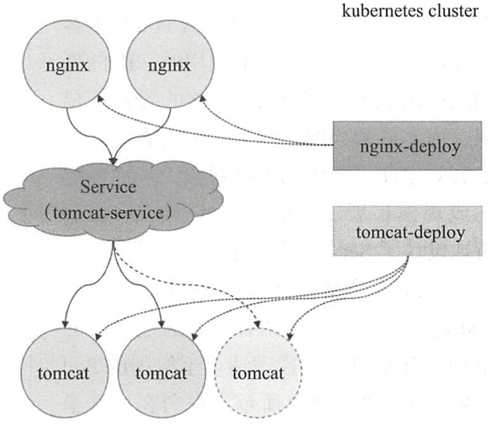
Service资源会通过API Server持续监视着(watch)标签选择器匹配到的后端Pod对象,并实时跟踪各对象的变动,例如,IP地址变动、对象增加或减少等。不过,需要特别说明的是,service并不直接链接至Pod对象,它们之间还有一个中间层——Endpoints资源对象,它是一个由IP地址和端口组成的列表,这些IP地址和端口则来自于Service的标签选择器匹配到的Pod资源。这也是很多场景中会使用“Service”的后端端点”(Endpoints)这一术语的原因。默认情况下,创建Service资源对象时,其关联的Endpoints对象会自动创建。
虚拟IP核服务代理
简单来讲,一个Service对象就是工作节点上的一些iptables或ipvs规则,用于将到达Service对象IP地址的流量调度转发至相应的Endpoints对象指向的IP地址和端口之上。工作于每个工作节点的kube-proxy组件通过API Server持续监控着各Service及与其关联的Pod对象,并将其创建或变动实时反映至当前工作节点上相应的iptables或ipvs规则上。客户端、Service及其Pod对象的关系如下图所示:
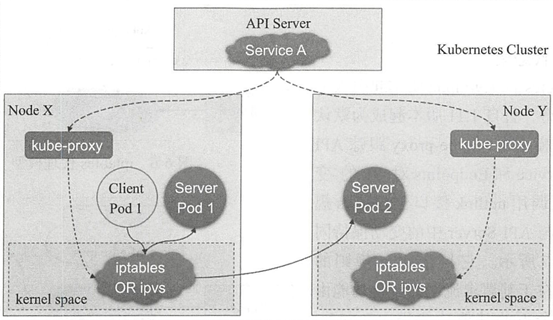
提示:Netfilter是Linux内核中用于管理网络报文的框架,它具有网络地址转换(NAT)、报文改动和报文过滤等防火墙功能,用户借助于用户空间的iptables等工具可按需自由定制规则使用其各项功能。ipvs是借助于Netfilter实现的网络请求报文调度框架,支持rr、wrr、lc、wlc、sh、sed和nq等十余种调度算法,用户空间的命令行工具是ipvsadm,用于管理工作于ipvs之上的调度规则。
Service IP事实上是用于生成iptables或ipvs规则时使用的IP地址,它仅用于实现Kubernetes集群网络的内部通信,并且仅能将规则中定义的转发服务的请求作为目标地址予以响应,这也是被称为虚拟IP的原因之一。kube-proxy将请求代理至相应端点的方式有三种:userspace(用户空间)、iptables和ipvs。
(1)userspace代理模型
此处的userspace是指Linux操作系统的用户空间。这种模型中,kube-proxy负责跟踪API Server和Endpoints对象的变动(创建或移除),并据此调整Service资源的定义。对于每个Service对象,它会随机打开一个本地端口(运行于用户空间的kube-proxy进程负责监听),任何到达此代理端口的连接请求都被代理至当前Service资源后端的各Pod对象上,至于会挑中哪个Pod对象则取决于当前Service资源的调度方式,默认的调度算法是轮询(round-robin),其工作逻辑如下图所示:
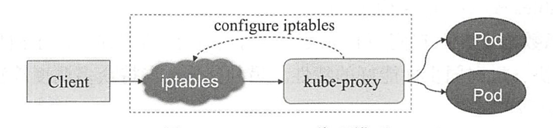
另外,此类的Service对象还会创建iptables规则以捕获任何到达ClusterIP和端口的流量。在Kubernetes 1.1版本之前,userspace是默认的代理模型。
这种代理模型中,请求流量到达内核空间后经由套接字送往用户空间的kube-proxy,而后再由它送回内核空间,并调度至后端Pod。这种方式中,请求在内核空间和用户空间来回转发必然会导致效率不高。
(2)iptables代理模型
同前一种代理模型类似,iptables代理模型中,kube-proxy负责跟踪API Server上Service和Endpoints对象的变动(创建或移除),并据此做出Service资源定义的变动。同时,对于每个Service,它都会创建iptables规则直接捕获到达Cluster IP和Port的流量,并将其重定向至当前Service的后端,如下图所示:
对于每个Endpoints对象,Service资源会为其创建iptables规则并关联至挑选的后端Pod资源,默认算法是随机调度(random)。iptables代理模式由Kubernetes 1.1版本引入,并自1.2版本开始称为默认的类型。
在创建Service资源时,集群中每个节点上的kube-proxy都会收到通知并将其定义为当前节点上的iptables规则,用于转发工作接口接收到的此Service资源的Cluster IP和端口的相关流量。客户端发来的请求被相关的iptables规则进行调度和目标地址转换(DNAT)后再转发至集群内的Pod对象之上。
相对于用户空间模型来说,iptables模型无须将流量在用户空间和内核空间来回切换,因而更加高效和可靠。不过,其缺点是iptables代理模型不会在被挑中的后端Pod资源无响应时自动进行重定向,而userspace模型则可以。
(3)ipvs代理模型
Kubernetes自1.9-alpha版本起引入了ipvs代理模型,且自1.11版本起称为默认设置。此中模型中,kube-proxy跟踪API Server上Service和Endpoints对象的变动,据此来调用netlink接口创建ipvs规则,并确保与API Server中的变动保持同步,如下图所示:
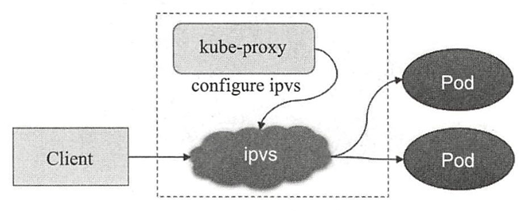
它与iptables规则的不同之处仅在于其请求流量的调度功能由ipvs实现,余下的其他功能仍由iptables完成。
类似于iptables模型,ipvs构建于netfilter的钩子函数之上,但它使用hash表作为底层数据结构并工作于内核空间,因此具有流量转发速度快、规则同步性能好的特性。另外,ipvs支持众多调度算法,例如rr、lc、dh、sh、sed和nq等。
Service资源的基础应用
Service资源本身并不提供任务服务,真正处理相应客户群请求的是后端的Pod资源。
创建Service资源
创建Service对象的常用方法有两种:一是直接使用“kubectl expose”命令,另一个是使用资源配置文件,它与此前使用资源清单文件配置其他资源的方法类似。定义Service资源对象时,spec的两个较为常用的内嵌字段分别为selector和ports,分别用于定义使用的标签选择器和要暴露的端口。下面的配置清单是一个Service资源示例:
cat myapp-svc.yaml apiVersion: v1 kind: Service metadata: name: myapp-svc spec: selector: app: myapp ports: - protocol: TCP port: 80 targetPort: 80
Service资源myapp-svc通过标签选择器关联至标签为“app=myapp”的各Pod对象,它会自动创建名为myapp-svc的Endpoints资源对象,并自动配置一个Cluster IP,暴露的端口由port字段进行指定,后端各Pod对象的端口则由targetPort给出,也可以使用同Port字段的默认值。myapp-svc创建完成后,使用下面的命令既能获取相关的信息输出以了结资源的状态:
kubectl create -f myapp-svc.yaml service/myapp-svc created kubectl get svc myapp-svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE myapp-svc ClusterIP 10.109.4.148 <none> 80/TCP 13s
上面命令中的结果显示,myapp-svc的类型为默认的Cluster IP,其使用的地址自动配置为10.109.4.148。此类型的Service对象仅能通过此IP地址接收来自于集群内的客户端Pod中的请求。若集群上存在标签为“app=myapp”的Pod资源,则它们会被关联和创建,作为此Service对象的后端Endpoint对象,并负责接收相应的请求流量。类似下面的命令可用于获取Endpoint资源的端点列表。
kubectl get endpoints myapp-svc NAME ENDPOINTS AGE myapp-svc 10.244.1.78:80,10.244.1.83:80,10.244.1.85:80 5m15s
提示:也不可以为Service资源指定.spec.selector熟悉值,其关联的Pod资源可由用户手动创建Endpoints资源进行定义。
Service对象创建完成后即可作为服务被各客户端访问,但要真正响应这些请求,还是要依赖于各后端的资源对象。
向Service对象请求服务
Service资源的默认类型为ClusterIP,它仅能接受来自于集群中的Pod对象中的客户端程序的访问请求。下面创建一个专用的Pod对象,利用其交互式接口完成访问测试。为了简单起见,这里选择直接创建一个临时使用的Pod对象作为交互式使用的客户端进行,它使用CirrOS镜像,默认的命令提示符“/#”:
kubectl run cirros-$RANDOM --rm -it --image=cirros -- sh
提示:CirrOS是设计用来进行云计算环境测试的Linux微型发行版,它拥有HTTP客户端工具curl等
而后,在容器的交互式接口中使用curl命令对myapp-svc服务的ClusterIP(10.109.4.148)和Port(80/tcp)发起访问请求测试:
/ # curl -I http://10.109.4.148:80 HTTP/1.1 200 OK Server: nginx/1.15.7 Date: Fri, 26 Jul 2019 09:24:08 GMT Content-Type: text/html Content-Length: 612 Last-Modified: Tue, 27 Nov 2018 12:31:56 GMT Connection: keep-alive ETag: "5bfd393c-264" Accept-Ranges: bytes
可以在容器中添加hostname.html输出当前容器的主机名,可反复向myapp-svc的此URL路径发起多次请求以验证其调度的效果:
/ # for loop in 1 2 3 4; do curl -I http://10.109.4.148:80/hostname.html; done
当前Kubernetes集群的Service代理模式为iptables,它默认使用随机调度算法,因此Service会将客户端请求随机调度至与其关联的某个后端Pod资源上。命令取样次数越大,其调度效果也越接近算法的目标效果。
Service会话粘性
Service资源还支持Session affinity(粘性会话或会话粘性)机制,它能够将来自同一个客户端的请求始终转发至同一个后端的Pod对象,这意味着他会影响调度算法的流量分发功用,进而降低其负载均衡的效果。因此,当客户端访问Pod中的应用程序时,如果有基于客户端身份保存某些私有信息,并基于这些私有信息追踪用户的活动等一类的需求时,那么应该启用Session affinity机制。
Session affinity的效果仅会在一定时间期限内生效,默认值为10800秒,超出此时长之后,客户端的再次访问会被调度算法重新调度。另外,Service资源的Session affinity机制仅能基于客户端IP地址识别客户端身份,它会把经由同一个NAT服务器进行源地址转换的所有客户端识别为同一个客户端,调度粒度且效果不佳,因此,实践中并不推荐使用此种方法实现粘性会话。
Service资源通过.spec.sessionAffinity和.spec.sessonAffinityConfig两个字段配置粘性会话。spec.sessionAffinity字段用于定义要使用的粘性会话类型,它仅支持使用“None”和“ClientIP”两种熟悉值。
- None:不使用sessionAffinity,默认值。
- ClientIP:基于客户端IP地址识别客户端身份,把来自同一个源IP地址的请求始终调度至同一个Pod对象。
在启用粘性会话机制时,.spec.sessionAffinityConfig用于配置其会话保持的时长,它是一个嵌套字段,使用格式如下所示,其可用的时长范围为“1~86400”,默认为10800秒:
spec:
sessionAffinity: ClientIP
sessionAffinityConfig:
clientIP:
timeoutSeconds: <integer>
例如,基于默认的10800秒的超时时长,使用下面的命令修改此前的myapp-svc使用Session affinity机制:
kubectl patch services myapp-svc -p '{"spec": {"sessionAffinity": "ClientIP"}}' service/myapp-svc patched
而后再次于交互式客户端内测试其访问效果即可验证其会话粘性效果。
/ # for loop in 1 2 3 4; do curl -I http://10.109.4.148:80/hostname.html; done
服务发现
微服务意味着存在更多的独立服务,但他们并非独立的个体,而是存在着复杂的依赖关系切彼此之间通常需要进行非常频繁地交互和通信的群体。然而,建立通信之前,服务和服务之间该如何获知彼此的地址呢?在kubernetes系统上,Service为Pod中的服务类应用提供了一个稳定的访问入口,但Pod客户端中的应用如何得知特定Service资源的IP和端口呢?这个时候就需要引入服务发现(Service Discovery)的机制。
服务发现概述
简单来说,服务发现就是服务或者应用之间相互定位的过程。不过,服务发现并非新概念,传统的单体应用架构时代也会用到,只不过单体应用的动态性不强,更新和重新发布的频度较低,通常以月甚至以年计,基本上不会进行自动伸缩,因此服务发现的概念无须显性强调。在传统的单体应用网络位置发生变化时,由IT运维人员手动更新一下相关的配置文件基本上就能解决问题。但在微服务应用场景中,应用被拆分成众多的小服务,它们按需创建且变动就能解决问题。但在微服务应用场景中,应用被拆分成众多的小服务,它们按需创建且变动频繁,配置信息基本无法事先写入配置文件中并及时跟踪和反映动态变化,因此服务发现的重要性便随之凸显。
服务发现机制的基本实现,一般是事先部署好一个网络位置较为稳定的服务注册中心(也称为服务总线),服务提供者(服务端)向注册中心注册自己的位置信息,并在变动后及时予以更新,响应地,服务消费者则周期性地从注册中心获取服务提供者的最新位置信息位置信息丛而“发现”要访问的目标服务器资源。复杂的服务发现机制还能让服务提供者提供其描述信息、状态信息及资源使用信息等,以供消费者实现更为复杂的服务选择逻辑。
实践中,根据服务发现过程的实现方式,服务发现还可分为两种类型:客户端发现和服务端发现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号