Python Altair COVID-19疫情数据可视化实践经验分享
前言
其实这篇博客一开始在CSDN发表,奈何我修改一下以后再发表,CSDN就说我违反国家法定法规。。。不允许我发表了,经查询,CSDN的客服说疫情期间所有跟疫情有关的博客都不允许发布。。
作为一个刚开始写博客的小萌新,实在是收到了一点打击,转换阵地继续发表,一下正文开始:
差不多两个月前,刚好学校有一个社会实践的任务,又是疫情期间,又看到网上已经有各路大神位COVID-19的疫情数据进行统计分析和建模。自己又是学习计算机的一名学生,不想应付了事,就趁着这个机会,决定也做一个类似的数据可视化,效果如下图
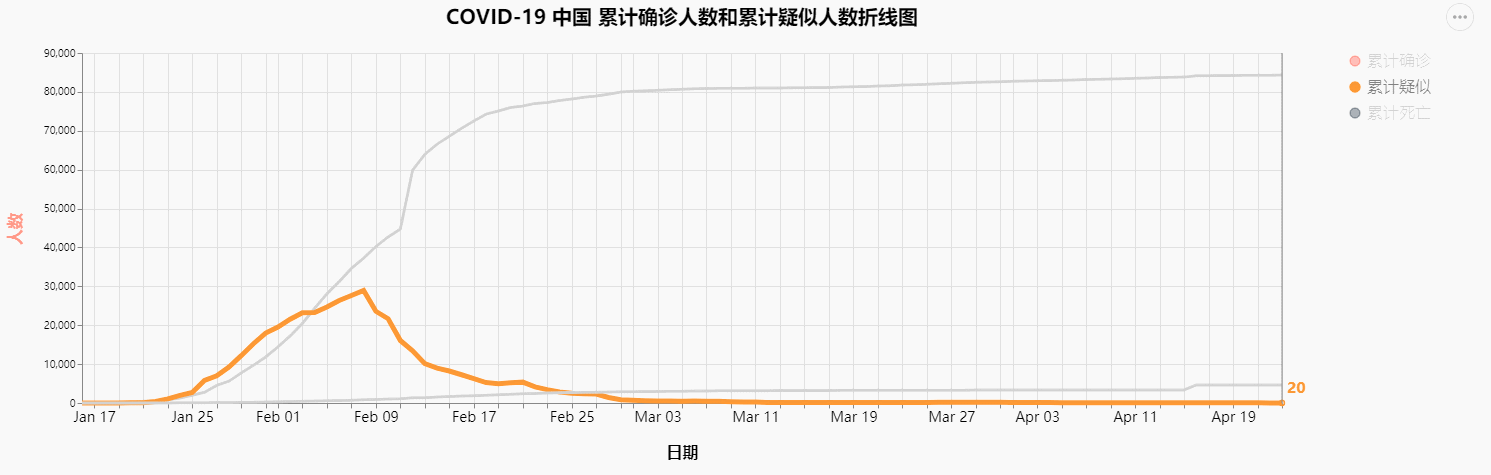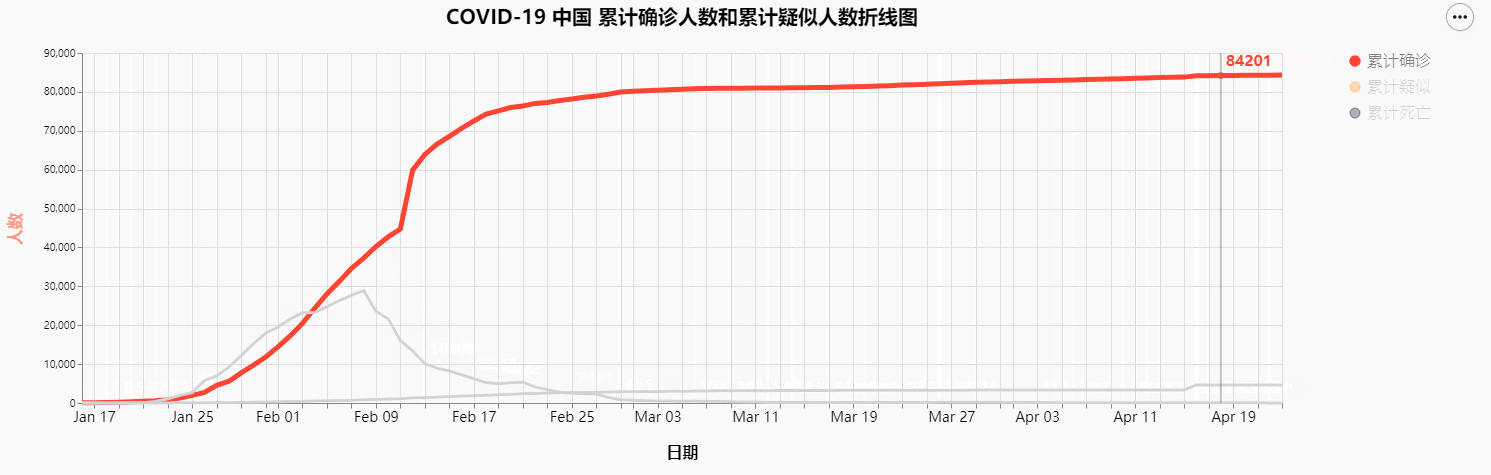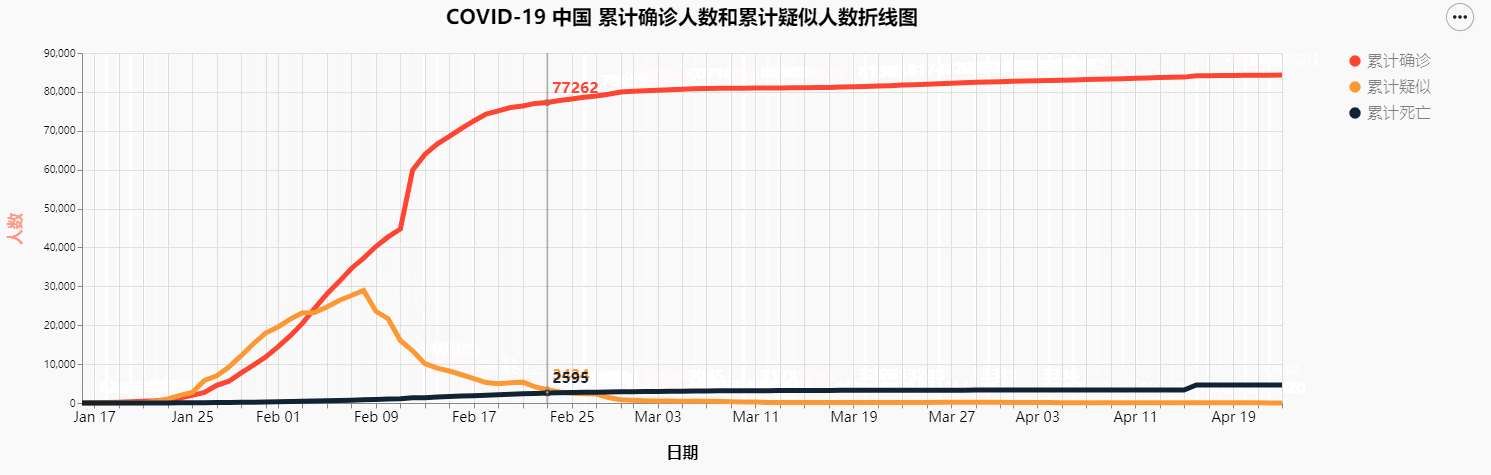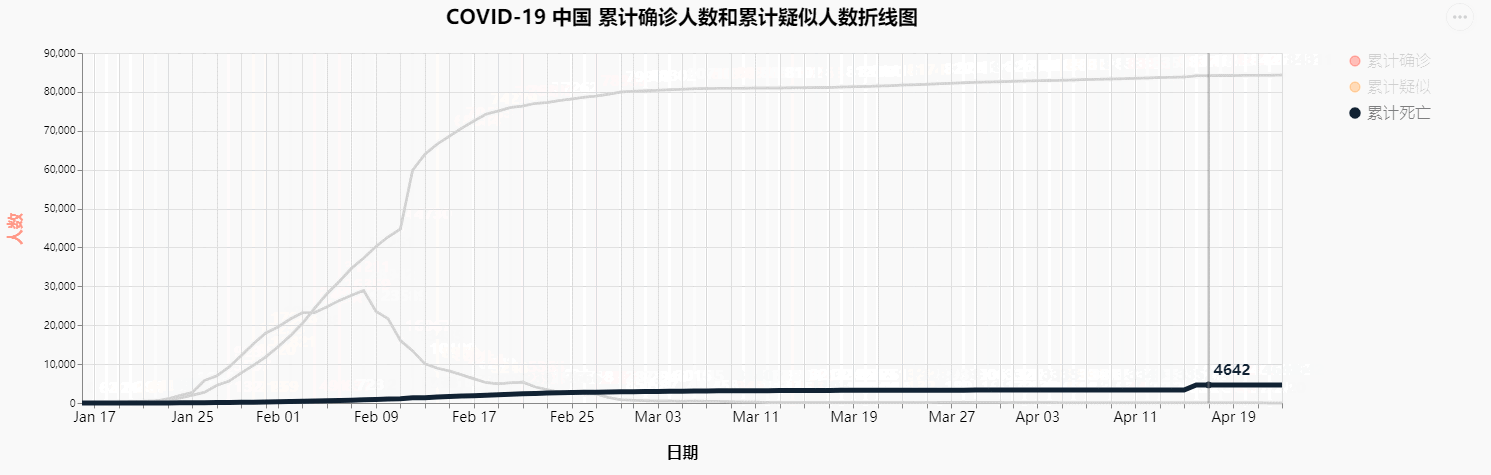
由于我想要实现的是可交互的图表,之前接触的matplotlib并不能满足我的这个需求,而pyechart这个库虽然比较简单方便,但是可定制化程度相对不高,风格也不是我喜欢的风格,所以寻寻觅觅,看上了Altair这个用于python可视化的库,但是网上关于这个库的使用的相关文章少之又少,所以自己去Altair
官网查看了相关文档和案例,终于完成了自己的目标,考虑到目前关于Altair的快速上手入门的教程基本没有,所以完成了这个项目后决定分享一下,方便后来者,仅仅是分享一下自己的心得,一点经验。如有不足,欢迎指出。
这个博客并不是一个给从零开始详细讲述关于python、numpy、pandas等的教程,而是为了达成目的的一个实践性心得,但是会尽量将一切讲得尽量详细,让初学者也可以跟着这个教程做出想要的美观的图表
COVID-19 疫情数据
数据从国家卫健委国家卫健委进行爬取,由于本次只专注于数据可视化,并且爬虫代码的有效性较短,如果国家卫健委修改了接口,那么就得重新分析,重构代码(本人项目期间国家卫健委的接口就修改了两次),所以此次不会进行爬虫的相关的讲解,我会直接给出爬取后序列化的csv文件。
Altair数据可视化
本次总共绘制以下几个几个图表:
- COVID-19 中国 累计确诊人数和累计疑似人数折线图
- COVID-19 中国 每日新增确诊人数和每日新增疑似确诊人数折线图
- COVID-19 中国 每日新增确诊增长率折线图
- COVID-19 中国 死亡率变化曲线图
- COVID-19 国内最严重省份(除湖北)确诊人数柱状图
- COVID-19 中国 前十严重省份累计确诊人数折线图
- COVID-19 世界累计确诊变化曲线
- COVID-19 海外各国(地区) 确诊人数柱状图
- COVID-19 全球 前五严重国家累计确诊人数折线图
- COVID-19 世界各国(地区) 确诊人数热度图
绘制图表的过程中我们用到的库有:
import os
import re
import json,requests
import geopandas
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import altair as alt
import datetime
import js2py
使用 jupyter lab(jupyter notebook)开发
预备知识
我们用pandas的DataFrame结构读取并保存我们csv文件中的数据,关于pandas不会过多讲解,但是有涉及到的都会力求让大家理解。十个图表大致可以分为折线图、柱状图、地理地图三大类,
在Altair中,altair.Chart (注:上面我们import altair 时, 是 import altair as alt,所以我们可以使用alt来指代altair,下文不再赘述)是基本的图表对象,我们可以使用mark_line()函数来绘制折线图,使用mark_point来绘制散点图,mark_bar来绘制柱状图,mark_geoshape()绘制地理地图。
绘制图表时需要有数据我们才能绘制图表,我们得需要把数据传递给alt.Char,根据Altair官方文档,所有最高层级的chart对象(包括:Chart, LayerChart, and VConcatChart, HConcatChart, RepeatChart, FacetChart,但是我们此次只需要用到Chart),都接受一个数据集作为其第一个参数,数据集可以是以下几种类型的:
- pandas 的 DataFrame 类型。
- Data 或者跟 Data 相关的对象。 (例如 UrlData, InlineData, NamedData)
- 一个指向 json 或者 csv 格式的url字符串,或者支持 geo_interface 接口的对象(例如 geopandas 的 GeoDataFrame,shapely 的 Geometries,GeoJson)
我们本次只会使用到pandas 的DataFrame,如果你此前对DataFrame并不熟悉甚至不了解也没关系,在这篇博客中我会讲下我们用到的地方。 本人对pandas并不是十分熟悉,如果想要深入了解,请自行查找相关资料。
如果你已经熟悉DataFrame下面可以跳过
DataFrame是一种形如:
| 时间 | 确诊人数 | 疑似人数 | 死亡人数 | |
|---|---|---|---|---|
| 1 | 2020-02-19 | 200 | 400 | 10 |
| 2 | 2020-02-20 | 300 | 600 | 20 |
的表格型数据结构,跟我们的excel表格类似,每一行都有单独的索引。
DataFrame有两种格式,一种是宽型:
| 时间 | 确诊人数 | 疑似人数 | 死亡人数 | |
|---|---|---|---|---|
| 0 | 2020-02-19 | 200 | 400 | 10 |
| 1 | 2020-02-20 | 300 | 600 | 20 |
这种就是宽型DataFrame,宽型DaraFrame每有一个独立变量值就会产生一行。元数据被记录在行和列标签中。
在这里每一行对应一个时间,每一个观察值(确诊人数、疑似人数、死亡人数)存储在这一行的一个列标签中。
还有一种是长型:
| 时间 | 类型 | 人数 | |
|---|---|---|---|
| 0 | 2020-02-19 | 确诊 | 200 |
| 1 | 2020-02-19 | 疑似 | 400 |
| 2 | 2020-02-19 | 死亡 | 10 |
| 3 | 2020-02-20 | 确诊 | 300 |
| 4 | 2020-02-20 | 疑似 | 600 |
| 5 | 2020-02-20 | 死亡 | 20 |
长型DataFrame每有一个观测值就有一行,元数据被作为值记录在表中。
在这里,每一行只包含一个观测值,还有伴随这个观察值的元数据。(在这里观察值是人数,时间和类型是伴随着这个观察值的元数据),最重要的是,列和索引标签,不再包含任何有用的索引信息。(简单来说就是宽型数据知道行列索引就可以知道对应元数据的还有确切意义,例如 行索引 0 列索引 确诊人数,我们就可以知道 2020-02-19 确诊人数是200,但是观察值。行索引 0 列索引 无论是时间还是类型,得到的都是无用的元数据,例如 行索引 0 列索引时间 得到的值是 2020-02-19,行索引 1 列索引时间 得到的值是 2020-02-19,并不唯一,并没有确定的意义,仅仅是一个值)
Altair在使用长型结构的DataFrame时可以有更好地表现,推荐使用长型,所以后面我们构建传递给Chart的DataFrame时都是构建长型的。
然后绘制图时,我们还需要告诉Chart哪些数据是作为x轴,哪些是作为y轴,在Altair中我们可以通过调用Chart对象的encode方法并往里面传递参数来对我们的x轴、y轴等进行设置。例如如下一个DataFrame:
| | 时间 |确诊人数
|--|--|--|--|
| 0 | 2020-02-19 |200 |
| 3 | 2020-02-20 |300 |
由于Chart还支持链式调用,所以我们可以使用
alt.Chart(data).mark_line().encode(x='时间',y='确诊人数')
来画出以时间为x轴,确诊人数为y轴的折线图,展现出确诊人数随时间变化的折线图。
COVID-19 中国 累计确诊人数和累计疑似人数折线图
为了绘制出COVID-19 中国 累计确诊人数和累计疑似人数折线图,我们需要中国疫情发生以来每日的疫情数据,我们所要用到的数据都在上面下载的资源里的 中国每日历史数据(截止到 2020-XX-XX).csv (2020-XX-XX可能会根据你下载的时间而有所不同)文件中,现假设你下载了数据集并且将其解压在了D:\ 盘下,所以你D:\ 下应该会有 :
- 2020-1-1-2020-1-23湖北迁出前十城市.csv
- 中国每日历史数据(截止到 2020-04-23).csv
- 中国省份总数据.csv
- 修复后的世界地图.csv
- 全球国家每日历史数据(截止至2020-04-23).json
file_name = 'D:\\中国每日历史数据(截止到 2020-XX-XX).csv'
chinaDayHisDf = pd.read_csv(file_name)
# 可以使用 chinaDayHisDf .head(number) number 是你想查看的前几行行数,若置空则默认五行
# 可以使用 chinaDayHisDf.info() 查看这个DataFrame的相关信息
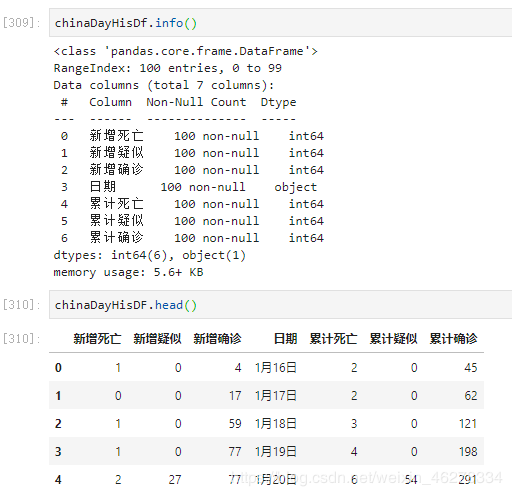
可以看到我们这个chinaDayHisDf的结构是:
| 新增死亡 | 新增疑似 | 新增确诊 | 日期 | 累计死亡 | 累计疑似 | 累计确诊 |
|---|---|---|---|---|---|---|
| 1 | 0 | 4 | 1月16日 | 2 | 0 | 45 |
| 0 | 0 | 17 | 1月17日 | 2 | 0 | 62 |
| 1 | 0 | 59 | 1月18日 | 3 | 0 | 121 |
| 1 | 0 | 77 | 1月19日 | 4 | 0 | 198 |
| 2 | 27 | 77 | 1月20日 | 6 | 54 | 291 |
| 3 | 26 | 149 | 1月21日 | 9 | 37 | 440 |
| 8 | 257 | 131 | 1月22日 | 17 | 393 | 571 |
| 8 | 680 | 259 | 1月23日 | 25 | 1072 | 830 |
| 16 | 1118 | 444 | 1月24日 | 41 | 1965 | 1287 |
| 15 | 1309 | 688 | 1月25日 | 56 | 2684 | 1975 |
| 24 | 3806 | 769 | 1月26日 | 80 | 5794 | 2744 |
| 26 | 2077 | 1769 | 1月27日 | 106 | 6973 | 4535 |
| 26 | 3248 | 1459 | 1月28日 | 132 | 9239 | 5597 |
| 38 | 4148 | 1741 | 1月29日 | 170 | 12167 | 7736 |
| 43 | 4812 | 1985 | 1月30日 | 213 | 15238 | 9720 |
| 46 | 5019 | 2104 | 1月31日 | 259 | 17988 | 11821 |
| ... | ... | ... | ... | ... | ... | ... |
我们首先简单地绘制出一天累计确诊人数的增长曲线,我们用到的数据有日期,累计确诊,以日期为x轴,累计确诊人数为y轴,我们先来绘制最简单的累计确诊人数随日期变化的曲线:
# 若使用的是jupyter lab 或类似的环境并且已经设定是,直接在代码模式下 输入chart运行便可查看结果
# 若是其他环境,则需要 chart.save('chart.html') 名字可随意, 生成html文件查看
chart = alt.Chart(chinaDayHisDF).mark_line().encode(
x='日期',
y='累计确诊'
)
结果如下面所示:
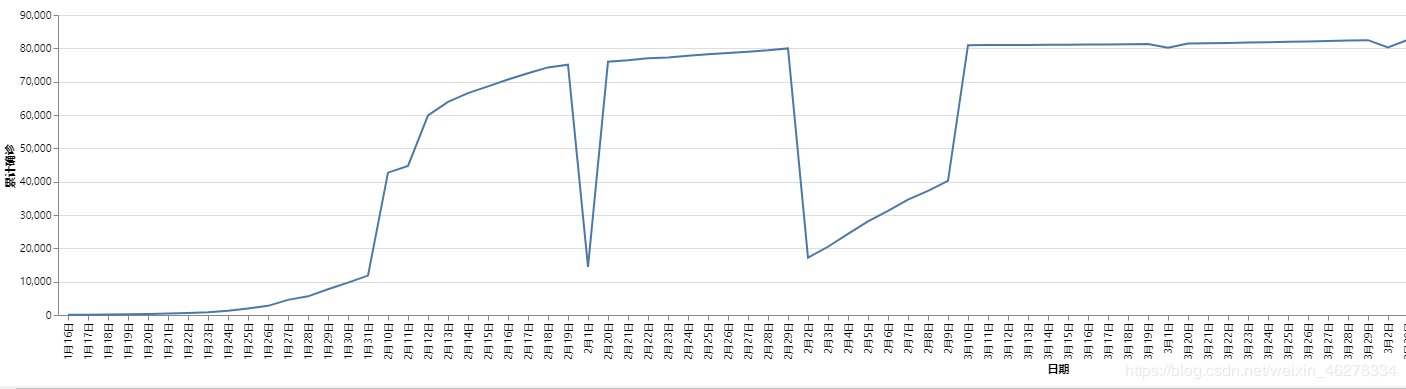
观察x轴可以看出日期的排序并不正确,这是由于我们日期所存储的数据是字符串类型的,所以自动按照了字符串的排序方法进行了排序,所以导致了显示的不正确,为了显示正确,我们需要将日期转换成便于操作的TimeStamp类型。观察日期的格式可以发现,我们可以用月和日提取出对应的月份,和日期,这需要用到正则表达式,此时不细讲正则表达式,所以仅贴出代码供参考:
def changeDate(dateStr):
# 定义匹配规则,将'月'前面的数字提取并划分到group[0]
# 将'日'前面的数字提取并划分到group[1]
rex = r'([\d]+)月([\d]+)日'
# 对dateStr进行匹配,并获取对应的月 日
m = re.match(rex,dateStr)
mon = m.groups()[0]
day = m.groups()[1]
# 构建初始化TimrStamp所需要的字符串
str = '2020-%s-%s' % (mon,day)
date = pd.to_datetime(str)
return date
有了这个函数,我们需要将这个函数应用到chinaDayHisDF每一行中的['日期']列,如果不熟悉DataFrame的朋友可能会直接用循环来迭代,对每一个值进行修改。
但是DataFrame为我们提供了简单的apply函数,可以将一个函数一你个用到每一行,或者每一列中。具体可查阅相应文档。
chinaDayHisDF['日期'] = chinaDayHisDF['日期'].apply(changeDate)
此时再绘制一次我们的图表,可以发现此时已经正常显示了,并且由于我们的['日期']是TImeStamp类型,所以Altair自动帮我们将x轴以日期的形式显示。

接下来我们需要对x轴,y轴进行自定义修改,例如修改x轴标题,标题颜色,字体大小,要达到这个目的,我们可以调用Chart.encode()函数对这些进行设置。(Chart对象可以链式调用,Chart().mark_line() 返回的还是Chart对象, 所以可以Chart(chinaDayHisDF).mark_line().encode()来进行调用)
alt.Chart(chinaDayHisDF).mark_line().encode(
x=alt.X('日期'),
# 使用axis参数对轴进行定义,此处我们传递一个我们自定义的alt.Axis对象进去
y=alt.X('累计确诊',axis=alt.Axis(title='累计确诊人数',titleFontSize=15,titleColor='red'))
)
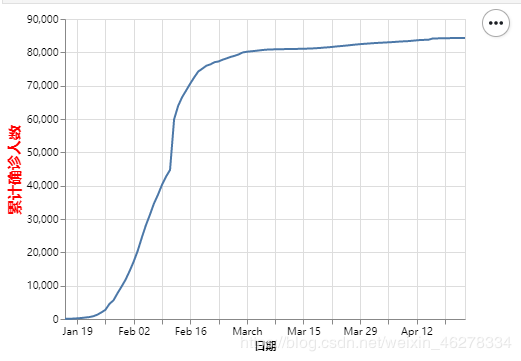
但我们现在的DataFrame格式是宽型的,同时绘制多条折线(例如同时绘制累计确诊人数,累计疑似确诊人数,累计死亡人数)十分不便,根据官方文档的建议,我们应该使用长型的数据格式,效率更高并且更方便。
所以我们需要一个['symbol']列来区分不同的折线,通过['count']列存储元数据,即存储对应的类型的人数。
构建对应的长型DataFrame代码如下:
# 创建可视化确诊和疑似确诊 Altair库需要的数据格式
data = {
'date':chinaDayHisDF['日期'],
'symbol':'累计确诊',
'count':chinaDayHisDF['累计确诊']
}
chinaConfAndSusDf = pd.DataFrame(data)
data = {
'date':chinaDayHisDF['日期'],
'symbol':'累计疑似',
'count':chinaDayHisDF['累计疑似']
}
chinaConfAndSusDf = chinaConfAndSusDf.append(pd.DataFrame(data))
data = {
'date':chinaDayHisDF['日期'],
'symbol':'累计死亡',
'count':chinaDayHisDF['累计死亡']
}
chinaConfAndSusDf = chinaConfAndSusDf.append(pd.DataFrame(data))
chinaConfAndSusDf 格式如下:
| date | symbol | count |
|---|---|---|
| 2020-01-16 | 累计确诊 | 45 |
| 2020-01-17 | 累计确诊 | 62 |
| 2020-01-18 | 累计确诊 | 121 |
| 2020-01-19 | 累计确诊 | 198 |
| 2020-01-20 | 累计确诊 | 291 |
| 2020-01-21 | 累计确诊 | 440 |
| 2020-01-22 | 累计确诊 | 571 |
| 2020-01-23 | 累计确诊 | 830 |
| 2020-01-24 | 累计确诊 | 1287 |
| 2020-01-25 | 累计确诊 | 1975 |
| 2020-01-26 | 累计确诊 | 2744 |
| ... | ... | ... |
此时若是直接绘制折线图可以发现并不是我们所预期的效果,这是因为只告诉了Chart要显示的x轴数据和y轴数据,但是此时有三个类型的需要同时绘制,即三组y轴的数据,并不能区分出来,所以需要我们告诉Chart对象到底用哪一列进行区分。我们可以往Chart.encode()传入color参数,用不同的颜色区分不同的折线。
alt.Chart(chinaConfAndSusDf).mark_line().encode(
x=alt.X('date',axis=alt.Axis(title='日期')),
y=alt.Y('count:Q',axis=alt.Axis(title='累计确诊人数',titleFontSize=15,titleColor='red')),
color='symbol'
)

此时我们对累计死亡人数的折线颜色不满意,希望用黑色来绘制累计死亡人数的折线,并且自动生成的图例标题是默认的’symbol‘,我们需要对其进行设置,并且默认生成的图表大小过小,我们可以通过Chart.properties对图表的长宽进行设置
color = alt.Color('symbol:N',legend=alt.Legend(title='图例'),
scale=alt.Scale(domain=['累计确诊','累计疑似','累计死亡'], range=['#FF4433','#FF9933','#112233']))
alt.Chart(chinaConfAndSusDf).mark_line().encode(
x=alt.X('date',axis=alt.Axis(title='日期')),
y=alt.Y('count:Q',axis=alt.Axis(title='累计确诊人数',titleFontSize=15,titleColor='red')),
color=color
).properties(
width=1200, height=350
)

但此时我们的图表还仅仅是静态的图表,并没有体现Altair库的优势,我们所需要的是一个动态的可交互的可视化图表。我们需要实现的功能是有一条竖线指示我们当前所在的x轴日期点,并且这个竖线会随我们的鼠标移动而在x轴上移动,并且在竖线于折线的交点上显示对应的人数。并且折线太多时会影响我们查看数据,所以我们还需要一个筛选功能,当我们点击对应图例时,只会显示当前图例对应的折线,其它折线灰显。
为了实现以上功能,我们需要介绍Altair的一个概念,selection和condition,selection是一种选择器,可以理解为根据不同的情况做出不同的反应,selection必须被添加在图上才可以使用,其中做出的反应由condition确定,某些属性的值可以根据不同的condition做出不同的响应或许我说得不清楚,有意向的朋友可以移步Altair官网查看文档我这里仅仅以解决上述问题入手说明一下
由于我们需要根据我们的鼠标做出反应,所以需要一个selection来跟我们鼠标移动这个事件绑定在一起,同时我们的rule是根据鼠标移动时而在x轴上移动,所以我们这个selection select的是date,根据不同的date,rule有不同的反应。所以首先我们得先把这个selection添加到我们的图上,但是我们的图是折现图,selection 好像只能绑定点图(官网没查阅到相关信息,但是自己有测试),所以我们需要一个点图来给绑定我们我的selection,或者用我们的线图中的mark_point方法来画出点图,在这里直接用我们的line线图的mark_point()方法产生一个point点图,selection通过这份点图 就可以找到对应的X值,但是point和line互相重叠,由于我们的主图是线图line,所以point图的点都需要设置透明,不可见。rule直线显示我们的当前位置和跟着我们的鼠标在x轴方向上左右移动,我们的rule通过chart的transform_filter来达到这样的效果,transform_filter可以理解为一个“过滤器”,根据selection,只在当前select的值做出反应。同时,我们的点图point应当在rule所在的交点显示出点,但是在其他应该都透明不可见,所以我们的point图应该根据condition来决定是否透明,此处是,当前select不透明,其他地方透明。所以point的opacity (透明度)应该设置为opacity=alt.condition(nearest, alt.value(1), alt.value(0)),1 不透明,0透明。同时我们需要用chart.mark_text()来显示人数值,这个同理,设置文本的text为count的值,同时其他未被select的地方都显示 ' '空白字符就行了
同时由于现在我们有了一个text的chat,一个line的chart,一个point的chart,还有一个rule的chart 总共有多张图要一起画在一张图上,所以我们需要使用alt.layer(line,point,text)来一起显示
这里可能有点难理解,如果本人讲得不够清楚,可以前往官网查阅
nearest = alt.selection_multi(name='nearest', nearest=True, on='mouseover',fields=['date'],empty='none')
line = alt.Chart(chinaConfAndSusDf,width=800,height=300).mark_line().encode(
x=alt.X('date', axis=alt.Axis(title='日期',titleFontSize=16,titlePadding=20,grid=True,labelFontSize=14)),
y=alt.Y('count', axis=alt.Axis( title='人数',titleFontSize=16,titleColor='#FF9988',titlePadding=20)),
color=alt.Color('symbol',legend=alt.Legend(title=None,titleFontSize=16,titleOpacity=0.5,titlePadding=20,labelFontSize=16,rowPadding=10,labelOpacity=0.5,offset=60),
scale=alt.Scale(domain=['累计确诊','累计疑似'], range=['#FF4433','#FF9933']))
)
points = line.mark_point(strokeWidth=5).encode(
x=alt.X('date', axis=alt.Axis(title='日期',titleFontSize=16,titlePadding=20,grid=True,labelFontSize=14)),
y=alt.Y('count', axis=alt.Axis( title='人数',titleFontSize=16,titleColor='#FF9988',titlePadding=20)),
opacity=alt.condition(nearest, alt.value(1), alt.value(0)),
).add_selection(
nearest
)
text = line.mark_text(align='left', dx=5, dy=-15,fontSize=15, fontWeight='bold').encode(
text=alt.condition(nearest, 'count', alt.value(' ')),
)
rules = alt.Chart(chinaConfAndSusDf).mark_rule(strokeWidth=2,color='gray',opacity=0.2).encode(
x=alt.X('date')
).transform_filter(
nearest
)
alt.layer(line,rules,points,text)
细心的读者可能发现,移动鼠标的时候,rule线很不跟手,有一种很卡顿的感觉,这其实是为什么呢?其实这个原因一开始我也没有发现,以为官方示例不够好,官方的示例是即使有了线图,也不会有现有的线图画点图,而是新画一个点图,这个点图只有x轴,y轴不设置,即默认都是0,这是为什么呢?看下我们的selection,它的nearest=True,,表明它会选取离我们最近的点,这样问题就来了,如果我们用line画出点图,由于我们需要显示点在曲线上,即这个点必须有x坐标,y坐标,并且在这个点图上添加selection,那么这个最近就会同时以x,y计算,得到的不是离我们最近的x轴的值,所以可能会出现跳跃现象,所以为了平滑,我们需要修改一下,不用line直接画点图,而且重新用数据构建一份点图,这份点图只有x轴,y的值系统选取,即是一条直线,这样就避免了跳跃,图也会流畅。最后我们只需要一个绑定legend(图例)的selection就行了,当select时,曲线显示,未select的曲线灰显,并且文本透明。不一一细说,好好理解selection condition之后都大同小异
# Create a selection that chooses the nearest point & selects based on x-value
# nearest 是一个selection,字面意思就是选择器,可以给它一个名字方便后续使用,也可以指定类型type,是单选择器还是多选择器
# 选择器可以看作一种选择判断、一种根据情况做出不同显示的类
# nearst=True表明选择最近的点,on是指定绑定什么事件,在这里是mouseover即鼠标移动,fields指定绑定的字段,在这里是指定X轴,即根据X轴取值
# 在这里,即是根据不同的date值有不同的情况
nearest = alt.selection(name='nearest',type='single', nearest=True, on='mouseover',
fields=['date'],empty='none')
# selCur 是一个selection,字面意思就是选择器,可以给它一个名字方便后续使用,
# fields指定绑定的字段,bind只当这个选择器绑定在那里
# 在这里就是这个选择器绑定在legend(图例)上,同时根据字段‘symbol’进行区分
# 在这里,即是根据不同的symbol值有不同的情况
selCur = alt.selection_multi(name='selCur',fields=['symbol'],bind='legend')
# color类可以为我们的曲线,图例设置不同的颜色,区分曲线,
# 可以用一个legend类构造color的legend,各种属性名字很好地表现出了它的作用
# scale属性可以用一个Scale类来实例化,domain指定了颜色作用的“域”,可以根据domain来区分不同的曲线,range可以分别设置颜色
# 在这里就是累计确诊用#FF4433颜色显示,累计疑似用#FF9933显示
color = alt.Color('symbol:N',legend=alt.Legend(title=None,titleFontSize=16,titleOpacity=0.5,titlePadding=20,labelFontSize=16,rowPadding=10,labelOpacity=0.5,offset=60),
scale=alt.Scale(domain=['累计确诊','累计疑似','累计死亡'], range=['#FF4433','#FF9933','#112233']))
# alt.Chart(data)画出图,这里data是我们需要绘制的数据,mark_line方法表明这是一个线图
# encode方法里面面的x属性是设置x轴alt.X是X轴的类,可以指定用那些列作为我们的x轴,axis是对坐标轴进行设计,同理,X中的date是列明,指定date做X轴
# 由于我们的是TimeStamp类型,是一个日期格式,所以可以用monthdata来只显示月日
# The basic line
line = alt.Chart(chinaConfAndSusDf).mark_line().encode(
x=alt.X('monthdate(date):T', axis=alt.Axis(title='日期',titleFontSize=16,titlePadding=20,grid=True,labelFontSize=14)),
y=alt.Y('count', axis=alt.Axis( title='人数',titleFontSize=16,titleColor='#FF9988',titlePadding=20)),
# condition 跟selection配合使用,第一个值为selection,第二个值是True时的值,即被选中时的值,第三个Fasle值
color=alt.condition(selCur,color,alt.value('lightgray')),
strokeWidth=alt.condition(selCur,alt.value(5),alt.value(3))
)
# Transparent selectors across the chart. This is what tells us
# the x-value of the cursor
# 选择器还需要挂载到我们的图上才行,不然是不起作用的
selectors = alt.Chart(chinaConfAndSusDf).mark_point(strokeWidth=3).encode(
x=alt.X('monthdate(date):T'),
opacity=alt.value(0),
).add_selection(
nearest
)
# Draw points on the line, and highlight based on selection
points = line.mark_point(strokeWidth=5).encode(
opacity=alt.condition(nearest, alt.value(1), alt.value(0)),
size=alt.condition(selCur,alt.value(3),alt.value(0)),
).add_selection(
selCur
)
# Draw text labels near the points, and highlight based on selection
text = line.mark_text(align='left', dx=5, dy=-15,fontSize=15, fontWeight='bold').encode(
text=alt.condition(nearest, 'count', alt.value(' ')),
opacity=alt.condition(selCur, alt.value(1), alt.value(0)),
)
# Draw a rule at the location of the selection
rules = alt.Chart(chinaConfAndSusDf).mark_rule(strokeWidth=2,color='gray',opacity=0.2).encode(
x=alt.X('monthdate(date):T')
).transform_filter(
nearest
)
# Put the five layers into a chart and bind the data
alt.layer(
line, selectors, points, rules, text
).properties(
width=1200, height=350,
title= {
"text": "COVID-19 中国 累计确诊人数和累计疑似人数折线图",
"fontSize": 20,
'offset':20
}
).configure_view(stroke=None)
最终结果图像如下:
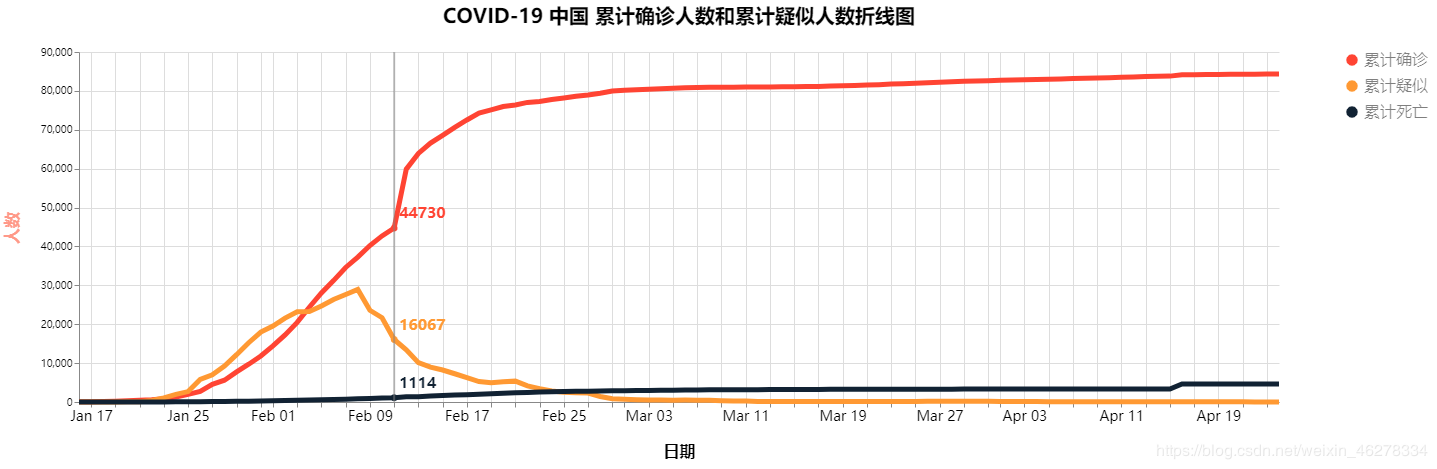
COVID-19 中国 每日新增确诊人数和每日新增疑似确诊人数折线图
与COVID-19 中国 累计确诊人数和累计疑似人数折线图类似,我们只需要构建对应的每日新增确诊人数,每日新增确诊疑似人数,死亡人数即可,在此不再赘述。
最终结果如图所示:

COVID-19 中国 每日新增确诊增长率折线图
构建COVID-19 中国 每日新增确诊增长率折线图与上述类似,不过我们并没有直接的每日新增确诊增长率的数据,所以我们需要从我们现有的数据构建出我们需要的数据。
我们先看一下我们的数据:
| 新增死亡 | 新增疑似 | 新增确诊 | 日期 | 累计死亡 | 累计疑似 | 累计确诊 |
|---|---|---|---|---|---|---|
| 1 | 0 | 4 | 1月16日 | 2 | 0 | 45 |
| 0 | 0 | 17 | 1月17日 | 2 | 0 | 62 |
| 1 | 0 | 59 | 1月18日 | 3 | 0 | 121 |
| 1 | 0 | 77 | 1月19日 | 4 | 0 | 198 |
| 2 | 27 | 77 | 1月20日 | 6 | 54 | 291 |
| 3 | 26 | 149 | 1月21日 | 9 | 37 | 440 |
| 8 | 257 | 131 | 1月22日 | 17 | 393 | 571 |
| 8 | 680 | 259 | 1月23日 | 25 | 1072 | 830 |
| 16 | 1118 | 444 | 1月24日 | 41 | 1965 | 1287 |
| 15 | 1309 | 688 | 1月25日 | 56 | 2684 | 1975 |
| 24 | 3806 | 769 | 1月26日 | 80 | 5794 | 2744 |
| 26 | 2077 | 1769 | 1月27日 | 106 | 6973 | 4535 |
| 26 | 3248 | 1459 | 1月28日 | 132 | 9239 | 5597 |
| 38 | 4148 | 1741 | 1月29日 | 170 | 12167 | 7736 |
| 43 | 4812 | 1985 | 1月30日 | 213 | 15238 | 9720 |
| 46 | 5019 | 2104 | 1月31日 | 259 | 17988 | 11821 |
| ... | ... | ... | ... | ... | ... | ... |
为了利于操作,直接在DataFrame上新增一列昨天的累计确认人数,然后我们今日累计确诊列减去昨天累计确诊列再除昨日确诊人数就可以计算出COVID-19每日确诊ren's的增长率。DateFrame.shift()函数可以讲某一列往后偏移一定量,DateFrame.shift()就是偏移一位例如:
数据本来是
那么偏移后的数据是
其中NaN是not a number 的意思,因为本来一前面就没有其他数据了,所以偏移后到底是什么呢?numpy用了NaN来指明NaN会在后续我们对数据的操作中引发很多异常,所以我们要进行处理,很自然地,我们用0来替代NaN。
yesDayConfirm = chinaDayListDF.confirm.shift()
yesDayConfirm[0] = 0
chinaDayListDF['yesDayConfirm'] = yesDayConfirm
# 使用round保留两位小数
chinaDayListDF['confirmAddRate'] = round((chinaDayListDF['confirm'] - chinaDayListDF['yesDayConfirm'])/ chinaDayListDF['yesDayConfirm']*100,2)
# 由于上一步存在 0 除上其他数 或者 其他数除0地可能,
# 所以可能会产生np.inf,-np.inf等,所以我们需要讲这些都替换为0
chinaDayListDF = chinaDayListDF.replace([np.inf,-np.inf,np.NaN],0)
操作过后的DataFrame应该是以下格式:
| 新增死亡 | 新增疑似 | 新增确诊 | 日期 | 累计死亡 | 累计疑似 | 累计确诊 | yesDayConfirm | confirmAddRate | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 4 | 2020-01-16 | 2 | 0 | 45 | 0.0 | inf |
| 1 | 0 | 0 | 17 | 2020-01-17 | 2 | 0 | 62 | 45.0 | 37.78 |
| 2 | 1 | 0 | 59 | 2020-01-18 | 3 | 0 | 121 | 62.0 | 95.16 |
| 3 | 1 | 0 | 77 | 2020-01-19 | 4 | 0 | 198 | 121.0 | 63.64 |
| 4 | 2 | 27 | 77 | 2020-01-20 | 6 | 54 | 291 | 198.0 | 38.89 |
| 5 | 3 | 26 | 149 | 2020-01-21 | 9 | 37 | 440 | 291.0 | 51.2 |
| 6 | 8 | 257 | 131 | 2020-01-22 | 17 | 393 | 571 | 440.0 | 29.77 |
| 7 | 8 | 680 | 259 | 2020-01-23 | 25 | 1072 | 830 | 571.0 | 45.36 |
| 8 | 16 | 1118 | 444 | 2020-01-24 | 41 | 1965 | 1287 | 830.0 | 53.49 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
剩下的操作与之前类似,不再赘述。
最终结果如下图所示:

求增长人数可以用时间序列的一次差分来绘制出,求增长率可以对时间序列进行对数化处理再进行一次差分操作绘制出,这涉及到时间序列的处理,仅提一句
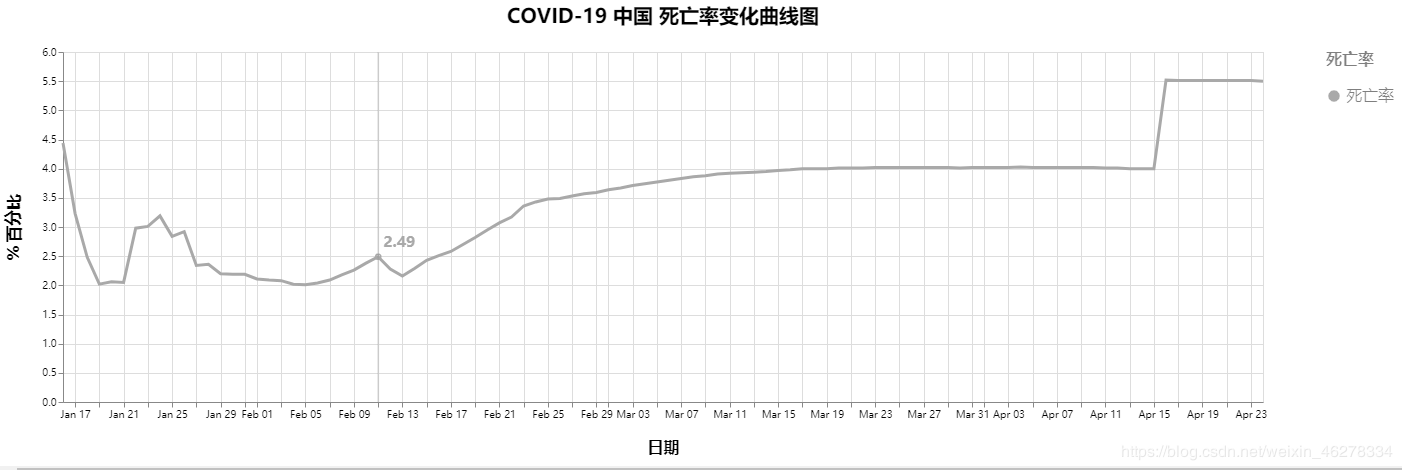
COVID-19 中国 死亡率变化曲线图
与上述操作类似,不再赘述
最终结果如下图所示:
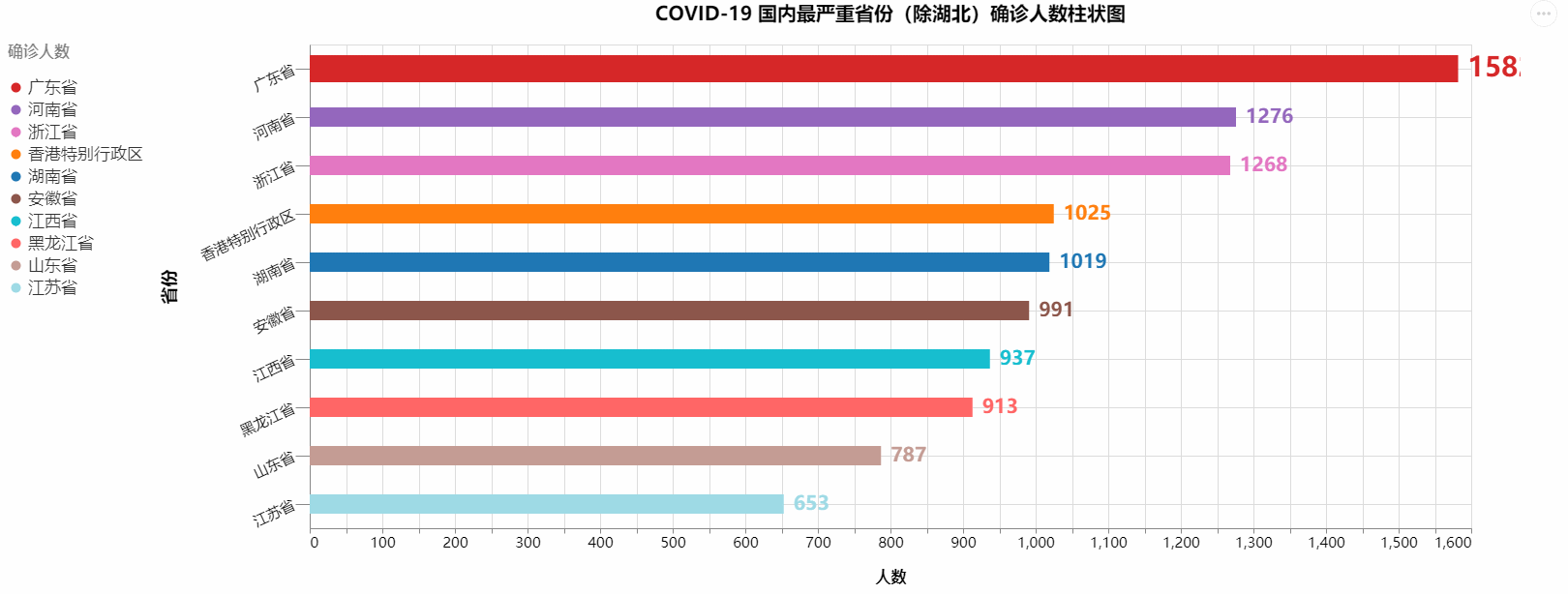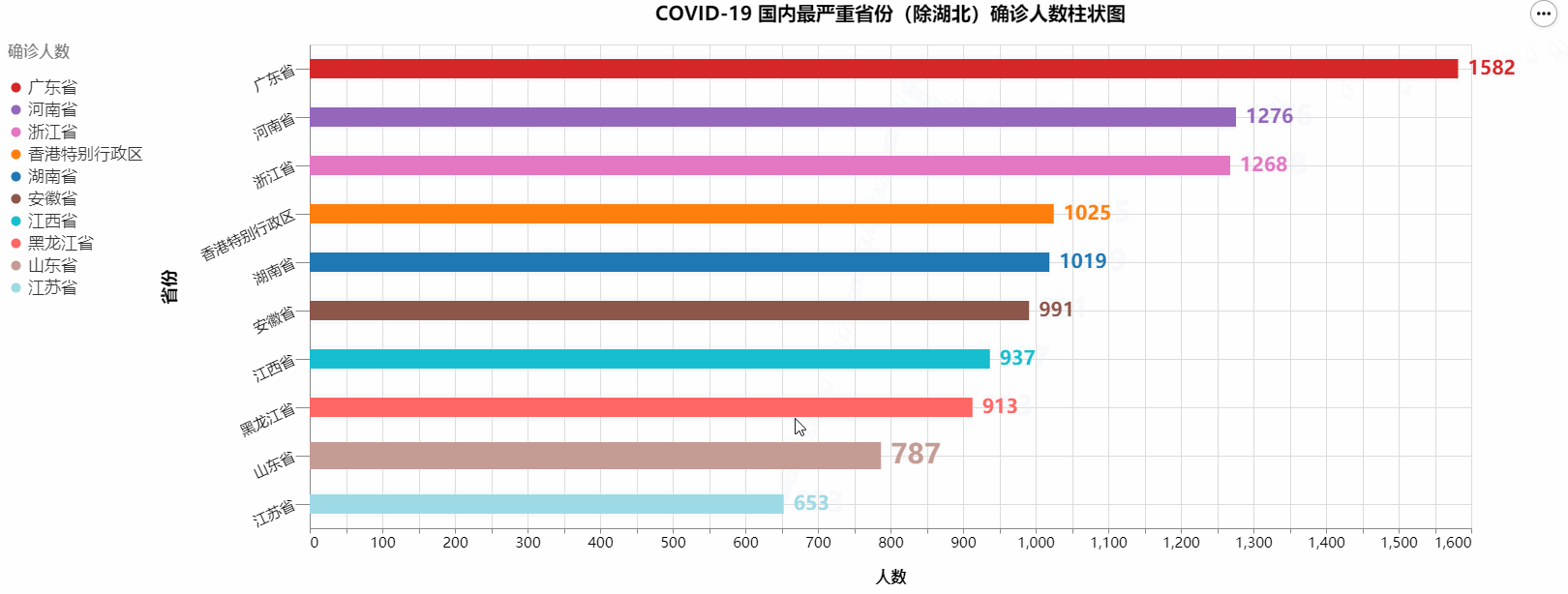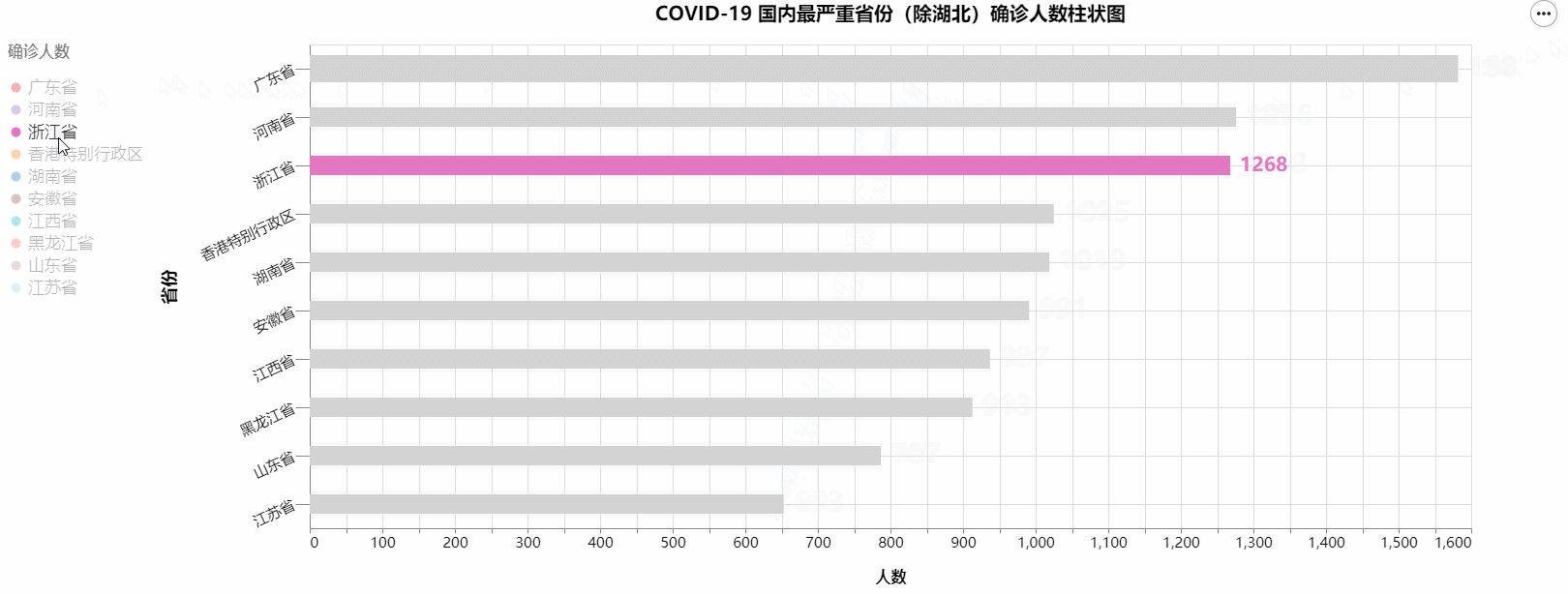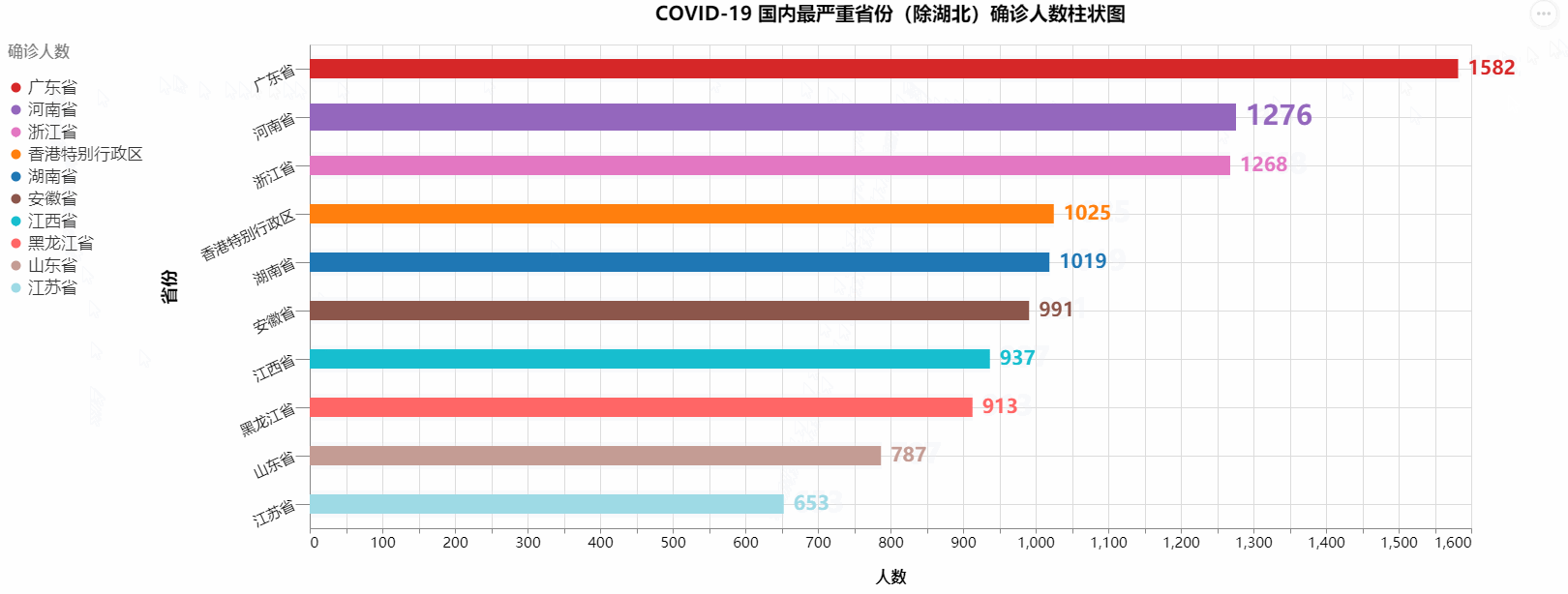
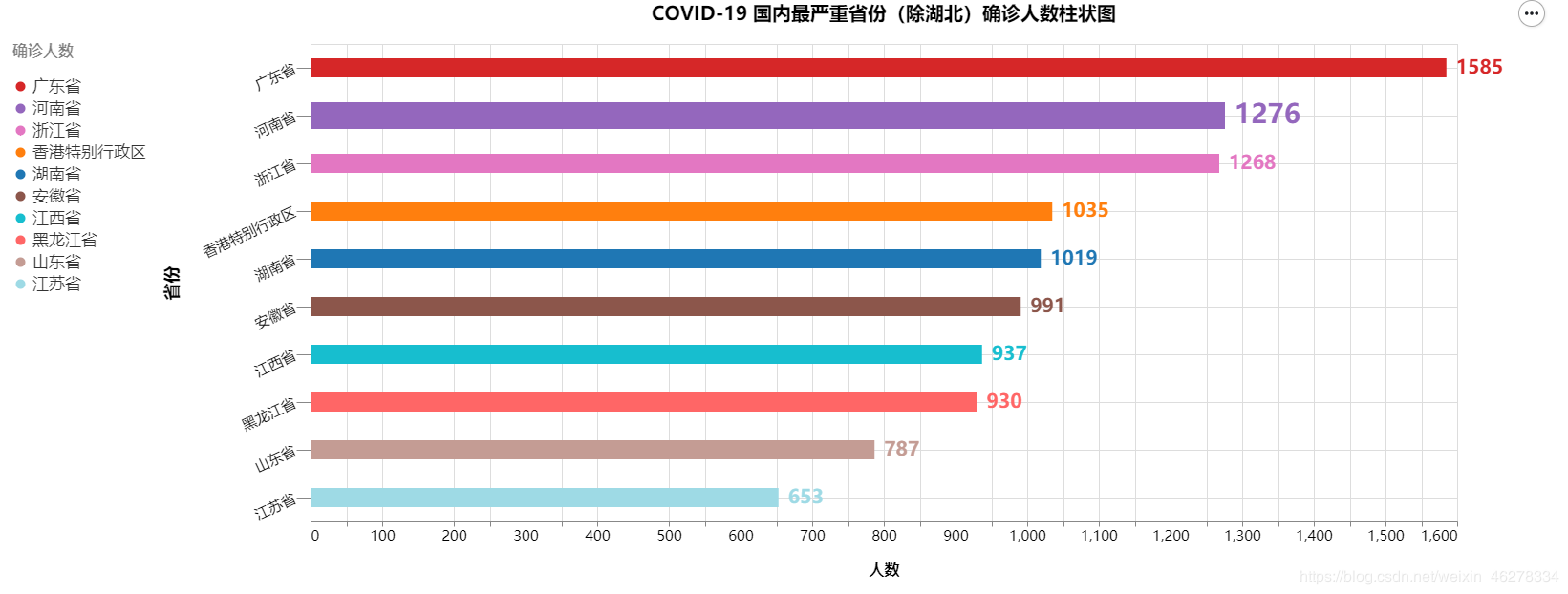
COVID-19 国内最严重省份(除湖北)确诊人数柱状图
对于我们要绘制的省内的数据,我们需要读取我上传的DataSet里面‘中国省份总数据.csv’
# 路径根据自己的路径进行修改
file_name = 'D:\\中国省份总数据.csv'
chinaProviceTotalDataDf = pd.read_csv(file_name)
由于这个DataFrame太大,我们无法在这里显示出来,各位读者有兴趣的可以自己去看看
我们目前有的是中国全部省份的每天的历史数据,而我们绘制的COVID-19 国内最严重省份(除湖北)确诊人数柱状图仅仅需要每个省份最新的数据,所以我们得先把每个省份最新得数据单独提取出来,构建一个全国所有省份最新数据的DataFrame
chinaProviceDataDf = pd.DataFrame()
chinaDayDf = pd.DataFrame()
# columns 中是每个省份名称,通过这个提取特定的省份数据
for name in list(chinaProviceTotalDataDf.columns):
df = pd.DataFrame(list(chinaProviceTotalDataDf[name]))
df['日期'] = df['日期'].apply(changeDate)
# 最近日期的索引
maxDayIdx = df['日期'] == np.max(df['日期'])
d = {
'name': name,
'date': df[maxDayIdx]['日期'],
'confirm': df[maxDayIdx]['累计确诊'],
'suspect': df[maxDayIdx]['累计疑似']
}
chinaProviceDataDf = chinaProviceDataDf.append(pd.DataFrame(d))
chinaProviceDataDf = chinaProviceDataDf.reset_index()
chinaProviceDataDf = chinaProviceDataDf.drop(columns='index')
生成的DataFrame : chinaProviceDataDf格式如下
| name | date | confirm | suspect | |
|---|---|---|---|---|
| 0 | 上海市 | 2020-04-24 | 641 | 12 |
| 1 | 云南省 | 2020-04-24 | 185 | 0 |
| 2 | 内蒙古自治区 | 2020-04-24 | 197 | 4 |
| 3 | 北京市 | 2020-04-24 | 593 | 1 |
| ... | ... | ... | ... | ... |
DataFrame.sort_valules()函数可以根据一个列的值大小进行升降序排序,然后我们通过head()函数可以获取出前几行,所以我们可以如下获取前五严重和前十严重的省份数据
most5ProDF = chinaProviceDataDf.drop(index=(chinaProviceDataDf[chinaProviceDataDf.name == '湖北省'].index)).sort_values('confirm',ascending=False).head(5)
most10ProDF = chinaProviceDataDf.drop(index=(chinaProviceDataDf[chinaProviceDataDf.name == '湖北省'].index)).sort_values('confirm',ascending=False).head(10)
selBarCur = alt.selection_multi(name='selBarLegend',fields=['name'],bind='legend')
hoverSel = alt.selection(name='hoverSel',type='single', nearest=True, on='mouseover',
fields=['name'],empty='none')
color = alt.Color('name:N',scale=alt.Scale(
domain=list(most10ProDF.name),
range=['#d62728','#9467bd','#e377c2','#ff7f0e','#1f77b4',
'#8c564b','#17becf','#FF6666','#c49c94','#9edae5']),
legend=alt.Legend(title='确诊人数', titleFontSize=16,titleOpacity=0.5,titlePadding=20,labelFontSize=17,rowPadding=5,labelOpacity=0.8,orient='left'))
# color = alt.Color('name:N',scale=alt.Scale(scheme='tableau20' ),
# legend=alt.Legend(title='确诊人数', titleFontSize=16,titleOpacity=0.5,titlePadding=20,labelFontSize=15,rowPadding=5,labelOpacity=0.8))
bar = alt.Chart(most10ProDF).mark_bar().encode(
x=alt.X('confirm',axis=alt.Axis(title='人数',titleFontSize=16,titlePadding=20,grid=True,labelFontSize=15)),
y=alt.Y('name:N',sort=list(most10ProDF.name),axis=alt.Axis(title='省份',titleFontSize=18,titlePadding=20,grid=True,tickSize=15,labelFontSize=15,labelPadding=2,labelAngle=-25)),
# color = alt.Color('name:N',legend=alt.Legend(title='确诊人数', titleFontSize=16,titleOpacity=0.5,titlePadding=20,labelFontSize=15,rowPadding=5,labelOpacity=0.5))
color=alt.condition(selBarCur,color,alt.value('lightgray')),
size=alt.condition(hoverSel,alt.value(28),alt.value(20)),
)
point = alt.Chart(most10ProDF).mark_point().encode(
y=alt.Y('name',sort=list(most10ProDF.name)),
opacity=alt.value(0)
).add_selection(
hoverSel
)
text = bar.mark_text(align='left', dx=10, dy=0,fontSize=15, fontWeight='bold').encode(
text='confirm',
opacity=alt.condition(selBarCur,alt.value(1),alt.value(0))
).add_selection (
selBarCur
)
alt.layer(
point,bar,text,
).properties(
width=1200,height=500,
title= {
"text": "COVID-19 国内最严重省份(除湖北)确诊人数柱状图",
"fontSize": 20,
'offset':20
}
)
绘制出的图标如下:
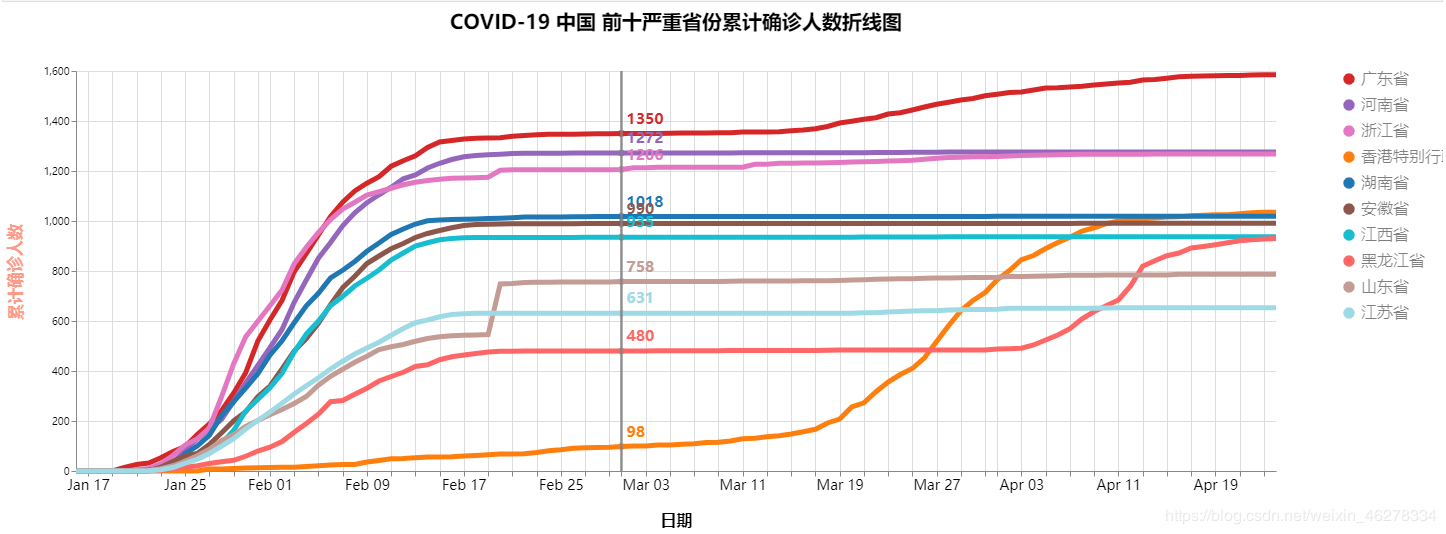
COVID-19 中国 前十严重省份累计确诊人数折线图
我们已经获取了前十严重的省份,所以我们可以取出省份名,再进行一个for循环获取出每个省份的历史数据然后构建我们需要的DataFrame。此处不再赘述。
most10ProList = list(most10ProDF.name)
chinaMost10ProDayHisDf = pd.DataFrame()
for name in most10ProList:
df = pd.DataFrame(list(chinaProviceTotalDataDf[name]))
df['日期'] = df['日期'].apply(changeDate)
d = {
'name': name,
'日期': df['日期'],
'累计确诊': df['累计确诊'],
}
chinaMost10ProDayHisDf = chinaMost10ProDayHisDf.append(pd.DataFrame(d))
import altair as alt
import pandas as pd
import numpy as np
# Create a selection that chooses the nearest point & selects based on x-value
nearest = alt.selection(name='nearest',type='single', nearest=True, on='mouseover',
fields=['日期'],empty='none')
selCur = alt.selection_multi(name='selCur',fields=['name'],bind='legend')
color = alt.Color('name:N',legend=alt.Legend(title=None, titleFontSize=16,titleOpacity=0.5,titlePadding=20,labelFontSize=16,rowPadding=10,labelOpacity=0.5,offset=60),
scale=alt.Scale(domain=list(chinaMost10ProDayHisDf.name),
range=['#d62728','#9467bd','#e377c2','#ff7f0e','#1f77b4',
'#8c564b','#17becf','#FF6666','#c49c94','#9edae5']))
# The basic line
line = alt.Chart(chinaMost10ProDayHisDf).mark_line().encode(
x=alt.X('monthdate(日期):T', axis=alt.Axis(title='日期',titleFontSize=16,titlePadding=20,grid=True,labelFontSize=14)),
y=alt.Y('累计确诊', axis=alt.Axis( title='累计确诊人数',titleFontSize=16,titleColor='#FF9988',titlePadding=20)),
color=alt.condition(selCur,color,alt.value('lightgray')),
strokeWidth=alt.condition(selCur,alt.value(5),alt.value(3)),
)
# Transparent selectors across the chart. This is what tells us
# the x-value of the cursor
selectors = alt.Chart(chinaMost10ProDayHisDf).mark_point(strokeWidth=3).encode(
x=alt.X('monthdate(日期):T'),
opacity=alt.value(0),
).add_selection(
nearest
)
# Draw points on the line, and highlight based on selection
points = line.mark_point(strokeWidth=5).encode(
opacity=alt.condition(nearest, alt.value(1), alt.value(0)),
size=alt.condition(selCur,alt.value(3),alt.value(0)),
).add_selection(
selCur
)
# Draw text labels near the points, and highlight based on selection
text = line.mark_text(align='left', dx=5, dy=-15,fontSize=15, fontWeight='bold').encode(
text=alt.condition(nearest, '累计确诊', alt.value(' ')),
opacity=alt.condition(selCur, alt.value(1), alt.value(0)),
)
# Draw a rule at the location of the selection
rules = alt.Chart(chinaMost10ProDayHisDf).mark_rule(strokeWidth=2,color='gray',opacity=0.2).encode(
x=alt.X('monthdate(日期):T')
).transform_filter(
nearest
)
# Put the five layers into a chart and bind the data
alt.layer(
line, selectors, points, rules, text
).properties(
width=1200, height=400,
title= {
"text": "COVID-19 中国 前十严重省份累计确诊人数折线图",
"fontSize": 20,
'offset':20
}
).configure_view(stroke=None)
最终效果如下所示:
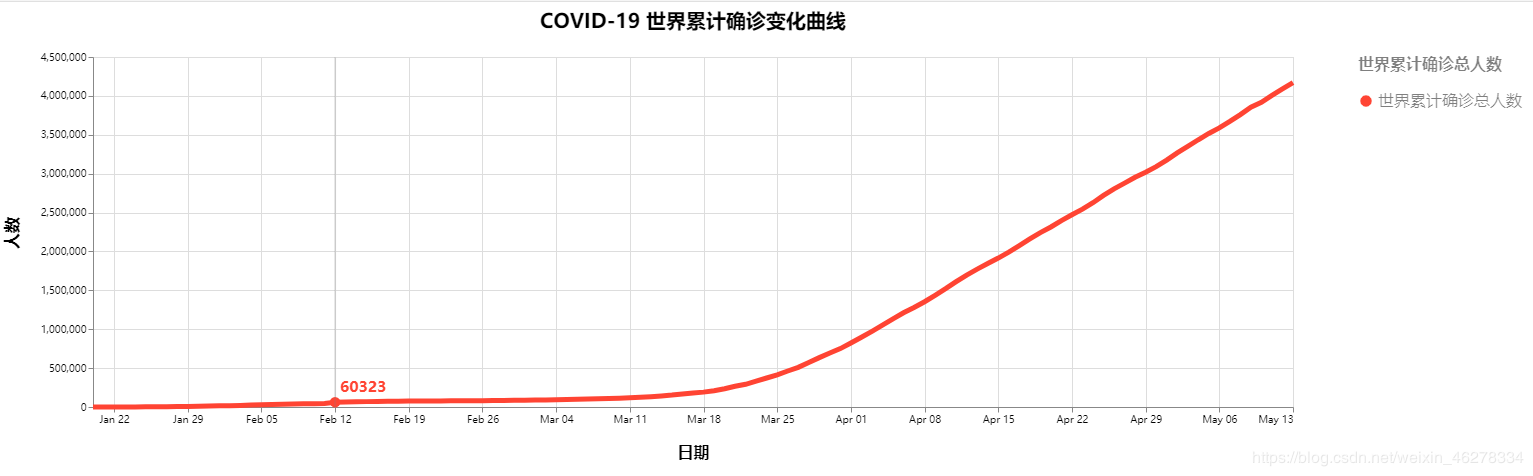
COVID-19 世界累计确诊变化曲线
世界整体疫情数据存放在 ‘全球每日历史数据.csv’中,按照之前的操作,即可简单完成,不再赘述。
最终效果如下所示:
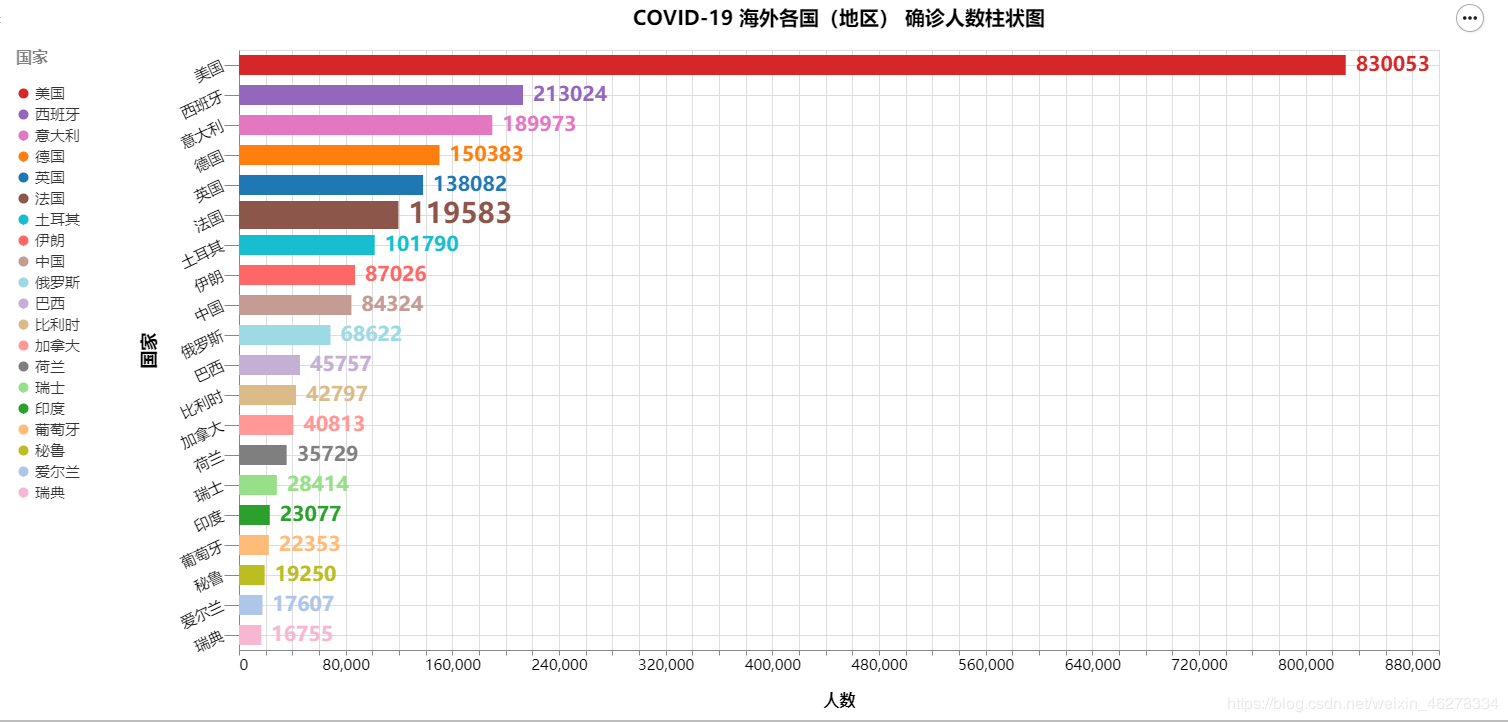
COVID-19 海外各国(地区) 确诊人数柱状图
由于每个国家数据开始统计的时间不一致,所以体现在数据格式上就是长度不一致,所以没办法直接整个存入在csv中,为了方便,DataSet中提供了全球国家每日历史数据的json文件,我们只需要读取json文件,将其存在dict中。
# file_name为全球国家每日历史数据(截止至2020-04-24).json在你电脑上的对应的路径
with open('%s' % file_name,'r') as f:
globalDict = json.loads(f.read())
然后我们读取每个国家中最近日期的累计确诊人数,将其保存下来
# file_name为全球国家每日历史数据(截止至2020-04-24).json在你电脑上的对应的路径
with open('%s' % file_name,'r') as f:
globalDict = json.loads(f.read())
globalCountryDf = pd.DataFrame()
for name in globalDict.keys():
tempDf = pd.DataFrame(globalDict[name])
tempDf['日期'] = tempDf['日期'].apply(changeDate)
df = tempDf[tempDf['日期'] == np.max(tempDf['日期'])]
d = {
'date' : df['日期'],
'name': name,
'confirm': df['累计确诊']
}
globalCountryDf = globalCountryDf.append(pd.DataFrame(d))
globalPCountryDf = globalCountryDf.sort_values('confirm',ascending=False).head(20)
selBarCur = alt.selection_multi(name='selBarLegend',fields=['name'],bind='legend')
hoverSel = alt.selection(name='hoverSel',type='single', nearest=True, on='mouseover',
fields=['name'],empty='none')
color = alt.Color('name:N',scale=alt.Scale(
domain=list(globalPCountryDf['name']),
range=['#d62728','#9467bd','#e377c2','#ff7f0e','#1f77b4',
'#8c564b','#17becf','#FF6666','#c49c94','#9edae5',
'#c5b0d5','#dbbb88','#ff9896','#7f7f7f','#98df8a',
'#2ca02c','#ffbb78','#bcbd22','#aec7e8','#f7b6d2']),
legend=alt.Legend(title='国家', titleFontSize=16,titleOpacity=0.5,titlePadding=20,labelFontSize=15,rowPadding=5,labelOpacity=0.8,offset=60,orient='left'))
# color = alt.Color('name:N',scale=alt.Scale(scheme='tableau20' ),
# legend=alt.Legend(title='确诊人数', titleFontSize=16,titleOpacity=0.5,titlePadding=20,labelFontSize=15,rowPadding=5,labelOpacity=0.8))
bar = alt.Chart(globalPCountryDf).mark_bar(size=23).encode(
# ,scale=alt.Scale(domain=(0,max))
x=alt.X('confirm',axis=alt.Axis(title='人数',titleFontSize=16,titlePadding=20,grid=True,labelFontSize=15)),
y=alt.Y('name:N', sort=list(globalPCountryDf),axis=alt.Axis(title='国家',titleFontSize=18,titlePadding=20,grid=True,tickSize=15,labelFontSize=15,labelPadding=2,labelAngle=-25)),
# color = alt.Color('name:N',legend=alt.Legend(title='确诊人数', titleFontSize=16,titleOpacity=0.5,titlePadding=20,labelFontSize=15,rowPadding=5,labelOpacity=0.5))
color=alt.condition(selBarCur,color,alt.value('lightgray')),
size=alt.condition(hoverSel,alt.value(28),alt.value(20)),
)
point = alt.Chart(globalPCountryDf).mark_point().encode(
y=alt.Y('name',sort=list(globalPCountryDf)),
opacity=alt.value(0)
).add_selection(
hoverSel
)
text = bar.mark_text(align='left', dx=10, dy=0,fontSize=15, fontWeight='bold').encode(
text='confirm',
opacity=alt.condition(selBarCur,alt.value(1),alt.value(0))
).add_selection (
selBarCur
)
alt.layer(
bar,text,point
).properties(
width=1200,height=600,
title= {
"text": "COVID-19 海外各国(地区) 确诊人数柱状图",
"fontSize": 20,
'offset':20
}
)
最终效果如下所示:
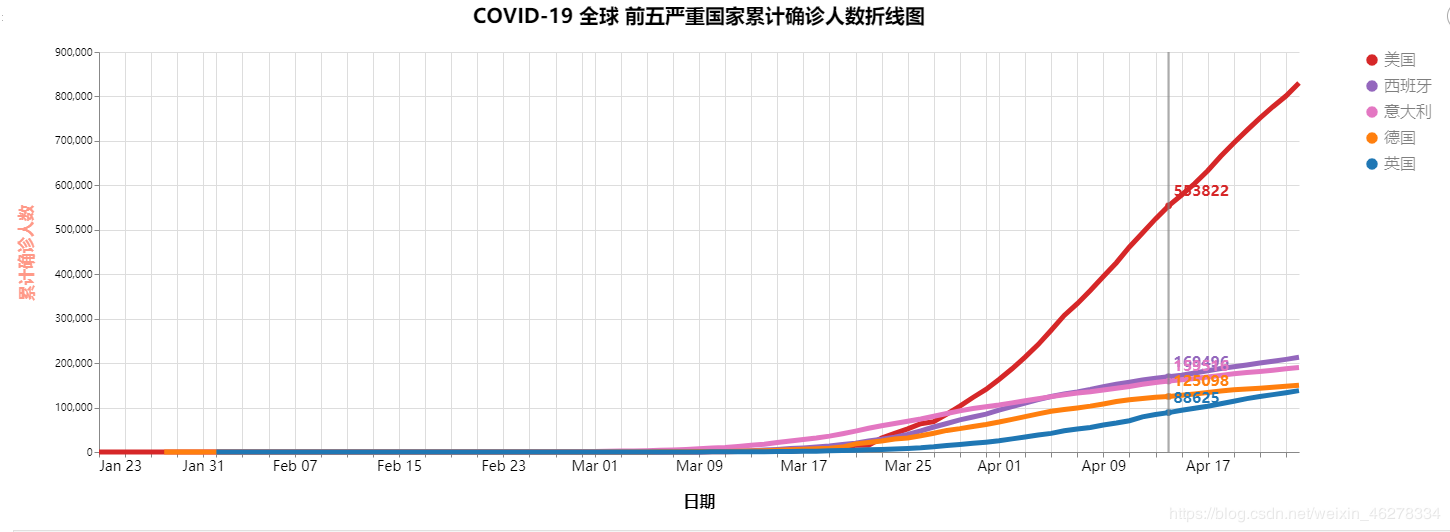
COVID-19 全球 前五严重国家累计确诊人数折线图
我们已经有了前十严重国家的名单,所以我们可以提取出前五严重的国家,所以我们只需要拿前五的国家名单去构建我们需要的这五个国家的每日历史数据的DataFrame就行了,就此不再赘述。
最终结果如下图所示:
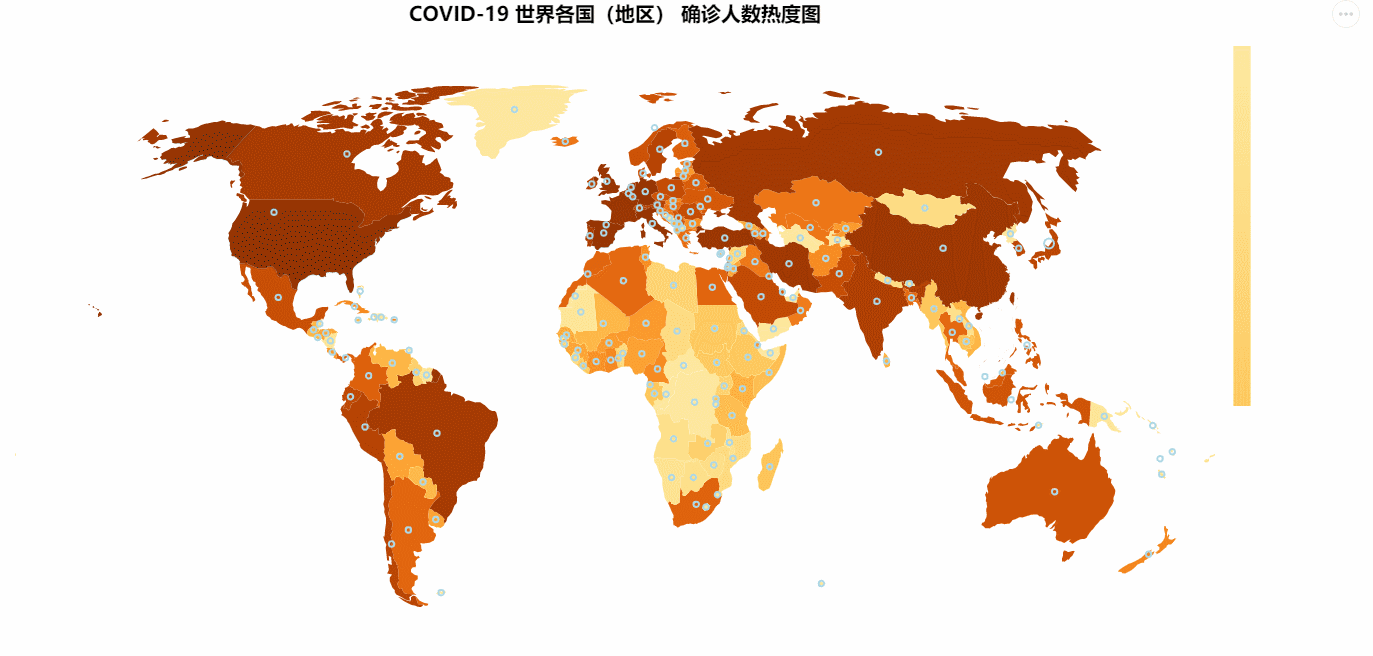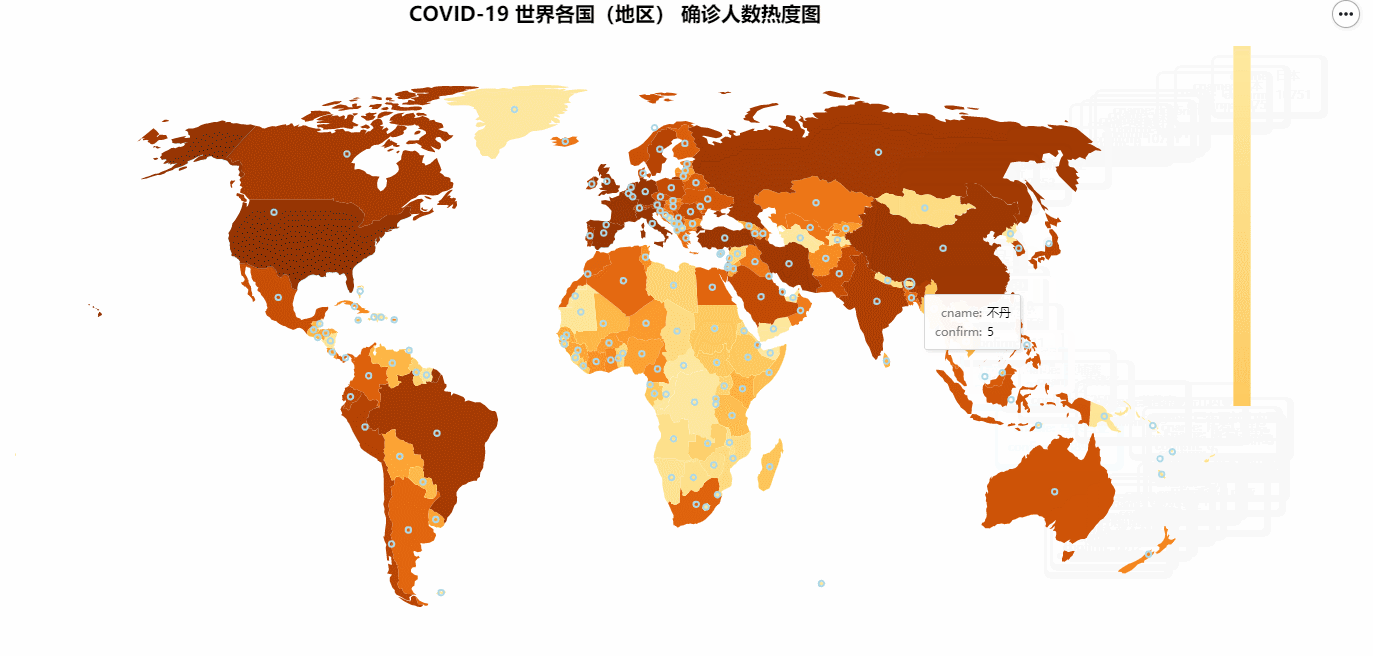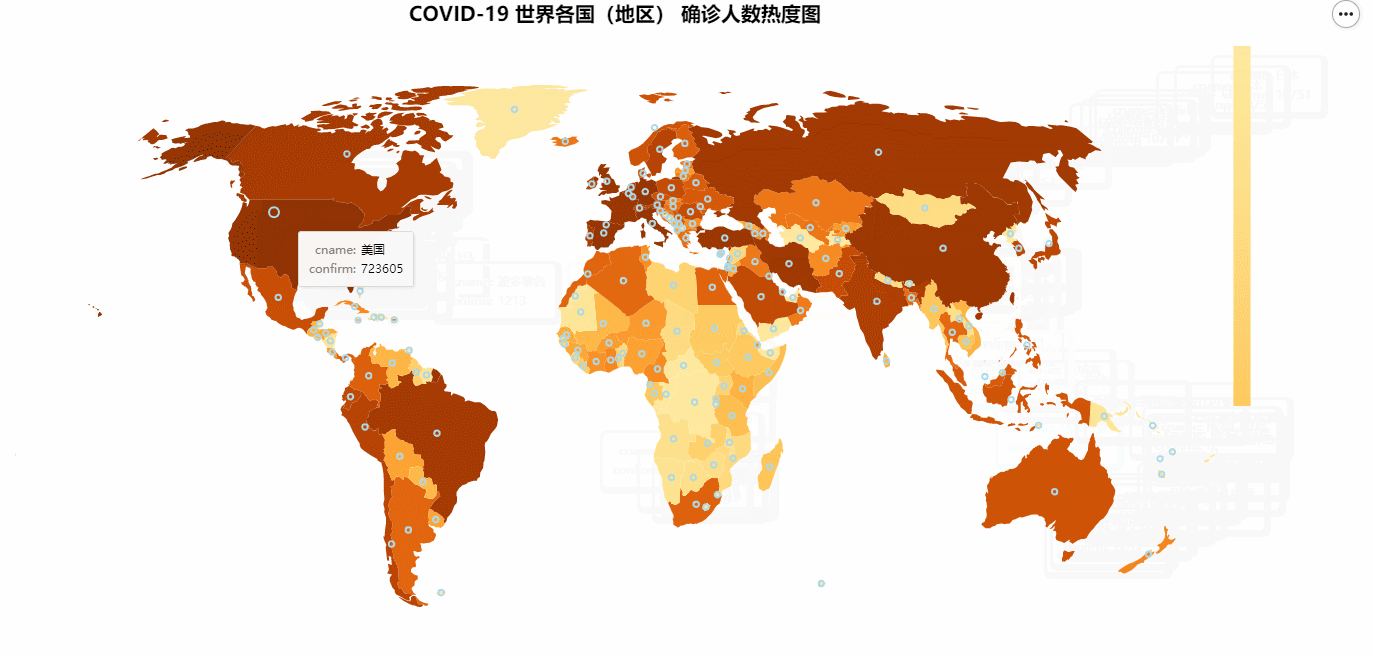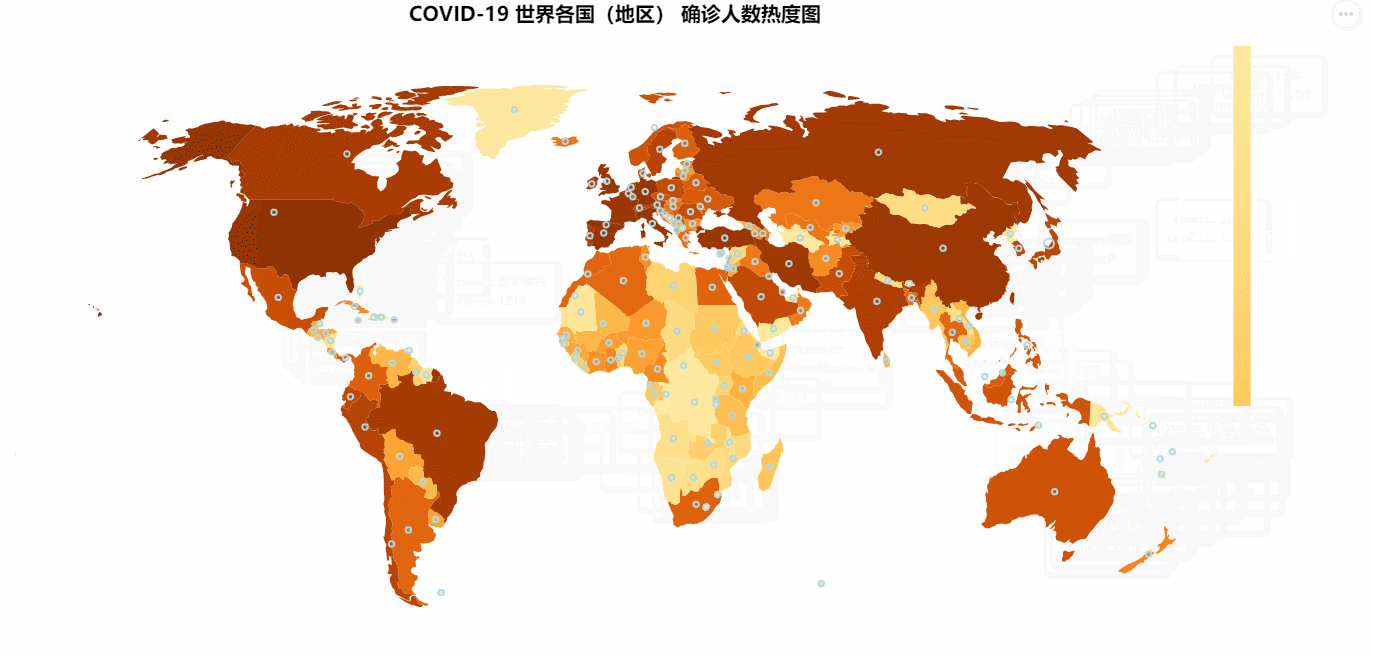
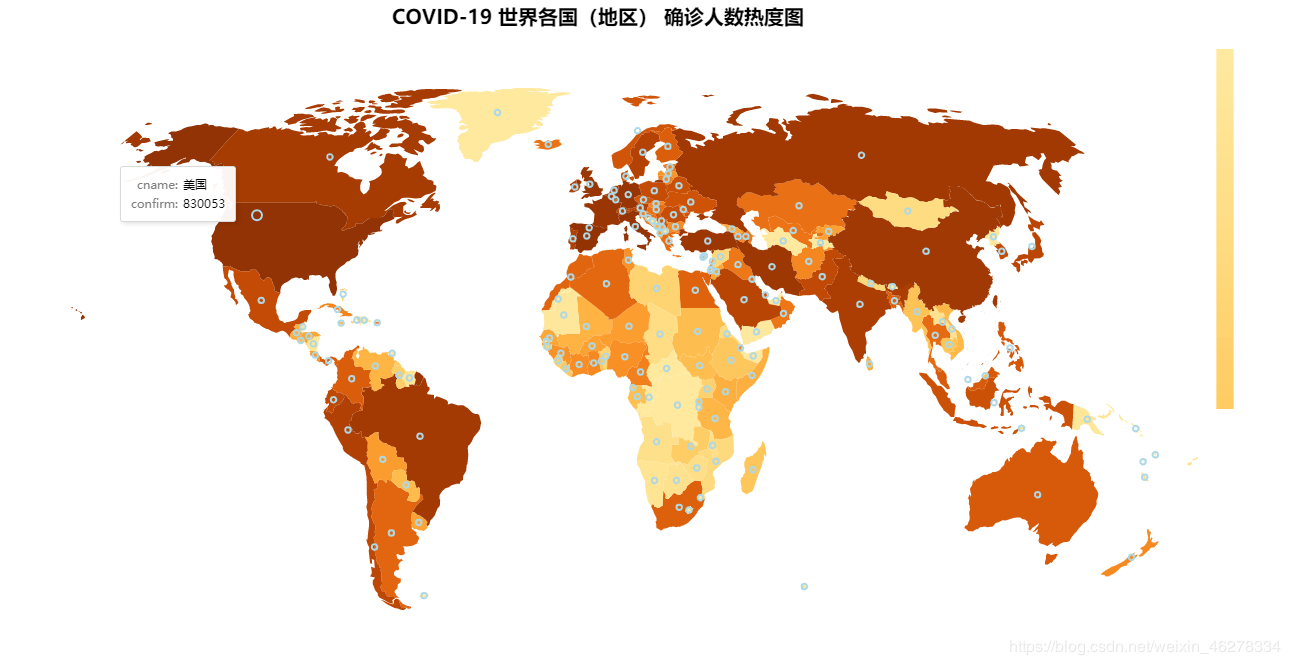
COVID-19 世界各国(地区) 确诊人数热度图
COVID-19 世界各国(地区) 确诊人数热度图所使用的数据在:修复后的世界地图.csv 中,这份地图是我提取修复过的。我们只需要用一个DataFrame读取里面的数据,然后添加确诊人数列到里面就可以了。
绘制地图其实有很多流程,还有技术方面可以讲,还有绘图的图层思想,但是由于太繁琐,所以此时不讲,如果比较多人有兴趣,有时间会考虑写详细点,毕竟现在已经写得很长了
color = alt.Color('confirm:N',legend=alt.Legend(title=None,titlePadding=20,rowPadding=-1,symbolStrokeWidth=0,symbolType='square',symbolSize=300,
labelPadding=20,labelOpacity=0,clipHeight=12,
titleFontSize=14,titleOpacity=0.5),scale=alt.Scale(scheme='yelloworangebrown'))
shape = alt.Chart().mark_geoshape(fill='lightblue')
geo = alt.Chart(world_gdf).mark_geoshape().encode(
color = color
).project(
'naturalEarth1'
).properties(
width=1200,height=600,
title= {
"text": "COVID-19 世界各国(地区) 确诊人数热度图",
"fontSize": 20,
'offset':20
}
)
hover = alt.selection(type='single', on='mouseover', nearest=True,fields=['lat','lon'])
base = alt.Chart(world_gdf).encode(
longitude='lon:Q',
latitude='lat:Q',
)
point = base.mark_point().encode(
color=alt.value('lightblue'),
size=alt.condition(~hover, alt.value(30), alt.value(100)),
tooltip=['cname', 'confirm'],
opacity=alt.value(1)
).add_selection(hover)
layer = alt.layer(
shape,geo,point
)
layer.configure_view(stroke=None)
最终结果如下图所示:
总结
后续还可以开展数据建模,疫情预测分析等。本人目前也没整理,所以没写,其实这个小小的项目可以做的有很多,例如过程中我就用到了爬虫,还有数据清洗,数据可视化,函数拟合,数据建模,在绘制世界地图时还自己处理修复了地图。希望以后有机会再分享。这次是我第一次写博客,尽量写得通俗易懂,但是肯定存在不完善的地方,不能尽善尽美,只希望可以帮助到有需要的人,如果有人跟着教程一步步做有问题,欢迎联系让我修改。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号