Hadoop 3.3.1 折腾记录
1. 配置网络
① 修改虚拟机网络适配器设置:
为了能够在不同网络下使用同一个静态IP地址,我们使用自定义的NAT模式:
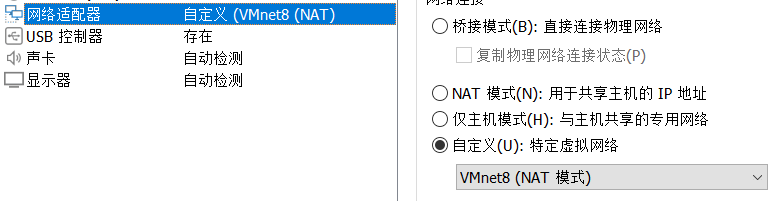
打开VMware Workstation的虚拟网络编辑器(在菜单编辑里):
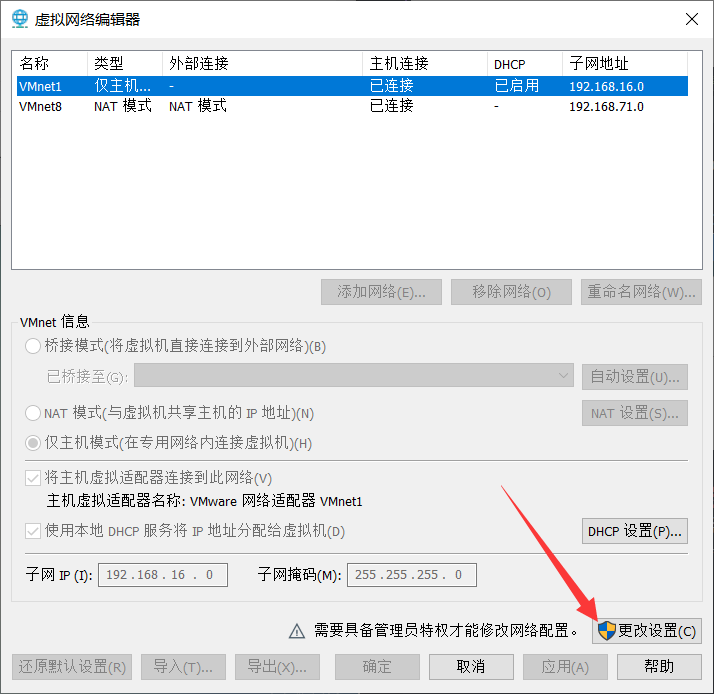
选中VMnet8,点击NAT设置,记住你的网关:
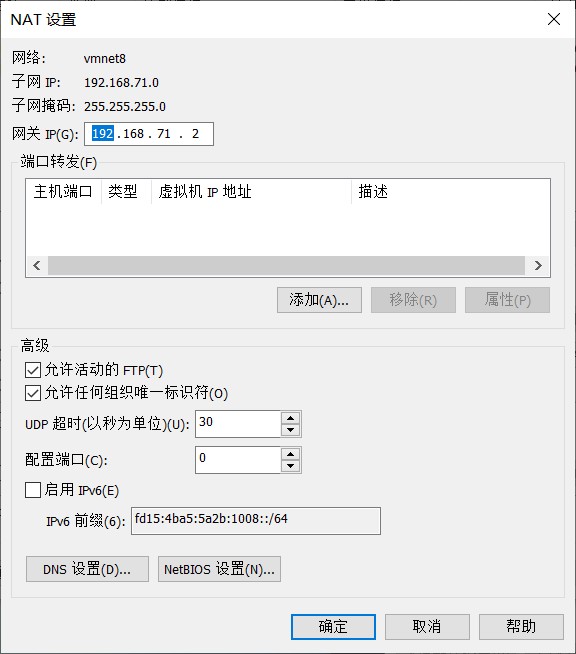
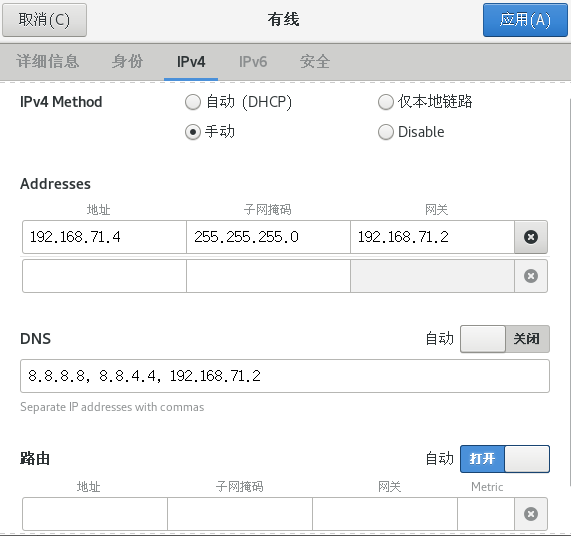
和CloudStack不同,配置Hadoop并不需要禁用NetworkManager服务,所以可以直接在有线设置里面修改:
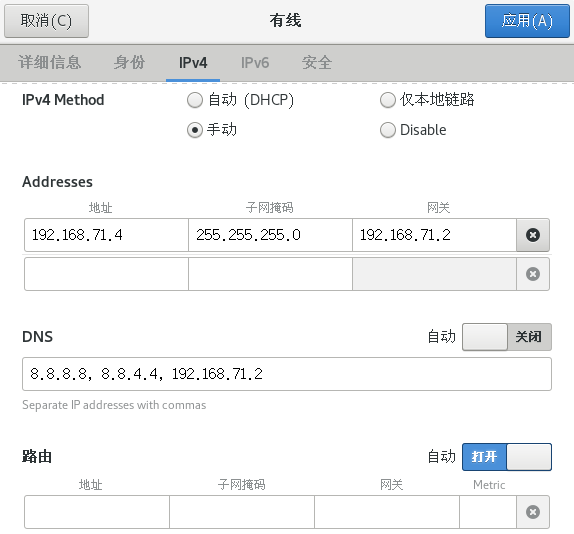
这里我仅以自己的地址为例,具体的请根据自己的网关修改:
IPv4选手动,地址填192.168.71.3-192.168.71.127都行;
DNS就填前面两个就行了;
IPv6直接禁用;
然后应用,打开网络。
注意:如果原先就是开着的,需要先关闭再打开。
2. 卸载OpenJDK并安装Oracle JDK
安装好CentOS之后,我们需要把系统自带的OpenJDK卸载,然后安装功能更加完整的JDK。
有关OpenJDK和JDK的区别请参考这篇文章。
步骤如下:
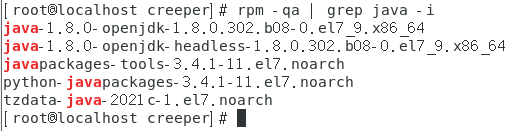
① 查询已安装的OpenJDK:
rpm -qa | grep java -i
② 卸载查询到的软件包:
用法:
rpm -e --nodeps [查询到的包]
示例:
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.302.b08-0.el7_9.x86_64 \
java-1.8.0-openjdk-headless-1.8.0.302.b08-0.el7_9.x86_64 \
javapackages-tools-3.4.1-11.el7.noarch \
python-javapackages-3.4.1-11.el7.noarch \
tzdata-java-2021c-1.el7.noarch
注意:需要在root权限下才能卸载,否则会提示权限不足!
进入root权限可使用:
su
然后输入密码(密码不回显,是看不见输入的是什么的)
③ 从Oracle官网下载JDK:
嫌麻烦的也可以从我的分享下载天翼云盘
④ 解压下载好的JDK:
示例:
打开主文件夹(桌面上那个文件夹),把软件包直接拖进去,然后在主文件夹中打开终端,并获取root权限;
注意:直接拖进来可能会因为VMware Tools的bug发生错误,解决方法是直接在CentOS里面下载,或者通过U盘传入!
创建一个目录用来存放软件包解压后的内容:
mkdir /usr/local/src/jdk
把软件包复制到这个目录:
cp jdk-8u311-linux-x64.tar.gz /usr/local/src/jdk/
(可选)把主文件夹中的软件包删除:
rm -f jdk-8u311-linux-x64.tar.gz
定位到目录/usr/local/src/jdk:
cd /usr/local/src/jdk
解压刚才复制过来的软件包:
tar -zxvf jdk-8u311-linux-x64.tar.gz
(可选)把当前文件夹中的软件包删除:
rm -f jdk-8u311-linux-x64.tar.gz
⑤ 添加环境变量:
打开全局环境变量配置文件:
vim /etc/profile
注意:vim是vi的高级版本,能用不同颜色高亮关键字。
移动到文件末尾,按小写字母i进入插入模式,添加下面的内容:
export JAVA_HOME=/usr/local/src/jdk/jdk1.8.0_311
export PATH=$PATH:$JAVA_HOME/bin
按Esc键,再按冒号:,输入小写字母wq,回车,即可保存退出。
顺边一说,不保存退出是:q!。
使环境变量配置立即生效:
source /etc/profile
查看JDK版本:
java -version
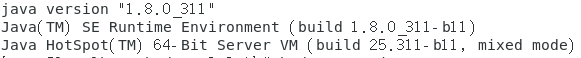
3. 配置Hadoop
3.1. 准备工作
访问官网:https://hadoop.apache.org/releases.html

在下载好的软件包所在目录中打开终端,获取root权限,创建目录:
mkdir /usr/local/src/hadoop
把软件包复制到这个目录:
cp hadoop-3.3.1.tar.gz /usr/local/src/hadoop/
(可选)把软件包删除:
rm -f hadoop-3.3.1.tar.gz
定位到新创建的目录:
cd /usr/local/src/hadoop
解压软件包:
tar -zxvf hadoop-3.3.1.tar.gz
(可选)把软件包删除:
rm -f hadoop-3.3.1.tar.gz
定位到解压出来的目录:
cd /usr/local/src/hadoop/hadoop-3.3.1
创建一些后面要用到的目录:
mkdir -p hdfs/data
mkdir hdfs/name
mkdir tmp
修改环境变量配置文件:
vim /etc/profile
移动到文件末尾,按小写字母i进入插入模式,添加或修改下面的内容:
export HADOOP_HOME=/usr/local/src/hadoop/hadoop-3.3.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
注意:PATH是修改之前配置JDK的那个,仅较之前添加了:$HADOOP_HOME/bin!
修改完大概是这样的:

使环境变量配置立即生效:
source /etc/profile
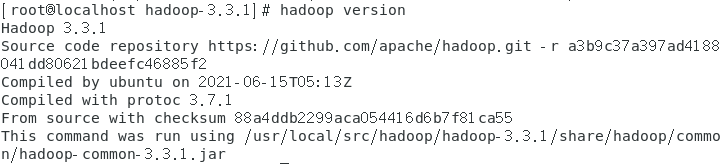
查看Hadoop版本:
hadoop version
3.2. 修改配置文件
定位到Hadoop软件包配置文件目录(root别忘记):
cd /usr/local/src/hadoop/hadoop-3.3.1/etc/hadoop
① 修改hadoop-env.sh文件:
vim hadoop-env.sh
找到下面的内容:

把export JAVA_HOME=取消注释,改为:
export JAVA_HOME=/usr/local/src/jdk/jdk1.8.0_311
② 修改core-site.xml文件:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop/hadoop-3.3.1/tmp</value>
</property>
</configuration>
③ 修改hdfs-site.xml文件:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/src/hadoop/hadoop-3.3.1/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/src/hadoop/hadoop-3.3.1/hdfs/data</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:9870</value>
</property>
</configuration>
注意:如果是老版本Hadoop,端口不是9870是50070!
④ 修改mapred-site.xml文件:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
⑤ 修改yarn-site.xml文件:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
⑥ 定位到Hadoop的sbin目录下:
cd /usr/local/src/hadoop/hadoop-3.3.1/sbin
⑦ 修改start-dfs.sh和stop-dfs.sh文件,在文件顶部添加如下内容:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
⑧ 修改start-yarn.sh和stop-yarn.sh文件,在文件顶部添加如下内容:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
3.3. 设置无密码ssh
在任意目录root权限下执行下面的命令即可:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
注意:某些教程里直接跳过了这一步,导致下面启动Hadoop的时候报错(类似Permission Denied这类错误)。
3.4. 初始化HDFS文件系统
定位到Hadoop的bin目录下:
cd /usr/local/src/hadoop/hadoop-3.3.1/bin
初始化文件系统:
hdfs namenode -format
3.5. 启动Hadoop
定位到Hadoop的sbin目录下:
cd /usr/local/src/hadoop/hadoop-3.3.1/sbin
开启NameNode和DataNode守护进程:
./start-dfs.sh
好,现在就可以通过浏览器访问下面的地址访问NameNode的网页界面了:
http://localhost:9870/
注意:老版本的Hadoop应该访问http://localhost:50070/
我们来创建几个目录用于后续执行MapReduce jobs:
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/<username>
注意:这里的<username>填你的用户名
开启ResourceManager和NodeManager守护进程:
./start-yarn.sh
好,现在就可以通过浏览器访问下面的地址访问ResourceManager的网页界面了:
http://localhost:8088/
4. 测试Hadoop性能
4.1. 查看可用测试工具
定位到MapReduce目录:
cd $HADOOP_HOME/share/hadoop/mapreduce
注意:如果出现错误,多半是环境变量没有应用,执行一下source /etc/profile就能解决。
不带参数执行jar包即可查看可用测试工具:
hadoop jar hadoop-mapreduce-client-jobclient-3.3.1-tests.jar
DFSCIOTest: Distributed i/o benchmark of libhdfs.
MRReliabilityTest: A program that tests the reliability of the MR framework by injecting faults/failures
TestDFSIO: Distributed i/o benchmark.
fail: a job that always fails
gsleep: A sleep job whose mappers create 1MB buffer for every record.
loadgen: Generic map/reduce load generator
mapredtest: A map/reduce test check.
mrbench: A map/reduce benchmark that can create many small jobs
nnbench: A benchmark that stresses the namenode w/ MR.
nnbenchWithoutMR: A benchmark that stresses the namenode w/o MR.
sleep: A job that sleeps at each map and reduce task.
testbigmapoutput: A map/reduce program that works on a very big non-splittable file and does identity map/reduce
testfilesystem: A test for FileSystem read/write.
testmapredsort: A map/reduce program that validates the map-reduce framework's sort.
testsequencefile: A test for flat files of binary key value pairs.
testsequencefileinputformat: A test for sequence file input format.
testtextinputformat: A test for text input format.
threadedmapbench: A map/reduce benchmark that compares the performance of maps with multiple spills over maps with 1 spill
timelineperformance: A job that launches mappers to test timeline service performance.
翻译版:
DFSCIOTest: libhdfs 的分布式 i/o 基准测试。
MRReliabilityTest: 一个通过注入错误/故障来测试 MR 框架可靠性的程序。
TestDFSIO: 分布式 i/o 基准测试。
fail: 一次总是失败的作业。
gsleep: 一次 sleep 作业,它的 mapper 为每条记录创建 1MB 的缓冲区。
loadgen: 通用 map/reduce 负载生成器。
mapredtest: map/reduce 测试检查。
mrbench: 一个可以创造大量小作业的 map/reduce 基准测试。
nnbench: 对 namenode w/ MR 的基准压力测试。
nnbenchWithoutMR: 对 namenode w/o MR 的基准压力测试。
sleep: 一次在每个 map 和 reduce 任务上 sleep 的作业。
testbigmapoutput: 一个在非常大的不可分割文件上作业的 map/reduce 程序,并执行一致性 map/reduce。
testfilesystem: 文件系统 read/write 测试。
testmapredsort: 一个验证 map-reduce 框架排序的 map/reduce 程序。
testsequencefile: 一个对二进制键值对的平面文件的测试。
testsequencefileinputformat: 一个对序列文件输入格式的测试。
testtextputformat: 一个对文本输入格式的测试。
threadmapbench: 一个 map/reduce 基准测试,用于比较具有多个 spill 的 map 对具有单个 spill 的 map 的性能。
timelineperformance: 一次启动 mapper 以测试 timeline 服务性能的作业。
先介绍一下查看文件系统的简单方法:

4.2. TestDFSIO:测试HDFS读写性能
向HDFS集群写10个10MB的文件:
hadoop jar ./hadoop-mapreduce-client-jobclient-3.3.1-tests.jar \
TestDFSIO \
-write \
-nrFiles 10 \
-size 10MB
注意:有可能遇到错误: 找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster这样的报错,解决方法参照这里。
读取刚才写入的10个文件:
hadoop jar ./hadoop-mapreduce-client-jobclient-3.3.1-tests.jar \
TestDFSIO \
-write \
-nrFiles 10 \
-size 10MB
查看测试结果:
cat TestDFSIO_results.log

删除测试临时文件:
hadoop jar ./hadoop-mapreduce-client-jobclient-3.3.1-tests.jar \
TestDFSIO \
-clean
4.3. mrbench:测试重复执行小作业效率
测试使用3个mapper和3个reducer运行一个小作业20次,生成输入行数为5,降序排列:
hadoop jar hadoop-mapreduce-client-jobclient-3.3.1-tests.jar \
mrbench \
-numRuns 20 \
-maps 3 \
-reduces 3 \
-inputLines 5 \
-inputType descending
注意:运行直接比较长,可适当减少运行次数。
4.4. nnbench:测试NameNode负载
测试使用3个mapper和3个reducer来创建100个文件:
hadoop jar hadoop-mapreduce-client-jobclient-3.3.1-tests.jar \
nnbench \
-operation create_write \
-maps 3 \
-reduces 3 \
-numberOfFiles 100 \
-replicationFactorPerFile 3 \
-readFileAfterOpen true
查看结果:
cat NNBench_results.log

5. 编写Hadoop实例
5.1. 安装eclipse
浏览器访问:https://www.eclipse.org/downloads/packages/
点这个地方下载:

有时候它选择的镜像可能不是很快,所以可以点这边选其他镜像:
比如这个就不错,直接怼它:
注意:点击之后可能会需要较长时间才弹出保存文件对话框,耐心等待即可。
下载完成后,来到下载文件夹,在空白处右键并选择在终端打开:
执行su进入root账户,然后复制下载好的软件包到其他地方:
cp eclipse-jee-2021-09-R-linux-gtk-x86_64.tar.gz /usr/local/src/
(可选)删除当前目录下的软件包:
rm -f eclipse-jee-2021-09-R-linux-gtk-x86_64.tar.gz
转到/usr/local/src/:
cd /usr/local/src/
解压软件包:
tar -zxvf eclipse-jee-2021-09-R-linux-gtk-x86_64.tar.gz
(可选)删除当前目录下的软件包:
rm -f eclipse-jee-2021-09-R-linux-gtk-x86_64.tar.gz
转到eclipse软件目录:
cd /usr/local/src/eclipse/
运行eclipse:
./eclipse
注意:这个终端不要关,关了的话eclipse也会关。
然后会提示选择工作目录(建议记一下这个默认路径),直接Launch:
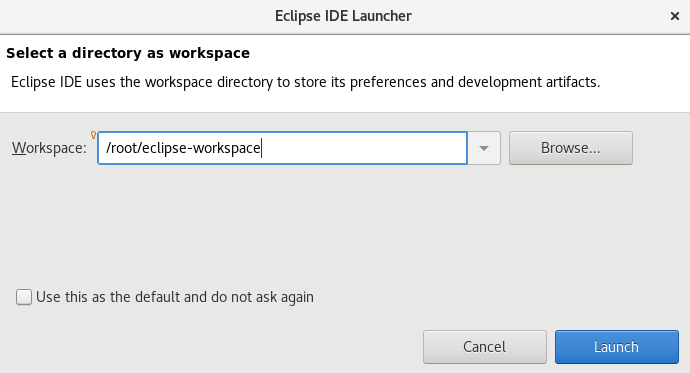
这样,就进入了eclipse。
5.2. 编写实例
创建Java Project:
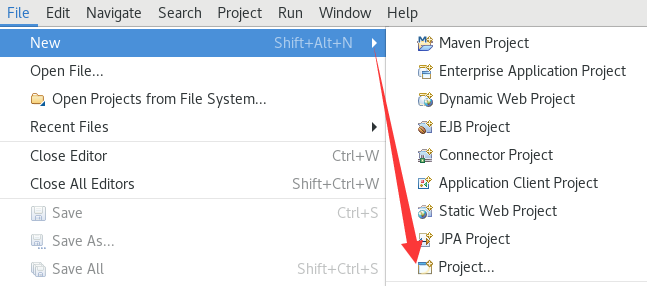
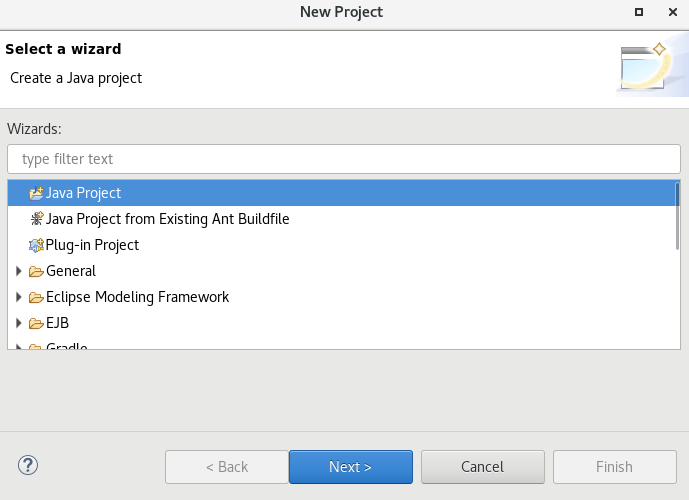
项目名随便填就行,JRE版本不太确定,试了试JavaSE-1.8是可以的:
项目建完没弹出来?把Welcome页关掉就行。
接下来要导入一些包:
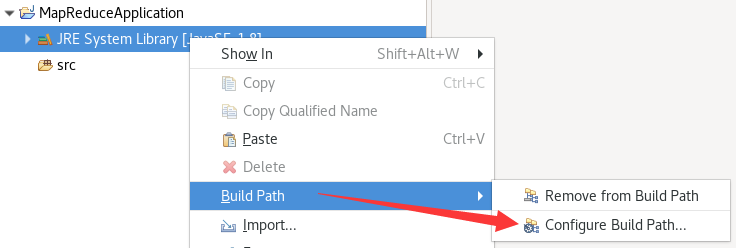
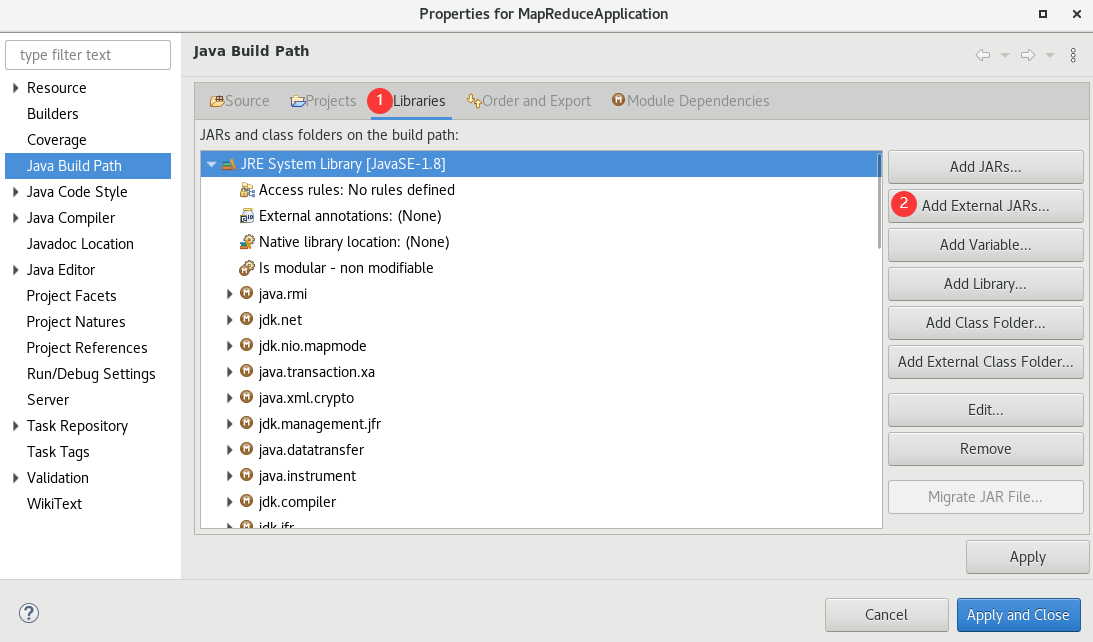
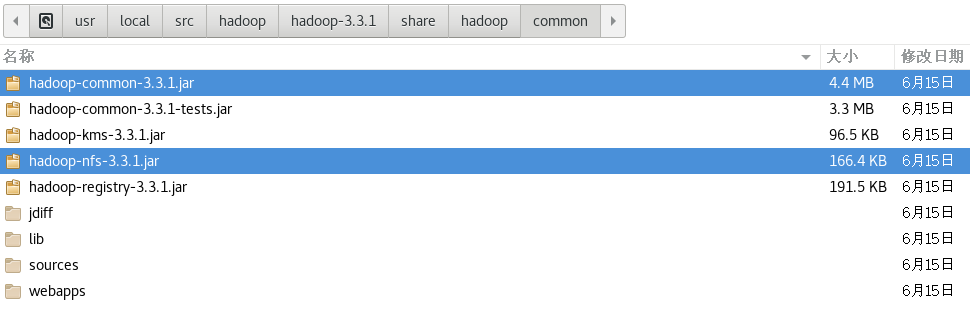
把$HADOOP_HOME/share/hadoop/common/目录下的2个jar包导入:
把$HADOOP_HOME/share/hadoop/common/lib/目录下的所有jar包导入:
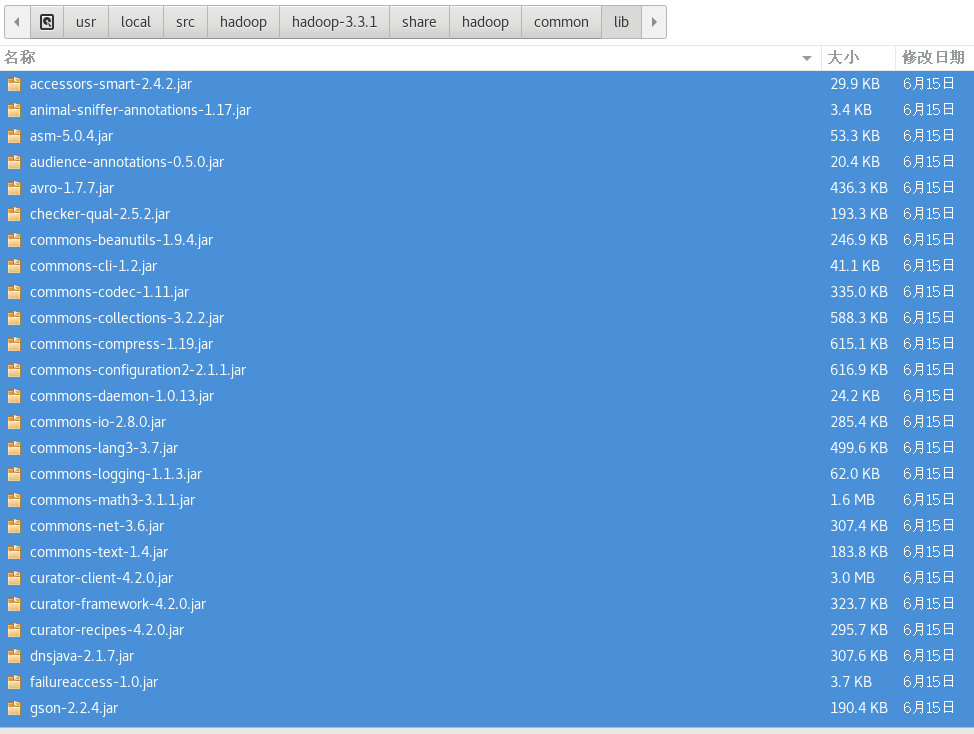
注意:选中一个包,按Ctrl+A即可全选。
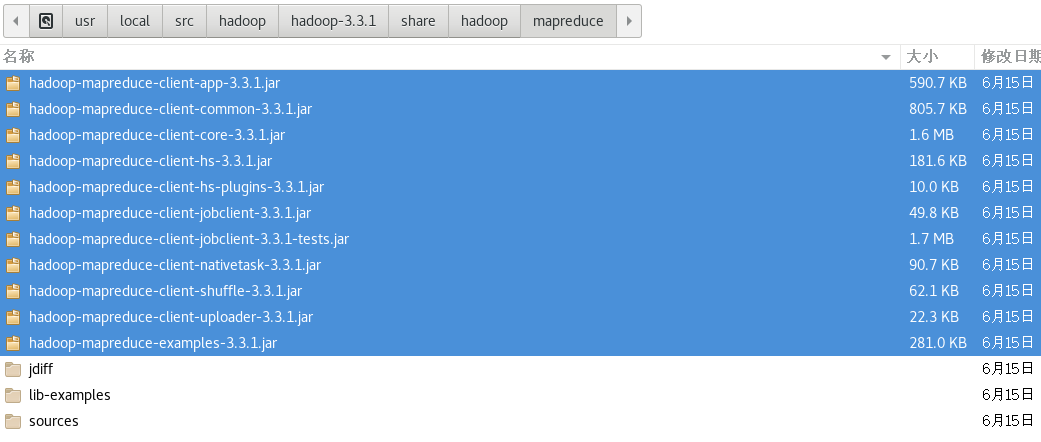
把$HADOOP_HOME/share/hadoop/mapreduce/目录下的所有jar包导入:
5.2.1. 数据去重
创建一个类:
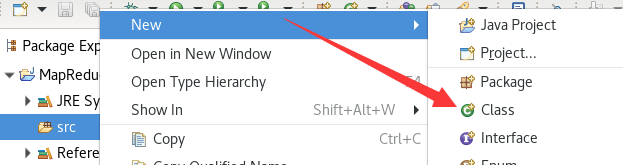
Package:dataUtil
Name:DataDedup
Modifiers:package(其实这项不用改,反正后面复制粘贴)
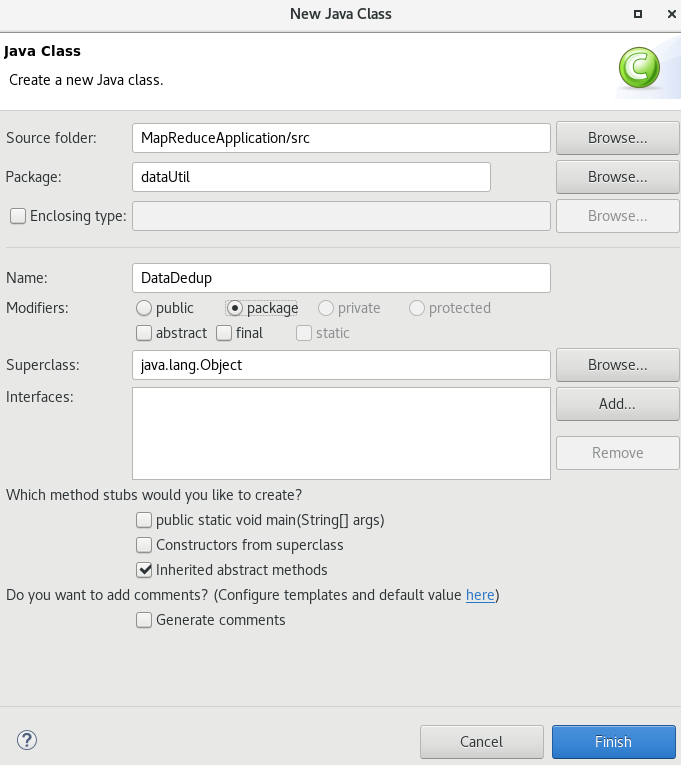
替换为下面的内容:
package dataUtil;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class DataDedup {
public static class Map extends Mapper<Object,Text,Text,Text>{
private static Text line=new Text();
public void map(Object key,Text value,Context context) throws IOException,InterruptedException{
line=value;
context.write(line, new Text(""));
}
}
public static class Reduce extends Reducer<Text,Text,Text,Text>{
public void reduce(Text key,Iterable<Text> values,Context context) throws IOException,InterruptedException{
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
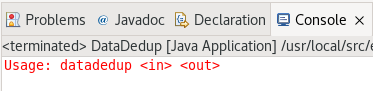
System.err.println("Usage: datadedup <in> <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "data dedup");
job.setJarByClass(DataDedup.class);
job.setNumReduceTasks(1);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
编译运行:

这里直接OK就行:
下面出现这个就对了:
导出可执行jar包:
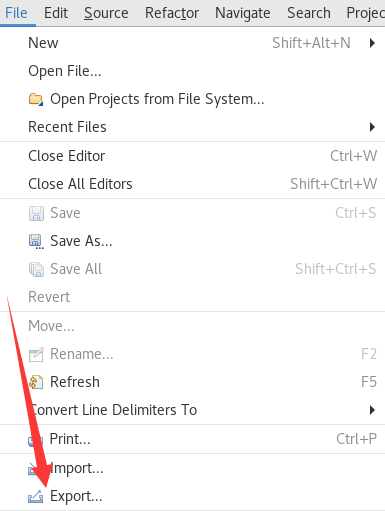
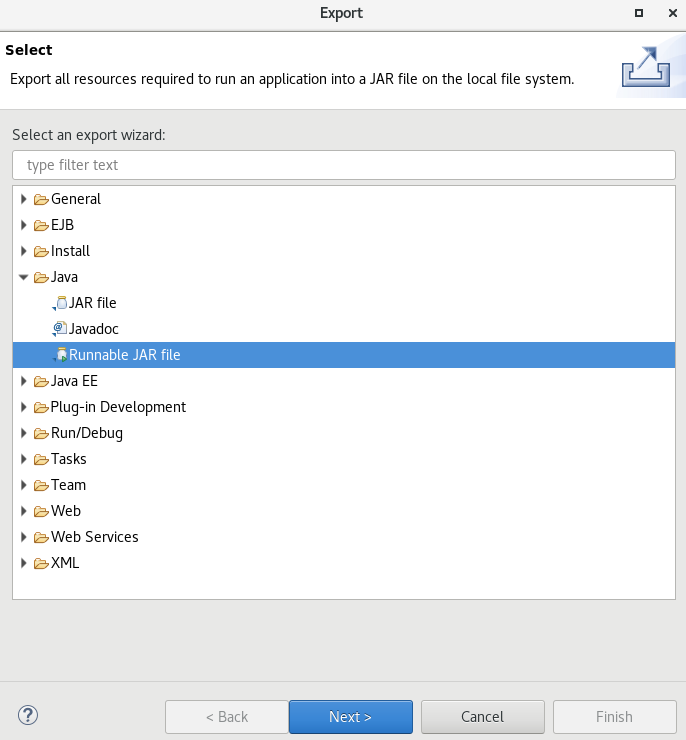
选中创建的类,选择导出路径:
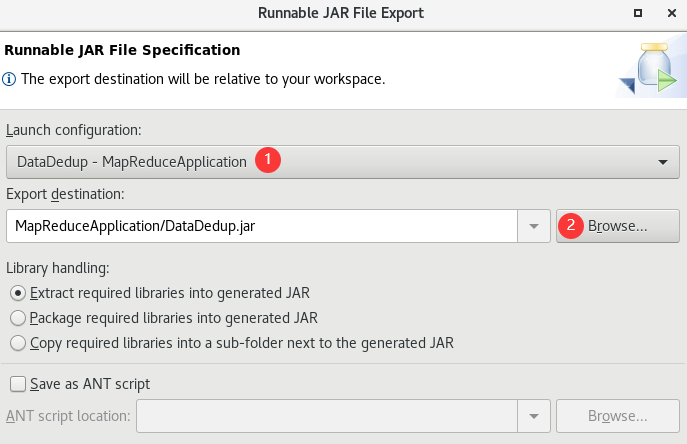
建议放在项目目录中:

然后直接点Finish就行了。(出现warning直接点ok)
5.3. 运行实例
打开终端,运行hadoop:
$HADOOP_HOME/sbin/start-all.sh
创建2个文本文档用于测试:
vim file1.txt
2021-10-11 a
2021-10-12 b
2021-10-13 c
2021-10-14 d
2021-10-15 a
2021-10-16 b
2021-10-17 c
2021-10-13 c
vim file2.txt
2021-10-11 b
2021-10-12 a
2021-10-13 b
2021-10-14 d
2021-10-15 a
2021-10-16 c
2021-10-17 d
2021-10-13 c
在hdfs上创建一个文件夹(<username>填你自己的账户):
hdfs dfs -mkdir /user/<username>/test1
注意:/user/<username>在之前配置hadoop时已经由我们创建,没创建的需要现在创建一下。
上传刚才创建的2个文本文档:
hdfs dfs -put file1.txt /user/<username>/test1
hdfs dfs -put file2.txt /user/<username>/test1
运行:
hadoop jar /root/eclipse-workspace/MapReduceApplication/DataDedup.jar /user/<username>/test1 /user/<username>/output1
查看运行结果:
hdfs dfs -cat /user/<username>/output1/*


 浙公网安备 33010602011771号
浙公网安备 33010602011771号