
多线程
https://www.runoob.com/note/34745
https://www.cnblogs.com/sinoaccer/p/12116469.html
一 多线程运行的五种状态:
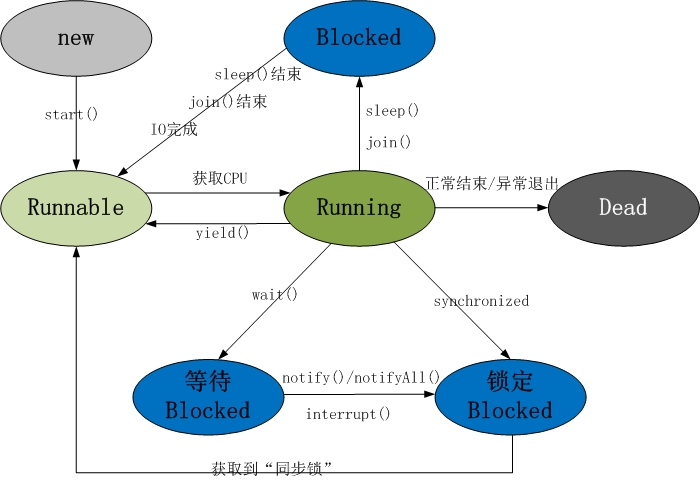
线程共包括以下 5 种状态:
1. 新建状态(New): 线程对象被创建后,就进入了新建状态。例如,Thread thread = new Thread()。
2. 就绪状态(Runnable): 也被称为“可执行状态”。线程对象被创建后,其它线程调用了该对象的start()方法,从而来启动该线程。例如,thread.start()。处于就绪状态的线程,随时可能被CPU调度执行。
3. 运行状态(Running): 线程获取CPU权限进行执行。需要注意的是,线程只能从就绪状态进入到运行状态。
4. 阻塞状态(Blocked): 阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。阻塞的情况分三种:
- (01) 等待阻塞 -- 通过调用线程的wait()方法,让线程等待某工作的完成。
- (02) 同步阻塞 -- 线程在获取synchronized同步锁失败(因为锁被其它线程所占用),它会进入同步阻塞状态。
- (03) 其他阻塞 -- 通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
5. 死亡状态(Dead): 线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
二 进程和线程
进程:是代码在数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位。
线程:是进程的一个执行路径,一个进程中至少有一个线程,进程中的多个线程共享进程的资源。
虽然系统是把资源分给进程,但是CPU很特殊,是被分配到线程的,所以线程是CPU分配的基本单位。
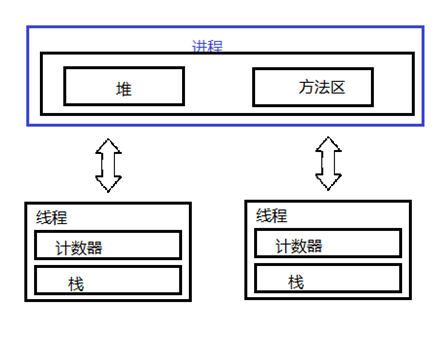
一个进程中有多个线程,多个线程共享进程的堆和方法区资源,但是每个线程有自己的程序计数器和栈区域。
程序计数器:是一块内存区域,用来记录线程当前要执行的指令地址 。
栈:用于存储该线程的局部变量,这些局部变量是该线程私有的,除此之外还用来存放线程的调用栈祯。
堆:是一个进程中最大的一块内存,堆是被进程中的所有线程共享的。
方法区:则用来存放 NM 加载的类、常量及静态变量等信息,也是线程共享的 。
二者区别:
进程:有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响。
线程:是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉就等于整个进程死掉。
二、并发与并行
并发:是指同一个时间段内多个任务同时都在执行,并且都没有执行结束。并发任务强调在一个时间段内同时执行,并发的多个任务在单位时间内不一定同时在执行 。
并行:是说在单位时间内多个任务同时在执行 。
在多线程编程实践中,线程的个数往往多于CPU的个数,所以一般都称多线程并发编程而不是多线程并行编程。
并发过程中常见的问题:
1、线程安全问题:

多个线程同时操作共享变量1时,会出现线程1更新共享变量1的值,但是其他线程获取到的是共享变量没有被更新之前的值。就会导致数据不准确问题。
2、共享内存不可见性问题

Java内存模型(处理共享变量)
Java 内存模型规定,将所有的变量都存放在主内存中,当线程使用变量时,会把主内存里面的变量复制到自己的工作空间或者叫作工作内存,线程读写变量时操作的是自己工作内存中的变量 。(如上图所示)
(实际工作的java内存模型)
上图中所示是一个双核 CPU 系统架构,每个核有自己的控制器和运算器,其中控制器包含一组寄存器和操作控制器,运算器执行算术逻辅运算。CPU的每个核都有自己的一级缓存,在有些架构里面还有一个所有CPU都共享的二级缓存。 那么Java内存模型里面的工作内存,就对应这里的 Ll或者 L2 缓存或者 CPU 的寄存器
1、线程A首先获取共享变量X的值,由于两级Cache都没有命中,所以加载主内存中X的值,假如为0。然后把X=0的值缓存到两级缓存,线程A修改X的值为1,然后将其写入两级Cache,并且刷新到主内存。线程A操作完毕后,线程A所在的CPU的两级Cache内和主内存里面的X的值都是l。
2、线程B获取X的值,首先一级缓存没有命中,然后看二级缓存,二级缓存命中了,所以返回X=1;到这里一切都是正常的,因为这时候主内存中也是X=l。然后线程B修改X的值为2,并将其存放到线程2所在的一级Cache和共享二级Cache中,最后更新主内存中X的值为2,到这里一切都是好的。
3、线程A这次又需要修改X的值,获取时一级缓存命中,并且X=l这里问题就出现了,明明线程B已经把X的值修改为2,为何线程A获取的还是l呢?这就是共享变量的内存不可见问题,也就是线程B写入的值对线程A不可见。
synchronized 的内存语义:
这个内存语义就可以解决共享变量内存可见性问题。进入synchronized块的内存语义是把在synchronized块内使用到的变量从线程的工作内存中清除,这样在synchronized块内使用到该变量时就不会从线程的工作内存中获取,而是直接从主内存中获取。退出synchronized块的内存语义是把在synchronized块内对共享变量的修改刷新到主内存。会造成上下文切换的开销,独占锁,降低并发性
Volatile的理解:
该关键字可以确保对一个变量的更新对其他线程马上可见。当一个变量被声明为volatile时,线程在写入变量时不会把值缓存在寄存器或者其他地方,而是会把值刷新回主内存。当其他线程读取该共享变量时,会从主内存重新获取最新值,而不是使用当前线程的工作内存中的值。volatile的内存语义和synchronized有相似之处,具体来说就是,当线程写入了volatile变量值时就等价于线程退出synchronized同步块(把写入工作内存的变量值同步到主内存),读取volatile变量值时就相当于进入同步块(先清空本地内存变量值,再从主内存获取最新值)。不能保证原子性
三、创建线程
1、继承Thread类,重写run()方法。
1) 定义Thread类的子类,并重写该类的run()方法,该run()方法的方法体就代表了线程要完成的任务。因此把run()方法称为执行体。
2)创建Thread子类的实例即创建了线程对象。
3)调用线程对象的start()方法启动线程。
2、实现Runnable接口,重写run()方法。
1)定义Runnable接口的实现类,并重写该方法的run()方法,该run()方法同样是该线程的执行体。
2)创建Runnable实现类的实例,并依此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。
3)调用线程对象的start()方法启动线程。
3、通过实现Callable接口和使用FutureTask包装器来实现线程。
1)创建Callable接口的实现类,并实现call()方法,该call()方法的方法体同样是该线程的执行体。
2)创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。
3)使用FutureTask对象作为Thread对象的target创建并启动新线程。
4)调用FutureTask对象的get()方法来获得子线程执行结束后的返回值。
三种实现方式的优缺点对比:
1、实现Runnable和Callable接口方式:
优点:
1)线程类只是实现了Runnable接口(JDK1.0开始)或Callable接口(JDK1.5开始),还可以继承其他类。
2)多线程可以共享同一个target对象,非常适合多个相同线程来处理同一份资源的情况,从而可以将CPU、代码和数据分开,形成清晰的模型,较好地体现了面向对象的思想。
3)实现Callable接口创建多线程最大的好处是可以有返回值。
缺点:
编程稍显复杂,如果要访问当前线程,则必须使用Thread.currentThread()方法。
2、使用继承Thread类方式:
优点:
编写简单,如果要访问当前线程无需使用Thread.currentThread()方法,直接使用this即可获得当前线程。
缺点:
线程类已经继承了Thread类,不能再继承其他类(java的单继承性),因此该方式不够灵活。
补充说明:
1)Callable规定重写call()方法;Runnable重写run()方法。
2)Callable的任务执行结束后可有返回值;Runnable的任务是不能有返回值的。
3)call()方法可以抛出异常;run()方法不可以。
4)运行Callable任务可以拿到一个Future对象,表示异步计算的结果。它提供了检查计算是否完成的方法,以等待计算的完成,并检查计算的结果。通过Future对象可以了解任务执行情况,可取消任务的执行,可以获取执行结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号