以初学者的角度理解:SQL实现关系除法
以初学者的角度理解:SQL实现关系除法
相信各位在学习SQL的时候,由于没有一家SQL语言提供除法命令而只能自己写一个。而网上大多就是四步骤加一个模板:
select distinct A.X
from A A1
where not exists(
select B.Y
from B
where not exists(
select *
from A A2
where A1.X = A2.X
and A2.Y = B.Y
)
)
那四个步骤又写的过于抽象~,看得一头雾水。因此笔者希望从一个初学者的角度,讲解一下关系除法的实现过程,帮助大家理解。
例子
我们举一个实例来讲解~
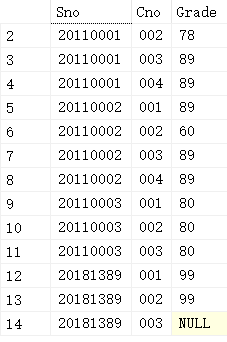
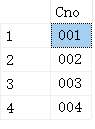
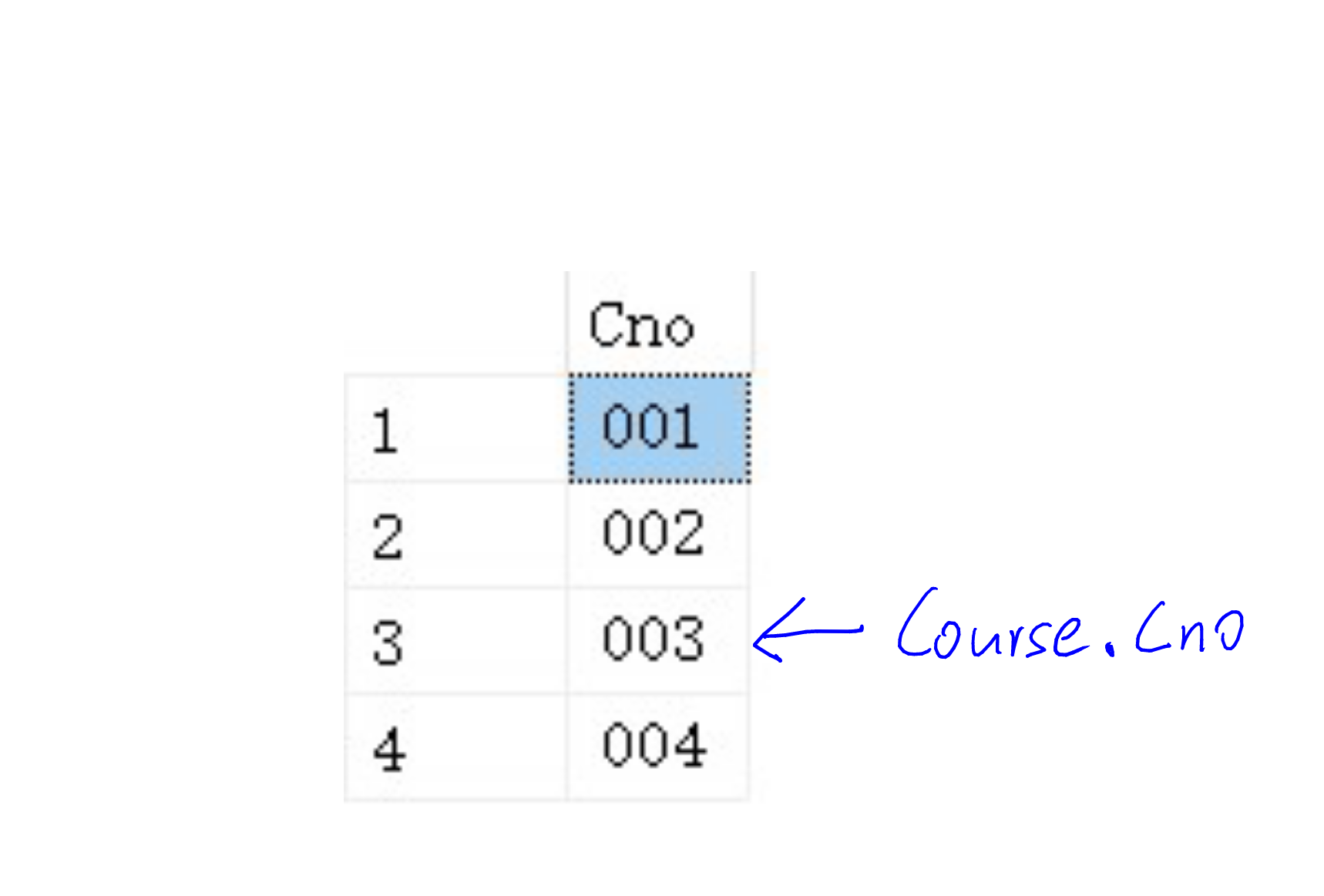
我们用一张SC表和Course表,其中:
SC表:
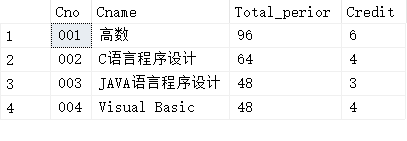
Course表:
而我们想要做的是:
查询选修了全部课程的学生姓名。
很明显我们需要做除法:
select distinct SC1.Sno
from SC SC1
where not exists(
select Course.Cno
from Course
where not exists(
select *
from SC SC2
where SC1.Sno = SC2.Sno
and SC2.Cno = Course.Cno
)
)
接下来讲解这段语句的整个过程~
具体讲解
我们先看看这两句SQL
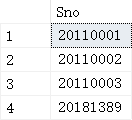
select distinct SC1.Sno
from SC SC1
这一段,产生的结果应该是:
接下来到下一句:
where not exists()
这句话的意思很简单,就是我即将进行括号中写好的查询语句,如果查询结果为空,返回true,否则返回false。
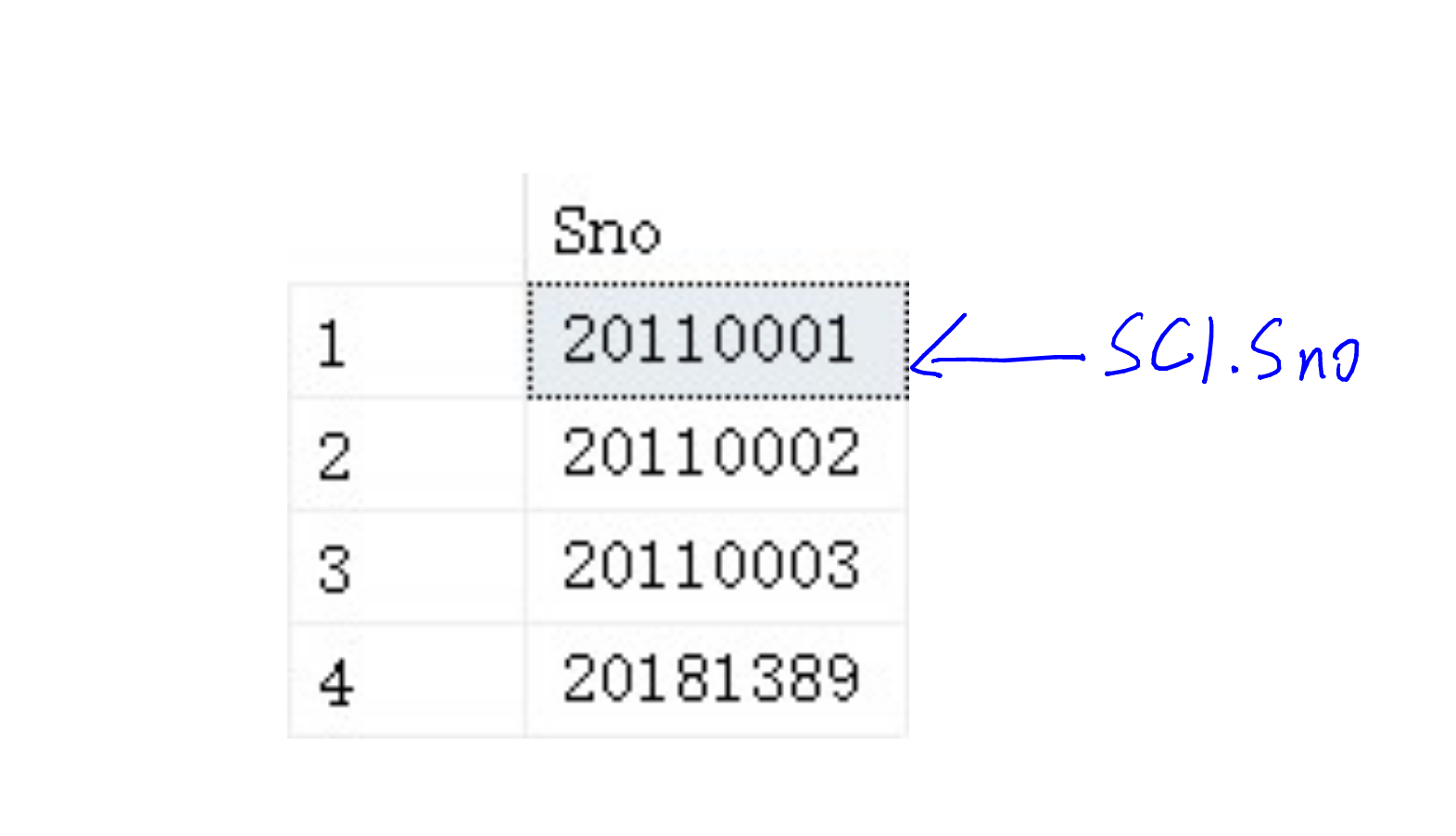
这时候,我们开始where语句,此时SC1.Sno的值会被挨个放进where中进行处理。
此时:
接下来进入not exists的部分。
select Course.Cno
from Course
跟上面一样,先看看它执行出来什么效果:
接下来到下一句:
where not exists()
此时:

接下来进入下一个not exists的部分。
select *
from SC SC2
where SC1.Sno = SC2.Sno
and SC2.Cno = Course.Cno
我们的SC表是这样子的:
我们看看当select完之后,where在干嘛:
where SC1.Sno = SC2.Sno
and SC2.Cno = Course.Cno
这句话的意思是:
当
SC1.Sno与本关系中的Sno相等且Course.Cno与本关系中Cno的值相等
那回头看看,我们进行的步骤,我们发现到这一步的时候,SC1.Sno = 20110001,而Course.Cno = 001。换言之,我们要找到符合这两个条件的元组。
不难找到:
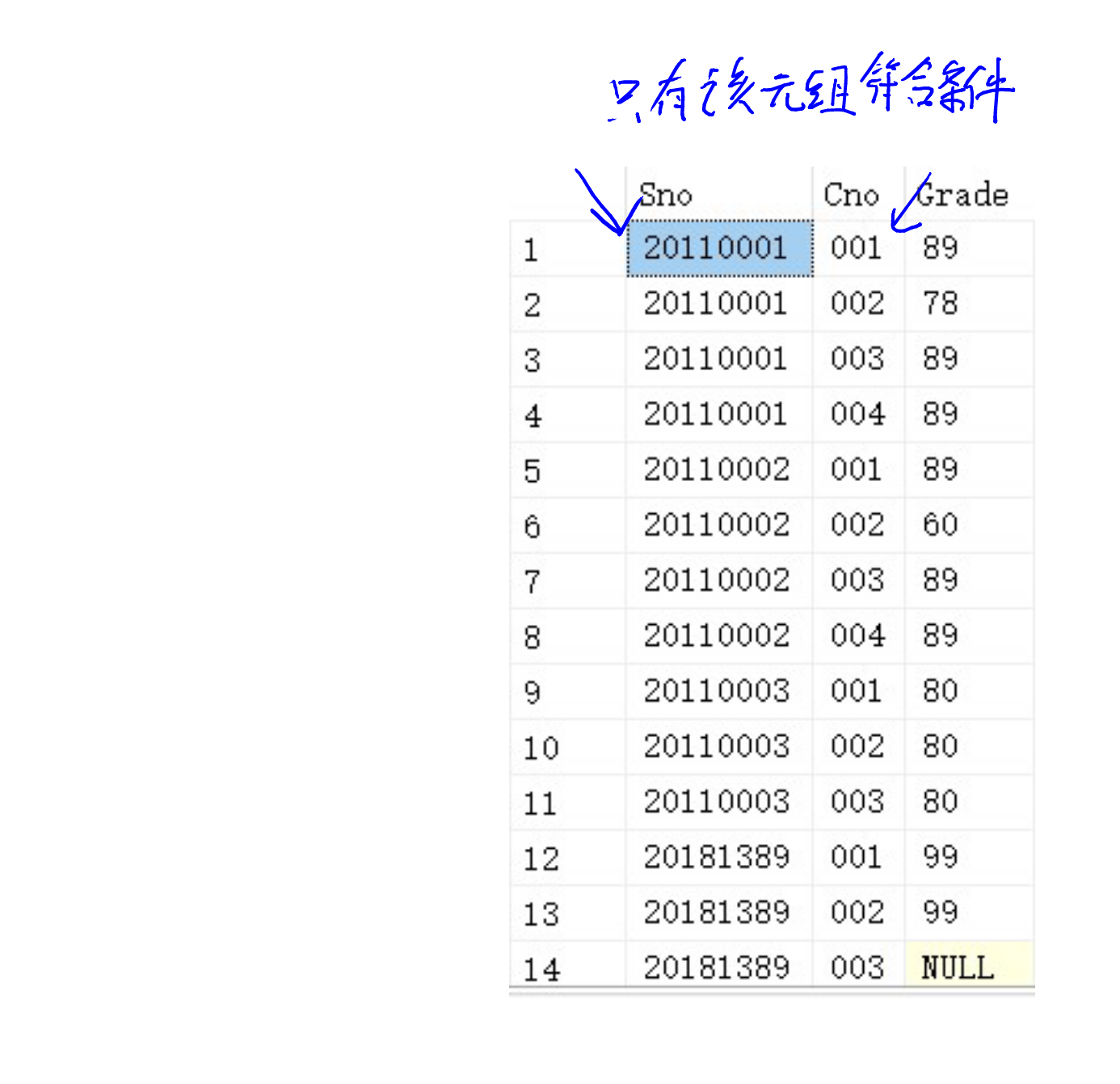
因此
select *
from SC SC2
where SC1.Sno = SC2.Sno
and SC2.Cno = Course.Cno
返回结果集:
20110001 001 89
这时候,我们看回上一层结构:
select Course.Cno
from Course
where not exists(...)
我们成功返回了not exists部分的结果集,因此where处得到的结果是false,因此Course.Cno = 001不被加入这层结构产生的结果集。所以指针往下,Course.Cno的数据变更:

Coures.Cno = 002
于是我们再次进入该语句:
select *
from SC SC2
where SC1.Sno = SC2.Sno
and SC2.Cno = Course.Cno
此时SC1.Sno = 20110001,而Course.Cno = 002。
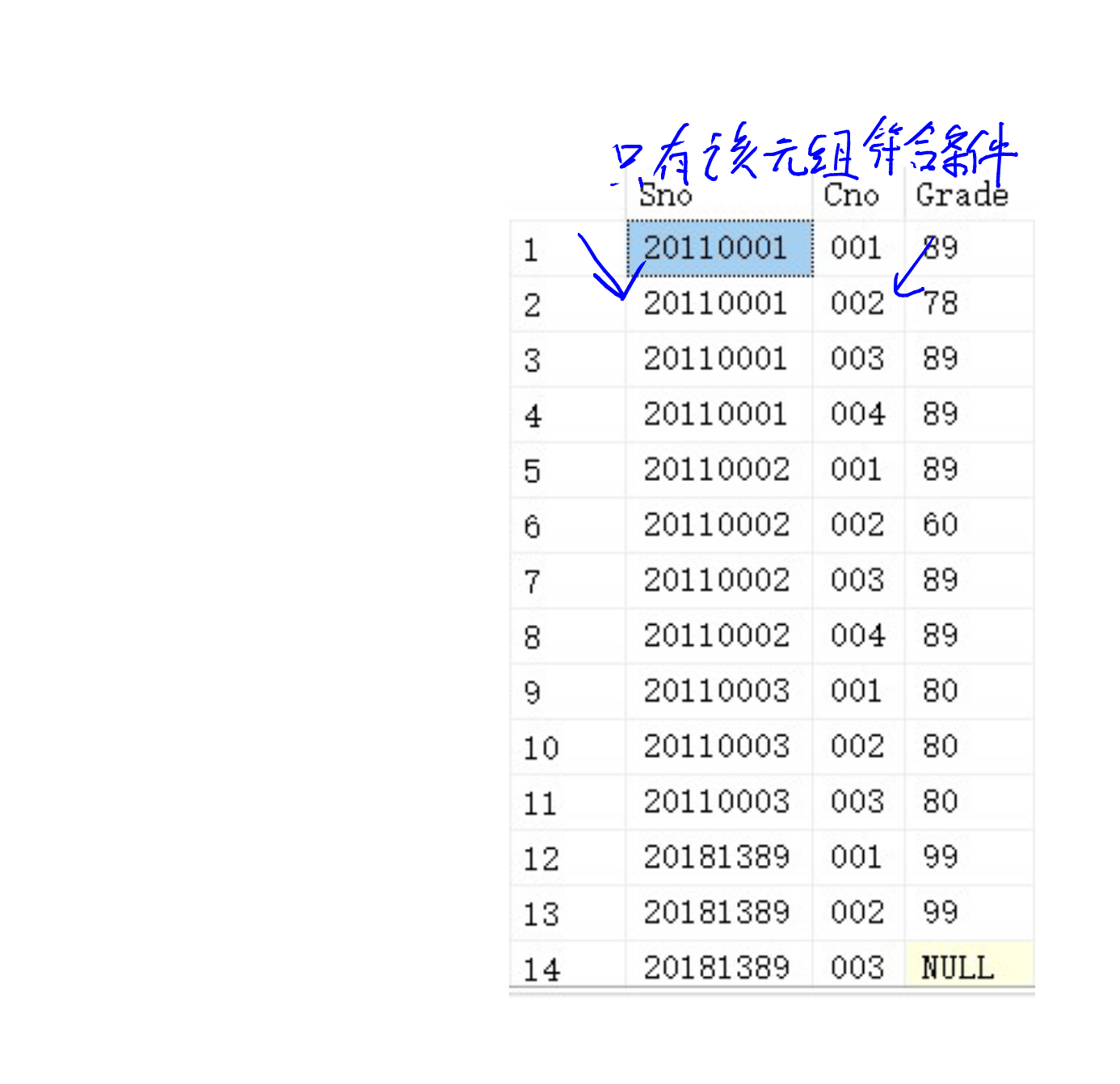
返回结果集:
20110001 002 78
这时候,我们看回上一层结构:
select Course.Cno
from Course
where not exists(...)
我们成功返回了not exists部分的结果集,因此where处得到的结果是false,因此Course.Cno = 002不被加入这层结构产生的结果集。所以指针往下,Course.Cno的数据变更:
Coures.Cno = 003
于是我们再次进入该语句:
select *
from SC SC2
where SC1.Sno = SC2.Sno
and SC2.Cno = Course.Cno
此时SC1.Sno = 20110001,而Course.Cno = 003。
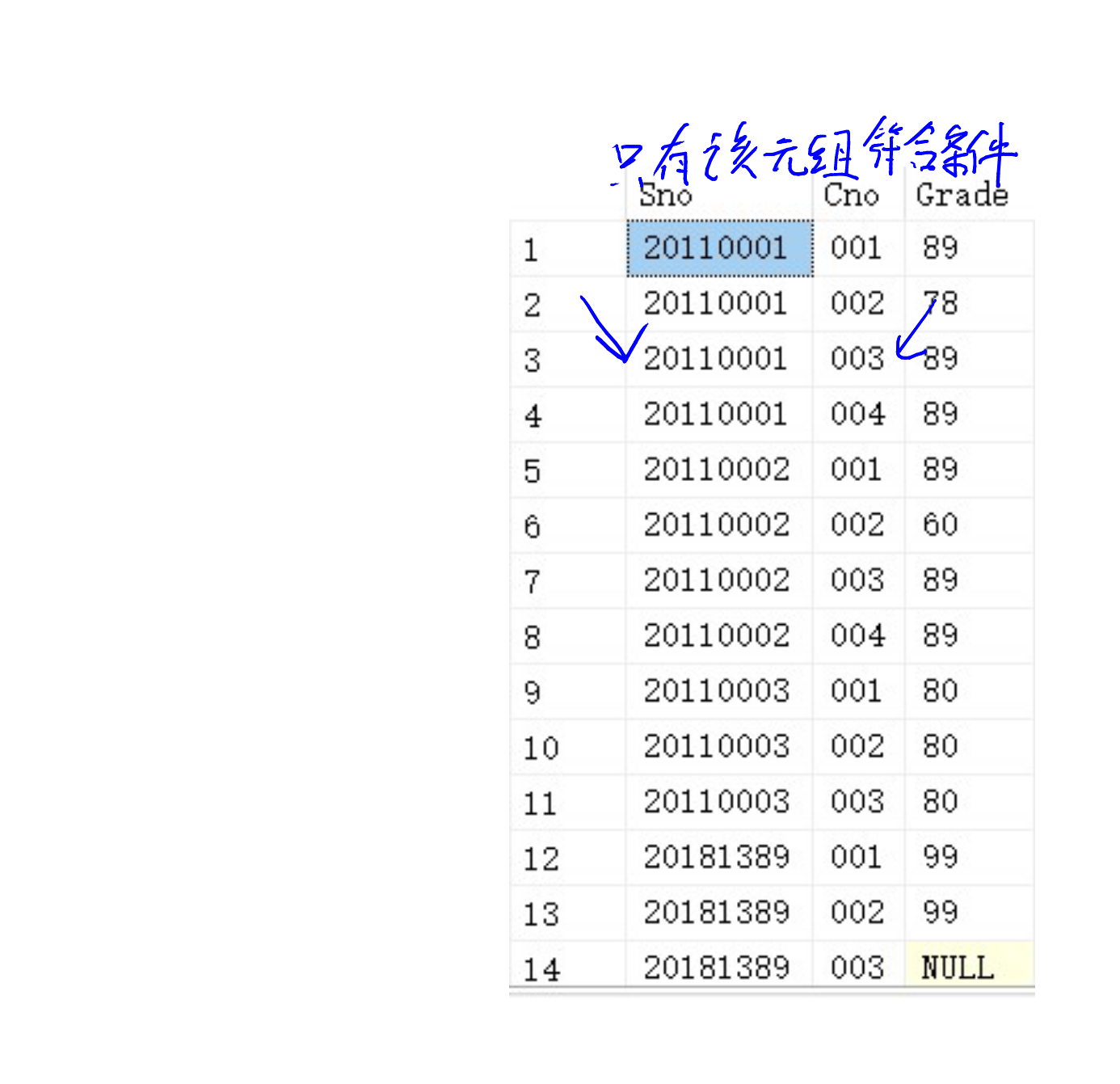
返回结果集:
20110001 003 89
这时候,我们看回上一层结构:
select Course.Cno
from Course
where not exists(...)
我们成功返回了not exists部分的结果集,因此where处得到的结果是false,因此Course.Cno = 002不被加入这层结构产生的结果集。所以指针往下,Course.Cno的数据变更:
Coures.Cno = 004
重复上述的操作,不再赘述。
我们发现,由于20110001这位同学刚刚好都把课选了。每次我们都能从SC表中找到数据,因此
select Course.Cno
from Course
where not exists(...)
该段语句最终的结果是一个空集,没有一个数据被放进了结果集。
这时候我们再回到上一层结构:
select distinct SC1.Sno
from SC SC1
where not exists(...)
该处的not exists中的查询语句返回的是空集,所以它返回的是true。
也就是说,where处得到的结果是true。
也就是说,Sno = 20110001 被加入结果集。
我们继续分析,想要Sno不被加入结果集:
select Course.Cno
from Course
where not exists(...)
这段语句就需要返回结果集。
也就是说这段语句not exists部分至少有一个返回true。
那么这段语句:
select *
from SC SC2
where SC1.Sno = SC2.Sno
and SC2.Cno = Course.Cno
只要元祖没有被找到(即有一门课该学生没有选),它就返回空集。
接下来一系列的连锁反应:
select Course.Cno
from Course
where not exists(...)
返回一个非空结果集
select distinct SC1.Sno
from SC SC1
where not exists(...)
由于返回的是true,所以该学生的学号不被加入结果集。
总结一下
select distinct A.X
from A A1
where not exists(
select B.Y
from B
where not exists(
select *
from A A2
where A1.X = A2.X
and A2.Y = B.Y
)
)
实际上,直观来看:
select distinct A.X
from A A1
where not exists()
这一段相当于按X分组。
select B.Y
from B
where not exists(
select *
from A A2
where A1.X = A2.X
and A2.Y = B.Y
)
这段就是分组来看,去确定在一组中,是不是有某一个数据没有没有在B.Y中,如果有,返回没有在B.Y中的结果
如果的确有一个数据没在其中,由于它是嵌套在not exists中的,只要它返回没有在B.Y中的结果不是空集,就说明该组不合要求,不加入结果集。如果是空集,说明符合要求,加入结果集。
瞎说一下
我知道非常绕,静下心按流程走一走,还是看不懂可以留言喔~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号