


机器学习中的度量——统计上的距离
机器学习是时下流行AI技术中一个很重要的方向,无论是有监督学习还是无监督学习都使用各种“度量”来得到不同样本数据的差异度或者不同样本数据的相似度。良好的“度量”可以显著提高算法的分类或预测的准确率,本文中将介绍机器学习中各种“度量”,“度量”主要由两种,分别为距离、相似度和相关系数,距离的研究主体一般是线性空间中点;而相似度研究主体是线性空间中向量;相关系数研究主体主要是分布数据。本文主要介绍统计上的距离。
1 马哈拉诺比斯距离——向量到某个分布的距离
马哈拉诺比斯距离(Mahalanobis distance)是由印度统计学家马哈拉诺比斯 (英语)提出的,表示数据的协方差距离。它是一种有效的计算两个未知样本集的相似度的方法。与欧氏距离不同的是它考虑到各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的)并且是尺度无关的,即独立于测量尺度。对于一个均值为u=(u1,u2,…, un),协方差为Σ的分布,多变量向量x=(x1, x2, …, xn)到此分布的马哈拉诺比斯距离为:
马哈拉诺比斯距离在某些情况下比欧几里得距离更符合实际,如图8所示:从二元正态分布中叠加100个随机抽取的散点图的等值线图,这个二元正态分布是均值为(0,0),每个维度方差为1,且相关系数为0.5的二元正态分布。正态分布的质心点用蓝色表示,三个兴趣点分别为橙色方块、红色三角形和紫色圆圈。
计算三个兴趣点和质心点的欧几里得距离可知橙色方块<紫色圆圈<红色三角形,但从数据分布来看红色三角形从统计分布意义上应该比紫色圆圈更靠近蓝色质心点。因此欧几里得距离在这里就失效了,如果我们用马哈拉诺比斯距离计算三个兴趣点和质心点的距离,可得橙色方块的马哈拉诺比斯距离为0.94,红色三角形的马哈拉诺比斯距离为0.04,紫色圆圈马哈拉诺比斯距离<0.01,那么三个兴趣点和蓝色质心点距离排序应该是橙色方块<红色三角形<紫色圆圈。
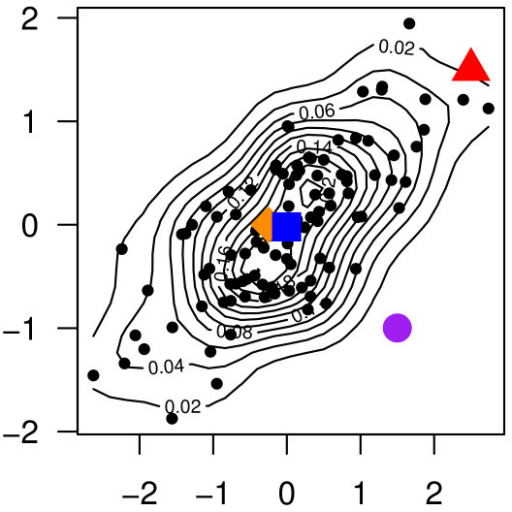
图1 马氏距离的物理意义(图源自《Integrative set enrichment testing for multiple omics platforms》
2 巴塔恰里雅距离——两个分布的距离
巴塔恰里雅距离 (Bhattacharyya distance)。在统计学中,巴塔恰里雅距离测量两个概率分布的相似性。 它与巴塔恰里雅系数密切相关,巴塔恰里雅系数是两个统计样本或群体之间重叠量的度量。此距离以1930年代在印度统计研究所工作的统计学家Anil Kumar Bhattacharya的名字命名。对于数据集X上两个概率分布p和q, 若数据集X对应的是离散分布它们的巴塔恰里雅距离定义为
若数据集X对应的是连续分布,它们的巴塔恰里雅距离定义为
巴塔恰里雅距离可用于确定所考虑的两个样本的相对接近程度。 它用于测量分类中类别的可分性,并且被认为比巴塔恰里雅距离更可靠,因为当两个类别的标准偏差相同时,马哈拉诺比斯距离(见2.2章)是巴塔恰里雅距离距离的特定情况。因此,当两个类具有相似的平均值但标准偏差不同时,马哈拉诺比斯距离将趋向于零,而巴塔恰里雅距离则根据标准偏差之间的差异而增长。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号