Python爬虫&词云图
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/Freshman |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/Freshman/homework/11734 |
| 作业目标 | 题目一:词云图 |
| 作业源代码 | https://github.com/IceSeclude/WinterVacationHomework |
| 学号 | xxxxxx |
#本文来自一名网安的萌新,通往漫长的python之路
这次作业选取题目一:词云海
嘛,无奈,感觉都挺难的。。
>>>>>>>>>>>>>>>>>>>>>>>>华丽的分割线>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
-
爬虫嘛,先找目标网站
捏软柿子软柿子,优先网页设计拉跨的网站下手,本文就拿豆瓣网做案例吧。
注:本文爬取目标为流浪地球的评论
-
分析目标数据在源码中的位置和url中传递的参数

分析发现评论都被放在标签中,所以我们可以利用正则解析获取目标数据
ex = '(.*?)'
text_list = re.findall(ex,page_text)#正则解析
并且通过尝试改变url中传递的参数,
发现页面返回评论由start参数控制,
当start为2时,则评论从第2条开始展示到第21条结束,
每次展示20条。
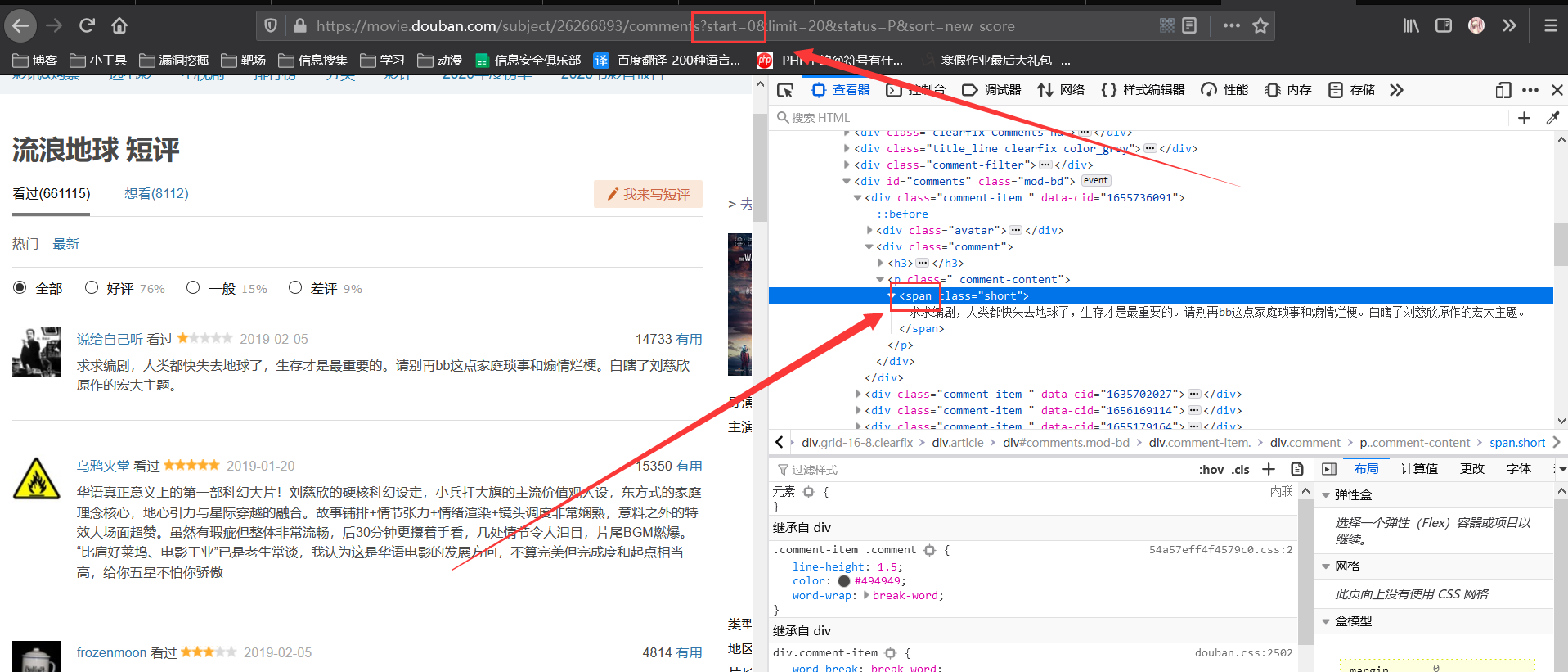
-
代码编写,获取目标数据
注:本文用到的数据库有 requests,re,jieba,imageio,至于安装方法
这里推荐用pycharm进行编写,个人感觉体验极佳。

`
代码如下
import requests
import re
if name == "main":
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
for i in range(0,220,20):
url = 'https://movie.douban.com/subject/26266893/comments?start=%d'%i+'&limit=20&status=P&sort=new_score'#利用for循环拼接url
page_text = requests.get(url=url,headers=headers).text#使用通用爬虫对url对应的一整张页面进行爬取
ex = '(.*?)'
text_list = re.findall(ex,page_text)#使用正则解析得到目标数据
print(text_list)
text_list = '\n'.join(text_list)
file = open("spider1.txt", "a+",encoding='UTF-8')#保存目标数据至spider1.txt
file.write(text_list + "\n")
file.close()
`
代码运行后会将目标数据输出,并保存到spider1.txt文件中
-
词云图制作
注:引用了系主任的博客文章。
代码如下
import jieba.analyse import imageio import jieba.posseg as pseg def jieba_cut(): #停用词 fr = open('tingci.txt', 'r',encoding='UTF-8') stop_word_list = fr.readlines() new_stop_word_list = [] for stop_word in stop_word_list: stop_word = stop_word.replace('\ufeef', '').strip() new_stop_word_list.append(stop_word) print(stop_word_list) #输出停用词 #输出词语出现的次数 fr_xyj=open('spider1.txt','r',encoding='utf-8') s=fr_xyj.read() words=jieba.cut(s,cut_all=False) word_dict={} word_list='' for word in words: if (len(word) > 1 and not word in new_stop_word_list): word_list = word_list + ' ' + word if (word_dict.get(word)): word_dict[word] = word_dict[word] + 1 else: word_dict[word] = 1 fr.close()#按次数进行排序 sort_words=sorted(word_dict.items(),key=lambda x:x[1],reverse=True) print(sort_words[0:101])#输出前0-100的词 from wordcloud import WordCloud color_mask =imageio.imread("cat.png") wc = WordCloud( background_color="white", # 背景颜色 max_words=500, # 显示最大词数 font_path="C:\Windows\WinSxS\amd64_microsoft-windows-font-truetype-simsun_31bf3856ad364e35_10.0.19041.1_none_b0fa2c8e0f0c57df\simsun.ttc", # 使用字体 min_font_size=10, max_font_size=60, width=400, height=860, mask=color_mask) # 图幅宽度 i=str('result') wc.generate(word_list) wc.to_file(str(i)+".png") jieba_cut()
运行后将词云图保存至文件result.png
即完成目标。

>>>>>>>>>>>>>>>>>>>>>>>>华丽的分割线>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
-
总结
·失败是成功之母。
总结是成功之母。√
无数次绊倒我,无数次重新面对的劲敌——————正则匹配。
知识点奉上。
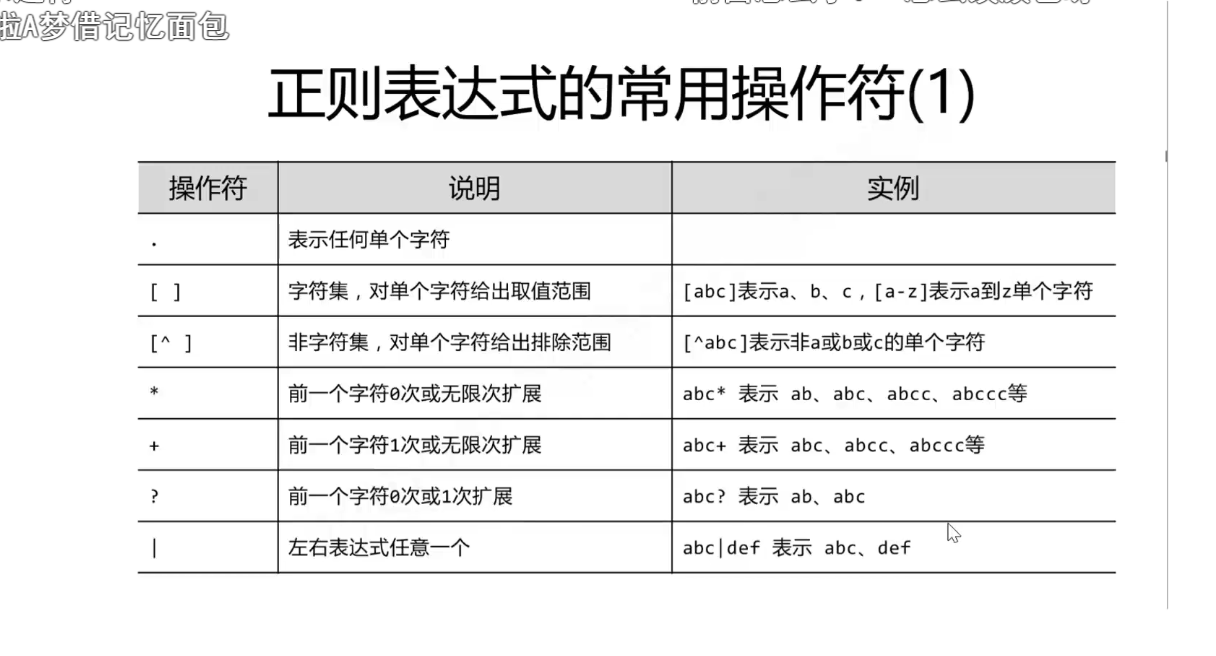
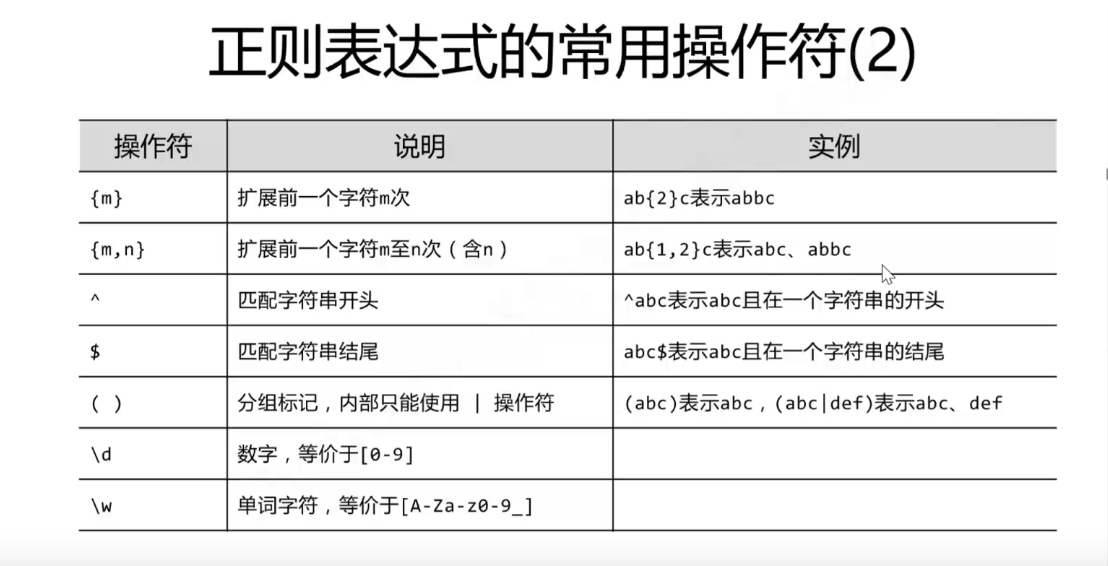
最后。。。。。。。
网安人加油!
>
>
最后的最后,网 安 俱 乐 部 欢 迎 你 的 加 入√


 浙公网安备 33010602011771号
浙公网安备 33010602011771号