随笔分类 - 爬虫
摘要:目录正则表达式XPathBeautifulSoupCSS-Selectorpyquery 正则表达式 XPath https://www.w3school.com.cn/xpath/xpath_axes.asp BeautifulSoup CSS-Selector https://www.w3sch
阅读全文
摘要:目录一、urllib使用request模拟发送请求官方文档urlopen发送get请求urlopen发送post请求parse介绍编码与解码Handler处理器1)登录验证2)ProxyHandler代理设置3)CookieJar/HTTPCookieProcessor获取、保存和读取Cookiee
阅读全文
摘要:目录一、HTML标签分类空标签/单标签闭合标签/双标签块级元素内联元素(行内元素)二、几种主要网页编码Unicode(统一码、万国码、单一码)UTF-8GB2312GBK如何让浏览器正确识别网页编码三、HTTP和HTTPS协议HTTP协议HTTPS协议浏览器中发送http请求的过程:请求方法 一、H
阅读全文
摘要:pyppeteer与selenium对比 分析来源 requests 爬取下来的只能是服务器端网页的源码,这和浏览器渲染以后的页面内容是不一样的。因为,真正的数据是经过 JavaScript 执行后,渲染出来的,数据来源可能是 Ajax,也可能是页面里的某些 Data,或者是一些 ifame 页面等
阅读全文
摘要:### 项目预览 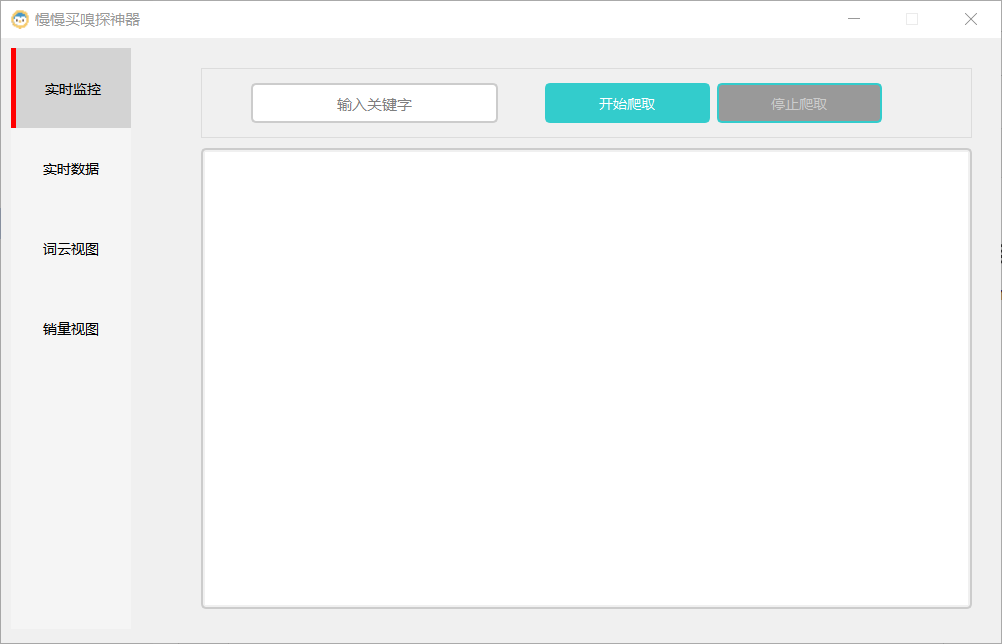 
 浙公网安备 33010602011771号
浙公网安备 33010602011771号