
摘要:
sigmoid会衰减输入的影响(大input,小output),层数过多的话,导致输入对cost的影响几乎为0 ReLU是Maxout的特例,Maxout比ReLU更灵活 如何训练Maxout 等价这个网络(不同的样本更新不同的参数) 优化器AdaGrad RMSProp local minima( 阅读全文
摘要:
Contextual Query Understanding,根据上文补全当前Query 为了热更,只需新增一个intent cls。 对话策略配置 阅读全文
摘要:
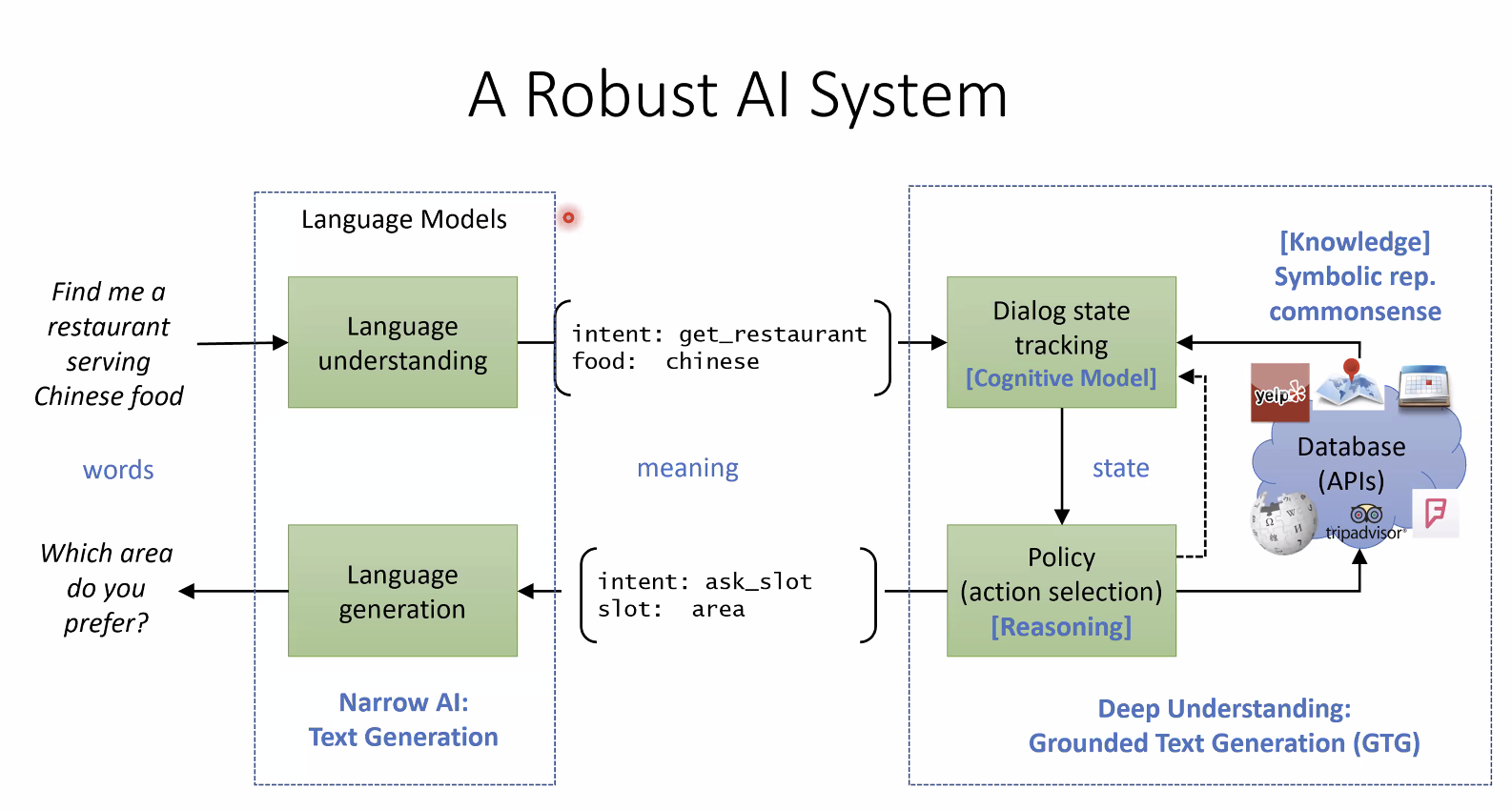
  :food= chinese 0.6,italian 0.4 简单的聚合函数是平均,下边是两种改进方案: 【词级别信息引入网络?】 阅读全文
摘要:
![](https://img2020... 阅读全文