
使用阿里云RDS for SQL Server性能洞察优化数据库负载-初识性能洞察
简介
数据库性能调优通常需要较高数据库水平,并伴随较多的前期准备工作,比如收集各种性能基线、不同种类的性能指标、慢SQL日志等,这通常费时费力且效果一般,当面对多个数据库时总体拥有成本会大幅增加。今天数据库早已迈入云时代,借助阿里云RDS for SQL Server Clouddba这一免费工具,可以快速准确地降低阿里云RDS for SQL Server数据库负载优化成本与操作人员技能水平要求,从而达到将更多精力用于实现业务本身的,而不是数据库上实现细节。
本篇文章主要分享阿里云Clouddba 性能洞察的基本原理与使用方式,并利用该平台诊断优化常见的性能问题。
如何评估数据库负载情况?
当问到,如何评估数据库负载时,不同角色可能想到不同的方法,例如以下几种:
- QPS/TPS
- 资源使用: IOPS CPU 内存
- SQL执行时间
- 并发量
- Application业务反馈
上述每一种评价方法都较为片面且作为对实际调优的参考也较为困难。
通常情况下,我们评价数据库资源负载是一个较为复杂的事情,需要我们对关系数据库的有一个较为全面的理解才行,但作为数据库的使用者,大多数人不需要对数据库进行深入学习,因此,我们倾向于简化指标。
比如说,我们会只看CPU、IO、内存等指标看数据库是否存在问题,这些指标适用于监控大多数应用,但对于数据库来说可能并不能够较为正确的反映数据库内发生了什么,以及我们该如何处理。我们还要结合很多数据库特有的指标综合判断,比如各种SQL Server专用的性能计数器、DMV、等待类型、长事务、网络、活动连接等等。但这些信息需要我们对数据库自身有一个高级的了解,这使得评估数据库的负载成为一个较高门槛的工作。
下面我们不妨换一个思路,关系数据库本身是一个同步调用的过程,也就是说,从应用程序发起SQL,到数据库返回结果,是同步的,数据库不完成该请求,那么应用程序无法收到结果,在此期间应用程序与数据库之间的Session就是所谓的“Active”状态,因此我们可以尝试不再从资源使用的角度出发评估数据库负载,而简化为一个简单的指标-AAS(Average Active Session),也就是活跃会话数量。
为什么我们使用AAS概念
设想一下,当你开车去一个目的地时,你更关注的是什么?目的地的距离?路上是否堵车?到目的地是否有停车位置?等等,你会关心汽车状态吗?或许会,但你需要了解发动机原理、汽车的相关原理才能正确判断车的状态是否正常吗?我们只需通过仪表盘几个简单的指标和报警灯做一个简单的判断即可。
数据库也是一样,绝大多数用户的场景并不需要理解数据库引擎底层原理,而是更多关注如何使用数据库,当然发烧友另说:-)
我们通过使用AAS的概念,提供了一种简单、抽象的评估方法,也就是数据库的活动连接数来衡量数据库的总体负载,以及每种SQL对负载的贡献,把数据库各种metric汇总为一个简单的指标----AAS
,从而使得用户使用该抽象的概念评估数据库负载,用户仅需要对比AAS与CPU核数来评估当前负载是否超出当前实例的能力,这极大的降低了用户需要对数据库技能的要求,用户可以花更多精力在业务逻辑而不是数据库技术细节上。优化器、执行计划、执行引擎,Buffer Pool,这些数据库的技术细节我们都可以减少了解
一个AAS概念简单的图形示例如图1所示:

图1.简单的性能洞察示例
横轴Time为时间,假设有3个长连接(也就是上图中的User),每个连接根据应用负载向数据库发送SQL请求,当时间为1时,User1连接正在执行SQL,并使用CPU资源,User2正在等待锁资源,User3没有负载,因此时间1的AAS值为2,时间2的AAS值为3,以此类推。
那么AAS的值是2还是3究竟是高还是低?这取决于当前数据库所拥有的CPU Core数量,每一个Core维护一个完整的SQL执行周期,如图2所示:
图2.SQL执行时每个CPU的调度状态
当AAS值<=CPU核数时,通常来讲数据库的负载没有额外等待,当前负载不需要额外等待其他CPU的调度,是AAS比较理想的状态。
设想一个场景,你作为数据库的运维人员,开发或业务方找到你说,嗨,数据库出问题了。通过AAS,你可以简单的根据AAS一个指标,初步缩小排查范围,确定问题是否真正的出在数据库。
一个简单的AAS与实例核数的对比关系如下:
- AAS ≈0 数据库无明显负载,异常在应用侧
- AAS < 1 数据库无阻塞
- AAS< Max CPUs 有空余CPU核,但可能存在单个Session打满或资源(OLAP)
- AAS> Max CPUs 可能存在性能问题,但存在特殊情况
- AAS>> Max CPUs 存在严重性能问题,但存在特殊情况
性能洞察简介
通过图3我们可以看到性能洞察功能的UI,该功能的入口如图
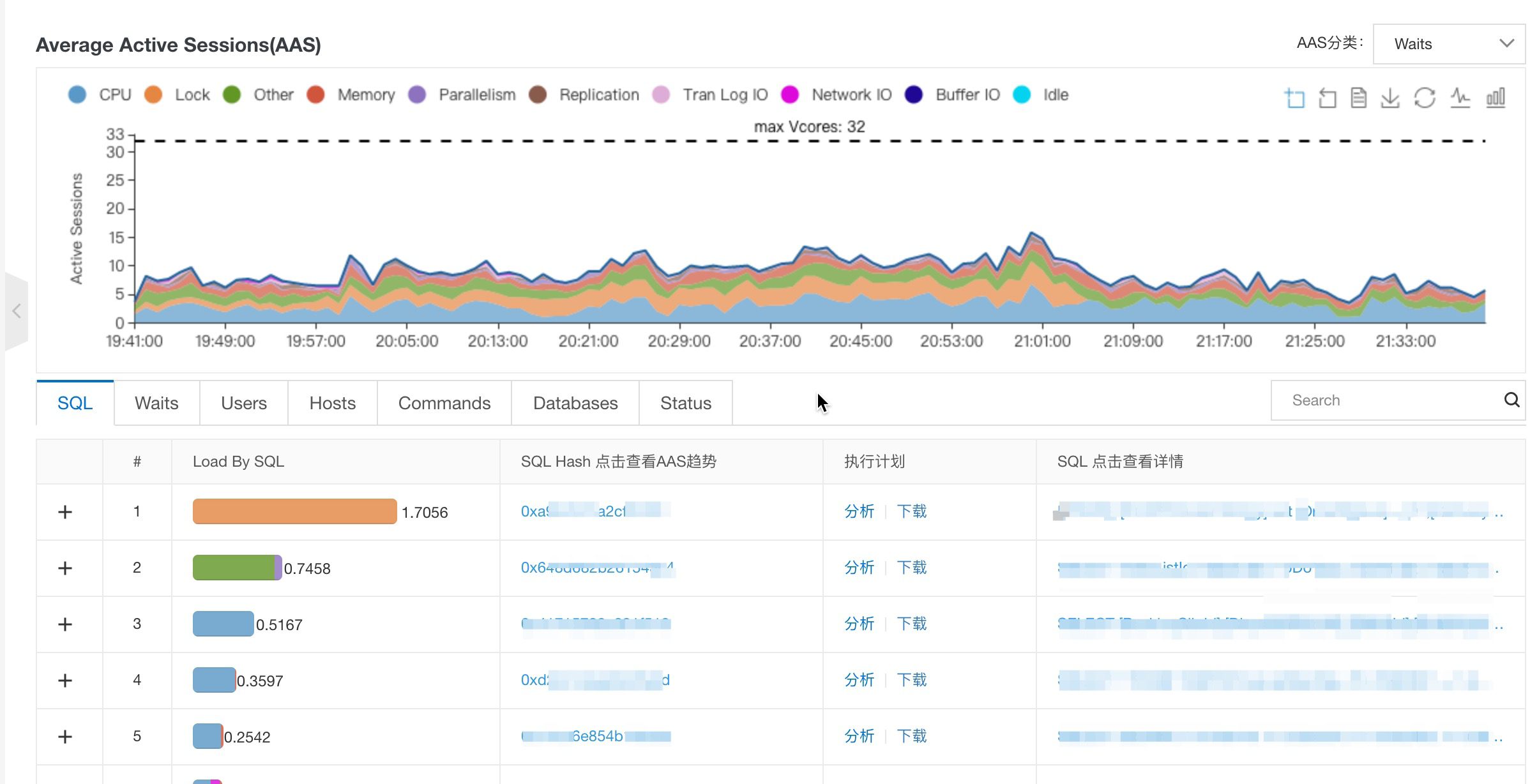
图3.性能洞察的一个典型UI
上下两部分,上部分是按时间序列展示每个时间段的AAS负载情况,下部分是按照不同维度由高到底展示不同维度资源所占的负载,默认以SQL维度为主。
上部分可以看到个时间段负载,每种资源所占比例,比如图中蓝色展示的是CPU,其中重要的是当前实例规格的核数(max Vcores: 32),如果AAS值超过实例所拥有的CPU核数,我们就知道当前实例负载处于超标状态,图3所示负载一直处于10左右,低于Max Vcores 32,可以知道数据库整体负载处于健康水位。
那从哪知道这些负载的来源?可以通过图3下面的部分看到对应的SQL,以及每个SQL所贡献的AAS比例,例如图中可以看到第一条SQL全部为橙色,值为1.7056,该值说明在给定时间段内,该语句存在的平均会话是1.7次。而主要是等待Lock资源,这说明该语句的瓶颈在于锁。
因此我们注意到第一个语句AAS贡献最高,且等待瓶颈在于锁,根据图4数据库调优的抽象方法论,就解决了两个问题“缩小范围”和“定位瓶颈”两个问题:

图4.性能调优4个步骤
通俗点说,也就是解决了下面两个问题:
- 哪些SQL在特定时间对实例的负载影响最大
- 这些SQL为什么慢
而具体如何实施优化,以及如何验证优化效果,会在后续文章中进行讲述。
USE CASE1:快速优化整体负载情况
80 20法则同样适用于数据库,80%的负载都是由20%的 SQL产生,也就是说只要优化这20%的SQL就已经完成了80%的优化工作,进一步想,如果20%中的20%,也就是4%,优化这部分岂不是就可以完成80%*80%=64%的工作。因此很多场景下,优化头部的几个SQL就能完成绝大多数优化工作。

图5.CPU 100%问题定位
图4我们可以看到,示例CPU使用率一直100%,在发生阻塞时会瞬间跌到个位数。我们观察一个小时的AAS数据,看到下面单个Select的SQL的平均AAS为78,远远超过实例8C的规格,因此只要优化这一个SQL,该实例的问题基本就能够得到解决。
通过图4的SQL“分析”功能,我们能够快速根据执行计划发现常见SQL慢的原因,包括索引缺失、参数类型转换、统计信息不准确等问题。
USE CASE2:找到特定时间段内数据库响应时间变慢的原因
这类场景也是一个经典场景,数据库整体可能较长时间处于健康水平,但在业务高峰或特定时间段,存在数据库负载压力较大,业务侧SQL较慢的场景。通常情况下,大多数数据库仅存在一些指标维度的监控,比如通用的CPU、网络、IO。或者引擎侧的指标,通常通过这些指标我们能猜测出大概范围,但难以定位到具体语句,通过AAS,我们可以通过查看特定时间段的高负载定位到导致特定时间数据库问题的语句,如图6所示:

图6.特定时间负载高
通过图6,我们可以看到再特定2分钟内有性能突发的毛刺,我们通过鼠标拖拽放大该时间范围,得到如图7所示结果

图7.拖拽后明显看到两个导致高AAS的语句
通过图7,我们可以快速定位到两个产生性能毛刺的语句,并且注意到等待类型分别为Lock与Tran Log IO,由此根据图4的调优理论,我们可以初步判断是大量的更新操作产生的日志IO负载,并由于这些语句之间的锁阻塞导致锁等待。这可以极大的降低调优成本。
小结
使用性能洞察,在云上我们可以做到不用任何额外成本,快速查看整体负载,查看负载细节,以及定位不同负载对应的SQL,从而可以帮我我们在云上快速解决数据库性能问题、并定期调优整体负载。
而且更重要的是,性能洞察是免费的!!!阿里云RDS for SQL Server全系列可用:-)
