

17 Group Replication
17.2.1 Group Replication部署单主模式
17.2.1.1 部署Group Replication实例
17.2.1.2 为一个实例配置Group Replication
17.3.1 Replication_group_member_stats
17.3.2 Replication_group_members
17.3.3 Replication_connection_status
17.3.4 Replication_applier_status
17.3.5 Group Replication Server States
17.4.3.2 Unblocking a Partition
17.9.3 Data Manipulation Statements
17.9.4 Data Definition Statements
17.5.9.2 Recovering From a Point-in-time
17.1 Group Replication后台
最常用创建容错系统是使用手段来冗余组件,也就是说组件可以被删除,但是系统还是正常运行。复制的数据库必须面临的一个问题,他们需要维护和管理多个实例,还有服务组合在一起创建,把一切其他传统分布式系统组合的问题也必须解决。
最主要的问题是抱着数据库和数据的复制在几个服务合作下,逻辑是一致的并且是简单的。也就是说,多个服务同意系统和数据的状态,并且同意系统前进时的每个修改。就是服务在每个数据库的传输的状态都必须同意,所有的处理就好像在一个数据库或者之后会覆盖的其他数据库到相同的状态。
MySQL Group Replication提供了分布式复制,使用server之间的强连接,如果服务在相同的group,那么久会自动连接上。Group可以是单主,也可以是多主的。
有一个编译好的服务,在任意时间点,可以看group的一致性和可用性。服务可以加入,离开group,并且view会有相应的更新。有时候服务会异常离开group,那么错误诊断机制会发现并且通知组并且修改view,这些都是自动的。
对于事务提交,需要大多数同意。事务提交和回滚完成是由单独服务确定的,不是所有的服务决定。如果有一个network partition,那么就会导致分裂,成员不能相互通信,因此系统不能处理,知道问题被解决。当然也有内置的,自动的主分裂保护的机制。
17.1.1 Replication技术
17.1.1.1 主从复制
MySQL传统的主从复制。有一个主,多个从。主执行事务,提交然后发送到从,重新执行。是shared-nothing系统,所有的服务默认是full copy的。
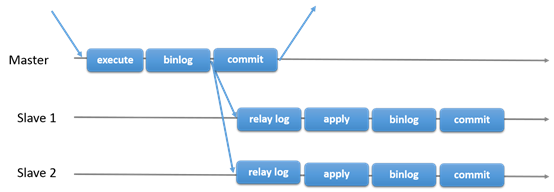
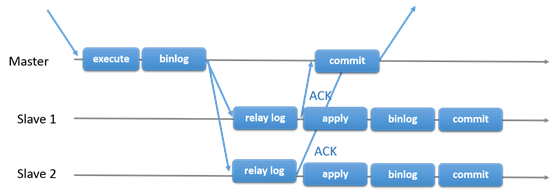
17.1.1.2 Group Replication
Group Replication可以用于容错系统,是一组互相交互的服务。交互层提供了机制确保消息的原子性和消息的交互。
Group Replication实现了多主的复制。复制组由多个服务组成,每个服务都可以运行事务。读写的时候之后group认可之后才能提交。只读事务因为不需要和group交互,因此提交很快。也就是说关于写入事务,group需要决定事务是否提交,而不是原始的服务单独确定的。当原始服务准备提交,服务会自动广播。然后事务的全局顺序被建立。这个很重要,也就是说所有的服务在相同的事务顺序下,收到了相同的事务。这样也就保证了group的数据一致性。
当然不同的服务并发的执行事务也会有冲突。这种冲突出现在检查不同写入集合的并发事务。这个过程叫做certification 。如果2个并发事务在不同的服务上运行,更新了相同的行,那么就是发生冲突了。解决方法是提交顺序在前面的,另外一个就回滚。
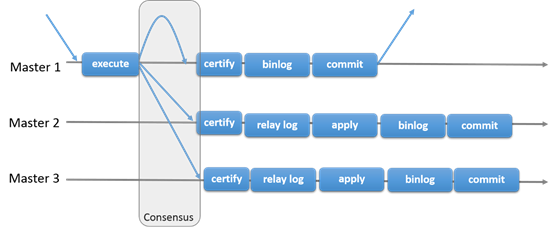
17.1.2 Group Replication使用场景
略,具体看:
https://dev.mysql.com/doc/refman/5.7/en/group-replication-use-cases.html
17.1.3 Group Replication细节
17.1.3.1 错误发现
有一个错误发现机制,用来找出报告那个服务是静默的,然后假定为已经挂了。错误发现其实分布式服务用来提供服务的活动信息。之后group决定服务确实出错,那么剩下的group成员就会排除这个成员。
当服务静默,错误发现机制就会被触发。当服务A没有收到来自服务B的,而且超时就会触发。
如果服务被所有的成员隔离,并怀疑所有的node都是错误的。就不能被group保护,怀疑是无效的。当服务被怀疑,那么就不能再执行任何本地事务。
17.1.3.2 Group成员
MySQL Group Replication管理到Group成员服务,这个服务是内置的插件,定义了那个服务是在线的,可以投票的。在线的服务被称为view。因此每个group内的服务都有一个一样的view,表示那个服务是活动的。
所有服务需要统一的不单单是事务提交,还有当前的view。因此如果所有同意一个新的服务的加入,然后Group重新配置,加入这个服务,并且出发view的修改。当服务离开group的时候也会发生,然后group重排配置,并且出发view的修改。
当一个成员自觉的离开group,会先初始化Group的重新配置。然后出发一个过程,除了一开的服务之外,其他服务都要同意,如果成员是因为故障一开的,错误发现机制发现问题,并且发出重新配置的提议。需要所有的服务同意,如果不能同意那么group的配置就无法修改。也就是说管理员需要手工来修复。
17.1.3.3 错误容忍
Group Replication实现了Paxos分布式算法来提供服务的分布式服务。要求大多数的服务活动以达到大多数,来做个决定。直接影响了系统可以容忍的错误容错公司如下,服务器n,容错f:n = 2 x f + 1
也就是说,容忍一个错误那么group必须要有3个成员。因为就算有一个错了,还有2个,任然可以形成大多数来处理一些事情。如果另外一个也挂, 那么就剩下一个,不发形成大多数(大于半数)。
|
Group Size |
Majority |
Instant Failures Tolerated |
|
1 |
1 |
0 |
|
2 |
2 |
0 |
|
3 |
2 |
1 |
|
4 |
3 |
1 |
|
5 |
3 |
2 |
|
6 |
4 |
2 |
|
7 |
4 |
3 |
17.2 Getting Start
17.2.1 Group Replication部署单主模式
每个实例可以运行在单个机器上,可以在同一个机器上。
17.2.1.1 部署Group Replication实例
第一步不是三个实例。Group Replication是MySQL内部的插件,MySQL 5.7.17之后版本都开始有。
mkdir data
mysql-5.7/bin/mysqld --initialize-insecure --basedir=$PWD/mysql-5.7 --datadir=$PWD/data/s1
mysql-5.7/bin/mysqld --initialize-insecure --basedir=$PWD/mysql-5.7 --datadir=$PWD/data/s2
mysql-5.7/bin/mysqld --initialize-insecure --basedir=$PWD/mysql-5.7 --datadir=$PWD/data/s3
17.2.1.2 为一个实例配置Group Replication
配置服务的基本配置:
[mysqld]
# server configuration
datadir=<full_path_to_data>/data/s1
basedir=<full_path_to_bin>/mysql-5.7/
port=24801
socket=<full_path_to_sock_dir>/s1.sock
配置复制相关,并启动GTID
server_id=1
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
binlog_checksum=NONE
log_slave_updates=ON
log_bin=binlog
binlog_format=ROW
Group Replication配置
transaction_write_set_extraction=XXHASH64
loose-group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
loose-group_replication_start_on_boot=off
loose-group_replication_local_address= "127.0.0.1:24901"
loose-group_replication_group_seeds= "127.0.0.1:24901,127.0.0.1:24902,127.0.0.1:24903"
loose-group_replication_bootstrap_group= off
第一行:所有的写入的事务的write set使用XXHASH64进行编码。
第二行:要加入的group的名字
第三行:服务启动后,不自动启动
第四行:使用127.0.0.1,端口为24901,来接入group成员的连接。
第五行:当加入一个group时,需要连接的host,只需要连接一个,然后该阶段会要求group重新配置,允许服务器加入到group。当多个服务同时要求加入group,保证用的seed已经在group 中。
第六行:插件是否关联到group,这个参数很重要,必须只有一个服务使用,不然会出现主分裂的情况,就是不同的group有相同的Group名字。第一个服务实例online之后就禁用这个选项。
17.2.1.3 用户授权
Group Replication使用异步复制的协议,处理分布的恢复,来同步将要加入group的成员。分布的恢复处理依赖于复制通道,group_replication_recovery 用来在group成员之间做传输。因此需要一个复制用户和足够的权限,用户成员之间的恢复复制通道。
创建一个拥有REPLICATION_SLAVE权限的用户,但是这个过程不能被binlog捕获。
mysql> SET SQL_LOG_BIN=0;
Query OK, 0 rows affected (0,00 sec)
mysql> CREATE USER rpl_user@'%' IDENTIFIED BY 'rpl_pass';
Query OK, 0 rows affected (0,00 sec)
mysql> GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';
Query OK, 0 rows affected, 1 warning (0,00 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0,00 sec)
mysql> SET SQL_LOG_BIN=1;
Query OK, 0 rows affected (0,00 sec)
配置好之后,使用change master to语句配置服务
mysql> CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='rpl_pass' \\
FOR CHANNEL 'group_replication_recovery';
Query OK, 0 rows affected, 2 warnings (0,01 sec)
分布式恢复的第一步就是把服务加入到Group中,如果账号和权限设置的不对那么无法运行恢复进程,最重要的是无法加入到group。类似的,如果成员不能正确的通过host识别其他成员那么恢复进程也会错误。可以通过performance_schema. replication_group_members查看host。可以使用report_host区别开来。
17.2.1.4 执行Group Replication
弄完上面的配置,并且启动后,连接到服务,执行一下命令:
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
安装好之后可以通过show plugins查看,如果安装成功就会在返回中。
启动group,让s1关联group并且启动Group Replication。这个关联要单个服务器完成,并且只能启动一次。所以这个配置不能保存在配置文件中,如果保存了,下次启动会自动关联到第二个Group,并且名字是一样的。如果开关plugin,但是参数是ON的也会有这个问题。
SET GLOBAL group_replication_bootstrap_group=ON;
START GROUP_REPLICATION;
SET GLOBAL group_replication_bootstrap_group=OFF;
一旦start完成,就可以查到成员了:
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+---------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+---------------+
| group_replication_applier | ce9be252-2b71-11e6-b8f4-00212844f856 | myhost | 24801 | ONLINE |
+---------------------------+--------------------------------------+-------------+-------------+---------------+
1 row in set (0,00 sec)
增加一些数据:
mysql> CREATE DATABASE test;
Query OK, 1 row affected (0,00 sec)
mysql> use test
Database changed
mysql> CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 TEXT NOT NULL);
Query OK, 0 rows affected (0,00 sec)
mysql> INSERT INTO t1 VALUES (1, 'Luis');
Query OK, 1 row affected (0,01 sec)
17.2.1.5 增加一个实例到Group
这个时候已经有一个成员了s1,已经有了一些数据,现在加入其它节点到Group
增加s2 到group,设置配置文件,基本和s1的一直,修改server_id,因为文档中是本地多实例,需要修改datadir等信息。
设置用于复制的用户:
SET SQL_LOG_BIN=0;
CREATE USER rpl_user@'%';
GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%' IDENTIFIED BY 'rpl_pass';
SET SQL_LOG_BIN=1;
CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='rpl_pass' \\
FOR CHANNEL 'group_replication_recovery';
然后启动
mysql> INSTALL PLUGIN group_replication SONAME 'group_replication.so';
Query OK, 0 rows affected (0,01 sec)
这里和s1不一样的地方。
START GROUP_REPLICATION;
通过 performance_schema.replication_group_members 检查成员是不是正常。
查看之前s1插入的数据时候已经完全同步过来。
17.3 监控Group Replication
使用performance schema 上的表来监控Group Replication,如果有performance_ schema那么就会在上面创建来个表:
· performance_schema.replication_group_member_stats
· performance_schema.replication_group_members
· performance_schema.replication_connection_status
· performance_schema.replication_applier_status
· group_replication_recovery
· group_replication_applier
17.3.1 Replication_group_member_stats
|
Field |
Description |
|
Channel_name |
Group Replication通道名 |
|
Member_id |
成员的uuid |
|
Count_transactions_in_queue |
未经过冲突检查的事务数量 |
|
Count_transactions_checked |
通过冲突检查的事务数量 |
|
Count_conflicts_detected |
没有通过冲突检查的事务数量 |
|
Count_transactions_rows_validating |
冲突检查数据库的大小 |
|
Transactions_committed_all_members |
成功提交到成员的事务数量 |
|
Last_conflict_free_transaction |
最后一次冲突,被释放的事务 |
17.3.2 Replication_group_members
|
Field |
Description |
|
Channel_name |
通道名 |
|
Member_id |
成员uuid |
|
Member_host |
成员host |
|
Member_port |
成员端口 |
|
Member_state |
成员状态 (which can be ONLINE, ERROR, RECOVERING, OFFLINE or UNREACHABLE). |
17.3.3 Replication_connection_status
|
Field |
Description |
|
Channel_name |
通道名 |
|
Group_name |
Group名 |
|
Source_UUID |
Group的标识 |
|
Service_state |
查看服务是否是group成员{ON, OFF and CONNECTING}; |
|
Received_transaction_set |
已经被该成员接受的gtid集 |
17.3.4 Replication_applier_status
|
Field |
Description |
|
Channel_name |
通道名 |
|
Service_state |
服务状态 |
|
Remaining_delay |
是否配置了延迟 |
|
Count_transactions_retries |
重试执行的事务个数 |
|
Received_transaction_set |
已经被接收的gtid集 |
17.3.5 Group Replication Server States
表replication_group_members在view发生变化的时候就会修改,比如group的配置动态变化。如果出现网络分离,或者服务离开group,信息就会被报告,根据不通的服务获得的信息不通。注意如果服务离开了group,那么就无法获得其他服务的信息。如果发生分离,比如quorum丢失,服务就不能相互进行协同。也就是说会报告unreachable而不会一个假设状态。
|
Field |
Description |
Group Synchronized |
|
ONLINE |
服务online可以提供全部服务 |
Yes |
|
RECOVERING |
成员正在恢复,之后会变成online黄台 |
No |
|
OFFLINE |
插件已经安装,但是成员不属于任何group |
No |
|
ERROR |
在recovery阶段或者应用修改的时候,出现错误 |
No |
|
UNREACHABLE |
错误排查怀疑服务无法连接。 |
No |
17.4 Group Replication操作
17.4.1部署多主或者单主模式
Group Replication有2个不同的模式:
1. 单主模式
2. 多主模式
默认是单主模式的,不能的模式不能出现在一个group中,比如一个成员是单主,一个成员是多主。切换模式需要重新配置,然后重启。不管什么模式,Group Replication都不支持failover。这个必须由程序自己来处理,或者用其他中间件。
当不是了多主,语句是可以兼容的,当在多主模式,以下情况是会被检查语句的:
1. 如果一个事务执行在serializable隔离级别,但是提交失败
2. 如果事务执行的表有外键,但是提交失败
当然检查可以通过group_replication_enforce_update_everywhere_checks来关闭。
17.4.1.1 单主模式
在单主模式下,只有主是可以读写的,其他都只能读取。这个设置是自动的。主通常是关联到group的,其他的成员join,自动学习主,并且设置为只读。
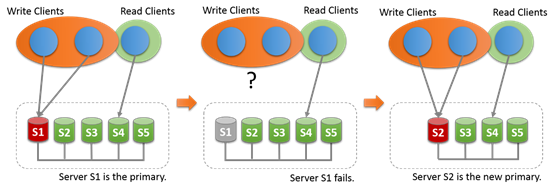
在单主模式下,多主的检查被取消,因为系统只有一个服务是可写的。当主成员失败,自动主选举机制会选取新的主。然后新竹根据成员的uuid进行排序然后选择第一个。
当主离开Group,也会选举新主,一旦新主被选出来之后,就会设置可读写,其他任然是从。
17.4.1.2 多主模式
在多主模式下,和单主不通,不需要选举产生多主,服务没有特定的角色。所有的服务都是可读写的。
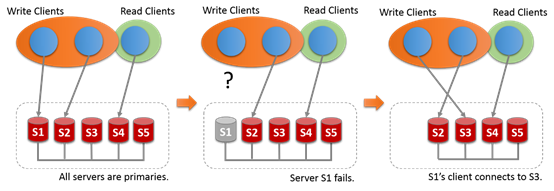
17.4.1.3 查找Primary
Primary 可以通过show status 或者select查找:
mysql> SELECT VARIABLE_VALUE FROM performance_schema.global_status WHERE VARIABLE_NAME= 'group_replication_primary_member';
+--------------------------------------+
| VARIABLE_VALUE |
+--------------------------------------+
| 69e1a3b8-8397-11e6-8e67-bf68cbc061a4 |
+--------------------------------------+
1 row in set (0,00 sec)
17.4.2 协调Recovery
当一个新的成员要加入到group,会连接到一个合适的donor并且获取数据,成员会一直获取直到状态变为online。
Donor选择
Donor选择是随机的在group中选一个成员。同一个成员不会被选择多次。如果连接到donor失败,那么会自动或去连接新的donor,一旦超过连接重试限制就会报错。
强制自动Donor切换
出现以下问题的时候会自动切换到一个新的donor,并尝试连接:
1. 清理数据场景,如果被选择的donor包含数据清理,但是是recovery需要的,那么会产生错误并且,获取一个新的donor。
2. 重复数据,如果一个joiner已经包含了一些数据,和selected的有冲突,那么也会报告错误,并且选择一个新的donor。
3. 其他错误,任何recovery线程的错误都会触发,连接一个新的donor。
Donor连接重试
Recovery数据的传输是依赖binlog和现存的MySQL复制框架,因此可能会有一些传输问题导致receiver或者applier有问题。这个时候会有donor切换。
重试次数
默认从donor pool里面可以尝试10次连接,也可以通过参数修改,一下脚本设置成了10次:
SET GLOBAL group_replication_recovery_retry_count= 10;
Sleep Routines
通过参数设置:
SET GLOBAL group_replication_recovery_reconnect_interval= 120;
设置为120秒,只有当joiner尝试连接了所有的donor,但是没有合适的,并且没有剩余的,那么按照参数来sleep。
17.4.3 网络隔离
17.4.3.1 发现网络隔离
Replication_group_members包含了当前view里面的所有服务的和服务的状态。大多数情况下服务运行是正常的,所以这个表对所有服务来说是一致的。如果出现网络隔离,那么quorum就会丢失,然后表上回显示UNREACHABLE。
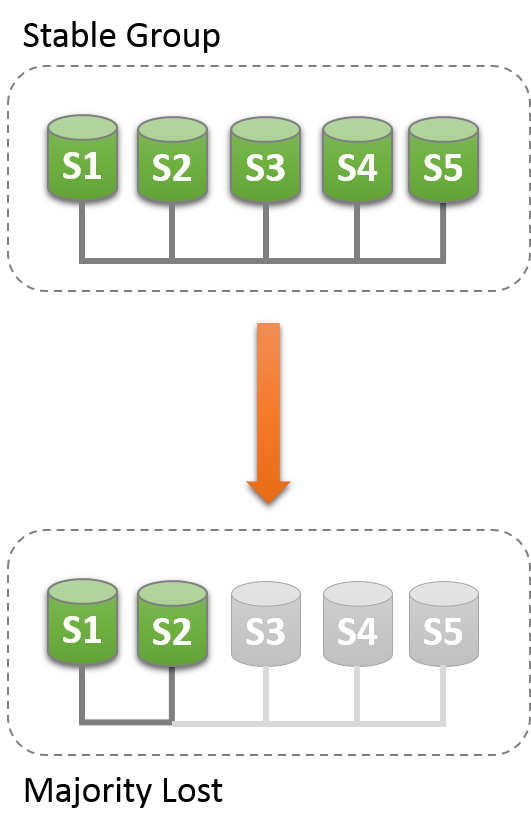
比如有个场景有5个服务,然后因为事故,其中3个丢失:
· Server s1 with member identifier 199b2df7-4aaf-11e6-bb16-28b2bd168d07
· Server s2 with member identifier 199bb88e-4aaf-11e6-babe-28b2bd168d07
· Server s3 with member identifier 1999b9fb-4aaf-11e6-bb54-28b2bd168d07
· Server s4 with member identifier 19ab72fc-4aaf-11e6-bb51-28b2bd168d07
· Server s5 with member identifier 19b33846-4aaf-11e6-ba81-28b2bd168d07
丢失之前的状态:
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | 127.0.0.1 | 13002 | ONLINE |
| group_replication_applier | 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | 127.0.0.1 | 13001 | ONLINE |
| group_replication_applier | 199bb88e-4aaf-11e6-babe-28b2bd168d07 | 127.0.0.1 | 13000 | ONLINE |
| group_replication_applier | 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | 127.0.0.1 | 13003 | ONLINE |
| group_replication_applier | 19b33846-4aaf-11e6-ba81-28b2bd168d07 | 127.0.0.1 | 13004 | ONLINE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
5 rows in set (0,00 sec)
然后因为事故quorum丢失:
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | 127.0.0.1 | 13002 | UNREACHABLE |
| group_replication_applier | 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | 127.0.0.1 | 13001 | ONLINE |
| group_replication_applier | 199bb88e-4aaf-11e6-babe-28b2bd168d07 | 127.0.0.1 | 13000 | ONLINE |
| group_replication_applier | 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | 127.0.0.1 | 13003 | UNREACHABLE |
| group_replication_applier | 19b33846-4aaf-11e6-ba81-28b2bd168d07 | 127.0.0.1 | 13004 | UNREACHABLE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
5 rows in set (0,00 sec)
因为大多数已经丢失,所以Group就无法继续运行。为了让Group恢复运行需要重置group成员列表。或者关闭s1,s2的group replication,然后解决s3,s4,s5出现的问题,然后重启group replication。
17.4.3.2 Unblocking a Partition
Group Replication可以强制成员配置来重置。一下场景只有S1,S2,就可以强制成员列表,通过设置变量group_replication_force_members变量。
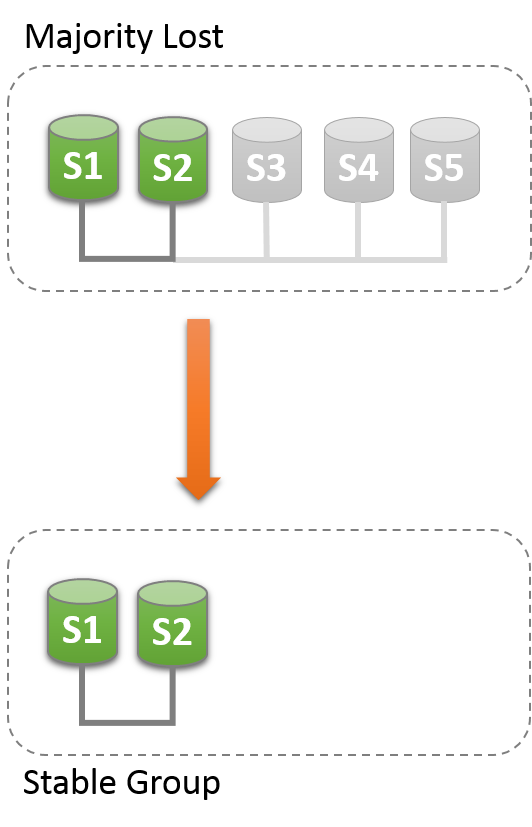
假设S1,S2存活,其他都非预期退出group,想要强制成员只有S1,S2。
首先查看S1上的成员列表:
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | 127.0.0.1 | 13002 | UNREACHABLE |
| group_replication_applier | 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | 127.0.0.1 | 13001 | ONLINE |
| group_replication_applier | 199bb88e-4aaf-11e6-babe-28b2bd168d07 | 127.0.0.1 | 13000 | ONLINE |
| group_replication_applier | 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | 127.0.0.1 | 13003 | UNREACHABLE |
| group_replication_applier | 19b33846-4aaf-11e6-ba81-28b2bd168d07 | 127.0.0.1 | 13004 | UNREACHABLE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
5 rows in set (0,00 sec)
然后从S1,S2中获取@@group_replication_local_address,然后设置到变量中
mysql> SELECT @@group_replication_local_address;
+-----------------------------------+
| @@group_replication_local_address |
+-----------------------------------+
| 127.0.0.1:10000 |
+-----------------------------------+
1 row in set (0,00 sec)
mysql> SELECT @@group_replication_local_address;
+-----------------------------------+
| @@group_replication_local_address |
+-----------------------------------+
| 127.0.0.1:10001 |
+-----------------------------------+
1 row in set (0,00 sec)
mysql> SET GLOBAL group_replication_force_members="127.0.0.1:10000,127.0.0.1:10001";
Query OK, 0 rows affected (7,13 sec)
检查members
mysql> select * from performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | b5ffe505-4ab6-11e6-b04b-28b2bd168d07 | 127.0.0.1 | 13000 | ONLINE |
| group_replication_applier | b60907e7-4ab6-11e6-afb7-28b2bd168d07 | 127.0.0.1 | 13001 | ONLINE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
2 rows in set (0,00 sec)
当强制一个新的成员配置,要保证其他服务是停止了。在场景中S3,S4,S5如果不是真的unreachable其实是online的,那么他们自己就会已形成一个功能分区。这样强制成员可能会造成主分隔的情况。因此保证其他服务是关闭的很重要,如果没有,那么就手工关闭他们。
17.5 Group Replication安全性
17.5.1 Ip地址白名单
IP白名单,是允许其他程序或者服务连接group Replication的设置。默认是内网,show的时候显示AUTOMATIC,参数是grou_replication_ip_whitelist。若s1设置了,s2连接的时候,会先去查看白名单,然后再考虑是否接受s2的连接。
默认配置显示AUTOMATIC,可以通过错误日志查看:
2016-07-07T06:40:49.320686Z 4 [Note] Plugin group_replication reported: 'Added automatically \\
IP ranges 10.120.40.237/18,10.178.59.44/22,127.0.0.1/8 to the whitelist'
为了更加安全可以手动设置这个白名单
mysql> STOP GROUP_REPLICATION;
mysql> SET GLOBAL group_replication_ip_whitelist="10.120.40.237/18,10.178.59.44/22,127.0.0.1/8";
mysql> START GROUP_REPLICATION;
17.5.2 SSL支持
MySQL Group Replication支持openssl和yassl。Group连接和recovery连接都可以使用ssl。
Recovery配置SSL
Recovery是通过传统的异步复制连接执行的。一旦选择好了donor,就会创建一个异步复制连接。那么需要给用户配置ssl。
donor> SET SQL_LOG_BIN=0;
donor> CREATE USER 'rec_ssl_user'@'%' REQUIRE SSL;
donor> GRANT replication slave ON *.* TO 'rec_ssl_user'@'%';
donor> SET SQL_LOG_BIN=1;
然后配置一些相关参数。
new_member> SET GLOBAL group_replication_recovery_use_ssl=1;
new_member> SET GLOBAL group_replication_recovery_ssl_ca= '.../cacert.pem';
new_member> SET GLOBAL group_replication_recovery_ssl_cert= '.../client-cert.pem';
new_member> SET GLOBAL group_replication_recovery_ssl_key= '.../client-key.pem';
然后在change master to 连接过去。
new_member> CHANGE MASTER TO MASTER_USER="rec_ssl_user" FOR CHANNEL "group_replication_recovery";
new_member> START GROUP_REPLICATION;
Group连接配置SSL
Group 连接配置ssl和服务有关,如果服务支持,那么group也就支持,那么配置服务的SSL需要配置这些参数:
[mysqld]
ssl_ca = "cacert.pem"
ssl_capath = "/.../ca_directory"
ssl_cert = "server-cert.pem"
ssl_cipher = "DHE-RSA-AEs256-SHA"
ssl_crl = "crl-server-revoked.crl"
ssl_crlpath = "/.../crl_directory"
ssl_key = "server-key.pem"
group_replication_ssl_mode= REQUIRED
17.6 Group Replication变量
略,自己看:
https://dev.mysql.com/doc/refman/5.7/en/group-replication-options.html
17.7 前提和限制
17.7.1 Group Replication前提
基础要求:
1. innodb存储引擎:因为如果出现冲突需要回滚,那么存储引擎要支持事务。
2. 主键,因为判断是否冲突需要用到主键
3. IPv4,目前只支持ipv4
4. 网络性能,因为group Replication是一个集群所以对网络带宽要求可能比较高。
服务参数设置:
1. 启动binlog,因为group Replication还是依赖binlog进行数据同步的。
2. Slave update logs,因为新加入的服务需要recovery,需要用到binlog,如果选中了donor是slave,那么就有用了
3. 启动GTID,group Replication的event应用都是依赖GTID的。
4. 复制信息存储方式,复制信息都要求保存在表上。
5. Transaction write set extraction,写事务提取,这里都用XXHASH64.
6. 多线程,group成员可以开多线程 applier。需要设置3个参数
slave-parallel-workers=N:线程数量
slave-preserve-commit-order=1:因为group Replication要保证成员事务提交顺序要和primary一样,因此需要设置。
slave-parallel-type=logical_clock表示可以并发的事务
17.7.2 Group Replication限制
Group Replication有这么一些限制:
1. replication event checksum,因为涉及的问题,group replication不能使用event checksum
2. gap lock,检验进程不使用gap lock,因为才能更好的检查冲突问题。
3. 表锁和命名锁,检验进程不使用表锁和命名锁。
4. SERIALIZABLE隔离级别,在多主group replication默认是不支持的,如果设置了就会不让提交。
5. 并发DDL和DML,多主DDL和DML在不同服务器并发是不支持的。这样不同服务执行相同object的DDL和DML会引起冲突。
6. 外键和级联,多主模式下不支持多级别的外键依赖,特别是定义了级联的外键。因为外键约束,多主情况下,外键的级联操作会造成无法诊断的冲突问题,所以建议使用group_replication_enforce_update_everywhere_checks=ON来解决不可发现的冲突问题。
7. 大事务,因为事务太大,会导致无法在成员间5秒钟内复制完,那么就会发生错误。
17.8 FAQ
https://dev.mysql.com/doc/refman/5.7/en/group-replication-frequently-asked-questions.html
17.9 Group Replication技术细节
17.9.1 Group Replication插件的结构
Group Replication是MySQL的一个插件,基于binary log,行模式,GTID。集成了当前的MySQL平台,比如performance schema,Group Replication结构如图:
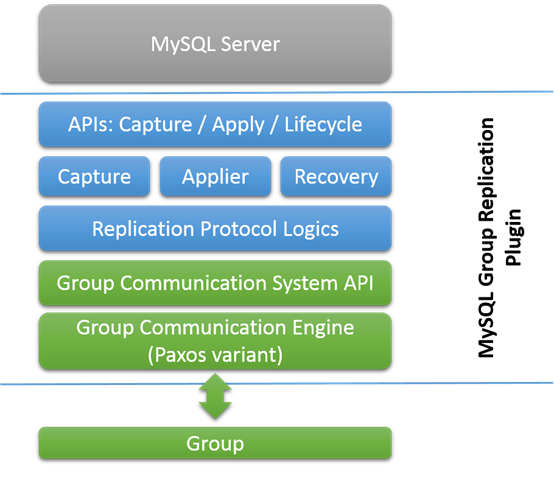
从图的上面开始,
Capture组件:用来跟着事务执行的上下文
Applier组件:负责执行远程事务
Recovery组件:当服务join到group的时候,用来恢复数据,并且捕获错误。
下面是复制协议逻辑,处理冲突诊断,接受和传播事务到group。
下面绿色是为上面高级别的API提供底层服务。
17.9.2 The Group
MySQL Group Replication,是一批服务组成。有一个uuid的group名。Group是动态的服务可以离开或者加入。Group会服务加入或者离开的时候调整自己。
如果一个服务加入group,会自动从已经存在的服务上获取数据,追上来。这个同步状态是异步的。如果服务离开group,剩下的服务会发现并且重新配置group。
17.9.3 Data Manipulation Statements
在多主下,任何服务都可以插入数据,任何服务在没有协调下都可以运行事务,但是事务提交需要服务协调并决定事务去留。
协调的目的:
1. 检查事务是否应该被提交
2. 传播事务到其他服务并且应用
事务传播是原子性的,要不全部接受,要不全部不接受。若接受就会以相同的顺序接受事务。冲突发现是通过比较和检查事务的写入集实现。如果出现冲突解决方式是保留第一个提交的事务。
17.9.4 Data Definition Statements
DDL语句,目前不支持原子性或者事务性,因此一旦执行,如果不要了不能回滚。因此DDL的语句执行,包含了这个object的数据的修改要在同一个服务上。单主的group Replication是不会有问题的。
MySQL DDL是不支持事务的。服务执行提交没有group的同意的,因此必须把DDL和包含这个object的DML放在一个服务上运行。
17.9.5 分布式恢复
17.5.9.1 Group Replication基础
Group Replication分布式recovery过程,用来同步joiner和donor之间的数据。大概分为2个步骤:
阶段1
这个阶段joiner选择一个group中的成员作为donor,然后donor把joiner没有的数据同步给joiner,这个同步是异步的。主要是通过binary log进行同步数据。
在binary log同步的时候,joiner会缓存group交换的事务。当从donor的binary log运行完之后,进入第二阶段
阶段2
这个阶段joiner,应用之前缓存起来的事务,应用完成之后,定义为online
Resilience
在阶段1,Recovery过程碰到donor出现错误的时候,会切换到另外一个新的donor。
17.5.9.2 Recovering From a Point-in-time
使用donor把 joiner同步到指定的点,donor和joiner使用GTID机制。但是单单GTID是不够的,因为GTID只能提供joiner丢失哪个事务。不能用来标记,要更新到哪个点,也不能用来传输认证信息。
View 和 View Change
View:当前可用服务的列表
View change:表示发生修改的发生,比如join或者leave
View标识符:是view的唯一标识,在view修改的时候生成。
在group交互层,view修改会有各自的view id来区别修改view的修改前和修改后。
View标识符由2个部分组成:1.随机数,由group生成,2.自增。Group生成的随机数,会一直保留知道group消亡,第二部分在view每次修改的时候都会自增。
使用2个部分来表示view标识符,主要是为了表示清楚group修改,实际上,只使用自增会导致view标识符和之前的group重复,破坏了binary log数据的唯一性。
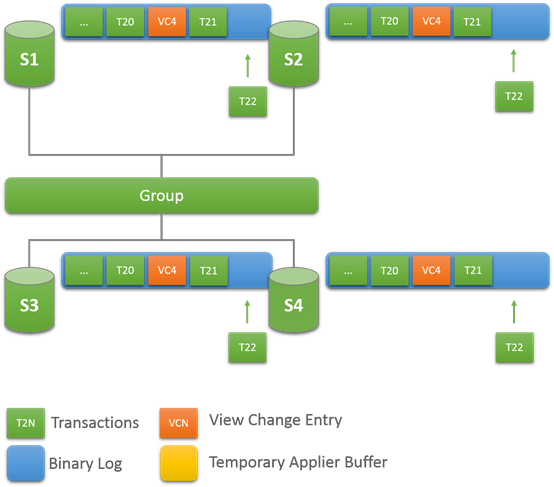
17.5.9.3 View Change
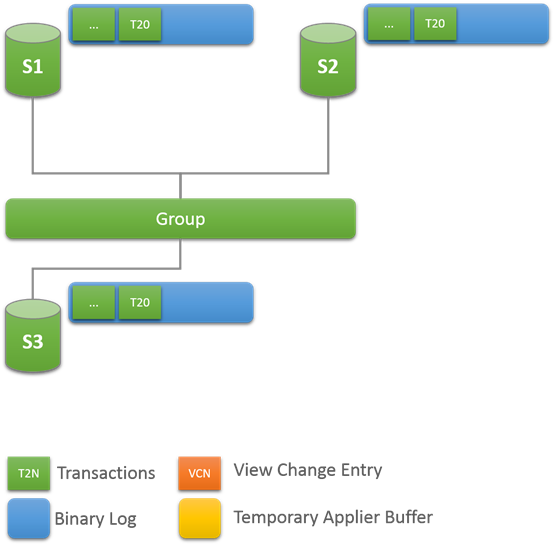
开始:稳定的Group
开始是一组稳定的online的group,每个服务都是online的。
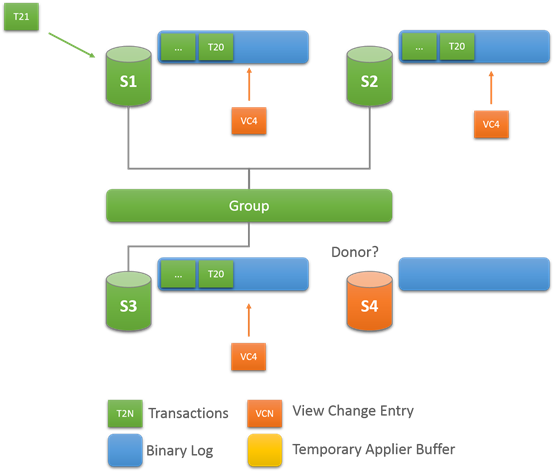
View Change:成员加入
当有一个新的成员加入,view change 开始执行,每个online服务队会队列一个view change log event。为啥要队列,因为有其他事物可能也在队列上,并且是属于老的view的。
不单单如此,joiner会选择一个group 里面的online成员作为donor,来同步数据.
开始传输:Catching Up
一旦joiner选择了一个donor,就会建立一个异步的复制连接,用来同步binlog数据。直到线程处理到view change log event。
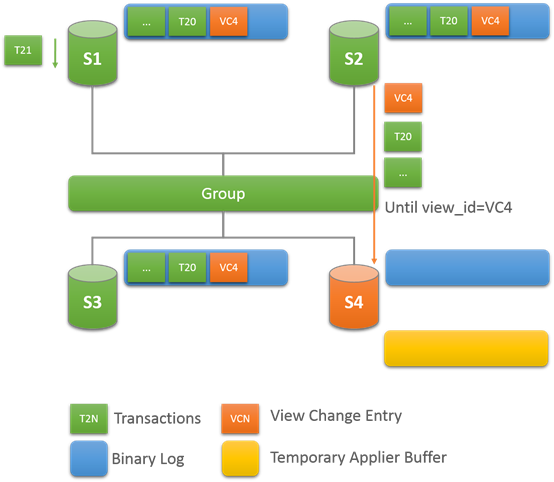
View id会在同时传输到所有的成员,joiner知道到那个view id复制要他停止。View id可以明确,哪些数据属于哪个view。当joiner同步donor的数据的时候也会缓存,过来的事务。同步停止后,会应用这些事务。
最后:Caught Up
当joiner发现view change log event是预期的view id,连接到donor会被中断,并开始应用缓存的事务。尽管在binlog中只是一个标记,表示view修改。也能用来确认新成员加入到group。如果没有,joiner就没有足够的信息来确定,加入之后的事务。
Catch up的时间,由事务生成的速度决定。在应用到时候是不会影响其他成员的事务。
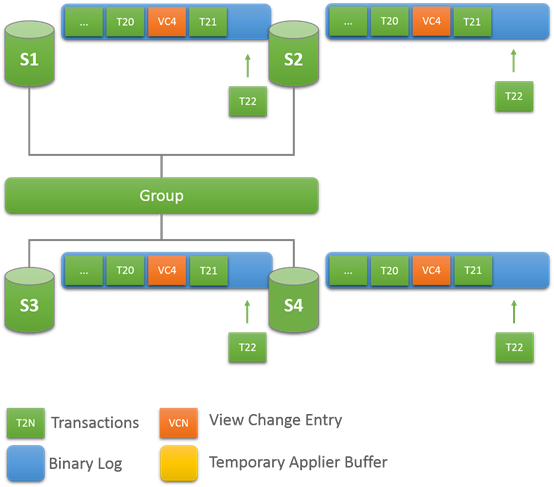
17.9.5.4 使用建议和分布式Recovery的限制
分布式Recovery有一些限制,就是因为是基于异步复制的,因此如果当使用较老的备份或者镜像来做新的成员,就会导致阶段1的时间会很长。因此建议使用较新的备份和镜像,减少阶段1的时间。
17.9.6 可见性
https://dev.mysql.com/doc/refman/5.7/en/group-replication-observability.html
17.9.7 Group Replication性能
17.9.7.1 调优Group交互线程
Group交互线程GCT,是循环运行的。FCT接受来自group和插件的消息,控制quorum和错误发现,发送一些keep alive消息,并且处理进出的事务。GCT等待incoming消息队列。当没有消失的时候,GCT会等待,让GCT在进入sleep,多自旋一会儿可能在某些case会更好些。因为sleep会切出cpu。可以通过参数来设置自旋的时间:
mysql> SET GLOBAL group_replication_poll_spin_loops= 10000;
17.9.7.2 消息压缩
当出现网络带宽的瓶颈,消息压缩在group交互层可以提供30-40%的吞吐量提升。
TCP是点对点的,当有N个连接,那么就要发N次信息。因为binary log量大,压缩率也很高,因此对大事务来说是一个强制的特性。
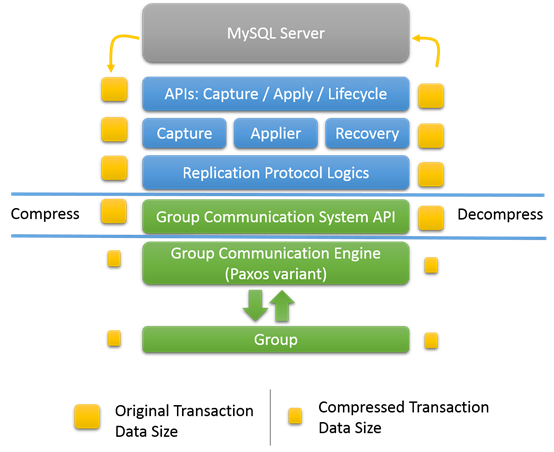
压缩发生在group交互引擎层,在数据被GCT处理前,所以他的上下文是mysql用户会话线程。压缩根据阀值来配置,默认都是压缩的。也没有要求group中所有的成员都必须启动压缩才能使用。当收到一个消息的时候,成员检查消息头,看看是不是压缩的,如果是那么进行解压。
压缩算法使用LZ4。默认压缩阀值是1000000字节。压缩阀值可以通过参数设置,一旦失误超过这个阀值就会被压缩。
STOP GROUP_REPLICATION;
SET GLOBAL group_replication_compression_threshold= 2097152;
START GROUP_REPLICATION;
这里压缩阀值是2MB,如果事务复制的消息大于2MB,就会压缩。把参数设置为0来取消压缩。
17.9.7.3 流量控制
https://dev.mysql.com/doc/refman/5.7/en/group-replication-flow-control.html

