信息收集
域名(子域名)信息
Whois查询根据已知的域名反查,分析出此域名的注册人、公司地址、电话、邮箱、姓名等- 子域名信息收集
- subDomainsBrute
- layer
- 使用谷歌、百度等搜索引擎使用site:baidu.com等语法进行检索,查看其子域名信息。
- https://fofa.so/ 域名检索
- https://www.zoomeye.org/ 域名检索
- https://www.shodan.io/ 域名检索
- https://crt.sh/ 安全证书检索
- https://searchdns.netcraft.com/ 域名检索
- https://www.yougetsignal.com/tools/web-sites-on-web-server/ 对域名进行IP地址及同网站域名查询
- https://www.webscan.cc/ 同段IP域名信息收集
- https://www.aizhan.com/
- http://seo.chinaz.com/
- https://x.threatbook.cn/
- https://site.ip138.com/
敏感目录
收集方向
- robotx.txt (禁止爬虫的敏感目录)
- 后台目录
- 安装包
- 上传目录
- MySQL管理接口
- 安装页面
- 编辑器
- IIS短文件
常用工具
- 字典爆破
- 御剑
- dirbuster
- wwwscan
- IIS_shortname_Scanner
- 蜘蛛爬行
- 爬行菜刀
- Webrobot
- burpsuite
旁站C段
- 旁站: 同服务器其他站点
- C段:同一网段其他服务器
收集方向:域名、端口、目录
常用工具:
- Web: http://www.5kik.com/c/ 目录扫描工具
- 端口:portscan
整站分析
- 服务器类型
- 服务器平台、版本等
- 网站容器
- IIS、Apache、Nginx、Tomcat等
- 脚本类型
- ASP、PHP、JSP、ASPX等
- 数据库类型
- access
- Sqlserver
- MySQL
- Oracle
- postgresql
- cms: CMS是Content Management System的缩写,意为"内容管理系统"。
- 企业建站:MetIfo(米拓)、蝉知、SiteServer CMS(.net)等
- B2C商城系统:商派shopex、ecshop、hishop、xpshop等;
- 门户:DedeCMS(织梦,PHP+MySQL)、帝国CMS(PHP+MySQQL)、PHPCMS、动易、cmstop、dianCMS等
- 博客:wordpress、Z-Blog等
- 论坛:discuz、phpwind、wecenter
- 问答系统:Tipask、whatsns等
- 知识百科:HDwiki
- B2B门户系统:destoon、B2Bbuilder、友邻B2B等
- 招聘:骑士CMS、PHP云人才管理系统
- 房产:FangCMS等
- 在线教育:kesion(科讯、ASP)、DeuSoho网校
- 电影网站:苹果CMS、ctcms、movcms等
- 小说文学:JIEQI CMS
- waf
- 安全狗、阿里云盾等
搜索引擎搜索语法
Google/百度
allintext: 搜索文本,但不包括网页标题和链接
allinlikns: 搜素链接、不包括文本和标题
related:URL 列出于目录URL地址有关的网页
link:URL 列出到链接到目录URL的网页清单
使用“-”排除结果,例如site:baidu.com –image.baidu.com
intext: 查找网页中含有xx关键字的网站,示例:intext: 后台登录
intitle: 查找某个标题, 示例: intitle: 后台登录 intitle <%eval(
filetype: 查找某个文件类型的文件 示例:数据挖掘 filetype: doc
inurl: 查找url中带有某字段的网站 示例:inurl: php?id=
site: 在某域名中查找信息 示例: site:hao123.com site:hao123.com inurl:php?id
site:.jp inurl:php?id site:.jp inurl:fckeditorshodan
shodan网络搜索引擎偏向网络设备以及服务器的搜索,具体内容可上网查阅,这里给出它的高级搜索语法。
地址:https://www.shodan.io/
搜索语法
hostname: 搜索指定的主机或域名,例如 hostname:”google”
port: 搜索指定的端口或服务,例如 port:”21”
country: 搜索指定的国家,例如 country:”CN”
city: 搜索指定的城市,例如 city:”Hefei”
org: 搜索指定的组织或公司,例如 org:”google”
isp: 搜索指定的ISP供应商,例如 isp:”China Telecom”
product: 搜索指定的操作系统/软件/平台,例如 product:”Apache httpd”
version: 搜索指定的软件版本,例如 version:”1.6.2”
geo: 搜索指定的地理位置,例如 geo:”31.8639, 117.2808”
before/after: 搜索指定收录时间前后的数据,格式为dd-mm-yy,例如 before:”11-11-15”
net: 搜索指定的IP地址或子网,例如 net:”210.45.240.0/24”censys搜索引擎
censys搜索引擎功能与shodan类似,以下几个文档信息。
地址:https://www.censys.io/
搜索语法
默认情况下censys支持全文检索。
23.0.0.0/8 or 8.8.8.0/24 可以使用and or not
80.http.get.status_code: 200 指定状态
80.http.get.status_code:[200 TO 300] 200-300之间的状态码
location.country_code: DE 国家
protocols: (“23/telnet” or “21/ftp”) 协议
tags: scada 标签
80.http.get.headers.server:nginx 服务器类型版本
autonomous_system.description: University 系统描述
正则fofa
FoFa搜索引擎偏向资产搜索。
地址:https://fofa.so
搜索语法
title=”abc” 从标题中搜索abc。例:标题中有北京的网站。
header=”abc” 从http头中搜索abc。例:jboss服务器。
body=”abc” 从html正文中搜索abc。例:正文包含Hacked by。
domain=”qq.com” 搜索根域名带有qq.com的网站。例: 根域名是qq.com的网站。
host=”.gov.cn” 从url中搜索.gov.cn,注意搜索要用host作为名称。
port=”443” 查找对应443端口的资产。例: 查找对应443端口的资产。
ip=”1.1.1.1” 从ip中搜索包含1.1.1.1的网站,注意搜索要用ip作为名称。
protocol=”https” 搜索制定协议类型(在开启端口扫描的情况下有效)。例: 查询https协议资产。
city=”Beijing” 搜索指定城市的资产。例: 搜索指定城市的资产。
region=”Zhejiang” 搜索指定行政区的资产。例: 搜索指定行政区的资产。
country=”CN” 搜索指定国家(编码)的资产。例: 搜索指定国家(编码)的资产。
cert=”google.com” 搜索证书(https或者imaps等)中带有google.com的资产。
高级搜索:
title=”powered by” && title!=discuz
title!=”powered by” && body=discuz
( body=”content=\”WordPress” || (header=”X-Pingback” && header=”/xmlrpc.php” && body=”/wp-includes/“) ) && host=”gov.cn”钟馗之眼
钟馗之眼搜索引擎偏向web应用层面的搜索。
地址:https://www.zoomeye.org/
搜索语法
app:nginx 组件名
ver:1.0 版本
os:windows 操作系统
country:”China” 国家
city:”hangzhou” 城市
port:80 端口
hostname:google 主机名
site:thief.one 网站域名
desc:nmask 描述
keywords:nmask’blog 关键词
service:ftp 服务类型
ip:8.8.8.8 ip地址
cidr:8.8.8.8/24 ip地址段Python URL采集
-
本文Chrome版本是114.0.5735.90,chromedriver版本114.0.5735.90
-
requests==2.31.0
-
selenium==4.9.
requests==2.31.0
selenium==4.9.1
sniffio==1.3.0
sortedcontainers==2.4.0
soupsieve==2.4.1
trio==0.22.0
trio-websocket==0.10.2
urllib3==2.0.2
wsproto==1.2.0下载Python Google chromedriver http://chromedriver.storage.googleapis.com/index.html , 下载和Chrome版本一致的chromedriver,解压文件得到chromedriver.exe放到Python3安装目录下
- 百度URL采集脚本
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import requests
from time import sleep
from urllib import parse
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, compress',
'Accept-Language': 'en-us;q=0.5,en;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
}
search_engines = 'http://www.baidu.com'
query = "Powerd by AspCms2.0"
cache_file = 'd:/url.txt'
def write_url(web_elements):
with open(cache_file, 'a', encoding='utf-8') as fi:
for web_element in web_elements:
t = web_element.find_element(By.CSS_SELECTOR, 'h3').text
h = web_element.find_element(By.CSS_SELECTOR, 'a').get_attribute('href')
baidu_url = requests.get(url=h, headers=headers, allow_redirects=False)
real_url = baidu_url.headers['Location']
print(t)
re_url = parse.urlparse(real_url)
fi.write(re_url.netloc + '\n')
if __name__ == "__main__":
options = webdriver.ChromeOptions()
options.add_argument('--ignore-certificate-errors')
options.add_argument('--incognito')
options.add_argument('--headless')
browser = webdriver.Chrome(options=options)
browser.get(search_engines)
search_bar = browser.find_element(By.NAME, 'wd')
search_bar.clear()
search_bar.send_keys(query)
search_bar.send_keys(Keys.RETURN)
sleep(5)
for page_num in range(10, 1000, 10):
res = browser.find_elements(By.CSS_SELECTOR, '.result.c-container')
print(f"打开第{int(page_num / 10 + 1)}个搜索页面")
write_url(res)
browser.execute_script('window.scrollTo(0, document.body.scrollHeight);')
sleep(5)
page_link = browser.find_element(By.CSS_SELECTOR, f'a[href*="pn={page_num}"]')
page_link.click()
sleep(5)
browser.quit()
服务器信息收集
- 服务:web/ftp/ssh/mail/mysql/rdp等
- 服务版本:漏洞相关信息收集
- 系统版本信息收集
信息收集工具:ScanPort、nmap
后台查找方法
弱口令默认后台:admin,admin/login.asp,manage,login.asp等等常见后台
查看网页的链接:一般来说,网站的主页有管理登陆类似的东西,有些可能被管理员删掉
查看网站图片的属性
查看网站使用的管理系统,从而确定后台
用工具查找:wwwscan,intellitamper,御剑
robots.txt的帮助:robots.txt文件告诉蜘蛛程序在服务器上什么样的文件可以被查看
GoogleHacker
查看网站使用的编辑器是否有默认后台
短文件利用
sqlmap --sql-shell load_file('d:/wwroot/index.php'); # 通过源代码找到注入漏洞
intitle:<%eval request(CDN绕过
如何判断网站有没有使用CDN(如:使用站长工具超级ping)
1.查找二级域名
2.让服务器主动给你发包(邮件)
3.敏感文件泄露
4.查询域名历史解析ip,最初始的IP可能是源站
访问绕过cdn方法,找到真实IP然后修改hosts文件
Chome常用插件
HackBar
Charset
Cookie Hacker
Proxy SwitchySharp
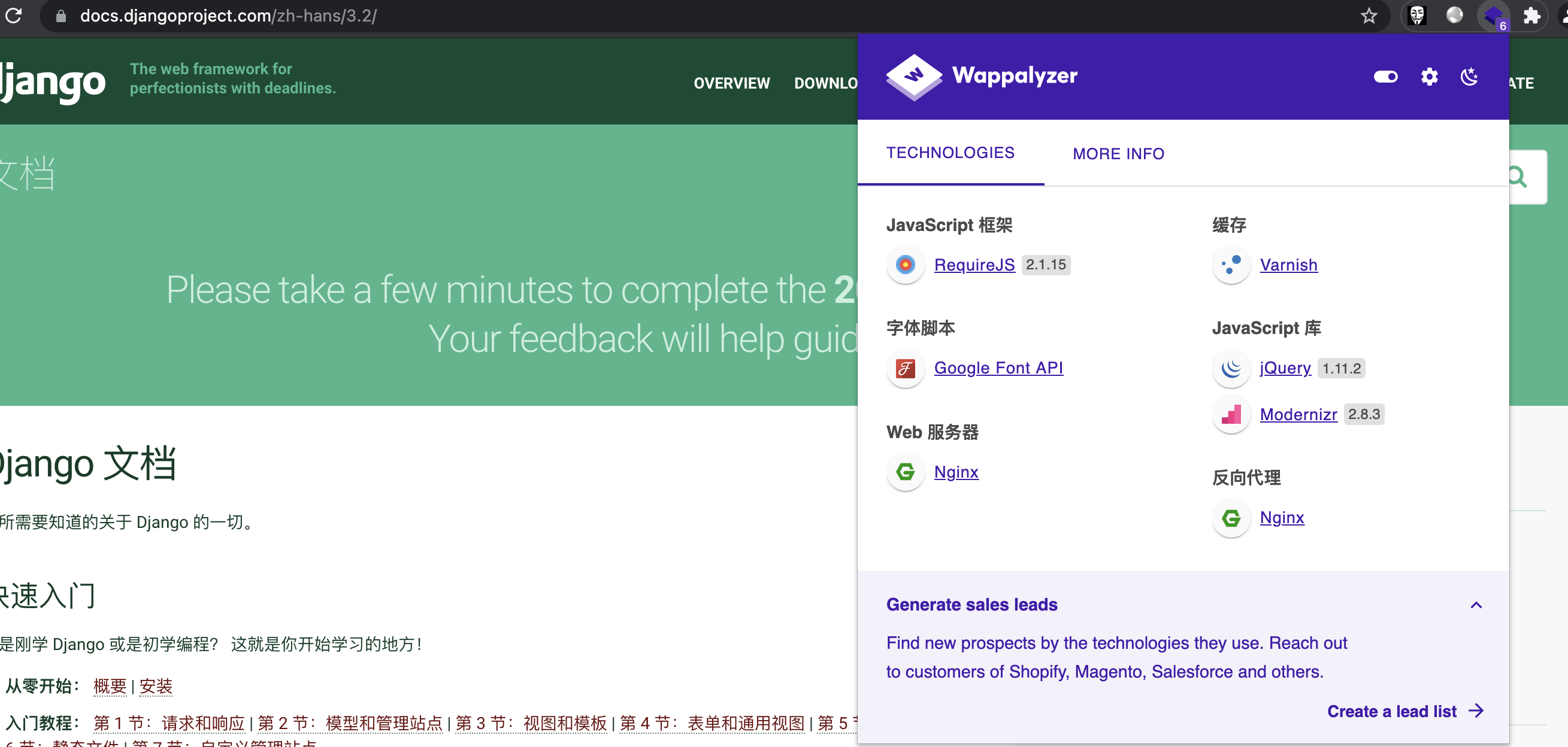
Wappalyzer
https://www.wappalyzer.com/