Compute Resource Consolidation Pattern 计算资源整合模式
Consolidate multiple tasks or operations into a single computational unit. This pattern can increase compute resource utilization, and reduce the costs and management overhead associated with performing compute processing in cloud-hosted applications.
合并多个任务或操作成一个单一的计算单元。这种模式可以提高计算资源的利用率,并降低与云托管的应用程序进行计算处理相关的成本和管理开销。
Context and Problem 背景与问题
A cloud application frequently implements a variety of operations. In some solutions it may make sense initially to follow the design principle of separation of concerns, and divide these operations into discrete computational units that are hosted and deployed individually (for example, as separate roles in a Microsoft Azure Cloud Service, separate Azure Web Sites, or separate Virtual Machines). However, although this strategy can help to simplify the logical design of the solution, deploying a large number of computational units as part of the same application can increase runtime hosting costs and make management of the system more complex.
云应用程序频繁地实现各种操作。在一些解决方案可能是有意义最初遵循的关注点分离的设计原则,并划分这些操作成离散的计算单位并进行托管和独立部署(例如,如在微软Azure云服务,独立Azure网站,独立角色离散计算单元,或单独的虚拟机)。然而,尽管这种策略可以帮助简化解决方案的逻辑设计,可部署大量计算单元在同一应用下提高运行时的托管费用,使系统的管理更加复杂。
As an example, Figure 1 shows the simplified structure of a cloud-hosted solution that is implemented using more than one computational unit. Each computational unit runs in its own virtual environment. Each function has been implemented as a separate task (labeled Task A through Task E) running in its own computational unit.
作为一个例子,图1示出了使用多个计算单元实施了云托管解决方案的简化的结构。每个计算单元在自己的虚拟环境中运行。每个功能已被实现为自己的计算单元上运行一个单独的任务(通过任务E标记任务A)。
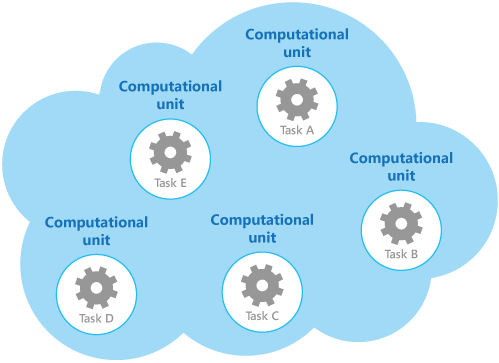
Figure 1 - Running tasks in a cloud environment by using a set of dedicated computational units
图1 - 通过使用一组专用的计算单元运行在云环境中的任务
Each computational unit consumes chargeable resources, even when it is idle or lightly used. Therefore, this approach may not always be the most cost-effective solution.
每个计算单元消耗的资源收费,即使是空闲或轻易使用。因此,这种方法可能不总是最有成本效益的解决方案。
Solution 解决方案
To help reduce costs, increase utilization, improve communication speed, and ease the management effort it may be possible to consolidate multiple tasks or operations into a single computational unit.
为了帮助降低成本,提高利用率,提高通信速度,减轻管理工作有可能将多个任务或操作固定成一个单一的计算单元。
Tasks can be grouped according to a variety of criteria based on the features provided by the environment, and the costs associated with these features. A common approach is to look for tasks that have a similar profile concerning their scalability, lifetime, and processing requirements. Grouping these items together allows them to scale as a unit. The elasticity provided by many cloud environments enables additional instances of a computational unit to be started and stopped according to the workload. For example, Azure provides autoscaling that you can apply to roles in a Cloud Service, Web Sites, and Virtual Machines. For more information, see Autoscaling Guidance.
任务可以根据各种基于由环境提供的功能,以及与这些功能相关的成本标准进行分组。一种常见的方法是寻找有关于他们的可扩展性,寿命和加工要求具有相似的任务。分组这些产品一起使它们能够扩展为一个单元。由许多云环境所提供的弹性使一计算单元的其他实例,以根据业务负载来启动和停止。例如,Azure提供了自动缩放,可以适用于云服务的角色、网站和虚拟机。欲了解更多信息,请参阅自动缩放指导。
As a counter example to show how scalability can be used to determine which operations should probably not be grouped together, consider the following two tasks:
作为抗衡例子来说明的可扩展性可以如何被用来确定哪些操作可能不应该被分组在一起,考虑以下两个任务:
- Task 1 polls for infrequent, time-insensitive messages sent to a queue.
- Task 2 handles high-volume bursts of network traffic.
•任务1轮询发送到队列的情况较少,时间不敏感的消息。
•任务2处理高容量爆发的网络流量。
The second task requires elasticity that may involve starting and stopping a large number of instances of the computational unit. Applying the same scaling to the first task would simply result in more tasks listening for infrequent messages on the same queue, and is a waste of resources.
第二任务要求的弹性可能涉及在启动和停止的大量的计算单元的实例。应用相同的缩放到第一任务只会导致更多的任务上监听同一队列不频繁的消息,并且是一种资源的浪费。
In many cloud environments it is possible to specify the resources available to a computational unit in terms of the number of CPU cores, memory, disk space, and so on. Generally, the more resources specified, the greater the cost. For financial efficiency, it is important to maximize the amount of work an expensive computational unit performs, and not let it become inactive for an extended period.
If there are tasks that require a great deal of CPU power in short bursts, consider consolidating these into a single computational unit that provides the necessary power. However, it is important to balance this need to keep expensive resources busy against the contention that could occur if they are over-stressed. Long-running, compute-intensive tasks should probably not share the same computational unit, for example.
Issues and Considerations 问题和注意事项
Consider the following points when implementing this pattern:
实施这一模式时,请考虑以下几点:
- Scalability and Elasticity. Many cloud solutions implement scalability and elasticity at the level of the computational unit by starting and stopping instances of units. Avoid grouping tasks that have conflicting scalability requirements in the same computational unit.
- 可扩展性和弹性。许多云解决方案通过启动和停止的单元实例实现可扩展性和弹性的计算单元的水平。避免分组在同一个计算单元相互矛盾的可扩展性要求的任务。
- Lifetime. The cloud infrastructure may periodically recycle the virtual environment that hosts a computational unit. When executing many long-running tasks inside a computational unit, it may be necessary to configure the unit to prevent it from being recycled until these tasks have finished. Alternatively, design the tasks by using a check-pointing approach that enables them to stop cleanly, and continue at the point at which they were interrupted when the computational unit is restarted.
- 生命周期。云基础设施会定期回收承载在虚拟环境的计算单元。当执行许多长期运行的任务在一个计算单元内,可能需要配置设备,以防止它被回收,直到这些任务已经完成。另外,设计这些任务通过使用检查点的方法,使他们停止干净,并继续中断的点在该计算单元重新启动的时候。
- Release Cadence. If the implementation or configuration of a task changes frequently, it may be necessary to stop the computational unit hosting the updated code, reconfigure and redeploy the unit, and then restart it. This process will also require that all other tasks within the same computational unit are stopped, redeployed, and restarted.
- 释放节奏。如果一个任务的执行或配置频繁变化,可能有必要停止计算单元承载更新的代码、配置和部署的单元,然后重新启动它。这个过程也将需要相同的计算单元中的所有其他任务被停止,部署和重新启动。
- Security. Tasks in the same computational unit may share the same security context and be able to access the same resources. There must be a high degree of trust between the tasks, and confidence that that one task is not going to corrupt or adversely affect another. Additionally, increasing the number of tasks running in a computational unit may increase the attack surface of the computational unit; each task is only as secure as the one with the most vulnerabilities.
- 安全。在相同的计算单元的任务可以共享相同的安全上下文,并能够访问相同的资源。必须有高度的可信性在任务之间,一个任务是不会损坏或产生不利影响另一个。此外,增加在一个计算单元的任务数目可能增加计算单元的攻击性;每个任务只是与大多数漏洞一个尽可能安全的。
- Fault Tolerance. If one task in a computational unit fails or behaves abnormally, it can affect the other tasks running within the same unit. For example, if one task fails to start correctly it may cause the entire startup logic for the computational unit to fail, and prevent other tasks in the same unit from running.
- 容错能力。如果一个计算单元中的某个任务失败或异常行为,它可以影响运行在同一单位内的其他任务。例如,如果一个任务无法正常启动它可能导致的整个计算单元的启动逻辑失败,且防止运行中的相同单位的其他任务。
- Contention. Avoid introducing contention between tasks that compete for resources in the same computational unit. Ideally, tasks that share the same computational unit should exhibit different resource utilization characteristics. For example, two compute-intensive tasks should probably not reside in the same computational unit, and neither should two tasks that consume large amounts of memory. However, mixing a compute intensive task with a task that requires a large amount of memory may be a viable combination.
- 竞争。避免引入竞争同一计算单元的任务之间争夺资源。理想情况下,共享相同的计算单元的任务应该表现出不同的资源利用特性。例如,两个计算密集型任务可能不应该驻留在相同的计算单位,,也不应该这个两个任务占用大量内存。然而,混合计算密集型任务需要大量内存的任务可能是一个可行的组合。
- Note:注意
- You should consider consolidating compute resources only for a system that has been in production for a period of time so that operators and developers can monitor the system and create a heat map that identifies how each task utilizes differing resources. This map can be used to determine which tasks are good candidates for sharing compute resources.
-
你应该考虑巩固只对已经生产了一段时间以便运营商和开发者可以监视系统和创建标识每个任务如何利用不同资源的热图系统的计算资源。这张地图可以用于确定哪些任务很适合于共享计算资源。
- Complexity.Combining multiple tasks into a single computational unit adds complexity to the code in the unit, possibly making it more difficult to test, debug, and maintain.
- 复杂性。多个任务合并成一个单一的计算单元中使单元增加了代码的复杂性,可能使得更难以进行测试,调试和维护。
- Stable Logical Architecture. Design and implement the code in each task so that it should not need to change, even if the physical environment in which task runs does change.
- 稳定的逻辑架构。设计并实现了每个任务中的代码,以便它不应该需要改变,即使物理环境中运行任务确实发生了改变。
- Other Strategies. Consolidating compute resources is only one way to help reduce costs associated with running multiple tasks concurrently. It requires careful planning and monitoring to ensure that it remains an effective approach. Other strategies may be more appropriate, depending on the nature of the work being performed and the location of the users on whose behalf these tasks are running. For example, functional decomposition of the workload (as described by the Compute Partitioning Guidance) may be a better option.
- 其他策略。整合计算资源是唯一一家以帮助减少同时运行多个任务相关的成本的方法。这需要仔细规划和监测,以确保它仍然是一个有效的办法。其他策略可能更适合,取决于正在执行的工作的性质和所代表这些任务正在运行的用户的位置。例如,工作量(如由计算分区指导所述)的功能分解可能是一个更好的选择。
When to Use this Pattern 什么时候使用本模式
Use this pattern for tasks that are not cost effective if they run in their own computational units. If a task spends much of its time idle, running this task in a dedicated unit can be expensive.
使用这种模式不是成本有效如果他们运行在自己计算单位的任务。如果一项任务花了很多空闲时间,运行此任务在一个专门的单元是昂贵的。
This pattern might not be suitable for tasks that perform critical fault-tolerant operations, or tasks that process highly-sensitive or private data and require their own security context. These tasks should run in their own isolated environment, in a separate computational unit.
这种模式可能不适合于执行关键容错操作该处理高度敏感的或私人数据,并要求他们自己的安全上下文的任务。这些任务应该在他们自己的分离的环境中运行,在一个单独的计算单元。
Example 例子
When building a cloud service on Azure, it’s possible to consolidate the processing performed by multiple tasks into a single role. Typically this is a worker role that performs background or asynchronous processing tasks.
当在Azure上构建一个云服务,它可能合并多任务的处理成一个单一的角色。通常,这是执行的背景或异步处理任务的辅助角色。
Note:
In some cases it may be possible to include background or asynchronous processing tasks in the web role. This technique can help to reduce costs and simplify deployment, although it can impact the scalability and responsiveness of the public-facing interface provided by the web role. The article Combining Multiple Azure Worker Roles into an Azure Web Role contains a detailed description of implementing background or asynchronous processing tasks in a web role.
在某些情况下,它可能在 web 角色中包括背景或异步处理任务。这种技术可以帮助降低成本和简化部署,虽然它可以影响的可伸缩性和响应能力提供 web 角色的面向公众的界面。文章《结合多个 Azure 工作者角色到 Azure Web 角色》包含 web 角色实施背景或异步处理任务的详细的说明。
The role is responsible for starting and stopping the tasks. When the Azure fabric controller loads a role, it raises the Start event for the role. You can override the OnStart method of the WebRole or WorkerRole class to handle this event, perhaps to initialize the data and other resources on which the tasks in this method depend.
角色是负责启动和停止的任务。当Azure结构控制器加载一个角色,它提出了该角色的Start事件。您可以覆盖WebRole或WorkerRole类的OnStart方法来处理这个事件,也许是初始化数据和其他资源,在这种方法的任务依赖。
When the OnStart method completes, the role can start responding to requests. You can find more information and guidance about using the OnStart and Run methods in a role in theApplication Startup Processes section in the patterns & practices guide Moving Applications to the Cloud.
当OnStart方法完成后,角色就可以开始响应请求。你可以找到更多的信息和有关使用在应用程序启动一个角色的OnStart和Run方法指导流程的模式与实践指南移动应用程序到云部分。
Note:注意:
Keep the code in the OnStart method as concise as possible. Azure does not impose any limit on the time taken for this method to complete, but the role will not be able to start responding to network requests sent to it until this method completes.
请尽可能保持OnStart方法的代码简洁。 Azure不征收采取这种方法来完成任何时间限制,但角色将不能启动响应,直到这个方法完成发送给它的网络请求。
When the OnStart method has finished, the role executes the Run method. At this point, the fabric controller can start sending requests to the role.
当OnStart方法完成后,角色执行Run方法。在这一点上,结构控制器可以开始将请求发送到角色。
Place the code that actually creates the tasks in the Run method. Note that the Run method effectively defines the lifetime of the role instance. When this method completes, the fabric controller will arrange for the role to be shut down.
在Run方法中设置实际创建任务的代码。注意,Run方法有效地定义角色实例的生命周期。当该方法完成后,结构控制器安排的作用将被关闭。
When a role shuts down or is recycled, the fabric controller prevents any more incoming requests being received from the load balancer and raises the Stop event. You can capture this event by overriding the OnStop method of the role and perform any tidying up required before the role terminates.
当一个角色关闭或回收,结构控制器可以防止从负载平衡器接收任何更多的传入请求并引发Stop事件。您可以通过覆盖角色的OnStop方法捕获这个事件,并执行任何清理行动中的作用终止前必需的。
Note:
Any actions performed in the OnStop method must be completed within five minutes (or 30 seconds if you are using the Azure emulator on a local computer); otherwise the Azure fabric controller assumes that the role has stalled and will force it to stop.
在调用OnStop方法执行的任何动作必须在五分钟(或30秒,如果您使用的是本地计算机上的Azure仿真器)内完成;否则Azure结构控制器假设角色已经停止,并迫使它停下来。
Figure 2 illustrates the lifecycle of a role, and the tasks and resources that it hosts. The tasks are started by the Run method, which then waits for the tasks to complete. The tasks themselves, which implement the business logic of the cloud service, can respond to messages posted to the role through the Azure load balancer.
图2示出了角色的生命周期,并且它承载的任务和资源。启动任务的 Run 方法,然后等待要完成的任务。这实现了云服务的业务逻辑的任务本身,可以通过Azure的负载均衡器发布到角色的消息作出回应。
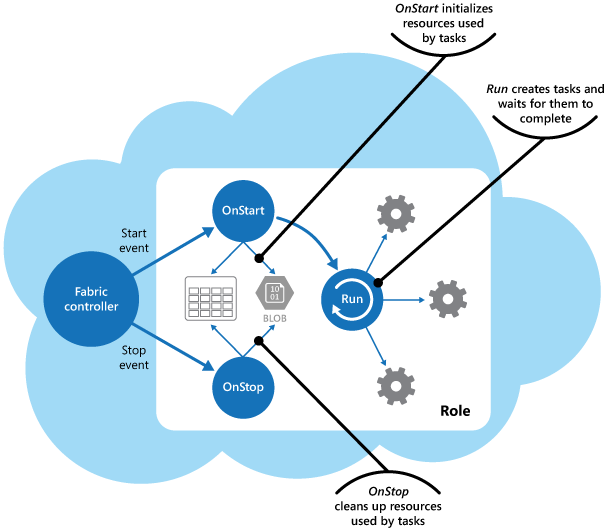
Figure 2 - The lifecycle of tasks and resources in a role in a Azure cloud service
Note:
The ComputeResourceConsolidation.Worker project is part of the ComputeResourceConsolidation solution that is available for download with this guidance.
ComputeResourceConsolidation.Worker 项目是可供下载本指南的ComputeResourceConsolidation 解决方案的一部分。
In the worker role, code that runs when the role is initialized creates the required cancellation token and a list of tasks to run.
辅助角色中,在运行时初始化作用的代码创建需要的取消标记CancellationToken和要运行的任务列表。
public class WorkerRole: RoleEntryPoint { // The cancellation token source used to cooperatively cancel running tasks. private readonly CancellationTokenSource cts = new CancellationTokenSource (); // List of tasks running on the role instance. private readonly List<Task> tasks = new List<Task>(); // List of worker tasks to run on this role. private readonly List<Func<CancellationToken, Task>> workerTasks = new List<Func<CancellationToken, Task>> { MyWorkerTask1, MyWorkerTask2 }; ... }
The MyWorkerTask1 and the MyWorkerTask2 methods are provided to illustrate how to perform different tasks within the same worker role. The following code shows MyWorkerTask1. This is a simple task that sleeps for 30 seconds and then outputs a trace message. It repeats this process indefinitely until the task is cancelled. The code in MyWorkerTask2 is very similar.
提供的MyWorkerTask1和MyWorkerTask2方法来说明如何在同一辅助角色内执行不同的任务。下面的代码显示MyWorkerTask1。这是一个简单的任务,休眠30秒,然后输出一个跟踪消息。直到任务被取消它无限期地重复这个过程。在MyWorkerTask2代码非常相似。
// A sample worker role task. private static async Task MyWorkerTask1(CancellationToken ct) { // Fixed interval to wake up and check for work and/or do work. var interval = TimeSpan.FromSeconds(30); try { while (!ct.IsCancellationRequested) { // Wake up and do some background processing if not canceled. // TASK PROCESSING CODE HERE Trace.TraceInformation("Doing Worker Task 1 Work"); // Go back to sleep for a period of time unless asked to cancel. // Task.Delay will throw an OperationCanceledException when canceled. await Task.Delay(interval, ct); } } catch (OperationCanceledException) { // Expect this exception to be thrown in normal circumstances or check // the cancellation token. If the role instances are shutting down, a // cancellation request will be signaled. Trace.TraceInformation("Stopping service, cancellation requested"); // Re-throw the exception. throw; } }
Note:注意:
The approach shown by the sample code is a common implementation of a background process. In a real world application you can follow this same structure, except that you should place your own processing logic in the body of the loop that waits for the cancellation request.
通过示例代码中显示的方法是一个后台进程的共同实现。在实际应用中,你可以按照同样的结构,但你应该把你自己的处理逻辑在等待取消请求的循环体。
After the worker role has initialized the resources it uses, the Run method starts the two tasks concurrently, as shown here.
随后辅助角色被初始化当它使用资源时,Run方法同时启动两个任务,如下图所示。
... // RoleEntry Run() is called after OnStart(). // Returning from Run() will cause a role instance to recycle. public override void Run() { // Start worker tasks and add them to the task list. foreach (var worker in workerTasks) tasks.Add(worker(cts.Token)); Trace.TraceInformation("Worker host tasks started"); // The assumption is that all tasks should remain running and not return, // similar to role entry Run() behavior. try { Task.WaitAny(tasks.ToArray()); } catch (AggregateException ex) { Trace.TraceError(ex.Message); // If any of the inner exceptions in the aggregate exception // are not cancellation exceptions then re-throw the exception. ex.Handle(innerEx => (innerEx is OperationCanceledException)); } // If there was not a cancellation request, stop all tasks and return from Run() // An alternative to cancelling and returning when a task exits would be to // restart the task. if (!cts.IsCancellationRequested) { Trace.TraceInformation("Task returned without cancellation request"); Stop(TimeSpan.FromMinutes(5)); } } ...
In this example, the Run method waits for tasks to be completed. If a task is canceled, the Run method assumes that the role is being shut down and waits for the remaining tasks to be canceled before finishing (it waits for a maximum of five minutes before terminating). If a task fails due to an expected exception, the Run method cancels the task.
在这个例子中,Run方法等待要完成的任务。如果任务被取消,Run方法假定作用正在关闭,并等待剩余的任务完成(它等待超过五分钟结束之前)之前被取消。如果任务失败,因为预期异常,Run方法取消任务。
Note:
Note that you could implement more comprehensive monitoring and exception handling strategies in the Run method such as restarting tasks that have failed, or including code that enables the role to stop and start individual tasks.
请注意,你可以实现在Run方法更全面的监测和异常处理策略,如重新启动已失败的任务,或者包括代码使角色停止和启动单个任务。
The Stop method shown in the following code is called when the fabric controller shuts down the role instance (it is invoked from the OnStop method). The code stops each task gracefully by cancelling it. If any task takes more than five minutes to complete, the cancellation processing in the Stop method ceases waiting and the role is terminated.
在下面的代码所示的Stop方法当结构控制器关闭角色实例(它是从调用OnStop方法调用)被调用。该代码通过取消其正常停止每项任务。如果任何任务的时间超过五分钟就能完成,在Stop方法取消处理不再等待和角色被终止。
// Stop running tasks and wait for tasks to complete before returning // unless the timeout expires. private void Stop(TimeSpan timeout) { Trace.TraceInformation("Stop called. Canceling tasks."); // Cancel running tasks. cts.Cancel(); Trace.TraceInformation("Waiting for canceled tasks to finish and return"); // Wait for all the tasks to complete before returning. Note that the // emulator currently allows 30 seconds and Azure allows five // minutes for processing to complete. try { Task.WaitAll(tasks.ToArray(), timeout); } catch (AggregateException ex) { Trace.TraceError(ex.Message); // If any of the inner exceptions in the aggregate exception // are not cancellation exceptions then re-throw the exception. ex.Handle(innerEx => (innerEx is OperationCanceledException)); } }
Related Patterns and Guidance 相关模式和指导
The following patterns and guidance may also be relevant when implementing this pattern:
实施这一模式时,以下模式和指导也可能是相关的:
- Autoscaling Guidance. Autoscaling can be used to start and stop instances of service hosting computational resources, depending on the anticipated demand for processing.
- 自动缩放指引。自动缩放可以用来启动和停止服务的实例托管计算资源,这取决于要处理的预期需求。
- Compute Partitioning Guidance. This guidance describes how to allocate the services and components in a cloud service in a way that helps to minimize running costs while maintaining the scalability, performance, availability, and security of the service.
- 计算分区指引。该指导说明如何分配在云服务的服务和组件的方式,有助于最小化运行成本,同时保持了可扩展性,性能,可用性,和服务的安全性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号