
实例描述
配送中心数为 \(1\),客户数 \(k\)为 \(8\),车辆总数 \(m\)为 \(2\);车辆载重皆为 \(8\) 吨;各客户点需求为 \(g(i = 1, 2, ... , 8)\)(单位为吨),已知客户点与配送中心的距离如表 $1 $(其中 \(0\) 表示中心仓库),要求合理安排车辆的运输路线,使总运输里程最小。
客户点与配送中心的距离表
| cij | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 4 | 6 | 7.5 | 9 | 20 | 10 | 16 | 8 |
| 1 | 4 | 0 | 6.5 | 4 | 10 | 5 | 7.5 | 11 | 10 |
| 2 | 6 | 6.5 | 0 | 7.5 | 10 | 10 | 7.5 | 7.5 | 7.5 |
| 3 | 7.5 | 4 | 7.5 | 0 | 10 | 5 | 9 | 9 | 15 |
| 4 | 9 | 10 | 10 | 10 | 0 | 10 | 7.5 | 7.5 | 10 |
| 5 | 20 | 5 | 10 | 5 | 10 | 0 | 7 | 9 | 7.5 |
| 6 | 10 | 7.5 | 7.5 | 9 | 7.5 | 7 | 0 | 7 | 10 |
| 7 | 16 | 11 | 7.5 | 6 | 7.5 | 9 | 7 | 0 | 10 |
| 8 | 8 | 10 | 7.5 | 15 | 10 | 7.5 | 10 | 10 | 0 |
各客户点需求
| g1 | g2 | g3 | g4 | g5 | g6 | g7 | g8 |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 2 | 1 | 4 | 2 | 2 |
运行结果
【Attention】下图并非最优结果,只是为了测试程序的正确性。可以尝试加大次数改良结果。

遗传算法分析
顾名思义,遗传算法是根据遗传规律写的一个算法,但是相比于医学中的遗传来讲,这里讲的遗传算法原理相对简单很多。
遗传算法的核心有三个部分:交叉、变异、轮盘赌。
解决问题的关键和难点就是理解遗传算法的作用:通过改变交叉和变异改变基因特性,导致个体发生改变,从而影响到适应度,最后利用轮盘赌的方式淘汰掉一些个体。
看一下整个程序的运行流程:
上面的数据一用有\(6\)行\(8\)列,我们可以说有\(6\)个个体,每个个体的基因长度是\(8\)。其中\(6\)可以说是种群大小,\(8\)可以说是每个个体的特征数目。到目前为止,我们可以定义一种运算规则了:通过每个个体的特征计算出该个体的样子(\(X\)),然后根据个体的样子,求出该个体的适应度(\(Y\))。
整个流程是:个体特征 --->> 个体 --->> 适应度
交叉过程:[Source Code]
假设个体\(1\)和个体\(2\)发生了交叉,交叉点在第\(7\)列,那么交叉之前,两个个体为:
交叉之后,两个个体为:
可以发现,交叉就是把交叉点后的所有列数据都进行交换(包括交叉点所在的列)。
变异过程:[Source Code]
假设个体\(4\)发生了变异,发生变异的点在第\(3\)点,那么变异之前为:
变异之后,该个体变为:
可以发现,变异就是把变异点所在的位置随机的更换一个数字。
轮盘赌:[Source Code]
轮盘赌的规则很简单:在左轮手枪的六个弹槽中放入一颗或多颗子弹,任意旋转转轮之后,关上转轮。游戏的参加者轮流把手枪对着自己的头,扣动板机;中枪的当然是自动退出,怯场的也为输,坚持到最后的就是胜者。
遗传算法中的轮盘赌和俄罗斯轮盘赌还是有点差距的。这里不以子弹作为筹码,而是以概率作为筹码。
还是以上面的\(6\)个个体作为例子,我们对上面的\(6\)个个体都求出适应度(\(Y\))后,\(6\)个适应度可能是下面的样子:
然后求出总适应度(sum(Y))将每个个体的适应度除以总适应度,得到下面的结果:
然后,对\(6\)个个体适应度从上到下累加求和,得到下面的结果:
对种群的处理已经完成,那么应该淘汰哪部分,是现在应该应该考虑的问题。
我们可以生成一个随机数序列,然后从小到大排序,假设下面是一个生成的随机序列:
比较规则:
对左右两列数据做对比:
- 选择第二列的第一个数(0.1635),依次与左侧数据对比,直到遇到一个比它大的数(0.1899),停止比较。
- 选择第二列的第二个数(0.3377),接着从(1)中停止的位置(0.1899)开始比较,直到遇到一个比它大的数(0.8077),停止比较。
- 按照上面的规律,直到比较完第二列的所有数据,轮盘赌结束。
如果不对比较次数做限制的话,那么整个比较过程会是如下的效果:
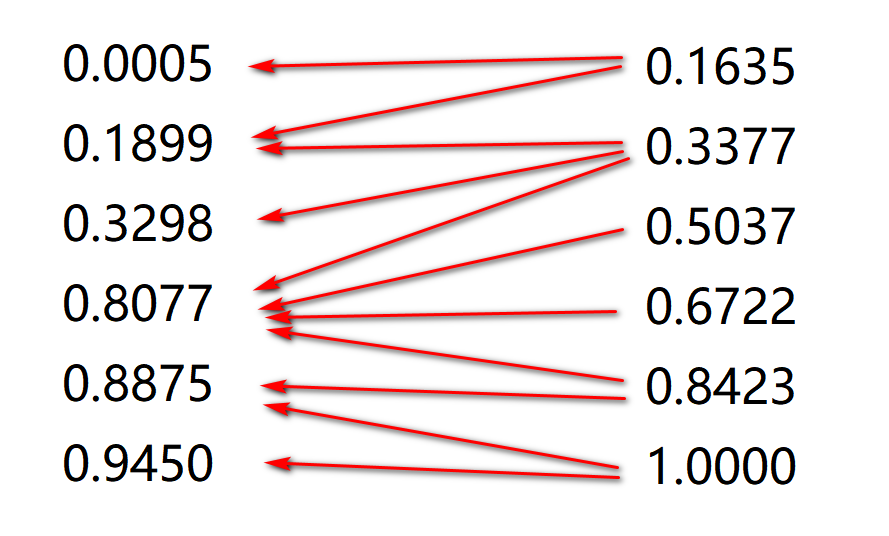
但是,鉴于种群数量有限,只能保存\(6\)个个体,因此,我们只保留箭头起始点较大的个体。
因为 0.1635 > 0.0005 ,故 0.1635 保留。
因为 0.5037 < 0.8077 ,故 0.5037 舍弃。
经过筛选后,我们得到下面的个体可以被保留:

也就是个体\(1\)、\(2\)、\(5\)、\(6\)被筛选了下来,而且,个体\(2\)和\(6\)被保留了两次。
以上就是整个遗传算法的核心了。其余部分(如何根据个体计算适应度,也就是如何根据\(x\)求出\(y\))需要根据具体情况做修改。
【注意】在交叉和变异中,需要将重复的元素去重,才能在适用于本题目。去重操作可以参考[Source Code]。
