
第一次作业
软件工程第一次作业
要求0:作业要求博客地址:【https://edu.cnblogs.com/campus/nenu/2016CS/homework/2110】
要求1:git仓库地址【https://git.coding.net/jinian/test.git】
1、PSP阶段表格
|
PSP2.1 |
计划耗时(min) |
实际耗时 |
|
估计耗时 |
50 |
60 |
|
分析需求 |
50 |
60 |
|
设计文档 |
70 |
80 |
|
代码规范 |
30 |
35 |
|
具体设计 |
100 |
130 |
|
具体编码 |
500 |
750 |
|
代码复审 |
170 |
200 |
|
测试代码 |
80 |
100 |
2、项目PSP
|
功能分类 |
具体 |
预计时间(min) (总体) |
实际耗时(min) (总体) |
|
功能一 |
具体设计 |
40 |
50 |
|
具体编码 |
280 |
300 |
|
|
调试运行 |
40 |
50 |
|
|
功能二 |
具体设计 |
60 |
70 |
|
具体编码 |
220 |
450 |
|
|
调试运行 |
40 |
50 |
|
|
功能三 |
|
|
|
3、 词频统计项目的预估计耗时和实际耗时的差距:其实主要差距还是在于自己的代码能力不行,没有养成一种规范的开发流程以及开发思想,导致在编码以及调试过程中出现许多问题。
要求3:
1、 主要思路
(1) 确定作业要求:四个功能都围绕词频统计进行了不同的拓展;
(2) 确定开发语言:C/C++是我最为熟悉的语言,因此选择C/C++,开发环境为DEVc++;
(3) 从控制台由用户输入到文件中,在代码中引用了文件路径
(4) 读取 test.txt 文档中的内容,用来统计词频
2、 代码介绍
功能一:
遍历文件夹中所有 .txt 后缀文件进行词频统计
本部分重点是遍历整个文件夹,所以我利用了库函数提取文件夹中所有 .txt 后缀文件的路径,并对每个路径进行处理,去掉路径仅留下文件名并添加 .txt 后缀,利用一个结构体储存所有处理后的“文件名 + .txt ",最后利用一个循环遍历所有结构体内的文件名进行词频统计。
从控制台由用户输入到文件中,在代码中引用了文件路径;
int main(int argc,char *argv[]) { int cmp(const PAIR& z, const PAIR& b); void swap(char s[66]); bool check(char x); bool check2(char y); void lower(string z); system(" d:\\test.txt /a-d /b /s >d:\\test.txt"); ifstream myfile("d:\\test.txt");
部分代码介绍:提取文件名
char zbwd[1024]; int Cnt = 0; while (! myfile.eof() ) { myfile.getline (zbwd,1024); int len = strlen(zbwd); int cnt = 0; bool tmp = false; for(int i = len - 1; i >= 0 ; i --) { if(zbwd[i] == '.') { for(int j = i-1; zbwd[j] != '\\'; j --) { zb[Cnt].s[cnt] = zbwd[j]; cnt ++; } } }; Cnt++; }
添加 .txt 后缀
for(int i = 0; i < Cnt-1 ; i ++) { swap(zb[i].s); strcat(zb[i].s,".txt"); }
这里需要注意的是,在提取文件名的过程中由于是从后向前进行处理的,所以储存起来是倒序的,所以需要进行字符串的翻转。
void swap(char s[66]) { int len = strlen(s); for(int i = 0,j = len-1; i < j ; i ++,j--) { char c; c = s[i]; s[i] = s[j]; s[j] = c; } }
判断是否有数字
int cmp(const PAIR& z, const PAIR& b) { return z.second > b.second; } bool check(char x){ if( (x>='a' && x<='z' )|| (x>='A'&&x<='Z') || (x>='0'&&x<='9') ) return 1; return 0; } bool check2(char y){ if( (y>='a' && y<='z' )|| (y>='A'&&y<='Z') ) return 0; return 1; }
运行结果截屏
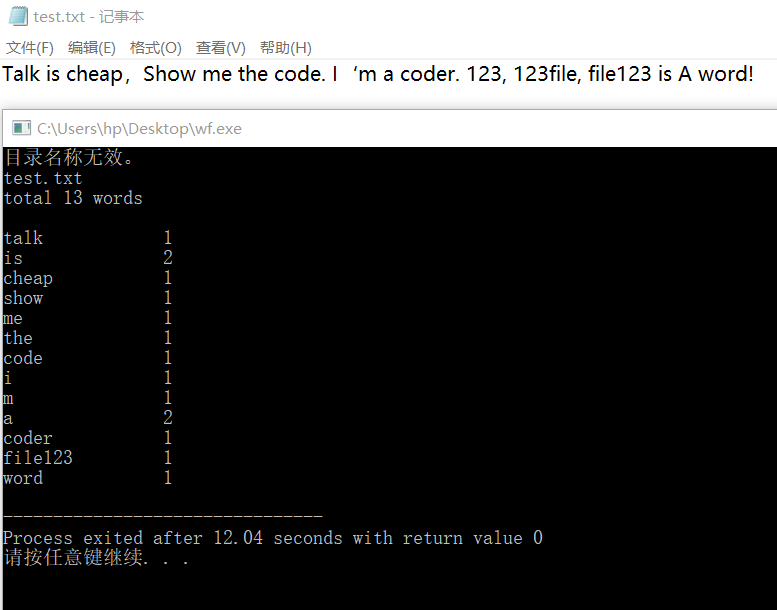
功能二:
using namespace std; int main() { FILE *fp; char text[1024]; char s[100]; //gets(s); printf(">input.txt\n"); fp=fopen("d:\\input.txt","r"); //fp=fopen(s,"r"); int n=0; int i; map<string,int>my_map; while(fgets(text,1024,fp)!=NULL) { puts(text); i=0; while(text[i]!='\0') { char s[30]; int j=0; while((text[i]>='a'&&text[i]<='z')||(text[i]>='A'&&text[i]<='Z')) { if(text[i]>='A'&&text[i]<='Z') text[i]+='a'-'A'; s[j++]=text[i++]; } s[j]='\0'; if(my_map[s]==0) n++; my_map[s]++; if(text[i]=='\0') break; else i++; } } fclose(fp); map<string,int>::iterator it; printf("\n\n"); printf(">wf -c test.txt\n"); cout<<"total"<<" "<<n-1<<endl<<endl<<endl; for(it=my_map.begin(),i=1;it!=my_map.end();it++,i++) { if(it->first=="") continue; cout<<left; cout<<setw(10)<<it->first; cout<<setw(10)<<it->second; cout<<" "; if(i%1==0) // cout<<'\n'; printf("\n"); } cout<<'\n'; return 0; }
因为自己代码能力不行,正在努力提升中
运行结果
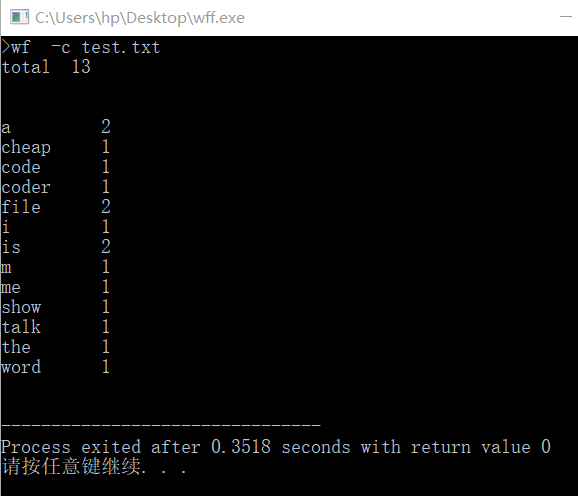
心路历程:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号