常用的 Excel 函数
概述
Excel 学的好,函数不可少。接下来就了解常用的函数。
首先作下简要说明:
- 本文的内容大多从网上搜集并加以个人理解整理而来,由于初学,可能会出现错误,如有欢迎指出;
- 所用演示软件为免费丑陋的 WPS 表格;
- Excel 函数对字母大小写不敏感,为了可读性,均小写。
主要内容
清洗处理类
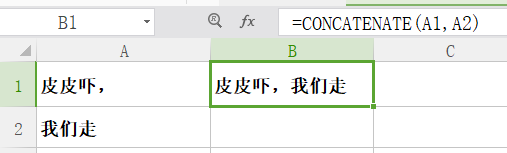
concatenate
功能: concatenate是一个文本连接函数。
格式: concatenate(text1,text2,text3......)
举例:如图
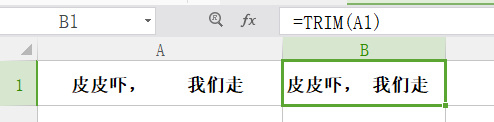
trim
功能: 用来删除字符串前后的单元格,但是会在字符串中间保留一个作为连接用途。
格式: trim(text)
举例:如图
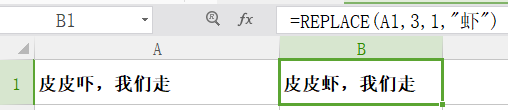
replace
功能: 用新字符串替换旧字符串,而且替换的位置和数量都是指定的。
格式:replace(old_text,start_num,num_chars,new_text)
举例:发现上面的例子字错了,我们改过来,如图
substitute
功能: 对指定的字符串进行替换。与 replace 相比,区别是全局替换,没有起始位置概念。
格式:substitute(text,old_text,new_text,[instance_num])
参数 Instance_num ——为一数值,用来指定以 new_text (新文本)替换第几次出现的 old_text(旧文本)。参数 Instance_num 可省略,这表示用 new_text(新文本)替换掉所有的old_text(旧文本)。
举例:如图

left,right,mid
功能: 截取字符串中的字符。
格式:left / right(指定字符串,截取长度),mid(指定字符串,开始位置,截取长度)
len,lenb
功能: 返回字符串的长度。在 len 中,中文计算一个,在 lenb 中计算两个。
格式:len / lenb(字符串)
find
功能: 查找并返回目标字符串在原始字符串的第几个位置。
格式: find(查找目标,查找区域,start_num)
参数 start_num 指定开始进行查找的字符数。比如 start_num 为1,则从单元格内第一个字符开始查找关键字。如果忽略 start_num,则假设其为 1. 注意 find 函数中不能出现通配符,否则错误。
举例:如图

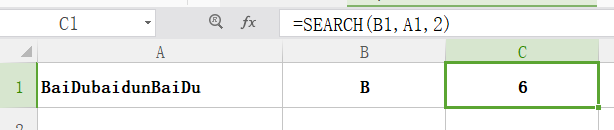
search
功能: 返回一个指定字符或文本字符串在字符串中第一次出现的位置 ,从左到右查找,忽略英文字母的大小写。
格式: search(查找目标,查找区域,start_num)
参数 start_num 指定开始进行查找的字符数。比如 start_num 为1,则从单元格内第一个字符开始查找关键字。如果忽略 start_num,则假设其为 1. search函数的参数查找目标可以使用通配符“*”,“?”。如果参数find_text就是问号或星号,则必须在这两个符号前加上“~”符号。
举例:如图
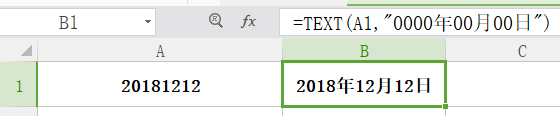
text
功能: 将各种形式的数值转化为文本,并可使用户通过使用特殊格式字符串来指定显示格式。
格式:text(数值,单元格格式)
举例:如图
统计函数类
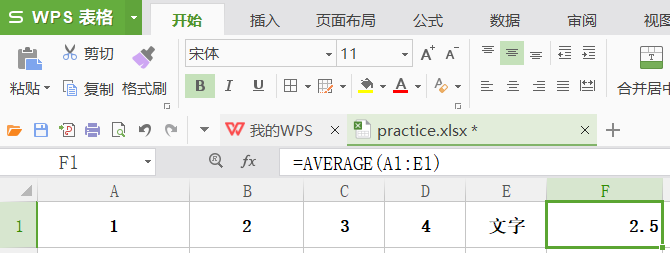
average
功能:如其名,求数组的平均值。如果单元格引用参数中有文字、空单元格,则忽略其值。
格式:average(数值区域或数组)
举例:如图所示,如果输入average(A1:E1),返回结果为 2.5,和 average(A1:D1)等价。尽管如此,我认为实际操作中,尽量避免这种情况。
类似的有函数:min,max,sum(,sumif,sumifs),stdev(标准差),不做详细说明。
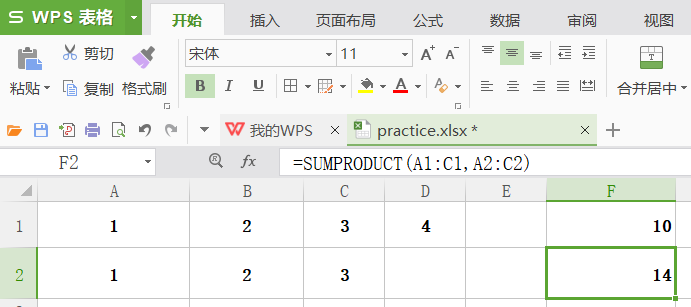
sumproduct
功能:求多个数组对应元素相乘之后的和。如含有空单元格,则不参与计算。
格式:sumproduct(数组1,数组2,···)
举例:如下图所示
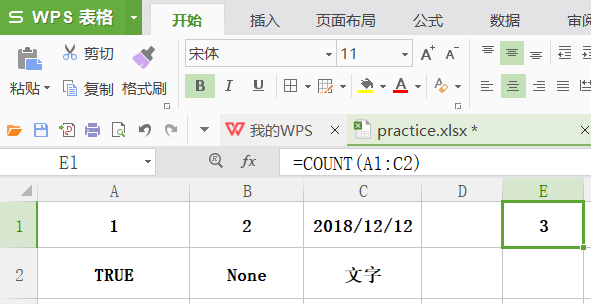
 ### count
**功能:**统计出是数字单元格和个数。
### count
**功能:**统计出是数字单元格和个数。
格式:count(区域)
举例:
此外,还有函数 countif(区域,条件),countifs(区域,条件,区域,条件,···),countifs 后面的括号可以加多个条件,但每个条件都需要有两个参数,一个单元格选取,另外一个就是判断条件。
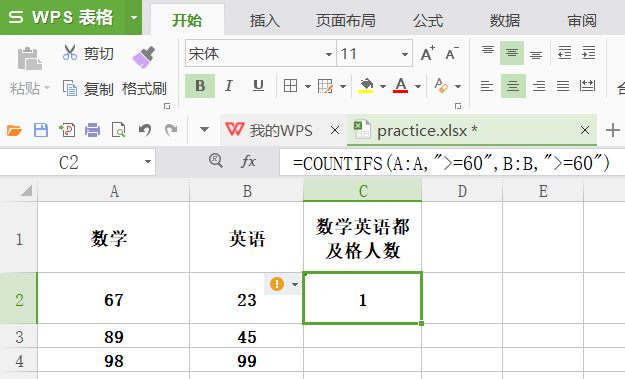
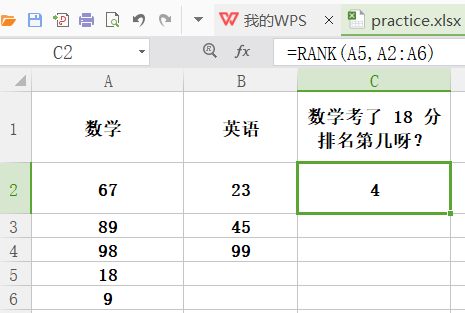
rank
功能:排序。返回指定值在引用区域中的排名,注意重复值是同一排名。order 为零或者省略代表降序,不为零则为升序。
格式:rank(数值,区域,order)
举例:
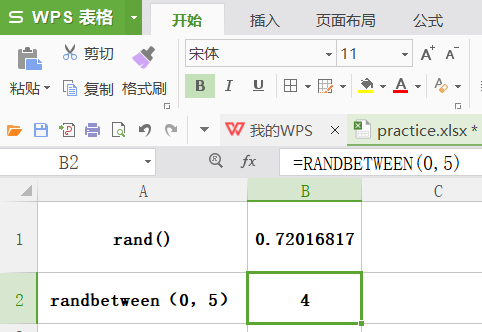
rand
功能:产生 0~1 之间服从平均分布的小数。不需要参数。
格式:rand()
类似有个randbetween(bottom, top),需要注意的是它返回的是整数。
举例:
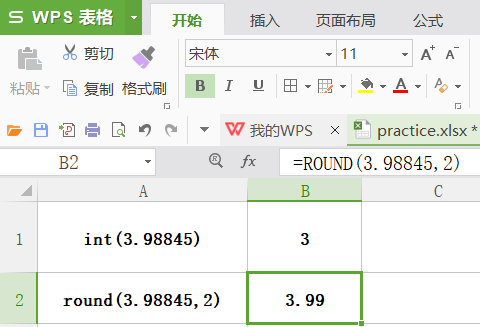
int / round
功能:取整函数。int 向下取整,round 按小数位取整。
格式:int(数值),round(数值,保留小数位数)
举例:
查找函数类
lookup
功能:查询一行或一列并查找另一行或列中的相同位置的值。
格式:lookup(要查找的值, 区域(查找的值在此),查找的相应位置)
举例:以一份学生成绩表为例,要查谁考了 59 分,可以如下图操作
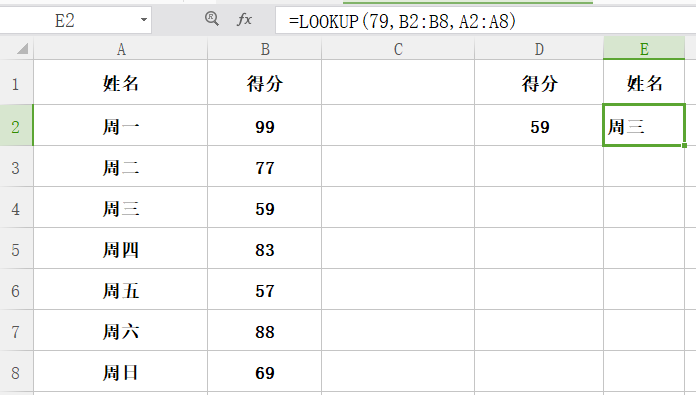
该lookup函数括号内的含义是,其中 59 就是我们查询的得分条件,B2:B8 是得分项所在的列区间,也叫条件区域,那么 A2:A8 就是我们要查找的对应区域。如果我们给的值不在查找区域内,比如要查找谁得了 58 分,表中没有人考这个分,那就会报错,我们的需求可能是谁“差不多”考这个成绩,这就需要模糊查找,也就是下面要介绍的 vlookup.
vlookup
功能:如果需要按行查找(在某列中)表或区域中的内容,请使用此函数。
格式:vlookup(查找值,查找范围,列序数,精确匹配或者近似匹配(false 或者 true))
注意查找值一定要在该区域的第一列。如果选择模糊查找的话,引用的数字区域一定要从小到大排序,杂乱的数字是无法准确查找到的,模糊查找的原理是:给一定个数,它会找到和它最接近,但比它小的那个数。
举例:
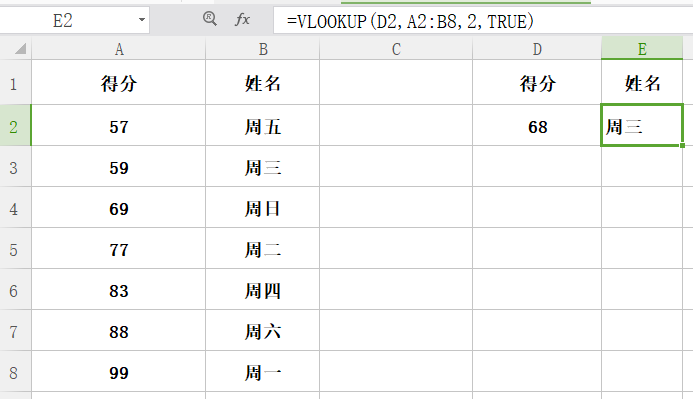
类似函数hlookup,查找水平方向(行),不再介绍。
index
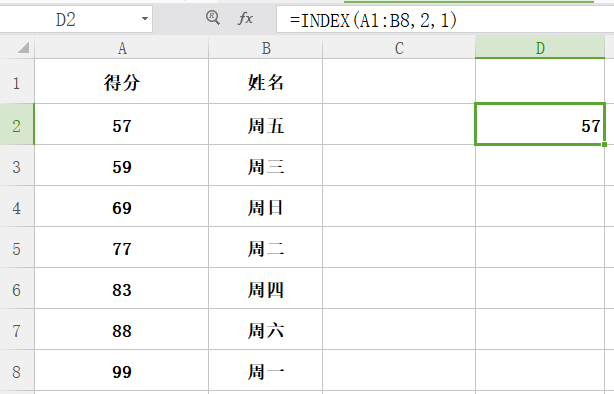
功能:查找区域中的某行某列交叉位置的值。
格式:index(查找范围,行序数,列序数)
举例:
match
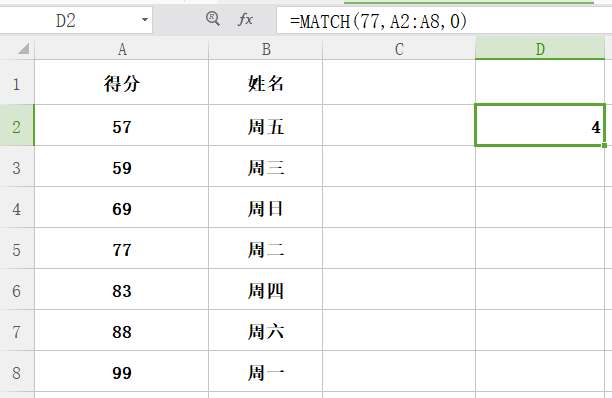
功能:返回目标值在查找区域中的相对位置。
格式:match(目标值,查找区域,match_type(0/1/-1))
注意:
- 查找区域只能为一列或一行;
- 参数 match_type=0,表示精确查找,如果查找区域按任意顺序排列。一般只使用精确查找。
- 参数 match_type=1,查找小于或等于目标值的最大数值在查找区域中的位置,查找区域中的值必须按升序排列(1)。
- 参数 match_type=-1,查找大于或等于目标值的最小数值在查找区域中的位置,查找区域中的值必须按降序排列(-1)。
举例:查找的 77 在所选区域的第 4 个位置。
逻辑运算类
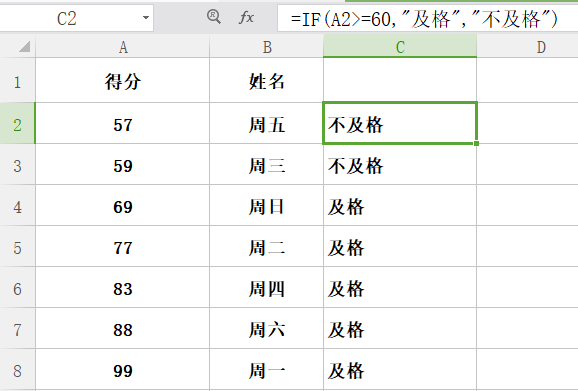
if
功能:条件判断函数
格式:if(logical_test,value_if_true,value_if_false)
举例:如图所示
and, or, is
功能:逻辑运算,没什么好说的。其中 is 常用判断检验,返回的都是布尔数值 true 和 false. 常用 iserror,isna(ISNA函数,是用来检测一个值是否为 #N/A,返回 TRUE 或 FALSE。ISNA 值为错误值 #N/A(值不存在),通常是和其与函数结合使用,比如我们常见到的,使用vlookup函数时,配合if函数和isna函数进行返回值"#N/A"为空的更正。)
最后
如有需要,会不断完善。
