

Erlang数据类型的表示和实现(5)——binary
binary 是 Erlang 中一个具有特色的数据结构,用于处理大块的“原始的”字节块。如果没有 binary 这种数据类型,在 Erlang 中处理字节流的话可能还需要像列表或元组这样的数据结构。根据之前对这些数据结构 Eterm 的描述,数据块中的每一个字节都需要一个或两个机器字来表达,明显空间利用率低,因此 binary 是一种空间高效的表示形式。
在 binary 对字节序列处理能力的基础上,Erlang 进一步泛化 binary 的功能,提供了 bitstring 数据结构,让开发者能打破字节的边界,能在 bit 层面上操作原始数据块。bitstring 的 bit 层次的模式匹配功能特别适用于网络编程中网络协议数据包的解析和文件解析等操作。
本文从实际的需求出发,从简单到复杂,逐步讨论 Erlang 中 binary 和 bitstring 的实现及优化。本文会介绍 binary 相关数据结构的 Eterm 以及在 Erlang 虚拟机内部的表达形式,并结合具体的示例程序和编译器生成的 beam 字节码及对应的虚拟机代码讨论 Erlang 对 binary 和 bitstring 的操作所做的优化。
下面首先讨论最简单的 binary —— heap binary。
heap binary
heap binary 是直接放在进程堆中的 binary,也就是说整个 binary 的数据都在进程堆中,就好像其他 boxed 数据结构一样。下图展示了 heap binary 在堆中的表现形式。
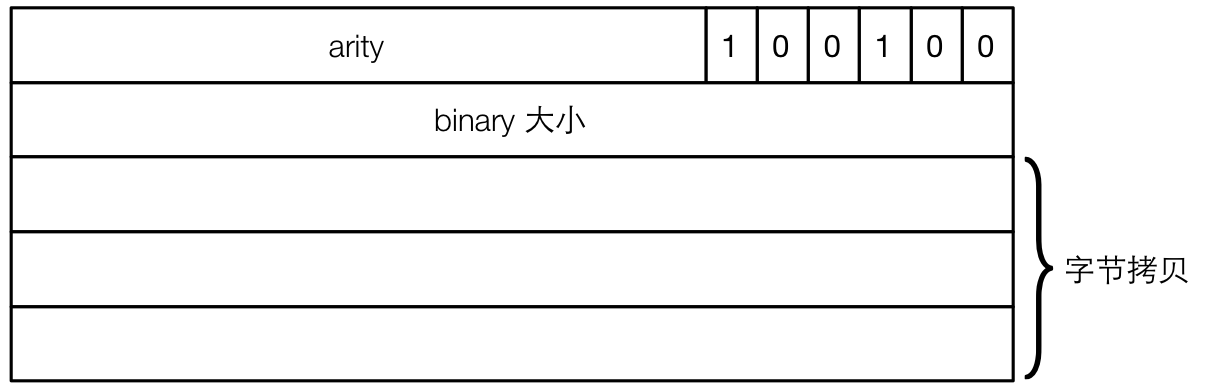
这是一个典型的 boxed 对象,第一个字的标签表示了这个对象的类型,arity 表示后面跟了几个字。第二个字则表示这个 binary 中的字节数。接下来就是 arity - 1 个字,从低地址到高地址原样保存了 binary 数据的拷贝。
由于 heap binary 直接放在堆中,属于“小”数据,进程间要发送这种 binary 消息的时候会涉及到复制,因此目前 Erlang 虚拟机代码中将 heap binary 大小限定为 64 字节。在创建 binary 的时候,如果事先确定 binary 中数据字节数小于等于 64 字节,那么 Erlang 虚拟机就会选择在堆中直接创建 heap binary。
如果在创建 binary 的时候,确定 binary 中数据的字节数大于 64 字节,那么 Erlang 虚拟机就会创建 refc binary。
refc binary
refc binary 是保存在 Erlang 虚拟机内存中,所有 Erlang 进程堆之外的区域中的 binary。Erlang 进程之间可以共享这种 binary。当一个 Erlang 进程给另一个 Erlang 进程发送这种 binary 的时候,理想情况下只需要发送一个引用即可,因此可以避免复制的开销和内存的开销。由于这种 binary 是可以被多个进程共享的,因此为了跟踪这种 binary 的使用,Erlang 虚拟机采用了引用计数的方式,因此这种 binary 得名为 refc binary,即 reference-counted binary 的意思。
由于 refc binary 是共享的,所以需要通过两个部分描述,一个部分是 binary 数据本身,另一个部分是对 binary 数据的引用,即 Erlang 进程堆中的 ProcBin 对象。下图展示了 ProcBin 和 Binary 对象之间的关系。
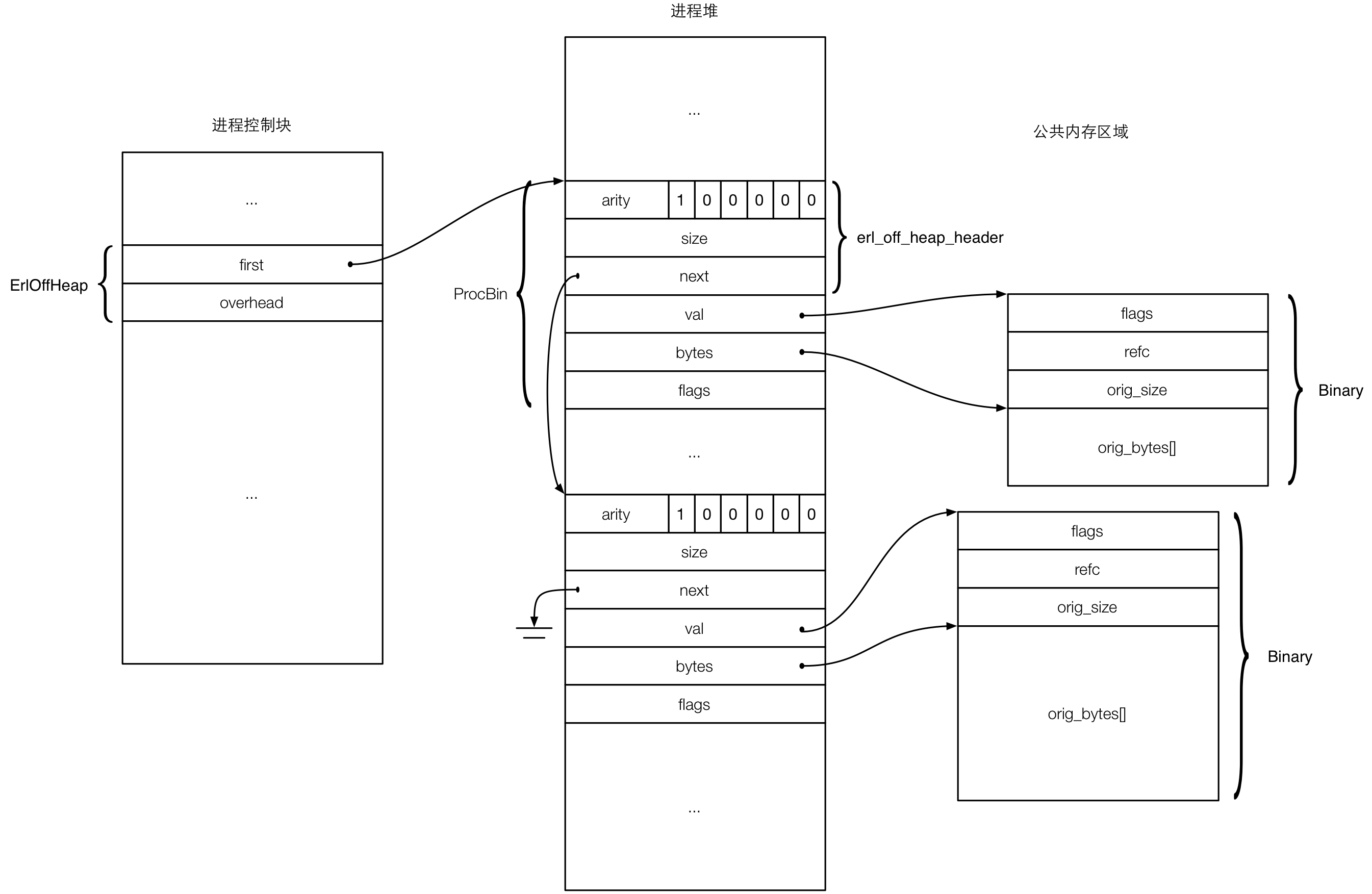
从图中可以看出,ProcBin 对象是在进程堆中的 boxed 对象,并且通过 next 指针串联起来了。进程控制块中有一个 ErlOffHeap 数据,这个数据是进程所有 off-heap(即“堆外”)数据的链表的头,first 指向第一个 ProcBin。目前 Erlang 进程只有 refc binary 这一种 off-heap 数据,不过以后有可能会有更多类型的 off-heap 数据类型,因为 off-heap 这种名称看上去很 general。ErlOffHeap 数据还有一个字段 overhead,这个字段记录了所有 off-heap 数据大小的总和,这个值会用于垃圾回收,如果这个 overhead 超过了进程的 vheap(虚拟堆)限制,则会进行垃圾回收。vheap 也是一个 general 的概念,尽管目前仅用于 binary。有关 vheap 的初始化、增长和对垃圾回收的控制,请参阅这篇博文[注5]。另外提一下,在 Erlang 虚拟机的代码中,有一个宏 MSO,经常能看到类似 MSO(c_p).overhead 和 MSO(c_p).first 这样的调用,MSO(c_p) 宏实际上获得的就是当前进程 c_p 的 ErlOffHeap 数据。估计 MSO 是 memory shared object 的简写吧,共享内存对象和 off-heap 对象应该是同一个意思。
ProcBin 对象的第一个字就是标准的 boxed 对象头。接下来的 size 表示 ProcBin 指向的 Binary 对象的实际字节数,next 指向进程中的下一个 ProcBin,val 指向共享内存区域中的实际 Binary 对象,bytes 则指向实际 Binary 对象中的真正的数据块。flags 是 ProcBin 相关的标志位,和 binary 操作的优化有关,后面会详细解释。
再来看 Binary 对象。Binary 对象完整地包含了 binary 实际要表达的数据,因此是一个可变大小的对象,实际数据在 orig_bytes 数组中。orig_size 表示 orig_bytes 数组中的字节数。refc 则是引用计数,初始化一个 refc binary 的时候对应的 Binary 的 refc 初始化为 1。refc 降为 0 的时候表示可以回收。由于 Binary 可以被多个进程访问,因此 refc 在 SMP 版本的 Erlang 虚拟机上是一个原子变量。Binary 的标志位 flags 主要由 Erlang 虚拟机中其他部分使用(标记 Binary 本身的不同类型,可以将 Binary 理解为“基类”,其他类型的 Binary 可能会添加一些特殊的功能,例如 ErtsMagicBinary 中添加了特殊的“析构函数”。),和 binary 本身操作无关,因此本文不详细讨论。
上面我们讨论了两种包含真实数据的 binary:heap 和 refc binary,这两种 binary 都是容器,分别对应了 boxed 对象的 header 标签 1000 和 1001。除此之外,我们还可以在 header 标签的列表中看到另外两种和 binary 相关的 header:表示 binary 匹配状态的 0001,以及表示 sub binary 的 1010。这两种 binary 对象本身并不包含实际的 binary 数据,而是引用其他 binary 中的部分数据。下面我们先看 sub binary。此外,bitstring 的实现也和 sub binary 有关。
sub binary 和 bitstring
sub binary 就是子 binary,表示 binary 中的部分内容。比如我们调用 BIF split_binary/2 的时候,如果参数正确,会将原来的 binary 分割为两个部分,得到两个 binary。这个 BIF 调用当然可以创建两个新的 heap 或 refc binary,然后分别将对应的数据复制到两个新的 binary。由于 Erlang 中的变量都是 immutable 的,所以我们可以认为一个 binary 在创建了之后不会被修改。因此,这种创建新 binary 并复制的操作显然是低效且浪费空间的。
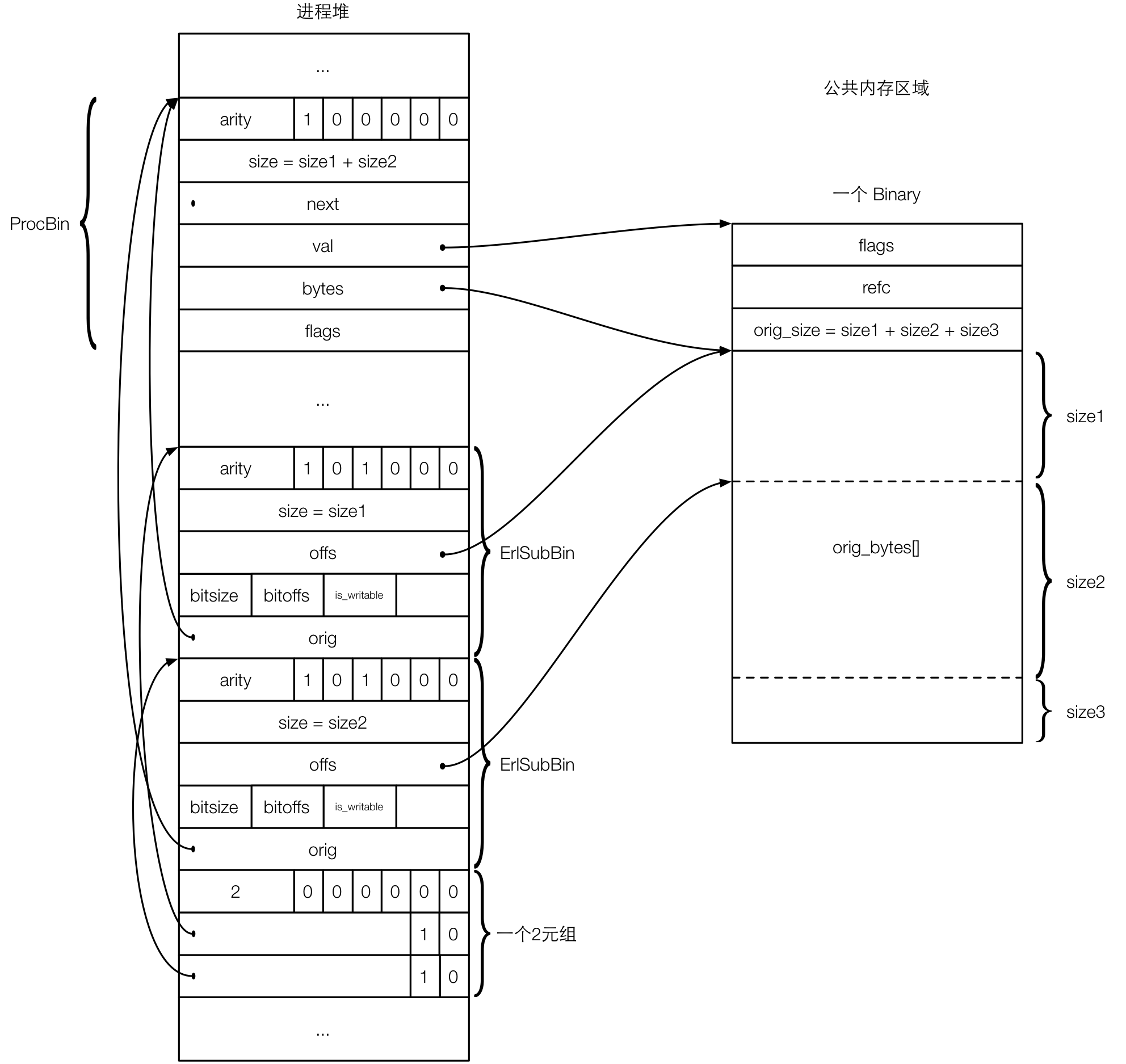
为了在分割 binary 的时候能复用原有的数据,Erlang 虚拟机内部引入了 sub binary 类型(Erlang 程序员在 Erlang 语言的层面感知不到)。Erlang 的 split_binary/2 调用生成的就是两个 sub binary,然后将这两个 sub binary 放在一个二元组中返回给调用者。下图展示了表示 sub binary 的 boxed 对象的结构,即图中的 ErlSubBin 部分,并展示了 split_binary/2 对一个 refc binary 操作之后的示例结果。
我们首先看 sub binary 的结构,在 Erlang 虚拟机代码中定义如下:
1 typedef struct erl_sub_bin { 2 Eterm thing_word; /* Subtag SUB_BINARY_SUBTAG. */ 3 Uint size; /* Binary size in bytes. */ 4 Uint offs; /* Offset into original binary. */ 5 byte bitsize; 6 byte bitoffs; 7 byte is_writable; /* The underlying binary is writable */ 8 Eterm orig; /* Original binary (REFC or HEAP binary). */ 9 } ErlSubBin;
和其他 boxed 对象的结构体一样,thing_word 是 boxed 对象的 header。size 表示这个 sub binary 引用的数据的大小,offs 表示这个 sub binary 引用的具体 binary 中的偏移值。bitsize 和 bitoffs 和 bistring 有关,后面会详细描述。is_writable 表示引用的那个 binary 是否可写,这个值和 binary 的拼接优化有关,也会在后面详细描述。orig 则指向原始的那个带有具体数据的 binary(既可以是 heap binary 也可以是 refc binary)。
在上面的图中,我们可以看到新生成的两个 sub binary,这两个 sub binary 的 offs 分别指向 被引用的 refc binary 的偏移位置 0 和 pos 处,两段的大小分别为 size 1 和 size2,然后这两个的 orig 均指向堆中原来的那个 refc。值得注意的是,我们可以看到底层 Binary 中的数据块被分为 3 段,还有一个大小为 size3 的段没有被引用,但是 Binary 自己的 orig_size 则记录了这个大小。这说明底层 Binary 本身的大小可能会大于 ProcBin 中记录的大小,因为底层的 Binary 可以执行类似“预分配”的优化,后面会详细讨论这种优化。
sub binary 还有一个重要的用途,就是支持 bitstring。bitstring 在 Erlang 虚拟机内部实际上也是靠 binary 支撑的,即实际数据都保存在 Binary 对象(或 heap binary)中。对于 Erlang 程序员来说,在操作 binary 的时候,实际上也不必太操心 binary 里面的位元数是否能被 8 整除,Erlang 虚拟机能在后台处理好各种情况。比如说 X = <<A:2, B:6>> 和 Y = <<A:3, B:6>>,A 和 B 都是整数,那么 X 是一个 binary,而 Y 称作是一个 bitstring。这两个对象在 Erlang 虚拟机内部表示是不同的。对于 Y 来说,为了能显示出“额外的”那个位元,Erlang 虚拟机内部就要使用 sub binary 了。下面通过例子来看两者的区别。先看能被 8 整除的情况:
1 bs_creator_bytes(X, Y) -> 2 <<X:500, Y:20>>.
为了让例子更复杂一些,我们这里选择创建 refc binary,520 个位刚好是 65 字节,Erlang 虚拟机会选择创建 refc binary。
然后再看不能被 8 整除的情况:
1 bs_creator_bits(X, Y) -> 2 <<X:500, Y:13>>.
这段代码要创建的是一个包含 513 个位的 binary,513 不能被 8 整除,所以这段代码创建的实际上是 bitstring。
下面我们从 Erlang 汇编代码[注6]的角度来看编译器对这两种情况的处理:
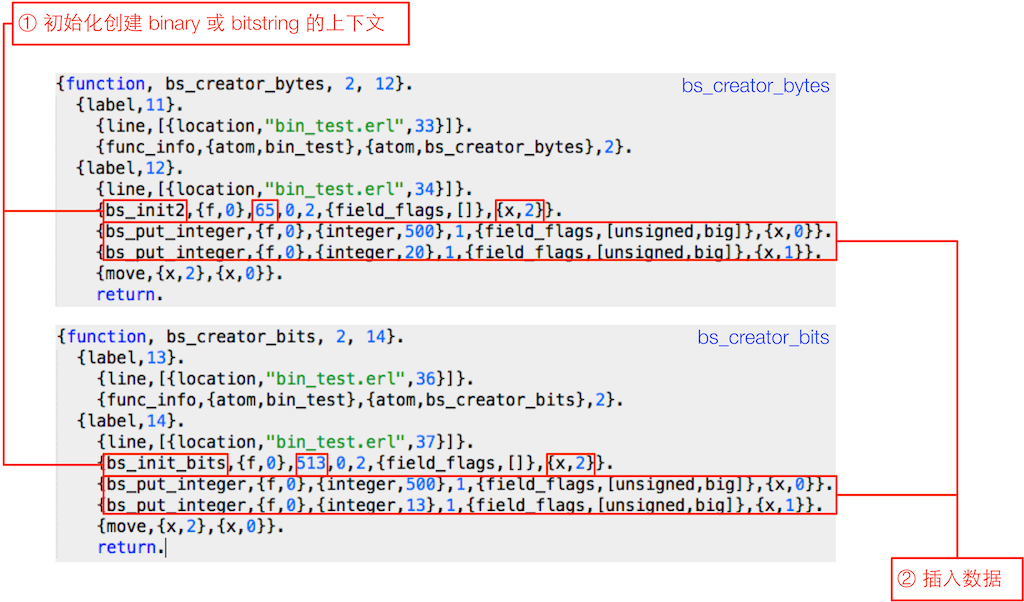
上图中的上下两块 beam 汇编代码分别是编译器为 bs_creator_bytes 和 bs_creator_bits 生成的代码(不用担心不能理解这里汇编代码的细节)。可以看出这两个函数实际上有两类步骤:第一步是初始化一个用于创建 binary 或 bitstring 的上下文,第二步是在之前创建的上下文中填入传入函数的整数。
两个函数代码的区别在于第一步的指令:bs_init2 和 bs_init_bits,从名字也能看出来,后面这条指令和 bit 有关。
先看 bs_init2 指令,从上图中可以看到这个指令接受的第二个参数 65 表示要创建的字节数。erts/emulator/beam/beam_emu.c 文件的 process_main() 函数是 Erlang 虚拟机的代码执行逻辑,从中可以看到这条指令执行的操作:
- 在共享内存中创建一个新的 Binary 对象,将 Binary 对象缓冲区大小设置为传入的大小,即 65
- 在进程的堆上创建一个新的 ProcBin 对象,新的 ProcBin 指向刚创建的 Binary,大小也设置为 65
- 返回对应刚创建 ProcBin 对象的 Eterm(上图中的例子将结果 Eterm 放在寄存器 x[2] 中)
接下来再看 bs_init_bits 指令,这条指令接受的第二个参数 513 表示要创建的 bitstring 的位元数,的执行逻辑:
- 根据传入指令的所需位数,计算出保存这么多位元所需要的字节数,例如 513 个位元需要占用 65 个字节
- 由于所需字节数超过 64,所以要创建 refc binary。即先在共享内存中创建一个 Binary 对象,缓冲区大小设置为上一步计算出来所需的字节数
- 在进程的堆上创建对应的 ProcBin
- 在进程的堆上创建一个 ErlSubBin,这一步是区分 binary 和 bitstring 的关键,结合之前列出的 ErlSubBin 字段描述,下面是各个字段的取值:
- size:Binary 所需字节数 - 1,因为在底层的 Binary 中最后一个字节并不是完整的,只需要使用其中的几个位。在这个例子中为 64 字节,第 65 字节只使用 1 个位
- offs:0,因为这是新创建的 sub binary
- bitsize:Binary 中最后那个字节中使用到的位元数,在这个例子中为 1
- bitoffs:依然是 0
- 返回对应刚创建的 ErlSubBin 对象的 Eterm(在上图中的例子中将结果 Eterm 放在寄存器 x[2] 中)
从上面的描述中,我们可以看出 binary 和 bitstring 在内部表达上的区别了,即 binary 可以直接通过 heap binary 或 refc binary 表示,而 bitstring 则需要通过 sub binary 来表示。在 Erlang 语言的层面看不出这个区别,这只是底层 Erlang 虚拟机在实现上的区别。Erlang 虚拟机的代码在处理 binary 的时候,会首先根据代表这些不同类型的 binary 的 Eterm(即 boxed header)来判断具体的类型并采取相应的操作。
不论是 binary 还是 bitstring,底层的 Binary 对象都能保证有足够大的缓冲区能支持后续的填写操作。因此第二个步骤就简单了。我们可以看出两个函数的第二个步骤都是两条 bs_put_integer 指令。bs_put_integer 这条指令主要看第二个参数(例如 {integer,500}) 和最后一个参数(例如 {x,0})。前一个参数告诉这条指令要在当前上下文中填入一个整数,这个整数长度为 500 位元。后一个参数告诉这条指令要填写的整数来源于 x[0] 寄存器。
从图中可以看出,两个函数第二个步骤的两条指令除了参数之外都是一模一样的,说明 bs_put_integer(以及其他类似功能的 bs_put_xxx 指令)都不用管写入的是 binary 还是 bitstring,这些指令都假设之前已经创建好并准备好了可以写入的上下文。
前面也多次提到了这个“上下文”,那么这个上下文到底是什么?后面在讨论匹配的时候也会提到这个“上下文”。上下文其实就是一个包含各种全局状态的环境,我们仔细看上面图中的汇编码,可以发现尽管第一步的指令,例如 bs_init_bits 最后将结果 ErlSubBin 对应的 Eterm 放在寄存器 x[2] 中返回,但是后面的 bs_put_integer 指令并没有用到这个寄存器作为参数。此外,bs_input_integer 指令也没有传入任何表示要在哪里开始写入的参数。从这两点我们可以看出,针对新创建的这个 bitstring 或 binary,至少一组全局状态用于表示缓冲区的位置以及当前写入的位置等,就好像文件描述符这样的东西。
事实上,的确有这样一组全局状态,也就是很多文档里面提到的“上下文”,在 Erlang 虚拟机中用 struct erl_bits_state 表示这个上下文(定义在 erts/emulator/beam/erl_bits.h 头文件中)。在 SMP 的虚拟机中,每一个调度器线程都有一个私有的这样的全局状态。bs_init2 和 bs_init_bits 指令都会初始化这个状态,然后之后的 bs_put_xxx 之类的指令可以通过这个全局状态得到缓冲区的位置以及要写入的位置,写完之后更新其中表示偏移量的字段。偏移量字段以位元为粒度。
上面已经介绍了 3 种和 binary 相关的数据结构:heap binary、refc binary 和 sub binary,还介绍了通过类似 <<Z:8, S:16, Y:20>> 这样的语法构造 binary 或 bitstring Erlang 虚拟机内部进行的操作。
binary 还可以通过向一个已有 binary 追加其他数据的方式进行构造。下面介绍 Erlang 虚拟机对这种构造方式的优化。
binary 追加构造的优化
通过类似 B1 = <<B0/binary, 1, 2>> 的语句,可以在 binary B0 之后追加 1,2 两个字节构造新的 binary 并保存在 B1 中。Erlang 虚拟机实现这种追加构造的最简单方法是先创建出有足够空间的 B1,然后将 B0 的数据和 1,2 两个字节一起复制到新创建的 B1。在 Erlang 中,如果编写类似 list_to_binary 的函数,每次处理 list 中的一个元素并追加到结果 binary 的尾部,那么这种模式的函数在上述机制下(每一次都要复制并创建新的 binary)效率会非常低下。结合之前描述的 refc binary 和 sub binary 的结构,我们自然会想到聪明的 Erlang 必然会有针对追加构造 binary 进行的优化。
Erlang 果然不会辜负我们的期望,在“效率指南”中关于 binary 构造和匹配的部分[注7]介绍了 Erlang 虚拟机对 binary 追加构造进行的优化。
我们先看一下效率指南中的例子:
1 Bin0 = <<0>>, %% 1 2 Bin1 = <<Bin0/binary,1,2,3>>, %% 2 3 Bin2 = <<Bin1/binary,4,5,6>>, %% 3 4 Bin3 = <<Bin2/binary,7,8,9>>, %% 4 5 Bin4 = <<Bin1/binary,17>>, %% 5 !!! 6 {Bin4,Bin3} %% 6
根据效率指南的描述,第 1 行创建一个 heap binary。第 2 行是 Bin0 第一次被追加内容,所以会创建一个新的 refc binary,并且将 Bin0 的内容复制到其中,不仅如此,新的 refc binary 底层的 Binary 对象还预留了 256 字节的空间。然后字节 1,2,3 会被追加到后面,得到 Bin1。第 3 行的时候就可以利用上面这个优化,直接把 4,5,6 字节放在预留的空间中。第 4 行是和第 3 行是一样的,7,8,9 字节放在以上预留空间的 4,5,6 之后。到第 5 行的时候就要注意了,Erlang 虚拟机肯定不能直接把 17 字节放在 Bin1 的后面,要不然 Bin2 里面的内容就要被覆盖了,虚拟机里面再怎么优化,也不能破坏语言本身提供给用户的语义,因此虚拟机能够通过某种机制发现这一点,将 Bin1 复制到新的 refc binary 中,然后剩下的过程就和上面的优化过程是一样的了。
尽管在语言层面这些优化都是透明的,但是下面通过简单的实验可以看出一点这种优化的迹象:
1 do_append_test_verbose() -> 2 io:format("in do_append_test_verbose~n"), 3 Bin0 = <<0>>, 4 io:format("Bin0 = ~p, ~p~n", [Bin0, erts_debug:get_internal_state({binary_info, Bin0})]), 5 append_test_verbose(Bin0). 6 7 append_test_verbose(Bin0) -> 8 io:format("in append_test_verbose~n"), 9 io:format("Bin0 = ~p, ~p~n", [Bin0, erts_debug:get_internal_state({binary_info, Bin0})]), 10 Bin1 = <<Bin0/binary,1,2,3>>, 11 io:format("Bin0 = ~p, ~p~n", [Bin0, erts_debug:get_internal_state({binary_info, Bin0})]), 12 io:format("Bin1 = ~p, ~p~n", [Bin1, erts_debug:get_internal_state({binary_info, Bin1})]), 13 {Bin0,Bin1}.
这段程序很简单,append_test_verbose/1 接受 Bin0 作为参数,先打印出 Bin0 以及 Bin0 的内部信息,然后再追加 Bin0 得到 Bin1,再打印出 Bin0 和 Bin1 的内部信息。打印内部信息的 erts_debug:get_internal_state/1 是一个未公开的调用,参见这篇博文[注8]。为了测试这个函数,必须再写一个测试函数 do_append_test_verbose/0,然后在 shell 里面调用 do_append_test_verbose/0,而不要直接在 shell 中调用 append_test_verbose/1(如果在 shell 中调用,Bin0 总是 refc binary,这应该是和 shell 的机制有关)。注意:之所以要单独列出一个函数以 Bin0 作为参数传入而不是像效率指南中那样直接写 Bin0 = <<0>>,是为了避免编译器做优化,直接把 Bin1 给计算出来了。
好了,在 shell 中调用 do_append_test_verbose(),得到以下输出:
328> bin_test:do_append_test_verbose().
in do_append_test_verbose
Bin0 = <<0>>, heap_binary
in append_test_verbose
Bin0 = <<0>>, heap_binary
Bin0 = <<0>>, heap_binary
Bin1 = <<0,1,2,3>>, {refc_binary,4,{binary,256},3}
{<<0>>,<<0,1,2,3>>}
从输出我们可以看出,Bin0 在刚创建的时候是 heap binary,然后被传入 append_test_verbose/1,仍然是 heap binary。接下来被追加字节,可以看出 Bin 0 仍然是 heap binary,因为 Bin0 没有被改动。从 Bin1 开始就能看到优化的作用了,Bin1 虽然只有 4 个字节,但是并不是以 heap binary 形式存在的,其本质上是一个 refc binary(后面可以看出,实际上 Bin1 引用的 boxed 对象是一个 sub binary,但是 erts_debug:get_internal_state/1 返回的是其背后真实的 binary 信息),大小为 4,这是符合常理的。从输出可以看出, Bin1 底层的 Binary 对象大小为 256 字节,说明真的预留了追加用的空间。最后的 3 表示 ProcBin 中的 flags 字段,并且同时设置了 PB_IS_WRITABLE 和 PB_ACTIVE_WRITER,更说明其特殊之处。
下面我们就在 beam 汇编码的指引下继续探索这种优化的实现细节。依然拿效率指南上的例子,和上面的例子一样,为了看到编译器做的工作,把几个追加的操作放在单独的函数中:
do_append_test() -> Bin0 = <<0>>, append_test(Bin0). append_test(Bin0) -> Bin1 = <<Bin0/binary,1,2,3>>, Bin2 = <<Bin1/binary,4,5,6>>, Bin3 = <<Bin2/binary,7,8,9>>, Bin4 = <<Bin1/binary,17>>, {Bin4,Bin3}.
生成的 beam 汇编码如下所示:
{function, append_test, 1, 4}.
{label,3}.
{line,[{location,"bin_test.erl",9}]}.
{func_info,{atom,bin_test},{atom,append_test},1}.
{label,4}.
{bs_append,{f,0},{integer,24},0,1,8,{x,0},{field_flags,[]},{x,1}}.
{bs_put_string,3,{string,[1,2,3]}}.
{bs_append,{f,0},{integer,24},0,2,8,{x,1},{field_flags,[]},{x,0}}.
{bs_put_string,3,{string,[4,5,6]}}.
{bs_append,{f,0},{integer,24},0,2,8,{x,0},{field_flags,[]},{x,2}}.
{bs_put_string,3,{string,[7,8,9]}}.
{bs_append,{f,0},{integer,8},3,3,8,{x,1},{field_flags,[]},{x,0}}.
{bs_put_string,1,{string,[17]}}.
{put_tuple,2,{x,1}}.
{put,{x,0}}.
{put,{x,2}}.
{move,{x,1},{x,0}}.
return.
每一个追加操作都是由两条指令配对完成的:首先由 bs_append 指令分配好空间,设置好上下文,然后由 bs_put_string 指令将实际的内容复制到正确的位置。关键在于 bs_append 指令。下面我们通过几个图示来观察 bs_append 指令是如何针对不同情况运作的,同时还能看到 bs_append 指令和 bs_put_string 指令的合作方式。有兴趣的读者还可以顺便参考 bs_append 指令实现的源代码,这条指令是由 erts/emulator/beam/erl_bits.c 文件中的 erts_bs_append() 函数实现的。
Bin0 = <<0>> 很简单,就是一个表示 heap binary 的 boxed 对象,其中只包含一个字节。这里就不画 Bin0 的图示了。
然后运行 Bin1 = <<Bin0/binary,1,2,3>> ,虽然 Bin1 最终的值是 <<0,1,2,3>>,显然也是能在 heap binary 中放得下的,但是 Erlang 虚拟机的优化使得情况变得更加复杂。下面的图展示了为了创建 Bin1 而创建的数据结构以及之间的关系(注意这个图只是为了展示数据结构之间的关系,所以就不太纠结比例和具体字段之类的细节了):
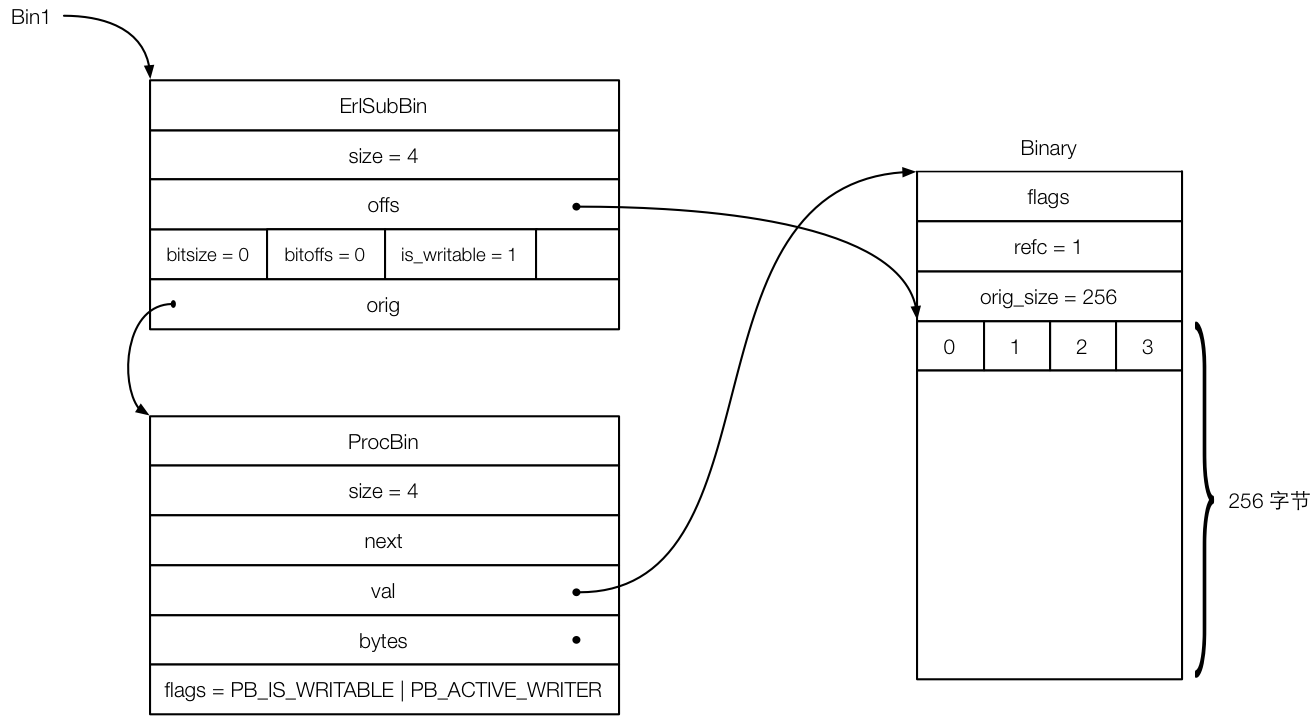
从图中我们可以看出为什么 Erlang 虚拟机要这么设计。bs_append 的优化主要体现在 Binary 中预分配了空间,预分配空间应该比原有的空间要大,否则就没有意义了。目前 Erlang 虚拟机采用的规则是,首先计算完成追加操作之后 binary 中需要容纳的字节数,然后将这个值乘以 2,再和 256 比较取其较大者。那么这里自然而然 256 就更大了。既然这么大了,那么肯定要用 refc binary 来表示这个 binary。但是由于 Binary 中有大部分空间是预留的,我们实际的 binary 只占 Binary 对象中的一部分,所以还要引入 sub binary。因此,创建 Bin1 会涉及到 sub binary、proc binary 以及底层的 Binary 对象。
在上图中,ErlSubBin 和 ProcBin 的 size 都设置为 Bin1 的实际大小,即 4。而 Binary 对象的 orig_size 大小则设置为 Binary 中缓冲区的大小,即 256。还要注意,ErlSubBin 的 is_writable 字段设置为 1,表示这个 sub binary 是可写的(所谓可写,也就是说可追加)。ProcBin 中的 flags 也被设置了,表示对应的 Binary 是可写的(即预分配了空间并且可以向后追加内容),而且当前有人正在写入内容。
空间都分配好了之后,bs_put_string 指令将字符串 1,2,3 填充在正确的位置。最后将新创建的 ErlSubBin 设置为结果返回,也就是说 Bin1 实际上是一个 sub binary。
接下来看运行 Bin2 = <<Bin1/binary, 4, 5, 6>> 之后会发生什么,如下图所示:
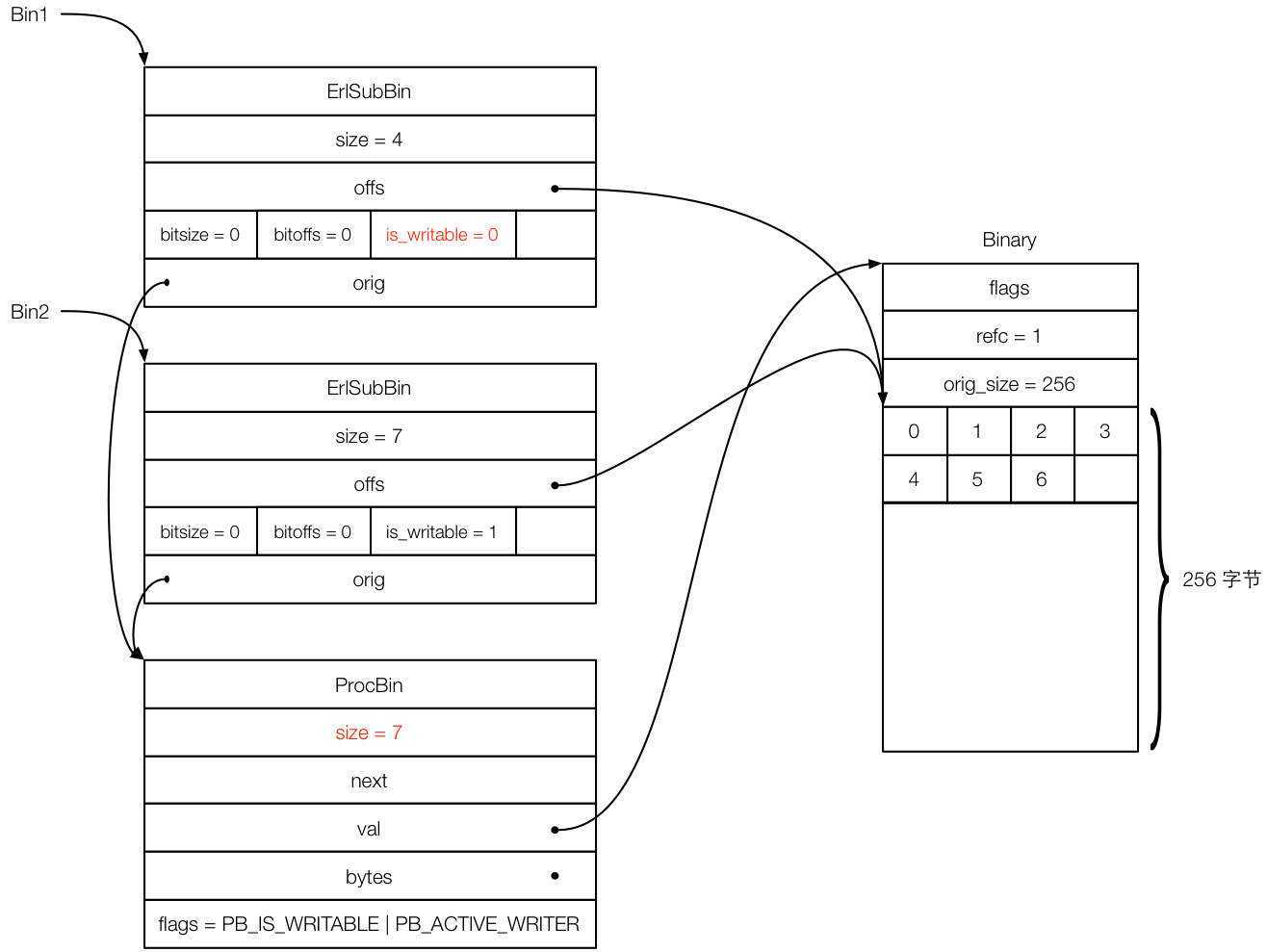
前面费了这么大的功夫,就是为了后续的 binary 追加操作能更加高效。从上图可以看出,Bin2 只创建了一个 ErlSubBin,而且 bs_put_string 仍然在之前预分配的空间中写入,避免了分配内存的操作。Bin2 怎么知道之前已经预分配了内存呢?这是因为 bs_append 在追加 Bin1 的时候,发现 Bin1 是一个 sub binary,而且 is_writable 设置为 1,所以 bs_append 就知道可以继续在后面追加了,而且在追加上下文中都设置好了各种偏移指针,bs_put_string 可以轻松填入内容。这里还要特别注意,bs_append 在创建自己的 ErlSubBin 之前,还把 Bin1 对应的那个 ErlSubBin 的 is_writable 设置为 0,即不可写了。这样就可以保证后面如果有继续追加 Bin1 的操作的时候,当前这个 Binary 在 Bin1 之后的内容不会被覆盖掉,bs_append 会创建出一套新的上述对象“三件套”(ProcBin、ErlSubBin 和 Binary),然后将 Bin1 的内容复制到新的 Binary 中。后面创建 Bin4 的时候就会发生这样的操作。
接下来是创建 Bin3,运行 Bin3 = <<Bin2/binary, 7, 8, 9>>,如下图所示:
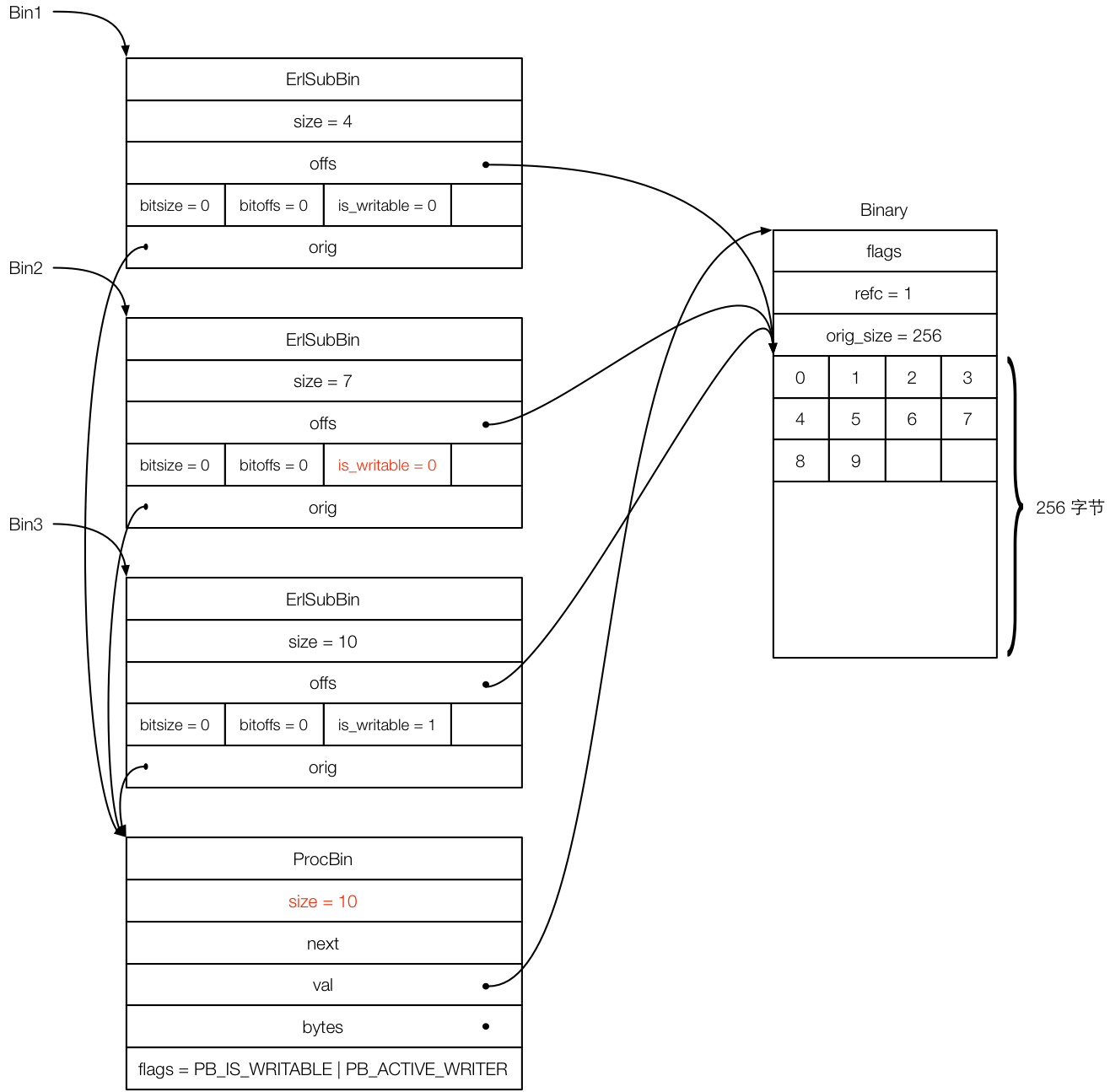
和 Bin2 的创建一样,Bin3 再一次享受到了内存预分配的好处,只需要在进程堆中弄一个新的 ErlSubBin即可,然后把 Bin2 的那个 sub binary 设置为不可写,最后填入要追加的字节。
在享受这种优化的时候,如果 Binary 空间不够用了怎么办?没事,只要把所需字节数翻倍一下,然后 realloc 一个 Binary 对象即可,同时要修改 ProcBin 中的 val 和 bytes 字段。由于在整个过程中,Binary 中的引用计数 refc 一直为 1,只有一个 ProcBin 引用了这个 Binary,所以只需要修改一个 ProcBin 中的字段。虽然图中的 ErlSubBin 中也有字段 offs 指向了 Binary 中的缓冲区,不过这个不用管,因为 offs 是索引值,图中的 offs 后面的箭头并不表示指针。
根据前面的描述,每次 bs_append 享受追加优化的时候都要把之前被追加的那个 sub binary 改成不可写,所以在运行 Bin4 = <<Bin1/binary, 17>> 的时候,Bin1 已经是不可写的 sub binary 了,所以创建 Bin4 的时候要创建全新的“三件套”,这些新创建的对象和之前上面图中的那些对象就没有关系了,而且结构是一样的,所以本文就省略 Bin4 的图示了。
可写 binary 的降级
从上面的讨论我们可以看出,如果有追加 binary 的操作,refc binary 的数据缓冲区一不小心就变得好大,而且是 double 的那种变大。如果被追加的 binary 本来就是很小的 heap binary,那么被追加之后就会变得好几倍大(256 字节)。这种优化虽然方便了往后面追加,但是这种优化除了会占用了额外的空间之外,根据前面的讨论,还有一个限制,那就是可追加的 refc binary 对应的底层 Binary 只能有一个 ProcBin 引用。因此在进行某些操作的时候,Erlang 虚拟机会对 refc binary 进行降级(emasculate)操作。比如说发送消息的时候:在同一个 Erlang 节点中一个进程向另一个进程发送 refc binary 的时候,实际上只有 ProcBin 参与了复制,所以 Binary 对象的引用计数 refc 会增加 1。如果这时这个 refc binary 预留了空间并且正在被追加,那么为了保证后续操作的正确性,Erlang 虚拟机会将这个 refc binary 降级。
看下面的例子:
1 bs_emasculate(Bin0) -> 2 Bin1 = <<Bin0/binary, 1, 2, 3>>, 3 NewP = spawn(fun() -> receive _ -> ok end end), 4 io:format("Bin1 info: ~p~n", [erts_debug:get_internal_state({binary_info, Bin1})]), 5 NewP ! Bin1, 6 io:format("Bin1 info: ~p~n", [erts_debug:get_internal_state({binary_info, Bin1})]), 7 Bin2 = <<Bin1/binary, 4, 5, 6>>, 8 io:format("Bin2 info: ~p~n", [erts_debug:get_internal_state({binary_info, Bin2})]), 9 Bin2.
输出如下所示:
437> bin_test:bs_emasculate(<<0>>).
Bin1 info: {refc_binary,4,{binary,256},3}
Bin1 info: {refc_binary,4,{binary,4},0}
Bin2 info: {refc_binary,7,{binary,256},3}
<<0,1,2,3,4,5,6>>
代码中第 2 行 Bin1 会变成可写的 sub binary,从输出的第 2 行可以看出来。第 5 行将 Bin1 作为消息发送出去,发送之前 Erlang 虚拟机会将 Bin1 降级,从输出的第 6 行我们可以看出 Bin1 现在没有预留空间了,而且 ProcBin 的 flags 标志位也被清零了。
可写 binary 降级是 erts/emulator/beam/erl_bits.c 文件中的 erts_emasculate_writable_binary() 函数实现的。在整个 OTP 源码中可以找到下面的位置中调用了这个降级函数:
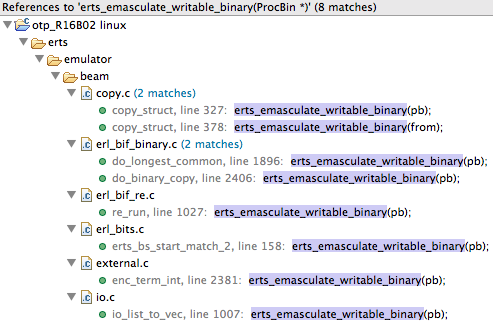
可以看出有几个地方会对可写的 binary 进行降级
- copy_struct 是对 Eterm 树形结构的复制,例如发送消息的时候会调用 copy_struct
- 几个 binary 相关的 bif
- 正则表达式 re 库的 bif 实现
- binary 匹配操作,因为匹配上下文中会引用 Binary
- 转换至外部 Eterm 格式的时候,在分布式 Erlang 中,节点之间传递 Eterm 采用的是外部 Eterm 格式
- 虚拟机将 iolist 输出到 port 的时候(通过 iovec 输出)
当然上面的列表仅供参考,具体的行为还请参阅相关的源代码,本文就不详述了,以后如果写博文介绍到相关内容的时候再详述。可写的 binary 被降级之后,之后的追加操作又会创建新的“三件套”,并且复制被降级的 binary。
另外,在 gc 的时候可能会缩小(shrink)。预分配的 Binary 缓冲区毕竟占用空间,因此 Erlang 进程在进行垃圾回收的时候也会考虑缩小预留的这一部分的空间。
看下面的例子:
1 bs_shrink(Bin0) -> 2 Bin1 = <<Bin0/binary, 1, 2, 3>>, 3 io:format("Bin1 info: ~p~n", [erts_debug:get_internal_state({binary_info, Bin1})]), 4 erlang:garbage_collect(), 5 io:format("Bin1 info: ~p~n", [erts_debug:get_internal_state({binary_info, Bin1})]), 6 erlang:garbage_collect(), 7 io:format("Bin1 info: ~p~n", [erts_debug:get_internal_state({binary_info, Bin1})]), 8 ok.
第 2 行产生了一个可写的 Bin1,然后连续强制进行两次垃圾回收,每一次回收之后都查看一下 Bin1 的状态,输出如下所示:
438> bin_test:bs_shrink(<<0>>).
Bin1 info: {refc_binary,4,{binary,256},3}
Bin1 info: {refc_binary,4,{binary,256},1}
Bin1 info: {refc_binary,4,{binary,24},1}
ok
挺有意思的,第一次垃圾回收只是去掉了 ProcBin 中 PB_ACTIVE_WRITER 标志位,但是空间没有缩小。第二次垃圾回收则真正回收了空间,但是并没有缩减到真实数据的大小,而是还保留了一部分预留空间。后面再调用强制垃圾回收也不会再缩减 Binary 缓冲区的空间了。第一次回收和第二次回收的区别可能在于 minor gc 和 major gc 吧,我还没有完全弄清楚 Erlang gc 的工作细节,所以不好妄下结论了,以后弄清楚了再写文章讨论。关于缩小后的 Binary 缓冲区大小,有兴趣的读者可以参阅 erts/emulator/beam/erl_gc.c 文件中的 sweep_off_heap 函数,这个函数清理的是进程堆中的 off-heap 数据。在“If we got any shrink candidates, check them out.” 这段注释文字之后的代码就是计算缩小后的大小并分配新 Binary 的代码。
接下来讨论 binary 的另外一项重要操作:模式匹配。模式匹配会用到 header 标签为 0001 的 boxed 对象。
binary 匹配
这一部分依然采用“Erlang 代码片段 -> beam 汇编码 -> 虚拟机代码”的方式研究 binary 匹配的实现。
这里用的 Erlang 代码片段依然是效率指南上面的例子,如下所示:
1 my_binary_to_list(<<H, T/binary>>) -> 2 [H|my_binary_to_list(T)]; 3 my_binary_to_list(<<>>) -> [].
这段代码的意图是将一个 binary 转换为一个列表,每一次调用从 binary 的头部取出一个字节出来,然后放到结果列表的头部。这个操作本身在 Erlang 中现在是通过 BIF 实现的,在虚拟机中直接用 C 语言操纵数据结构的效率更高。不过这个纯 Erlang 的实现效率也很高,得益于聪明的 Erlang 编译器和优化的虚拟机。下面我们来看 Erlang 对这种应用模式的优化。编译器生成的 beam 汇编码及注释如下图所示:

第 1 步创建匹配上下文,标志着下面要开始进行匹配操作了。 实际上在虚拟机层面,bs_start_match2 指令是优化的,只有在这个递归函数(例如本例中的 my_binary_to_list)第一次调用的时候才会真正创建匹配上下文。执行这条指令的时候,x[0] 传入的参数是一个 binary(不论是什么类型的,sub binary、heap binary 或是 refc binary)或匹配上下文,这条指令对应的虚拟机代码(process_main() 函数中的 OpCase(i_bs_start_match2_rfIId))会判断传入的是 binary 还是匹配上下文。如果是 binary,则调用 erts_bs_start_match_2() 函数创建新的匹配上下文。从上面的汇编码中可以看出,这个新创建的匹配上下文一直在 x[0] 寄存器中,之后再 call 这个函数的时候 x[0] 中就是一个匹配上下文了,bs_start_match2 指令碰到传入匹配上下文的时候基本啥都不用做,可以完全复用第一次创建的数据结构,因此效率很高。
第 2 步就在进行真正的匹配操作,bs_get_integer2(如果是其他数据类型,也有对应的指令)指令试图取出一个字节。注意这条指令接受了 x[0] 作为参数,而 x[0] 中当前保存的就是匹配上下文,因此 bs_get_xxx 系列指令从 binary 中获取了正确的数据之后,还要修改匹配上下文中的信息(详见后述)。
匹配上下文对应的数据结构是 ErlBinMatchState,如下所示:
1 typedef struct erl_bin_match_buffer { 2 Eterm orig; /* Original binary term. */ 3 byte* base; /* Current position in binary. */ 4 Uint offset; /* Offset in bits. */ 5 size_t size; /* Size of binary in bits. */ 6 } ErlBinMatchBuffer; 7 8 typedef struct erl_bin_match_struct{ 9 Eterm thing_word; 10 ErlBinMatchBuffer mb; /* Present match buffer */ 11 Eterm save_offset[1]; /* Saved offsets */ 12 } ErlBinMatchState;
了解了 binary 匹配的工作方式及需求之后就很容易理解 ErlBinMatchState 这个数据结构了。和其他 boxed 对象一样,thing_word 是对象的 header,其中包含 arity 和标签,匹配上下文的标签是 0001。通过 mb 中的 base 指针可以快速访问 binary 数据所在的缓冲区。对于匹配操作来说,offset 和 size 两个字段非常重要。offset 表示下一次在 binary 数据中要进行匹配的位置。初始化的时候自然为 0,然后 bs_get_xxx 系列的指令在成功从中匹配所需求的数据之后要负责更新这个 offset。通过 size 则可以快速获得 binary 的大小信息。要注意,offset 和 size 的单位都是位,因此可以方便地适用于 binary 和 bitstring。后面的 saved_offset[] 数组是一个用于保存之前用过的 offset 的缓冲区。大部分情况下这个数组大小默认为 1,bs_start_match2 有一个参数可以设置这个数组的大小。bs_save2 和 bs_restore2 指令会用到这个数组。具体意义目前我也说不太清,应该是涉及到某一种特定模式的匹配代码。
接下来的步骤在代码注释中都很明确了。
运行到第 7 步的时候,说明函数顺利执行完。x[0] 寄存器原本保存的是表示 ErlBinMatchState 的 Eterm,但是在正常返回的时候,x[0] 修改为表示结果的列表的 Eterm,因此本身只创建了一次的 ErlBinMatchState boxed 对象在函数返回之后就失去引用了,会在恰当的时候被 gc 回收。
上例中步骤 3 之上的框中说明了编译器在这里有一个优化。如果我们调用编译器的时候添加 +bin_opt_info 参数,可以看到编译器在这里输出了一句话:
bin_test.erl:105: Warning: OPTIMIZED: creation of sub binary delayed
说明这里有一个关于 sub binary 的优化。在匹配语句 <<H, T/binary>> 中,剩下的 T 应该是一个 sub binary,但是编译器精明地发现在函数体中并没有使用这个 T,而是直接把这个 T 传递给下一次递归调用做匹配了,因此编译器就不需要在这里创建一个 sub binary。如果编译器无法判定 T 是否会被使用,那么编译器还要创建一个 sub binary,产生额外开销。
最后,我们再来看一下 binary 的 comprehension 构造操作的优化。binary comprehension 的操作同时涉及到了模式匹配和 binary 追加的操作。
binary comprehension 的优化
作为一门函数式语言,Erlang 自然支持 list comprehension,而作为 Erlang 特色的 binary,也提供了高效的 binary comprehension 的支持。想象一个非常简单的需求:对于一个数据块,需要将按照一定数字节(比如说 8)为单位来分块,然后给每一块添加一个前缀(比如说 <<0,1,2>>),最后将这些添加了前缀的分块拼成一个大块。粗看这种需求可以快速写出代码,但是效率可能不高,会涉及到很多重复的拷贝。有了 binary comprehension 的支持,可以写出非常高效简洁的代码,而且只涉及到一次数据拷贝。代码如下[注9]:
1 bc(Input) -> 2 << <<0, 1, 2, Bin:8/binary>> || <<Bin:8/binary>> <= Input >>.
很简单明了,每次从 Input 中取出 8 个字节的 binary,然后在前面追加 <<0,1,2>>,并将所有的块拼接在一起。同样,为了研究其工作原理,我们看编译器输出的 beam 汇编码:

了解了之前的匹配操作之后,这个图应该好理解多了。重点在于两条特殊的指令:bs_init_writable 和 bs_private_append。binary comprehension 的操作是完全可以通过 bs_append 指令实现的,但是 bs_append 是共享的,多个 binary 都可以通过对某一个 binary 进行 bs_append 生成,因此每一次调用 bs_append 都会生成一次 sub binary。而 bs_private_append 则不会,这条指令是被 comprehension 的 binary 私有独享的,因此 bs_init_writable 和 bs_private_append 可以合作高效地构造 binary:bs_init_writable 构造出一个可写的 ProcBin,并且将 ProcBin 标记为 PB_ACTIVE_WRITER,然后分配好最终所需的空间,创建 Binary 对象。bs_private_append 直接在这个 ProcBin 中追加,修改 ProcBin 的大小,然后建立好后续 bs_put_xxx 系列指令所需的上下文,不需要创建 sub binary。可见这一系列效率很高,最终的数据只经历了一次拷贝。
好了,以上就是 Erlang 中 binary 数据结构的实现以及相关优化。虽然我不保证这些内容的详尽性,但是应该覆盖了大部分重要的内容。我们研究优化,不仅是为了了解和学习 Erlang 虚拟机中所做使用的各种技巧,更重要的是通过了解这些实现和优化,我们能更清楚地了解虚拟机的限制,知道 Erlang 虚拟机在执行我们编写的代码的时候会进行什么样的操作,从而帮助我们编写更高效的代码(即避免编写低效的代码)。
[注5] http://blog.yufeng.info/archives/2903
[注6] 关于 Erlang 汇编码(beam 抽象码及虚拟机执行的汇编码)的格式和反汇编可以参考 http://blog.yufeng.info/archives/34 和 http://blog.yufeng.info/archives/498 。在 http://erlangonxen.org/more/beam 可以找到大部分 beam 抽象码和虚拟机汇编码的功能说明即参数说明。
[注7] http://www.erlang.org/doc/efficiency_guide/binaryhandling.html
[注8] http://blog.yufeng.info/archives/2988
[注9] http://erlang.org/pipermail/erlang-questions/2013-April/073263.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号