二 Hive分桶
二.Hive分桶
1.创建分桶表
create table t_buck (id string ,name string) clustered by (id) //根据id分桶 sorted by (id) //根据id排序 into 4 buckets //分为4个桶 row format delimited fields terminated by ',';
向创建的分桶表中插入数据需要是已分桶且排序的。通常是将其他表查询的结果插入桶中才会执行分桶操作。分桶的原理和分区原理差不多,类似HashPartitioner。
2.向分桶表中导入其他表查询后的数据
select id ,name from t_shizhan01 distribute by (id) sort by (id);
或者
insert into t_buck select id ,name from t_shizhan01 cluster by (id);
可以使用distribute by(id) sort by(id asc) 或是排序和分桶的字段相同的时候使用Cluster by(字段)
注意使用cluster by 就等同于分桶+排序(sort)
3.设置变量,设置分桶为true, 设置reduce数量是分桶的数量个数
set hive.enforce.bucketing = true;
set mapreduce.job.reduces=4;
设置是否分桶及设置reduce的数量。在创建表的时候设置的分桶数量要和此处设置的相匹配,如果此处不设置reduce数量和是否分桶,表对应的空间中只会有一个桶。
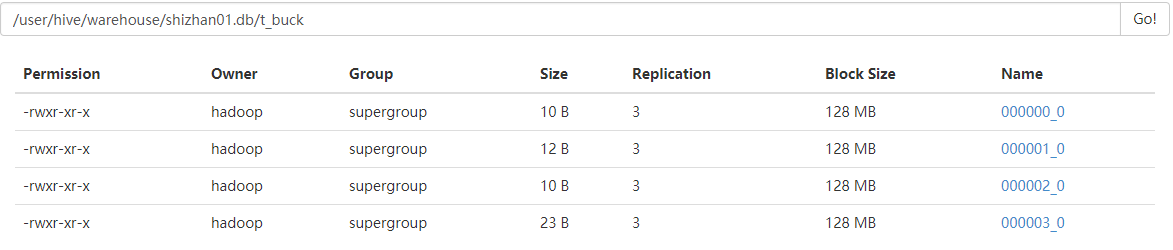
执行插入操作后hdfs目录如下: