

python自动化运维二:业务服务监控
一文件比较:
在实际维护过程中,涉及到许多文件对比的操作。在Linux下,自带diff命令,比较两个文件的结果如下。
其中a,d,c分别表示添加,删除,及修改操作。1,2c1,2中的1,2代表的是行号。从diff这个命令来看,其实不太直观。
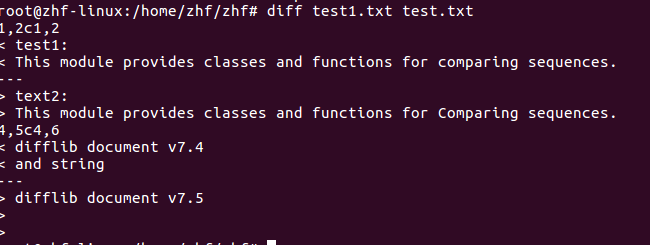
我们用python中自带的difflib模块来做下对比:用同样的两段文本
import difflib
if __name__=="__main__":
text1="""text1:
This module provides classes and functions for comparing sequences.
including HTML and context and unified diffs
difflib document v7.4"""
text1_lines=text1.splitlines()
text2="""test2:
This module provides classes and functions for Comparing sequences.
including HTML and context and unified diffs
difflib document v7.5"""
text2_lines=text2.splitlines()
d=difflib.Differ()
diff=d.compare(text1_lines,text2_lines)
print '\n'.join(list(diff))
运行结果:
- text1:
+ test2:
- This module provides classes and functions for comparing sequences.
? ^
+ This module provides classes and functions for Comparing sequences.
? ^
including HTML and context and unified diffs
- difflib document v7.4
? ^
+ difflib document v7.5
? ^
其中-代表包含在第一个序列行中,但不包含在第二个序列行。
+包含在第二个序列行中,但不包含在第一个序列行
‘’两个序列行 一致
‘?’两个序列行存在增量差异
‘^’两个序列行存在的差异字符。
difflib的对比结果比diff中的更直观一些。我们还可以将结果更加美化一下。输出一个HTML文档
代码修改为:
d=difflib.HtmlDiff()
print d.make_file(text1_lines,text2_lines)
make_file得到的是html代码。将代码copy到文件中。打开得到的结果如下:

下面来介绍另一个比较模块:filecmp
当进行代码文件审查时,往往要检查原始与目标文件的一致性。包括修改时间,访问时间等等。这里就要用到filecmp。
1 首先来看下单文件对比:
def file_cmp_try():
print 'test os.stat result %s' % os.stat('/home/zhf/zhf/test.txt') #打印出os.stat的结果
print 'test1 os.stat result %s' % os.stat('/home/zhf/zhf/test1.txt')
print filecmp.cmp('/home/zhf/zhf/test.txt','/home/zhf/zhf/test1.txt')
if __name__=="__main__":
file_cmp_try()
test os.stat result posix.stat_result(st_mode=33204, st_ino=6036599L, st_dev=2049, st_nlink=1, st_uid=1000, st_gid=1000, st_size=145L, st_atime=1501998994, st_mtime=1501998985, st_ctime=1501998986) #test的os.stat结果
test1 os.stat result posix.stat_result(st_mode=33204, st_ino=6037307L, st_dev=2049, st_nlink=1, st_uid=1000, st_gid=1000, st_size=154L, st_atime=1501998992, st_mtime=1501998920, st_ctime=1501998920) #test1的os.stat结果
False
cmp会根据os.stat的结果来进行比较,如果相等则会返回True,不相等则返回False。 另外cmp还有一个参数shallow. 这个参数默认为True表示不对文件内容进行对比。如果为False 则会对文件内容也进行比较。
2 多文件对比filecmp.cmpfiles
def file_cmp_try():
print filecmp.cmpfiles('/home/zhf/zhf','/home/zhf/zhf/python_prj',['test.txt','chapter1.py'])
if __name__=="__main__":
file_cmp_try()
结果为3个列表,分别表示匹配,不匹配,错误。错误列表包括了目录中不存在的文件,不具备读权限或其他原因导致的不能比较的文件清单。从下面的结果来看都是在错误的列表。原因在于/home/zhf/zhf/python_prj中并没有包含chapter1.py
([], [], ['test.txt', 'chapter1.py'])
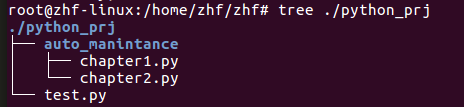
3目录比较:
tree命令可以直观的查看文件路径的结构,但是不能进行对比输出
def file_cmp_try():
dir_ret=filecmp.dircmp('/home/zhf/zhf/python_prj','/home/zhf/zhf/python_source')
print dir_ret.report()
if __name__=="__main__":
file_cmp_try()
输出结果:report 中输出了哪些是路径下特有的文件。
diff /home/zhf/zhf/python_prj /home/zhf/zhf/python_source
Only in /home/zhf/zhf/python_prj : ['auto_manintance', 'test.py']
Only in /home/zhf/zhf/python_source : ['Django-1.10.3', 'Django-1.10.3.tar.gz', 'curl-7.36.0', 'curl-7.36.0.tar.gz', 'dnspython-1.9.4', 'dnspython-1.9.4.tar.gz', 'psutil-2.0.0', 'psutil-2.0.0.tar.gz', 'pycurl-7.19.3.1', 'pycurl-7.19.3.1.tar.gz', 'scapy-2.2.0', 'scapy-2.2.0.tar.gz']
None
二:发送 邮件
电子邮件是现在工作中不可缺少的工具。在自动化和运维上,也常常用邮件来发送告警信息,业务质量报表等。电子邮件的协议主要有SMTP,POP3
SMTP 的全称是“Simple Mail Transfer Protocol”,即简单邮件传输协议。它是一组用于从源地址到目的地址传输邮件的规范,通过它来控制邮件的中转方式。SMTP 协议属于 TCP/IP 协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。SMTP 服务器就是遵循 SMTP 协议的发送邮件服务器。
POP3是Post Office Protocol 3的简称,即邮局协议的第3个版本,它规定怎样将个人计算机连接到Internet的邮件服务器和下载电子邮件的电子协议。它是因特网电子邮件的第一个离线协议标准,POP3允许用户从服务器上把邮件存储到本地主机(即自己的计算机)上,同时删除保存在邮件服务器上的邮件,而POP3服务器则是遵循POP3协议的接收邮件服务器,用来接收电子邮件的
看了上面的介绍。可以看出SMTP是发送邮件的,POP3是接受邮件的。首先来看下python发送邮件的几个步骤和调用的模块。python调用smtplib模块来进行邮件发送。
主要是下面的几个步骤:
1 SMTP.connect(host,port): 远程连接smtp主机,其中host为主机地址,port为端口。这个主机地址不是我们在浏览器中输入的mail.163.com这种地址,而是像smtp.163.com或者smtp.qq.com. 端口都是默认的25
2 SMTP.login(user,password):参数为用户名和密码
3 SMTP.sendmail(from_addr,to_addr, msg): 其中from_addr是发件人,to_addr是收件人。msg是邮件正文。
4 SMTP.quit():断开smtp服务器的连接。
来看一个具体的实例:
def send_email():
server='smtp.163.com'
from_addr='maple412@163.com'
to_addr='179039149@qq.com'
username='xxxxx
password='xxxxx'
subject='python send email test'
content='just for test'
msg=MIMEText(content)
msg['Subject']=Header(subject)
msg['From']=from_addr
msg['To']=to_addr #可以是多个收件地址,每个地址间用,分开即可
smtp=smtplib.SMTP()
smtp.connect(server)
smtp.login(username,password)
smtp.sendmail(from_addr,to_addr,msg.as_string())
查看邮件,收到一封来自163的邮件
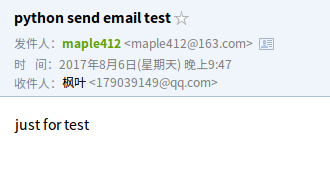
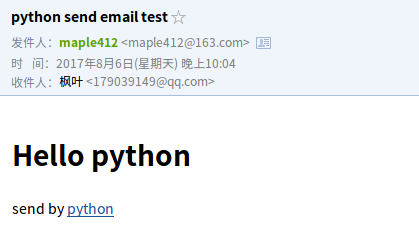
上面的邮件只是发送的一个普通的文本字符。如果我们想发送一个网页版的该如何操作呢。其实只需要修改下MIMEText中的内容即可。总共需要两次代码需要修改。将网页代码复给content
content='''<html><body><h1>Hello python</h1><p>send by <a href="http://www.python.org">python</a></p></body></html>
'''
msg=MIMEText(content,'html') #MIMEText中第二个参数赋值为html。参数默认为plain.
邮件效果如下图:
接下来再看下邮件中带附件:带附件的邮件可以被看做包含若干部分的邮件。文本和各个附件本身。所以可以构造一个MIMEMultipart来代表邮件。然后往里面加上一个MIMEText作为邮件正文。再继续往里面加上表示附件的MIMEApplication对象就可以了
server='smtp.163.com'
from_addr='maple412@163.com'
to_addr='179039149@qq.com'
username='xxxxxxx'
password='xxxxxxx'
subject='python send email test'
msg=MIMEMultipart() #在这里,msg是一个多部分组成的
msg['Subject']=subject
msg['From']=from_addr
msg['To']=to_addr
att1=MIMEApplication(open('/home/zhf/zhf/test.txt','rb').read())
att1.add_header('Content-Disposition','attachment',filename='test.txt')
msg.attach(att1)
try:
smtp=smtplib.SMTP()
smtp.connect(server)
smtp.login(username,password)
smtp.sendmail(from_addr,to_addr,msg.as_string())
smtp.quit()
except BaseException,e:
print e
效果如下。
当然 也可以既然发送截图,有发送正文。只需要另外再加上一个MIMEText就可以了:
att2=MIMEText(content,'html')
msg.attach(att2)
同样的这个附件可以是XLSX,jpg以及MP3的文件。
在定制报表的时候,经常在邮件正文中发送图片。我们来看下这是如何实现的:
def send_email_with_picture():
server='smtp.163.com'
from_addr='maple412@163.com'
to_addr='179039149@qq.com'
username='xxxxxxxxx'
password='xxxxxxxxx'
subject='python send email test'
content='''<html><body><h1>Hello python</h1><img src="cid:io"></body></html>
'''
#在网页代码中,src=”cid:io”,网页中嵌入图片是通过cid来索引到具体的图片,在这里cid引用的是io的图片。
msg=MIMEMultipart()
msg['Subject']=subject
msg['From']=from_addr
msg['To']=to_addr
p=open('/home/zhf/Pictures/1.jpg','rb')
msgimage=MIMEImage(p.read()) #创建一个图片对象
p.close()
msgimage.add_header('Content-ID','io') #在这里设置图片对象的cid为io. 便于被网页代码引用
msg.attach(msgimage)
msgtext=MIMEText(content,'html','utf-8')
msg.attach(msgtext)
try:
smtp=smtplib.SMTP()
smtp.connect(server)
smtp.login(username,password)
smtp.sendmail(from_addr,to_addr,msg.as_string())
smtp.quit()
except BaseException,e:
print e
效果如下:
最后介绍一个web监控函数:pycurl. 这相当于Linux命令curl的python实现
def web_detect_function():
url="www.sina.com.cn"
c=pycurl.Curl()
c.setopt(pycurl.URL,url)
c.setopt(pycurl.CONNECTTIMEOUT,5)
c.setopt(pycurl.TIMEOUT,5)
c.setopt(pycurl.NOPROGRESS,1)
c.setopt(pycurl.FORBID_REUSE,1)
c.setopt(pycurl.MAXREDIRS,1)
c.setopt(pycurl.DNS_CACHE_TIMEOUT,30)
#setopt是设置各项下载的参数
try:
c.perform()
except Exception,e:
print e
NAMELOOKUP_TIME=c.getinfo(c.NAMELOOKUP_TIME)
CONNECT_TIME=c.getinfo(c.CONNECT_TIME)
TOTAL_TIME=c.getinfo(c.TOTAL_TIME)
HTTP_CODE=c.getinfo(c.HTTP_CODE)
HEADER_SIZE=c.getinfo(c.HEADER_SIZE)
SPEED_DOWNLOAD=c.getinfo(c.SPEED_DOWNLOAD)
#getinfo是得到网页浏览的各项参数
print 'NAMELOOKUP TIME:%d' % NAMELOOKUP_TIME
print 'CONNECT TIME:%d' % CONNECT_TIME
print 'TOTAL TIME:%d' % TOTAL_TIME
print 'HTTP_CODE:%s' % HTTP_CODE
print 'HEADER_SIZE:%d' % HEADER_SIZE
print 'SPEED_DOWNLOAD:%d' % SPEED_DOWNLOAD
c.close()
运行结果:
NAMELOOKUP TIME:0
CONNECT TIME:0
TOTAL TIME:0
HTTP_CODE:200
HEADER_SIZE:709
SPEED_DOWNLOAD:1145386

