
基于RBM的推荐算法
很多人讲RBM都要从能量函数讲起,由能量最低导出极小化目标函数(你听说过最常见的建立目标函数的方法可能是最小化平方误差或者最大化似然函数),然后用梯度下降法求解,得到网络参数。Introduction to Restricted Boltzmann Machines这篇博客没有遵循这种套路来讲RBM,它直接给RBM网络权重的训练方法,讲得浅显易懂,清新脱俗。本文只是对英文版的翻译。
在基于LFM(Latent Factor Model)的推荐算法一文中我们介绍了用因子分析法来做推荐。比如用户购买了《推荐系统实践》、《用Python做数据分析》,背后的隐藏因子是数据挖掘;用户购买了《一课经济学》、《郎咸平说》,背后的隐藏因子是经济学。因子分析法就是找到用户对各个隐藏因子的喜好程度$U=(uf_1,uf_2,...,uf_n)$,以及商品在各个隐藏因子上的概率分布$I=(if_1,if_2,...,if_n)$,然后两个向量做乘法即得到用户对商品的喜好程度。RBM可以理解为一种二值化的因子分析法(当然RBM还有其他的理解方式)。先来一张图看看RBM的网络结构。
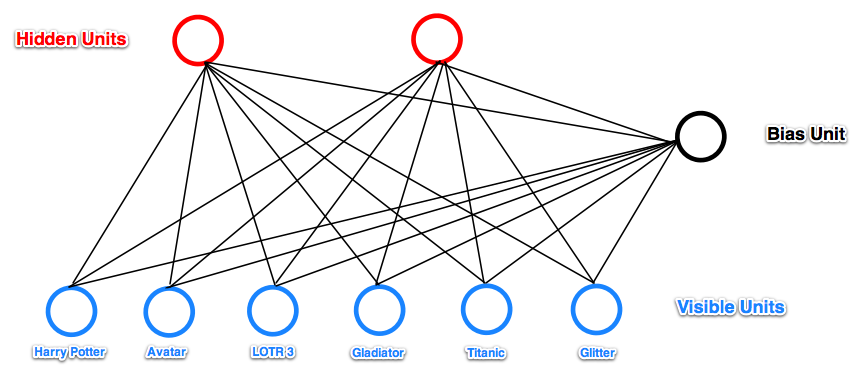
- 它只有两层:可视层和隐藏层,两层之间是全连接。另有一个偏置单元,跟所有的可视单元和隐藏单元都有连接。可视层之间、隐藏层之间无连接。
- 所有连接都是双向的,并且是带权重的。
- 所有神经元的状态只有0和1两种。
- RBM是一个随机网络,即所有神经元以一个概率值选择状态为0还是1。偏置单元是个例外,它总为1。偏置单元用来反应商品固有的受欢迎程度,所谓“固有”就是跟外界无关,反应到RBM网络里面就是隐藏单元的状态并不是完全由可视层决定的,也由隐藏层神经元自身固有的一些因素决定,这些固有的因素就由偏置单元来承载。反过来对于可视层也一样,可视层神经元固有的受欢迎程度由偏置单元来承载。我们在带偏置的LFM中也说明了偏置的作用。
RBM的运作方式
可视层的神经元用$x_i$表示,隐藏层神经元用$x_j$表示,它们之间的权重用$w_{ij}$表示,可视层神经元个数为$m$,隐藏层神经元个数为$n$。当给定可视层状态后,用下式更新隐藏层的状态。
\begin{equation}net_j=\sum_{i=0}^m{x_i{w_{ij}}}\end{equation}$x_0$是偏置单元,总为1
\begin{equation}prob(j)=sigmoid(net_j)=\frac{1}{1+e^{-net_j}}\end{equation}
$x_j$以概率$prob(j)$取1,以概率$1-prob(j)$取0。
$sigmoid$函数关于(0,0.5)这一点中心对称,$x$为正时$sigmoid(x)>0.5$,$x\to\infty$时$sigmoid(x)\to{1}$。
根据隐藏层求可视层方式雷同,就不写公式了。
对于推荐系统来说,我们知道用户购买了哪些商品,将对应的可视层神经元置为1,其他置为0,求出隐藏层状态,由隐藏层再返回来求可视层状态,这个时候可视层哪些神经元为1我们就把相应有商品推荐给用户。
权重学习方法
训练RBM网络就是训练权重$w_{ij}$。首先随机初始化$w_{ij}$,然后每一次拿一个样本(即可视层是已知的)经历下面的步骤。
- 由可视层的$x_i$算出隐藏层的$x_j$,令$w_{ij}$的正向梯度为\begin{equation}positive(w_{ij})=x_i*{x_j}\end{equation}
- 由隐藏层$x_j$再来反向计算$x’_i$,注意此时算出的$x’_i$跟原先的$x_i$已经不一样了,令$w_{ij}$的负向梯度为\begin{equation}negative(w_{ij})=x'_i*{x_j}\end{equation}
- 更新权重\begin{equation}w_{ij}=w_{ij}+\alpha*(positive(w_{ij})-negative(w_{ij}))\end{equation}
我们不去深究为什么正向梯度和负向梯度是这样一个公式。上述学习方式叫对比散度(contrastive divergence)法。
循环拿样本去训练网络,不停迭代,直到收敛(即$x’_i$和$x_i$很接近)。
实践中的优化
- 上面讲述中我们拿$x_i$去RBM网络中返回一次得到$x’_i$,然后就开始计算$negative(w_{ij})$,改进方法是多往返几次后再计算$negative(w_{ij})$。
- 计算$positive(w_{ij})$时用$prob(i)*prob(j)$,而非$x_i*{x_j}$。$negative(w_{ij})$同样。
- 加正则项,对较大的权重$w_{ij}$进行惩罚。
- 更新$w_{ij}$时加动量向,即本次前进的方向是本次的梯度与上次迭代中梯度的线性加权。
- 每次调整权重时使用一批样本,而非不一个样本。虽然计算结果是一样的,但由于numpy对矩阵乘法做了加速优化,比逐个计算向量乘法要快。
rbm.py
# coding=utf-8
__author__ = "orisun"
import numpy as np
class RBM(object):
def __init__(self, num_visible, num_hidden, learn_rate=0.1, learn_batch=1000):
self.num_visible = num_visible # 可视层神经元个数
self.num_hidden = num_hidden # 隐藏层神经元个数
self.learn_rate = learn_rate # 学习率
self.learn_batch = learn_batch # 每次根据多少样本进行学习
'''初始化连接权重'''
self.weights = 0.1 * \
np.random.randn(self.num_visible,
self.num_hidden) # 依据0.1倍的标准正太分布随机生成权重
# 第一行插入全0,即偏置和隐藏层的权重初始化为0
self.weights = np.insert(self.weights, 0, 0, axis=0)
# 第一列插入全0,即偏置和可视层的权重初始化为0
self.weights = np.insert(self.weights, 0, 0, axis=1)
def _logistic(self, x):
'''直接使用1.0 / (1.0 + np.exp(-x))容易发警告“RuntimeWarning: overflowencountered in exp”,
转换成如下等价形式后算法会更稳定
'''
return 0.5 * (1 + np.tanh(0.5 * x))
def train(self, rating_data, max_steps=1000, eps=1.0e-4):
'''迭代训练,得到连接权重
'''
for step in xrange(max_steps): # 迭代训练多少次
error = 0.0 # 误差平方和
# 每次拿一批样本还调整权重
for i in xrange(0, rating_data.shape[0], self.learn_batch):
num_examples = min(self.learn_batch, rating_data.shape[0] - i)
data = rating_data[i:i + num_examples, :]
data = np.insert(data, 0, 1, axis=1) # 第一列插入全1,即偏置的值初始化为1
pos_hidden_activations = np.dot(data, self.weights)
pos_hidden_probs = self._logistic(pos_hidden_activations)
pos_hidden_states = pos_hidden_probs > np.random.rand(
num_examples, self.num_hidden + 1)
# pos_associations=np.dot(data.T,pos_hidden_states) #对隐藏层作二值化
pos_associations = np.dot(
data.T, pos_hidden_probs) # 对隐藏层不作二值化
neg_visible_activations = np.dot(
pos_hidden_states, self.weights.T)
neg_visible_probs = self._logistic(neg_visible_activations)
neg_visible_probs[:, 0] = 1 # 强行把偏置的值重置为1
neg_hidden_activations = np.dot(
neg_visible_probs, self.weights)
neg_hidden_probs = self._logistic(neg_hidden_activations)
# neg_hidden_states=neg_hidden_probs>np.random.rand(num_examples,self.num_hidden+1)
# neg_associations=np.dot(neg_visible_probs.T,neg_hidden_states) #对隐藏层作二值化
neg_associations = np.dot(
neg_visible_probs.T, neg_hidden_probs) # 对隐藏层不作二值化
# 更新权重。另外一种尝试是带冲量的梯度下降,即本次前进的方向是本次梯度与上一次梯度的线性加权和(这样的话需要额外保存上一次的梯度)
self.weights += self.learn_rate * \
(pos_associations - neg_associations) / num_examples
# 计算误差平方和
error += np.sum((data - neg_visible_probs)**2)
if error < eps: # 所有样本的误差平方和低于阈值于终止迭代
break
print 'iteration %d, error is %f' % (step, error)
def getHidden(self, visible_data):
'''根据输入层得到隐藏层
visible_data是一个matrix,每行代表一个样本
'''
num_examples = visible_data.shape[0]
hidden_states = np.ones((num_examples, self.num_hidden + 1))
visible_data = np.insert(visible_data, 0, 1, axis=1) # 第一列插入偏置
hidden_activations = np.dot(visible_data, self.weights)
hidden_probs = self._logistic(hidden_activations)
hidden_states[:, :] = hidden_probs > np.random.rand(
num_examples, self.num_hidden + 1)
hidden_states = hidden_states[:, 1:] # 即首列删掉,即把偏置去掉
return hidden_states
def getVisible(self, hidden_data):
'''根据隐藏层得到输入层
hidden_data是一个matrix,每行代表一个样本
'''
num_examples = hidden_data.shape[0]
visible_states = np.ones((num_examples, self.num_visible + 1))
hidden_data = np.insert(hidden_data, 0, 1, axis=1)
visible_activations = np.dot(hidden_data, self.weights.T)
visible_probs = self._logistic(visible_activations)
visible_states[:, :] = visible_probs > np.random.rand(
num_examples, self.num_visible + 1)
visible_states = visible_states[:, 1:]
return visible_states
def predict(self, visible_data):
num_examples = visible_data.shape[0]
hidden_states = np.ones((num_examples, self.num_hidden + 1))
visible_data = np.insert(visible_data, 0, 1, axis=1) # 第一列插入偏置
'''forward'''
hidden_activations = np.dot(visible_data, self.weights)
hidden_probs = self._logistic(hidden_activations)
# hidden_states[:, :] = hidden_probs > np.random.rand(
# num_examples, self.num_hidden + 1)
'''backward'''
visible_states = np.ones((num_examples, self.num_visible + 1))
# visible_activations = np.dot(hidden_states, self.weights.T) #对隐藏层作二值化
visible_activations = np.dot(hidden_probs, self.weights.T) # 对隐藏层不作二值化
visible_probs = self._logistic(visible_activations) # 直接返回可视层的概率值
return visible_probs[:, 1:] # 把第0列(偏置)去掉
if __name__ == '__main__':
rbm = RBM(num_visible=6, num_hidden=2, learn_rate=0.1, learn_batch=1000)
rating_data = np.array([[1, 1, 1, 0, 0, 0], [1, 0, 1, 0, 0, 0], [1, 1, 1, 0, 0, 0], [
0, 0, 1, 1, 1, 0], [0, 0, 1, 1, 0, 0], [0, 0, 1, 1, 1, 0]])
rbm.train(rating_data, max_steps=500, eps=1.0e-4)
print 'weight:\n', rbm.weights
rating = np.array([[0, 0, 0, 0.9, 0.7, 0]]) # 评分需要做归一化。该用户喜欢第四、五项
hidden_data = rbm.getHidden(rating)
print 'hidden_data:\n', hidden_data
visible_data = rbm.getVisible(hidden_data)
print 'visible_data:\n', visible_data
predict_data = rbm.predict(rating)
print '推荐得分:'
for i, score in enumerate(predict_data[0, :]):
print i, score # 第三、四、五项的推荐得分很高,同时用户已明确表示过喜欢四、五,所以我们把第三项推荐给用户
本文来自博客园,作者:张朝阳讲go语言,转载请注明原文链接:https://www.cnblogs.com/zhangchaoyang/articles/5537643.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号