
增长中的时间序列存储(Scaling Time Series Data Storage) - Part I
2019-03-22 19:30 yx1989 阅读(759) 评论(0) 编辑 收藏 举报本文摘译自 Netflix TechBlog : Scaling Time Series Data Storage — Part I
重点:扩容、缓存、冷热分区、分块。
时序数据 - 会员观看历史
Netflix的用户,每天观看1.4亿小时的内容。每位用户在查看影片和保存观看记录的时候,都会提供几个数据点。Netflix分析这些观看数据并且提供实时的精确书签和个性化推荐。
观看历史数据在如下三个方面增长:
- 随着时间进展,每位会员都会有更多的观看数据需要被保存。
- 随着会员数量增长,更多的会员的观看数据需要被保存。
- 会员每月观看时间在增加,每位会员都有更多的观看数据需要被保存。
随着Netflix在第一个十年增长到了1亿全球会员,这里有观看历史数据也有了巨大的增长。这边文章重点关注,怎样面对持续增长的观看历史数据的巨大挑战。
简单的开始
第一个云原生的版本使用了Cassandra。
在最初的版本里,每位会员的观看数据被以一个单独行保存在了Cassandra里。这使得会员增长的扩容变得很高效,并且读一位会员的完整观看记录变得简单高效。但是随着会员的增加,更重要的是每位会员观看了更多的影片,每行的大小以及总体的大小都在增长。
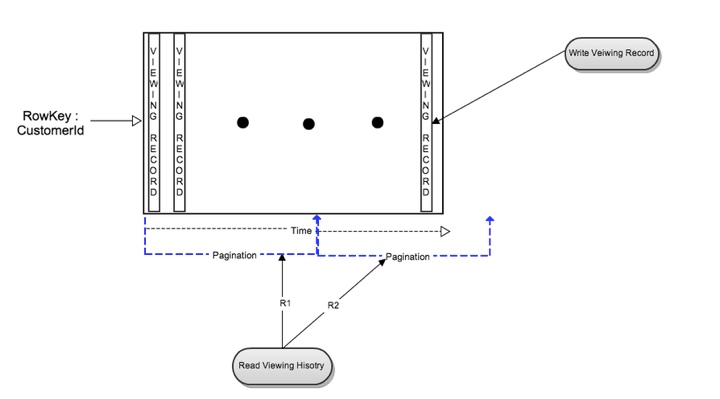
当每位会员的观看数据变多的时候,读有很多列的行就会成为很大的压力。
缓存层
Cassandra在写观看历史数据方面工作的很好,但是需要去优化读延迟的问题。为了优化读延迟,在增加写工作的代价下,我们在Cassandra存储前添加了一个内存中的分片缓存层(EVCache)。每个想Cassandra的写,都会导致一个额外的缓存查找,并且在缓存命中的时候新数据会和已存在的值合并。观看历史读请求会先被缓存服务。如果缓存未命中,条目会从Gassandra中读取,并且被压缩然后插入到缓存中。
配合着额外的缓存层,单一的Cassandra表存储方式在很多年都工作的很好。基于CustomerId的分区,在Cassandra集群上也扩容的很好。到2012年,观看历史的Cassandra集群,已经是Netflix最大的Cassandra集群。
重新设计:实时和压缩存储方式
为了可以设计出足以满足未来5年增长预期的方式,团队分析了数据的特点和数据模式,然后围绕两个主要目标重新设计了观看历史的存储:
- 更小的存储空间。
- 随着每位会员的观看增长,保持读写性能的一致性。
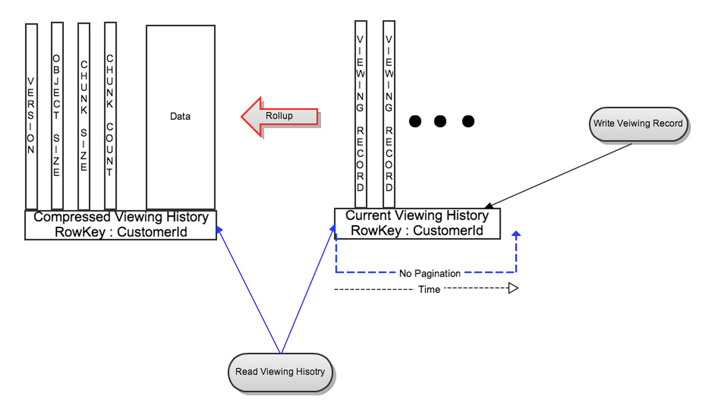
对于每位会员,观看历史数据被分成了两个部分:
- 实时或者最近观看历史(LiveVH): 更少数量的最近观看记录,更频繁的更新。这部分数据以未压缩的格式,保存在上述的简单设计里。
- 压缩或者归档的观看历史(CompressedVH): 更大数量的老观看记录,更少的更新。数据被压缩以减少存储空间。压缩后的观看记录,保存在每个row key中的单一行里。
LiveVH和CompressedVh呗保存在不同的表里,并且经过不同的调校去达到更好的性能。
写流程
新的观看记录,使用和上边描述一样的方式写入LiveVH。
读流程
为了能够从新设计中获益,观看历史的API被更新增加了带有读最近或全部数据的选项。
- 最近观看历史:对于大多数情况,结果只从LiveVH里读取。限制了数据大小以获得低得多的延迟。
- 完整观看历史:从LiveVH 和 CompressedVH 中并行读来实现。由于数据压缩以及CompressedVH有更少的列,更少的数据被读取;因此读速度有了显著的提高。
CompressedVH 更新流程
在从LiveVH中读观看历史记录的时候,如果记录的数量超过了配置的阈值,最近观看记录会一个后台任务被汇总、压缩、保存在CompressedVH里。汇总的数据会带row key:CustomerId被保存在CompressedVH中。新汇总的记录会被记录版本,并且在被写入后会被读取检查一致性。只有在验证过新版本的一致性后,旧版本的汇总数据会被删除。
通过分块自动扩容
对于大部分会员来说,在一行里保存压缩后的全部观影数据,在读流程里有着很好的性能。但是由于少量的有着非常大观影历史的会员来说,从CompressedVH的单行里读取记录由于和上述类似的原因开始变慢。所以需要对这种少见的情况有个上限,并且避免影响到正常情况的读写延迟。
为了解决这些问题,如果数据大小超过了配置的阈值,我们会把汇总压缩的数据分成了几块。这些块保存在不同的Cassandra节点上。这样并行读写这些块使得即使非常大的观看记录也可以有个读写延迟的上限。
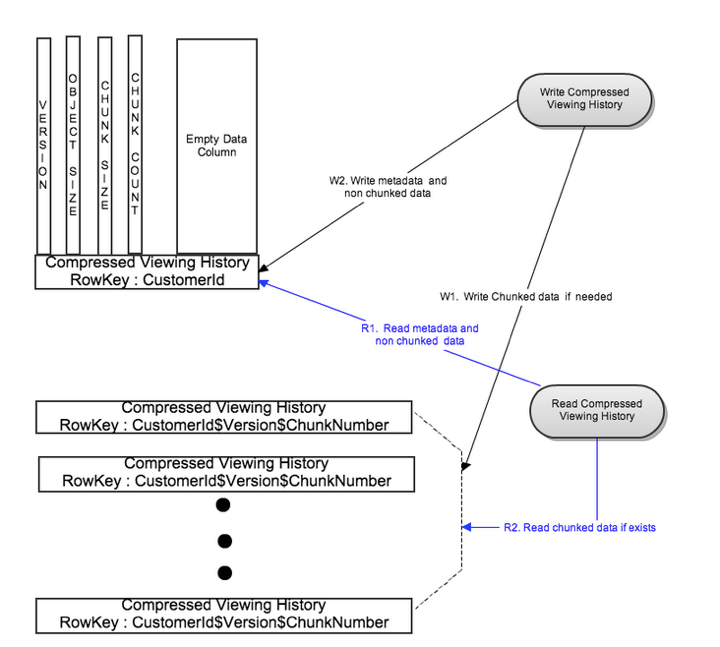
写流程
依照配置的块大小,汇总压缩的数据被拆封到多个块里。所有的块并行写到不同的行里,使用row key: CustomerId$Version$ChunkNumber. 在写完前边的块数据之后,Metadata 被写到他单独的行里,使用row key: CustomerId。
读流程
先通过CustomerId的key读metadata。每次读最多延迟成两次读。
缓存层变化
对于有很大观看记录的会员来说,把全部缓存记录保存在一个EVCache entry是不可能的。所以和CompressedVH模型类似,每个大观看记录缓存单元会被拆成多个块,metadata保存在第一个块里。
结果
在并行,压缩,和改进过的数据模型的共同作用下,这个团队完成了所有的目标。
- 通过压缩打到更小的存储空间
- 通过分块和并写读写,达到了一致性读写性能。
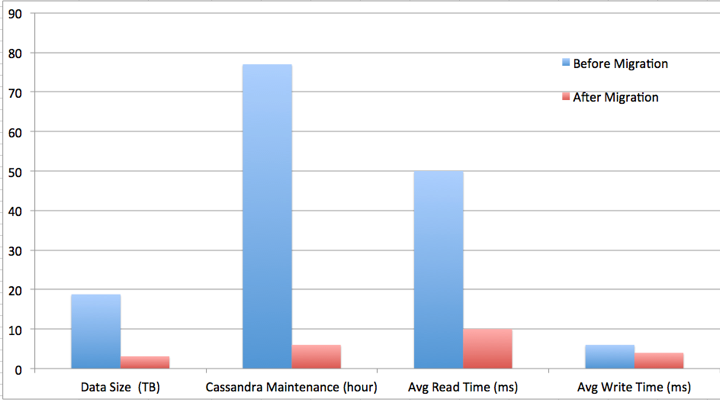
团队减少了6倍的数据空间,减少13倍的Cassandra的维护时间,减小了5倍的平均读延迟,和1.5倍的平均写延迟。更重要的是,给了团队一个可扩容的架构,和课协调Netflix飞速增长的观看数据的头部空间。
在下一部分,会解释最近的扩容挑战,促进了下一个观看历史数据存储架构的迭代。

