前段时间为了做编译器,猛啃了一下编译原理。语法分析部分用的是比较简单上手的LL(1), 自认为LL(1)的理论部分理解得不错,在这里写出来跟大家share一下。
关于什么是LL(1),就不赘述了,书上也说得很清楚,就是从左向右扫描输入,然后产生最左推导(就是每次都把最左边的非终结字符用产生式代替)。
(一)为什么我们需要First集合
比如有产生式 A-> + T | - P , 当我们读到串为 +开头的时候,我们可以很直接地判断选择 A-> + T 这个生成式;串为- 开头的时候,选择 A-> - P 这个生成式。但如果文法是类似于A →T | P 这样的都以非终结字符开头的呢?一眼就很难判断的,我们就需要知道,T 是怎么展开的,如果 T -> a |b ,P->c|d , 那当串以a或b开头的时候,我们显然需要选择A →T ,而当串以c或d开头的时候,就应该选择A->P 这个生成式了。也就是说,我们需要知道T这个分支和P这个分支,都可以用什么终结字符开头。因此我们需要计算每个生成式的开始记号的集合,也就是First集合。
下面给出First集合的算法:
•直接收取:如果存在 T→a … (a为终止符), 把a直接放到First(T)中,很显然A →T | P →a…|P,遇到a的时候走T这条分支
•反复推送: T→E … ,把First(E)的元素加入到First(T)中
这里举个简单的例子:四则运算
•exp→exp addop term | term
•addop→ +| -
•term →term mulop factor | factor
•mulop→∗|/
•factor →(exp)|<number>
把它分解后变成
(1)exp→exp addop term
(2) exp→term
(3) addop→+
(4) addop→-
(5) term→term mulop factor
(6) term→factor
(7) mulop→∗
(8) mulop→/
(9)factor→(exp)
(10) factor→<number>
最容易算的是First(addop)和First(mulop),因为他们的分支都直接以终结字符开始。
First(mulop)={*,/}, First(addop)={+,-}
First(factor)={(,<number>}
term的分支一边是term自己(就是说把term的First内容加到本身,不对自己产生变化),一边是factor(把factor的first集合内容加到term的first集合中),因此First(term)=First(factor) 同理First(exp)=First(term)
当然这个例子只是为了说明First集合的计算,本身存在左递归,是不能做LL1运算的。
(二)感觉First集合已经足够了,为什么还需要Follow集合
其实Follow集合是专门为了空操作而存在的
我们可以来看这个例子:
•A→Tb | P
•T→ε | a
•P→c
我们知道First(T) = {ε , a} Frist(P) = {c},当遇到a开头的串的时候,选择A→Tb,遇到c开头的串,选择 A-> P
但其实,由于ε在First(T) 里,我们可以得到
A→Tb | P →(ε│a)b | P → (b| ab) | c
也就是说,当串以b开头的时候,其实选择的也是A→Tb
所以,为了特殊处理当一个非终结字符可以推出空时候的情况,我们需要知道它后面紧跟的是什么终结符合,这个终结符号也是能被这个串所直接接收的。
•定义:FOLLOW(A)是可能在某些句型中紧跟在A右边的终结符号的集合
Follow集合的算法
S→…U…算Follow(U)
1.如果存在一个产生式 A→…UP,那么First(P)中除了ε 之外都应该放入Follow(U)中
2.如果存在一个产生式 A→…U,或者存在产生式 A→…UP,且First(P)中包含ε,则Follow(A)中的所有元素都在Follow(U)中
3.将$放入Follow(S)中,其中S是开始符号,$是输入右端的结束标识
2的推导: S->EAT, A可以用…U代替,S->E…UT,所以A后面出现的终止符和U后面出现的终止符一样
2和3可得出: S->…U,那么Follow(S)的元素就在Follow(U)中,所以$在Follow(U)中
还是刚才的例子:
(1)exp→exp addop term
(2) exp→term
(3) addop→+
(4) addop→-
(5) term→term mulop factor
(6) term→factor
(7) mulop→∗
(8) mulop→/
(9)factor→(exp)
(10) factor→<number>
Exp为开始符号,所以把$放入Follow(exp)中,由式(1)知First(addop)要加入Follow(exp)中,此时Follow(exp)={+,-,$},同理,Follow(addop)={(,number},由式(2),把Follow(exp)加入到Follow(term)中……
(三) 从First,Follow到预测分析表
由First集合和Follow集合就可以得出我们需要的预测分析表了,先来感官性地认识一下:
![]()
![]()
我们可以看到表格的Y方向是所有的非终结符(也就是所有生成式的左边部分的集合),X方向是所有终结符。
表格的每一项表示,当我目前在N这个非终结符,遇到T这个终结符之后,应该选择的生成式。 比如在stmt时候,如果遇到s,则选择stmt->s这个生成式。
从开始符号出发,每遇到一个输入,就判断往哪边走,最后走完为止,如果中间没有路可以走了,就说明语法有错。
下面来看预测分析表是怎么生成的。其实跟刚才First集合和Follow集合的思路一致。
M[N,T] 其中N为非终止符,T为终止符
算法:为每个非终结符A和产生式 A→ α重复以下两个步骤:
1)对于First(α)中的每个记号a,都将 A→ α 添加到项目 M[ A, a ]中(即,当输入中遇到a,选择A→ α 这一产生式)
2)如果ε在First(α)中,对于Follow(A)中的每个元素a,(记号或者$), 都将A→ α 添加到项目 M[ A, a ]中。
就是正常的话直接看终结符,在哪个分支就往哪个分支走。但如果这个分支的First集合里有ε,那么需要看它后面的终止字符集合。
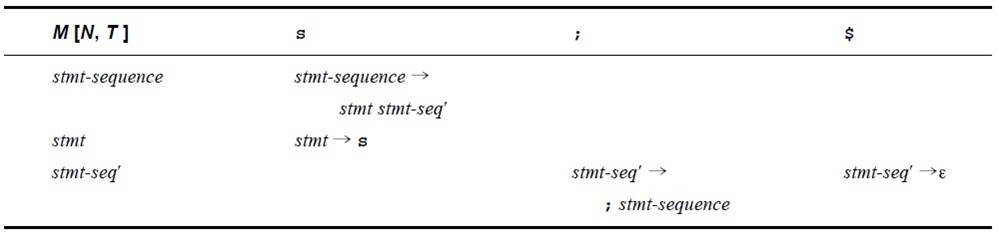
例子:
E→nE′
E′→ +nE′ | ε
First(E) = { n } First(E’)= { + , ε}
Follow(E) = Follow(E’) = {$}
| M[N,T] |
n |
+ |
$ |
| E |
E→nE′ |
|
|
| E' |
|
E′→ +nE′ |
E′→ε |
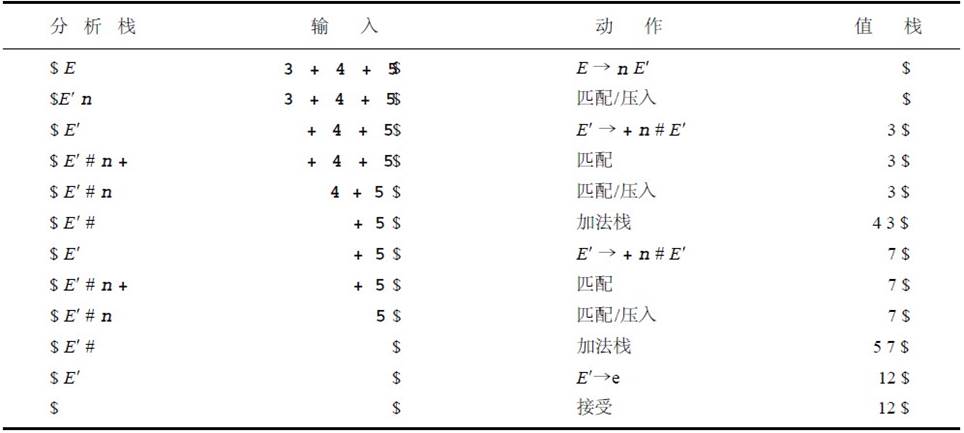
根据它来做的出栈入栈如下,比如分析 3+4=5(栈中的#只是为了计算结果,可以不理)
![]()
首先把$和开始字符E入栈,然后读取输入串。第一个字符是3,也就是n,M[E,n]是E→nE′,所以我们把E出栈,把n和E’入栈。从右到左入栈,即先入E’,再入n。这个时候,输入n和栈顶n匹配,把n出栈,读取字符串的下一个字符,即+,栈顶的E'遇到+根据表格知道应该选择E′→ +nE′ ,把E’出栈,E’,n,+入栈,+和输入的+匹配,出栈,顶端为E’.......依次下去,直到匹配结束。


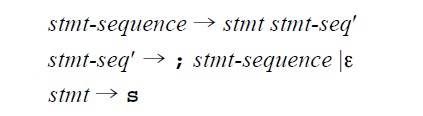

 浙公网安备 33010602011771号
浙公网安备 33010602011771号