要求0:作业要求地址【https://edu.cnblogs.com/campus/nenu/2016CS/homework/2110】
要求1:git仓库地址【https://git.coding.net/yangmx2016011904/wf.git】
要求2:
PSP
|
任务内容
|
计划时间(min)
|
完成时间(min)
|
Planning
|
计划
|
30
|
60
|
Estimate
|
估计这个任务需要多少时间,并规划大致工作步骤
|
30
|
60
|
Development
|
开发
|
630
|
910
|
Analysis
|
需求分析
|
40
|
60
|
Design Spec
|
生成文档
|
20
|
30
|
Design Review
|
设计复审
|
0
|
0
|
Coding Standard
|
代码规范
|
20
|
40
|
Design
|
具体设计
|
60
|
120
|
Coding
|
具体编码
|
420
|
540
|
Code Review
|
代码复审
|
30
|
40
|
Test
|
测试
|
30
|
80
|
Reporting
|
报告
|
160
|
400
|
Test Report
|
测试报告
|
120
|
120
|
Size Measurement
|
计算工作量
|
20
|
30
|
Postmortem & Process Improvement Plan
|
事后总结, 并提出过程改进计划
|
30
|
50
|
功能模块
|
具体阶段
|
预计时间(min)
|
实际时间(min)
|
功能1
|
具体设计
具体编码
测试完善
|
20
120
10
|
30
150
20
|
功能2
|
具体设计
具体编码
测试完善
|
20
150
10
|
40
150
25
|
功能3
|
具体设计
具体编码
测试完善
|
20
150
10
|
50
240
35
|
分析预估耗时和实际耗时的差距原因:
在整个项目的完成过程中,我在具体编码的这个方面花费的时间最多,我认为主要有两方面原因:
1.在计划和需求分析,将有些问题想的过于简单,在编程中不断有新的问题产生,一个一个问题解决起来花费了一些超过预期的时间
2.我对于编写程序还不是很熟悉,所以突然要开始上手具体编写程序时就有一些懵了。由于不是很熟悉,所以需要通过大量的查询才能完成,但在查阅资料后在具体使用的时候还是会出现这样那样的错误,这就大大拖慢了我的速度。经过这一次的个人项目,让我认识到了我在实践方面的不足,也激励我在今后的学习中多动手,多实践。
项目实现的过程要比我想象中艰难,花费的时间也是远远超过我的预期。但也让我从中收获到很多,不断发现问题,分析问题,解决问题的过程也让我对java语言有了更好的应用和理解。
要求3:
解题思路描述:
在看到统计文本文件(文件名后缀为txt)中的单词出现次数这个题目时,我一头雾水,感觉文本很长,统计要花费很多时间,于是我便开始在网上查阅有关统计词汇的介绍,看了很多的博客、代码,慢慢学习到了解决这个问题的思路,我觉得看到一道题之后的思维方式很重要,有了思路之后才能慢慢解决接下来遇到的困难。通过学习参考网上一些类似问题的解决方法,我确定了这道题的解题思路:就是无论多长的文章,都把它看成一句话,是个字符串,这个字符串中可能不仅有英文单词,还有一些标点符号,而这些空格、非字母正好是分割函数中的分割标准,这样一来,在将这个长长的字符串进行分割后,剩余的就是一个又一个需要计数统计的单词,从而实现功能1。功能2主要是获取某文件夹下的所有文件名,将文件名按字典序排序后返回指定文件。功能3则是对单词出现的频率进行排序,再按要求输出出现次数最多的前N个单词。
简述代码并展示部分代码片段:
我一共使用了四个类, 其中wfone、wftwo、wfthree分别对应功能1、2、3,并用类wf作为测试类。在实现功能1时,单词不区分大小写,所以将其全部转换为小写,使用了word = word.toLowerCase(),然后空格和非字母字符进行分割并存入数组,利用循环,使用isLegal()函数判断是否为合法单词,并利用map函数的特点,来统计单词的数量;在实现功能2时,首先在文件夹中读取所有文件并参考功能1完成的;功能3则是通过增加比较器来实现的。感觉自己学会的东西太少,所以很多都需要找资料看博客,但在这个解决问题的过程中自己也学会了很多知识点,是有很大收获的。在其中很大的收获就是关于map函数的一些理解,map这个集合函数的使用,利用它的一些特性,健值不重复,可以统计有多少不重复的单词;将它的两个属性一个设置为字符串类型,来记录单词,另一个设计成整型,来记录其个数。在向其中添加值时,利用myMap.containsKey(word[i])语句进行判断,如果map中已有,则其数量值加1,若匹配不上,则将数量值记为1。
接下来是一些代码展示:
String str=characters.toString().toLowerCase();//将字符全部转化为小写
String[] word = str.split("[^a-zA-Z0-9]");//按空格和非字母进行分割
int num =0;
Map<String,Integer> myMap = new TreeMap<String,Integer>();//分割后存入数组
//遍历数组将其存入Map<String,Integer>中
String regex="^[a-zA-Z][a-zA-Z0-9]*$";
Pattern p = Pattern.compile(regex);
for(int i=0;i<word.length;i++) {
Matcher m =p.matcher(word[i]);
if(m.matches()) {
if(myMap.containsKey(word[i])) {
num = myMap.get(word[i]);
myMap.put(word[i], num+1);
}
else {
myMap.put(word[i], 1);
}
}
}//判断是否为合法单词 将合法单词存入Map
List<Map.Entry<String, Integer>> list =new ArrayList<Map.Entry<String,Integer>>(myMap.entrySet());//Map转换成list进行排序
System.out.println("total"+" "+list.size()+"\n");
for(int i=0;i<word.length;i++) {
if(myMap.containsKey(word[i])) {
System.out.println(word[i]+" "+myMap.get(word[i]));
myMap.remove(word[i]);
}//在Map集合中不应该利用get()方法来判断是否存在某个键,而应该利用containsKey()方法来判断
}
bufferedReader.close();
public String readDir(String filepath){
File file = new File(filepath);
String[] filelist = file.list();
String[] characterlist = new String [filelist.length];
for(int i=0;i<filelist.length;i++) {
File readfile = new File(filepath+"\\"+filelist[i]);
characterlist[i]=readfile.getName();
}
List<String> list = (List<String>)Arrays.asList(characterlist);
Collections.sort(list);
String[] paths = list.toArray(new String[0]);
return paths[0];
}// 使用readDir()函数读取某文件夹下的所有文件
Collections.sort(list,new Comparator<Map.Entry<String, Integer>>(){
public int compare(Entry<String,Integer> e1,Entry<String,Integer> e2) {
return e2.getValue().compareTo(e1.getValue());
}
}); //使用比较器进行排序
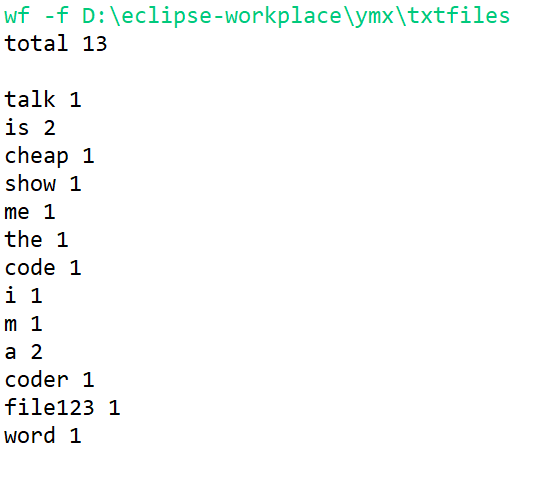
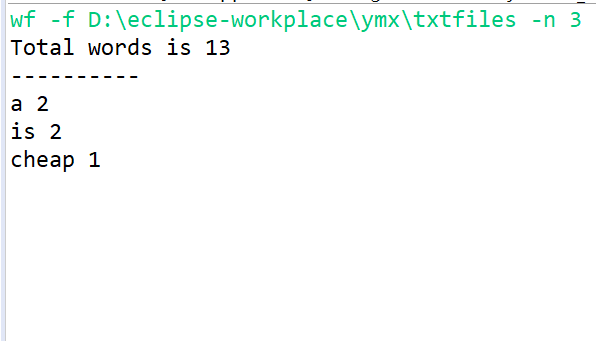
运行截图:
![]()
![]()
![]()
![]()
个人感想:
在完成项目的过程中,从最初的找不到方向到开始整理思路,解决遇到的一个又一个问题,我感觉做什么事都是要一步一步来的,这样我想到了《构建之法》中第三章中,通过大家小时候经常玩的魔方引出技能的反面是解决问题,通过不断地练习,把那些低层次的问题都解决了,变成不用经过大脑的自动操作,然后才有时间和脑力来解决较高层次的问题。学习也是个循序渐进的过程。

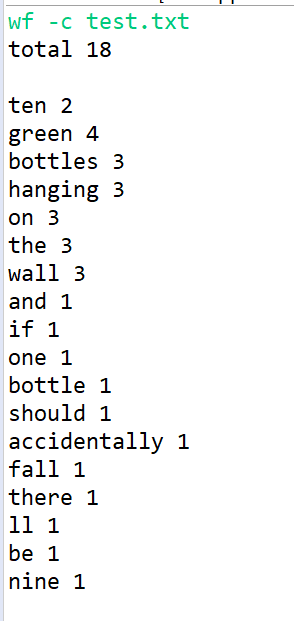


 浙公网安备 33010602011771号
浙公网安备 33010602011771号