

前段时间在dataguru上报了一个hadoop的培训班,希望能够帮助自己更快的了解、掌握并且熟悉hadoop的开发和原理。
上一期的作业是要自己搭建一个hadoop的环境,并能运行mapreduce,我们公司的实验室中已经在10台机器上搭建了用来测试的hadoop环境,于是我利用了其中三台datanode,新建了一个帐号,又搭建了一个由三台服务器组成的小型的hadoop+HA+完全分布式的集群。
现在将搭建的过程写成博客,希望能帮助到有同样需求的朋友!
我这里用到的三台机器,主机名分别为ut07、ut08、ut09,部署图如下,如有不恰当之处,还请各位不吝指出!

1、用户创建
使用命令:
useradd hadooptest
修改密码:
passwd hadooptest
2、安装JDK
将下载好的JDK进行解压:
tar -zxvf jdk-8u91-linux-x64.gz -C /home/hadooptest
在$HOME/.bashrc下添加环境变量:
export JAVA_HOME=/home/hadooptest/jdk1.8.0_91
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:${JAVA_HOME}/bin
3、安装Zookeeper-3.4.6
将下载好的zookeeper-3.4.6.tar.gz解压:
tar -zxvf zookeeper-3.4.6.tar.gz -C /home/hadooptest
在$HOME/.bashrc下添加环境变量:
export ZOOKEEPER_HOME=/home/hadooptest/zookeeper-3.4.6
export PATH=$PATH:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf
进入zookeeper目录,修改配置文件
vim conf/zoo.cfg
将如下内容复制到zoo.kfg中
# The number of milliseconds of each tick tickTime=120000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/home/hadooptest/zookeeper-3.4.6/var/data dataLogDir=/home/hadooptest/zookeeper-3.4.6/var/datalog # the port at which the clients will connect clientPort=2191 server.1=ut07:2988:3988 server.2=ut08:2988:3988 server.3=ut09:2988:3988 # the maximum number of client connections. # increase this if you need to handle more clients maxClientCnxns=1500 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # #http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1
在zookeeper目录下创建文件夹
mkdir -p var/data var/datalog
在var/data目录下创建myid,并输入1,保存

其他节点在复制文件后,根据zoo.cfg中的值进行相应的更改
4、安装hadoop-2.6.0
将下载好的hadoop-2.6.0.tar.gz解压:
tar -zxvf hadoop-2.6.0.tar.gz -C /home/hadooptest/
在hadoop-2.6.0目录下创建目录:
mkdir -p name tmp data/yarn/local data/yarn/log
进入etc/hadoop/目录下,开始修改配置文件
修改slaves文件
修改masters文件

修改hadoop-env.sh以及yarn-env.sh
# The java implementation to use.
export JAVA_HOME=/home/hadooptest/jdk1.8.0_91
修改core-site.xml:

修改hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.nameservices</name> <value>clustertest</value> </property> <property> <name>dfs.ha.namenodes.clustertest</name> <value>ut07,ut08</value> </property> <property> <name>dfs.namenode.rpc-address.clustertest.ut07</name> <value>ut07:8030</value> </property> <property> <name>dfs.namenode.http-address.clustertest.ut07</name> <value>ut07:50170</value> </property> <property> <name>dfs.namenode.rpc-address.clustertest.ut08</name> <value>ut08:8030</value> </property> <property> <name>dfs.namenode.http-address.clustertest.ut08</name> <value>ut08:50170</value> </property> <property> <name>dfs.namenode.servicerpc-address.clustertest.ut07</name> <value>ut07:53433</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://ut07:8486;ut08:8486;ut09:8486/clustertest</value> </property> <property> <name>dfs.client.failover.proxy.provider.clustertest</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/hadooptest/hadoop-2.6.0/tmp/journal</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///home/hadooptest/hadoop-2.6.0/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///home/hadooptest/hadoop-2.6.0/data</value> </property> <property> <name>dfs.datanode.address</name> <value>0.0.0.0:51010</value> </property> <property> <name>dfs.datanode.ipc.address</name> <value>0.0.0.0:51020</value> </property> <property> <name>dfs.datanode.http.address</name> <value>0.0.0.0:51075</value> </property> <property> <name>dfs.journalnode.http-address</name> <value>0.0.0.0:8479</value> </property> <property> <name>dfs.journalnode.rpc-address</name> <value>0.0.0.0:8486</value> </property> </configuration>
修改mapred-site.xml:
<?xml version="1.0" encoding="utf-8"?> <configuration> <property> <name>mapreduce.application.classpath</name> <value>$HADOOP_CONF_DIR, $HADOOP_COMMON_HOME/share/hadoop/common/*, $HADOOP_COMMON_HOME/share/hadoop/common/lib/*, $HADOOP_HDFS_HOME/share/hadoop/hdfs/*, $HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*, $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*, $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*, $HADOOP_YARN_HOME/share/hadoop/yarn/*, $HADOOP_YARN_HOME/share/hadoop/yarn/lib/*</value> </property> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>ut07:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>ut07:19888</value> </property> <property> <name>mapreduce.map.speculative</name> <value>false</value> </property> <property> <name>mapreduce.reduce.speculative</name> <value>false</value> </property> <property> <name>mapreduce.map.memory.mb</name> <value>4000</value> </property> <property> <name>mapreduce.map.java.opts</name> <value>-Xmx1700m</value> </property> <property> <name>mapreduce.reduce.java.opts</name> <value>-Xmx3000m</value> </property> <property> <name>mapreduce.shuffle.port</name> <value>13563</value> </property> </configuration>
修改yarn-site.xml:
注意: yarn.resourcemanager.ha.id的值在ut08中需修改为rm2
<?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <!-- 指定nodemanager启动时加载server的方式为shuffle server --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定resourcemanager地址 --> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>ut07</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>ut08</value> </property> <property> <name>yarn.resourcemanager.ha.id</name> <value>rm1</value> </property> <property> <name>yarn.resourcemanager.address.rm1</name> <value>${yarn.resourcemanager.hostname.rm1}:8132</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>${yarn.resourcemanager.hostname.rm1}:8130</value> </property> <property> <name>yarn.resourcemanager.webapp.https.address.rm1</name> <value>${yarn.resourcemanager.hostname.rm1}:8189</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>${yarn.resourcemanager.hostname.rm1}:8188</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>${yarn.resourcemanager.hostname.rm1}:8125</value> </property> <property> <name>yarn.resourcemanager.admin.address.rm1</name> <value>${yarn.resourcemanager.hostname.rm1}:8141</value> </property> <property> <name>yarn.resourcemanager.address.rm2</name> <value>${yarn.resourcemanager.hostname.rm2}:8132</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>${yarn.resourcemanager.hostname.rm2}:8130</value> </property> <property> <name>yarn.resourcemanager.webapp.https.address.rm2</name> <value>${yarn.resourcemanager.hostname.rm2}:8189</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>${yarn.resourcemanager.hostname.rm2}:8188</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>${yarn.resourcemanager.hostname.rm2}:8125</value> </property> <property> <name>yarn.resourcemanager.admin.address.rm2</name> <value>${yarn.resourcemanager.hostname.rm2}:8141</value> </property> <property> <name>yarn.nodemanager.localizer.address</name> <value>ut07:8140</value> </property> <property> <name>yarn.nodemanager.webapp.address</name> <value>ut07:8142</value> </property> <property> <name>yarn.nodemanager.address</name> <value>ut07:8145</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>/home/hadooptest/hadoop-2.6.0/data/yarn/local</value> </property> <property> <name>yarn.nodemanager.log-dirs</name> <value>/home/hadooptest/hadoop-2.6.0/data/yarn/log</value> </property> <property> <name>yarn.client.failover-proxy-provider</name> <value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value> </property> <property> <name>yarn.resourcemanager.zk-state-store.address</name> <value>ut07:2191,ut08:2191,ut09:2191</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>ut07:2191,ut08:2191,ut09:2191</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>clustertest</value> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> </property> <property> <name>yarn.scheduler.fair.allocation.file</name> <value>/home/hadooptest/hadoop-2.6.0/etc/hadoop/fairscheduler.xml</value> </property> <property> <name>mapreduce.application.classpath</name> <value>$HADOOP_CONF_DIR, $HADOOP_COMMON_HOME/share/hadoop/common/*, $HADOOP_COMMON_HOME/share/hadoop/common/lib/*, $HADOOP_HDFS_HOME/share/hadoop/hdfs/*, $HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*, $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*, $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*, $HADOOP_YARN_HOME/share/hadoop/yarn/*, $HADOOP_YARN_HOME/share/hadoop/yarn/lib/*</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>18432</value> <discription>每个节点可用内存,单位MB</discription> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>18000</value> <discription>单个任务可申请最大内存,默认1024MB</discription> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>4500</value> <discription>单个任务可申请最少内存,默认1024MB</discription> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>4000</value> <description>每个Reduce任务的物理内存限制</description> </property> </configuration>
添加fairscheduler.xml:
<?xml version="1.0" encoding="utf-8"?> <allocations> <queue name="news"> <minResources>1024 mb, 1 vcores</minResources> <maxResources>1536 mb, 1 vcores</maxResources> <maxRunningApps>5</maxRunningApps> <minSharePreemptionTimeout>300</minSharePreemptionTimeout> <weight>1.0</weight> <aclSubmitApps>root,yarn,search,hdfs</aclSubmitApps> </queue> <queue name="crawler"> <minResources>1024 mb, 1 vcores</minResources> <maxResources>1536 mb, 1 vcores</maxResources> </queue> <queue name="map"> <minResources>1024 mb, 1 vcores</minResources> <maxResources>1536 mb, 1 vcores</maxResources> </queue> </allocations>
5、免密码访问
在所有服务器上,均执行(执行时,一路回车即可):
ssh-keygen -t rsa
在用户的HOME目录下会生成.ssh目录,进入其中,将id_rsa.pub的内容复制到authorized_keys中(如果没有authorized_keys则创建),同理,将其他服务器的id_rsa.pub也都复制到该机器的authorized_keys中,此时,我们得到了一个记录了所有服务器公钥的文件,现在只需将这个文件复制到其他服务器的同一目录下即可。
复制时,可以使用scp命令:
scp ./authorized_keys hadooptest@ut08:/home/hadooptest/.ssh/
scp ./authorized_keys hadooptest@ut09:/home/hadooptest/.ssh/
这样,我们就能通过ssh免密码访问各个服务器了(第一次访问时可能需要手动输入yes来保存地址表,以后就无需输入了)。
6、数据克隆
接下来,我们需要把ut07服务器上,刚刚准备好的hadoop-2.6.0目录,jdk1.8.0_91目录,以及zookeeper-3.4.6目录克隆到其他两台服务器上,并在各个服务器上做一些针对性的修改。
同样,我们使用scp命令,将数据进行克隆(复制目录需要加上参数 -r):
scp -r ./hadoop-2.6.0 ./zookeeper-3.4.6 ./jdk1.8.0_91 hadooptest@ut08:/home/hadooptest/
scp -r ./hadoop-2.6.0 ./zookeeper-3.4.6 ./jdk1.8.0_91 hadooptest@ut09:/home/hadooptest/
前文中提到,由于ut08是作为resourcemanager的HA,所以需要修改ut08中的/home/hadooptest/hadoop-2.6.0/etc/hadoop/yarn-site.xml的yarn.resourcemanager.ha.id字段
进入zookeeper的目录下,修改var/data/myid


7、启动zookeeper
在每个服务器上运行:
zkSever.sh start
运行后使用jps命令,可以查看到QuorumPeerMain进程,使用命令:
zkSever.sh status
可以查看zookeeper,其中只有一个为leader,其他全为follow


格式化zookeeper集群:
在ut07上执行:
hdfs zkfc -formatZK
注意:-formatZK中,ZK为大写
出现INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/clustertest in ZK.即代表格式化成功。
8、启动hadoop
启动journalnode
在ut07的hadoop-2.6.0/sbin下执行:
./hadoop-daemons.sh start journalnode
注意:./hadoop-daemons.sh表示操作机器中所有服务器,可以在每台服务器上执行./hadoop-daemon.sh,表示只操作本台服务器。
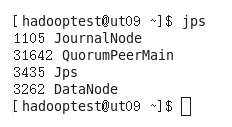
使用jps查看进程:

如果使用./hadoop-daemons.sh start journalnode只能启动本服务器journalnode,请检查slaves和masters文件是否配置正确.
格式化namenode
在ut07上执行:
hdfs namenode -format
出现 INFO common.Storage: Storage directory /home/hadooptest/hadoop-2.6.0/name has been successfully formatted.表示格式化成功
启动namenode
在ut07上执行:
./hadoop-daemon.sh start namenode
将刚刚格式化的namenode信息同步到ut08上,在ut08上执行:
hdfs namenode -bootstrapStandby
出现INFO common.Storage: Storage directory /home/hadooptest/hadoop-2.6.0/name has been successfully formatted.表示同步成功。
接着,在ut08上执行:
./hadoop-daemon.sh start namenode

启动所有datanode
在ut07上执行:
./hadoop-daemons.sh start datanode

查看其他服务器,均启动了datanode进程

启动yarn
在ut07上执行命令:
./start-yarn.sh

在ut07上启动了ResourceManager,在ut07,ut08,ut09上启动了NodeManager
启动zkfc
分别在ut07,ut08上执行
./hadoop-daemon.sh start zkfc


通过web查看hadoop是否启动成功:

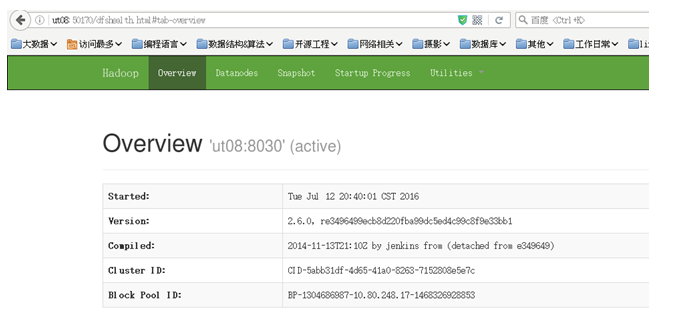
至此,hadoop启动成功!
