

一、学习总结
1.1查找思维导图
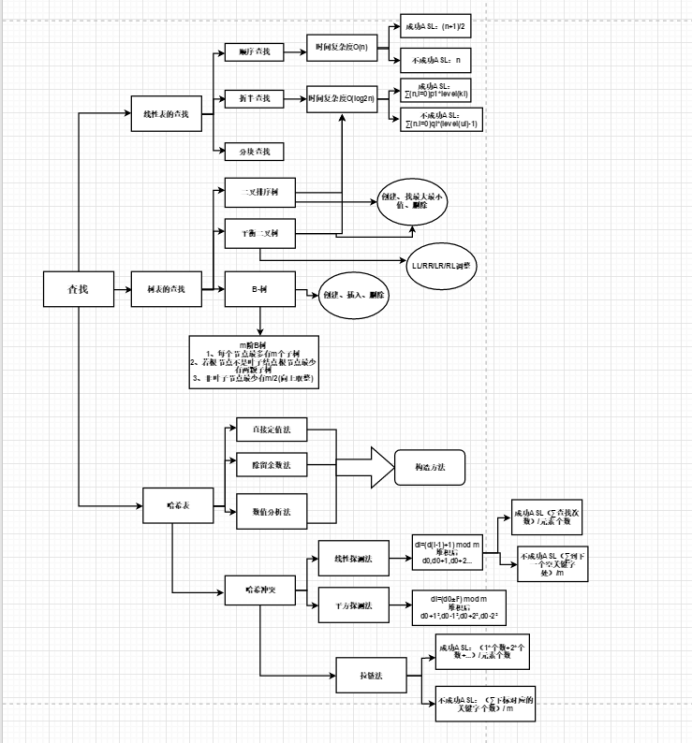
1.2查找学习体会
查找的方法有许多种:二叉排序树,AVL树,B-树,B+,树哈希表等,其中我觉得哈希表这一部分最难,而前面的树更多的利用的是递归算法。
查找的结果通常有两种可能:一种可能是查找成功,即找到关键字等于给定值的数据元素,这时作为查找结果,可报告该数据元素在数据表中的位置,还可进一步给出该数据元素的具体信息,后者在数据库技术中叫做检索;另一种可能是查找不成功(查找失败),即数据表中找不到其关键字等于给定值的数据元素,此时查找的结果可给出一个“空”记录或“空”指针。
哈希表的题目我还是不太会做,希望在后面的联系中,能够补缺补漏。
二、PTA实验作业
(1)2.1题目1:是否二叉搜索树
2.2设计思路:
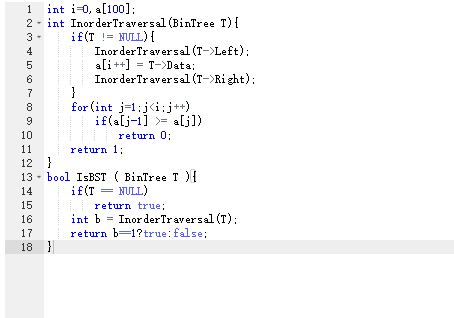
老师上课讲过如果一个树是二叉搜索树,那么中序排序把该树用中序排列排出来后是一串从小到大的数列。这道题目我的思路就是:先用递归算法,把树化成连续数组。然后在判断是否后一个树都比前一个数大,如果不是就返回0,是就返回1,这题还要注意一点,当树是空的时候,返回true。
伪代码:
Bool IsBst(BinTree T)
{
若T是空树
是二叉搜索树
中序遍历
如果后一个值都大于前一个值,返回真,否则假
}
2.3代码截图
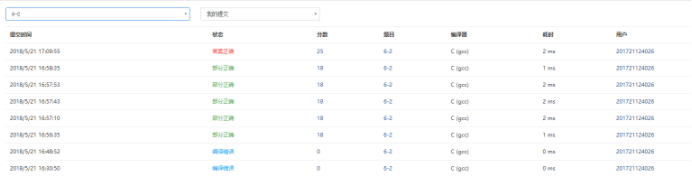
2.4PTA提交列表说明
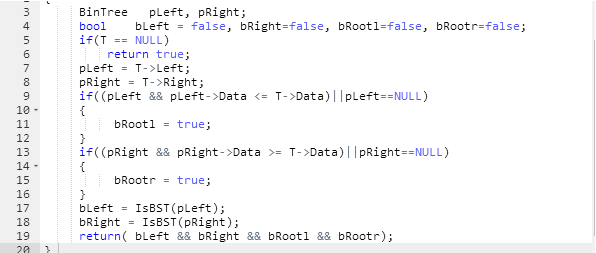
刚开始直接利用该树的定义:即左小右大的方法来判断,但是这种方法是不一定正确的,比如该反例: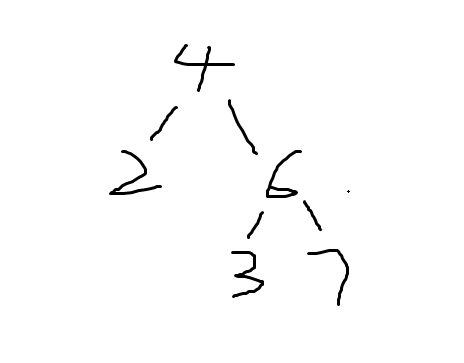
这很明显不是一个正确的二叉树,3不应该出现在那个位置。
(2)2.1题目2:二叉搜索树中的最近公共祖先
2.2 设计思路:有两种情况:1.u,v不在树中;
2.u,v在树中:<1>u,v都在左子树上,就让T=T->Left,递归,
<2>u,v都在右子树上,就T=T->Right,递归,
<3>u,v一个在左子树上,一个在右子树上,公共祖先就是当前节点指向的key;
<4>u,v有一个在根上,公共祖先就是u或v。
伪代码描述:
{if(T不为NULL)
返回ERROR
If(找不到u或v)
返回ERROR
If(u或v等于T->Key)
返回当前节点
If(u和v一个大于T一个小于T)
返回当前节点
If(两个都大于T)
返回LCA(T->Right,u,v)
If(两个都小于T)
返回LCA(T->Left,u,v)}
2.3代码截图
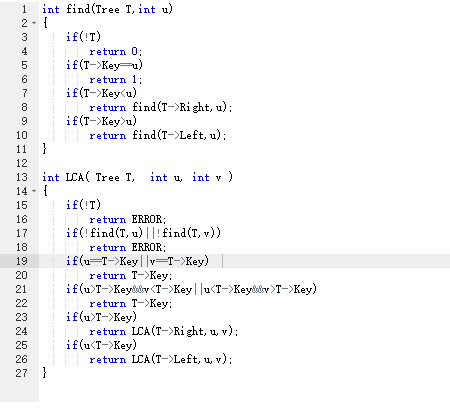
代码说明:
find函数:使用递归查找u和v所在的位置。
如果树空或者找完所有节点都没有找到u或v,就返回ERROR。
2.4PTA提交列表说明

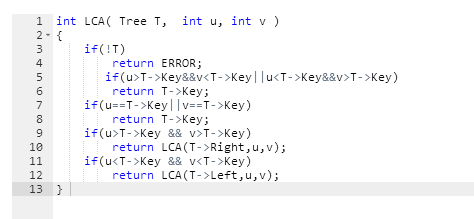
没有判断u或v是否都在树中。
(3)2.1题目3: QQ帐户的申请与登陆
2.2设计思路:
在循环中先判断是N还是L,然后再把各个情况罗列出来。
伪代码:
循环n次
输入状态
如果(是N)
{
Scanf(账号密码)
if已存在,输出ERROR: Exist
else注册成功,输出New: OK}
如果(是L){
if账号不存在,输出ERROR: Not Exist
if密码不对,输出ERROR: Wrong PW
if登录成功,输出 Login: OK}
2.3代码截图

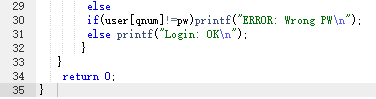
2.4PTA提交列表说明

这道题目我觉得对我来说还是有难度,因为我去网上看了下map函数的使用,感觉还是不太明白(自学能力不够)。然后去搜了一下代码,发现如果能把map函数弄懂了的话,其他就都很简单了
3.1 PTA排名(截图带自己名字的排名)

我的总分:120
- 阅读代码(必做,1分)
标准库map类型是一种以键-值(key-value)存储的数据类型。以下分别从以下的几个方面总结:
map对象的定义和初始化
map对象的基本操作,主要包括添加元素,遍历等
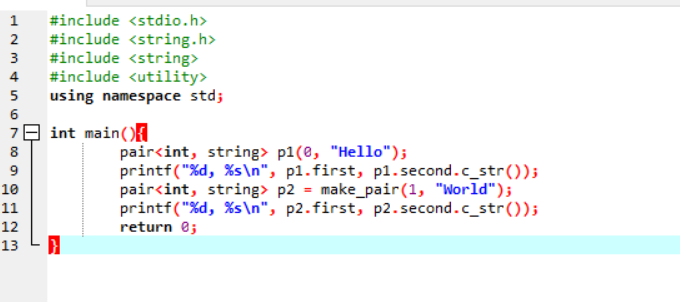
1、pair类型
1.1、pair类型的定义和初始化
pair类型是在有文件utility中定义的,pair类型包含了两个数据值,通常有以下的一些定义和初始化的一些方法:
pair<T1, T2> p;
pair<T1, T2> p(v1, v2);
make_pair(v1, v2)
上述第一种方法是定义了一个空的pair对象p,第二种方法是定义了包含初始值为v1和v2的pair对象p。第三种方法是以v1和v2值创建的一个新的pair对象。
1.2、pair对象的一些操作
除此之外,pair对象还有一些方法,如取出pair对象中的每一个成员的值:
p.first
p.second
2、map对象的定义和初始化
map是键-值对的组合,有以下的一些定义的方法:
map<k, v> m;
map<k, v> m(m2);
map<k, v> m(b, e);
上述第一种方法定义了一个名为m的空的map对象;第二种方法创建了m2的副本m;第三种方法创建了map对象m,并且存储迭代器b和e范围内的所有元素的副本。
map的value_type是存储元素的键以及值的pair类型,键为const。
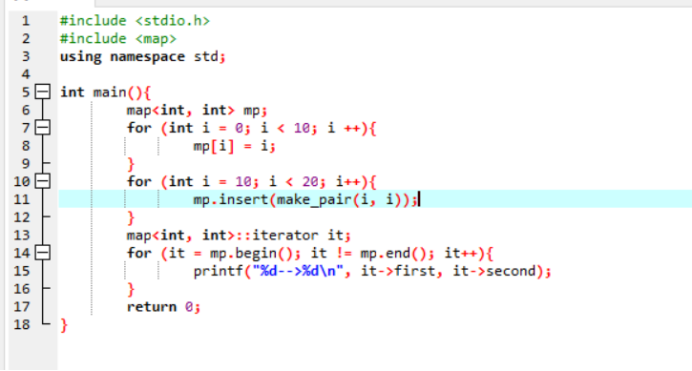
3、map对象的一些基本操作
3.1、map中元素的插入
在map中元素有两种插入方法:
使用下标
使用insert函数
在map中使用下标访问不存在的元素将导致在map容器中添加一个新的元素。
insert函数的插入方法主要有如下:
m.insert(e)
m.insert(beg, end)
m.insert(iter, e)
上述的e一个value_type类型的值。beg和end标记的是迭代器的开始和结束。
两种插入方法如下面的例子所示:
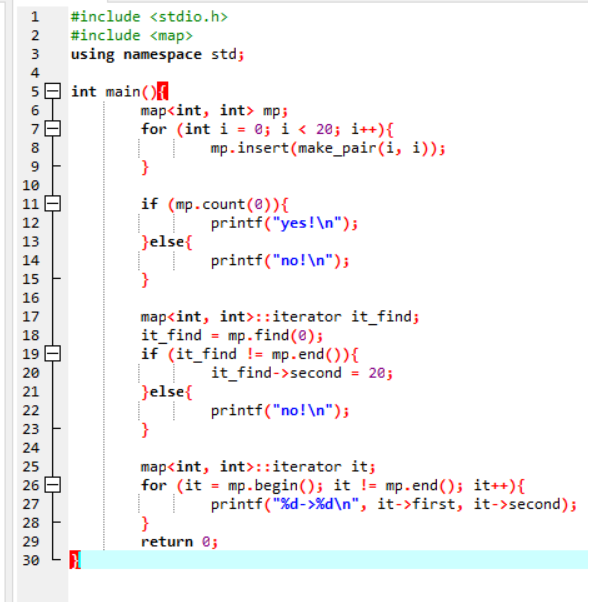
3.2、map中元素的查找和读取
注意:上述采用下标的方法读取map中元素时,若map中不存在该元素,则会在map中插入。
因此,若只是查找该元素是否存在,可以使用函数count(k),该函数返回的是k出现的次数;若是想取得key对应的值,可以使用函数find(k),该函数返回的是指向该元素的迭代器。
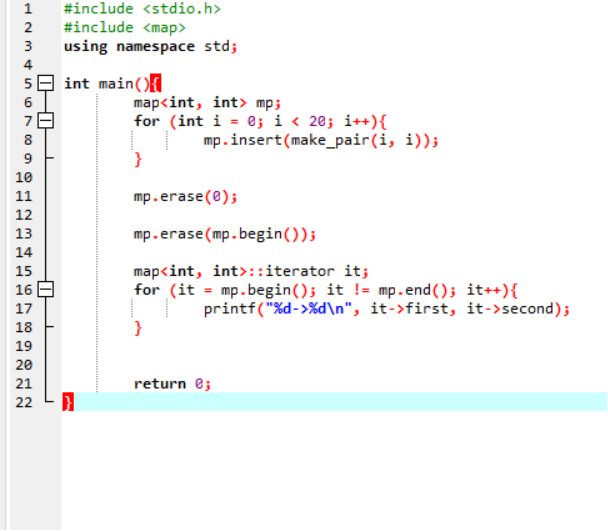
3.3、从map中删除元素
从map中删除元素的函数是erase(),该函数有如下的三种形式:
m.erase(k)
m.erase(p)
m.erase(b, e)
第一种方法删除的是m中键为k的元素,返回的是删除的元素的个数;第二种方法删除的是迭代器p指向的元素,返回的是void;第三种方法删除的是迭代器b和迭代器e范围内的元素,返回void。
如下所示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号