

简单的网页内容采集器(C#)
运行环境
windows nt/xp/2003 or above
.net Framework 1.1
SqlServer 2000
开发环境 VS 2003
目的
学习了网络编程,总要做点什么东西才好。于是想到要做一个网页内容采集器。
作者主页: http://www.fltek.com.cn
下载地址:http://download.csdn.net/source/398623
使用方式
测试数据采用自cnBlog。见下图
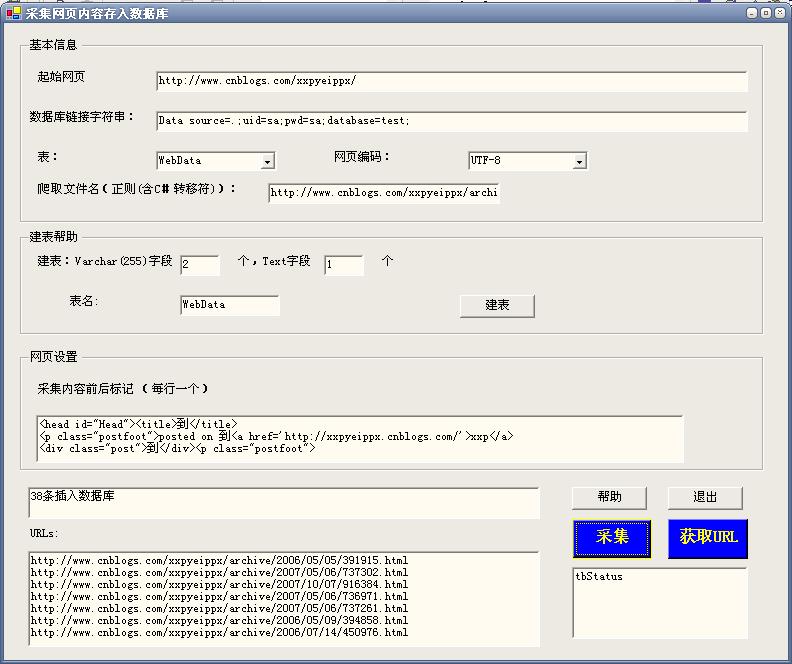 用户首先填写“起始网页”,即从哪一页开始采集。
用户首先填写“起始网页”,即从哪一页开始采集。然后填写数据库连接字符串,这里是定义了采集到的数据插入到哪个数据库,后面选择表名,不必说了。
网页编码,不出意外的话,中国大陆都可以采用UTF-8
爬取文件名的正则:呵呵 这个工具明显是给编程人员用的。正则都要直接填写啦。比如说cnblogs的都是数字的,所以写了\d
建表帮助:用户指定要建立几个varchar型的,几个text型的,主要是放短数据和长数据啊。如果你的表里本来就有列,那就免啦。程序里面没有做验证哦。
网页设置里面:
采集内容前后标记:
比如说都有 <div id="title">xxx</div>,如果我要采集xxx就写“<div id="title">到</div>”,意思,当然就是<div id="title">到</div>之间的内容啦。
后面的几个文本框是显示内容的。
点击“获取URL”可以查看它捕获的Url对不对的。
点击“采集”,可以把采集内容放到数据库,然后就用 Insert xx () (select xx) 可以直接插入目标数据了。
程序代码量非常小(也非常简陋),需要的改动一下啦。
不足
应用到了正则表达式、网络编程
由于是最简单的东西,所以没有用多线程,没有用其他的优化方法,不支持分页。
测试了一下,获取38条数据,用了700M内存啊。。。。
如果有用的人 ,可以改一下使用啦。方便程序员用,免写很多代码。
Surance Yin@ Surance Center
转载请注明出处
转载请注明出处

