排序---->选择排序
选择排序
选择排序的基本思想是:每一趟从n-i+1 (i=1,2,…,n)个元素中选取一个关键字最小的元素作为有序序列中第i个元素。在简单选择排序的基础上,对其进行改进的算法有树型选择排序和堆排序。
4.1简单选择排序
基本思想
简单选择排序的基本思想非常简单,即:第一趟,从n个元素中找出关键字最小的元素与第一个元素交换;第二趟,在从第二个元素开始的n-1个元素中再选出关键字最小的元素与第二个元素交换;如此,第k趟,则从第k个元素开始的n-k+1个元素中选出关键字最小的元素与第k 个元素交换,直到整个序列按关键字有序。选择排序是不稳定的排序方法。
例子:

代码实现
代码实现1
//选择排序
public void selectSort(Object[] r, int low, int high){
for (int k=low; k<high-1; k++){
int min = k;
for (int i=min+1; i<=high; i++)
if (strategy.compare(r[i],r[min])<0) min = i;
if (k!=min){
Object temp = r[k];
r[k] = r[min];
r[min] = temp;
}
}
}
代码实现2
import junit.framework.TestCase;
public class CollectSort extends TestCase {
// 选择排序
public void sort(Integer a[]) {
int min;
int temp;
for (int i = 0; i < a.length - 1; i++) {
min = i; // 本次排序最小的
for (int j = i + 1; j < a.length; j++) {
if (a[j] < a[min]) {
min = j;
}
}
if (min != i) {
temp = a[min];
a[min] = a[i];
a[i] = temp;
}
}
}
public void test() {
Integer array[] = { 49, 38, 65, 97, 76, 13, 27, 49 };
sort(array);
for (int i = 0; i < array.length; i++) {
System.out.print(array[i] + " ");
}
}
}
效率分析
空间效率:显然简单选择排序只需要一个辅助空间。
时间效率:在简单选择排序中,所需移动元素的次数较少,在待排序序列已经有序的情况下,简单选择排序不需要移动元素,在最坏的情况下,即待排序序列本身是逆序时,则移动元素的次数为3(n-1)。然而无论简单选择排序过程中移动元素的次数是多少,任何情况下,简单选择排序都需要进行n(n-1)/2次比较操作,因此简单选择排序的时间复杂度为O(n2)。
算法改进思想:从上述效率分析中可以看出,简单选择排序的主要操作是元素间的比较操作,因此改进简单选择排序应从减少元素比较次数出发。在简单选择排序中,首先从n个元素的序列中选择关键字最小的元素需要n-1次比较,在n-1个元素中选择关键字最小的元素需要n-2次比较……,在此过程中每次选择关键字最小的元素都没有利用以前比较操作得到的结果。欲降低比较操作的次数,则需要把以前比较的结果记录下来,由此得到一种改进的选择类排序算法,即树型选择排序。
4.2树型选择排序-----锦标赛排序
基本思想
树型选择排序也称为锦标赛排序。其基本思想是:先把待排序的n个元素两两进行比较,取出较小者,若轮空则直接进入下一轮比较;然后在⎡n/2⎤个较小者中,采用同样的方法进行比较,再选出较小者;如此反复,直到选出关键字最小的元素为止。重复上述过程,直到所有元素全部输出为止,则得到按关键字有序的序列。
举例:
这个过程可以使用一颗具有n个结点的完全二叉树来表示,最终选出的关键字最小的元素就是这棵二叉树的根结点。例如图(a)给出了对8 个元素的关键字{ 26, 53 , 48 , 11 , 13 , 48 , 32 , 15}选出最小关键字元素的过程。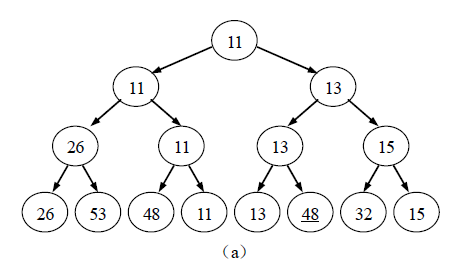
在输出关键字最小的元素后,为选出次小关键字,可以将最小关键字元素所对应的叶子结点的关键字设置为∞,然后从该叶子结点起逆行向上,将所经过的结点与其兄弟进行比较,修改从该叶子结点到根结点上各结点的值,则根结点的值即为次小关键字。
例如,在图(a)的基础上输出最小关键字11 后,输出次小关键字13 的过程如图(b)所示。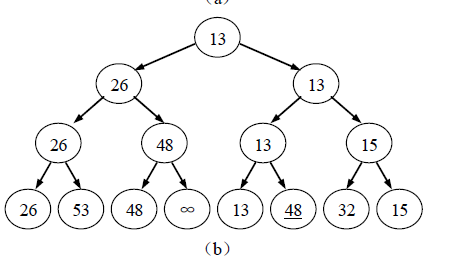
在图(b)的基础上输出最小关键字13 后,输出次小关键字15 的过程如图(c)所示。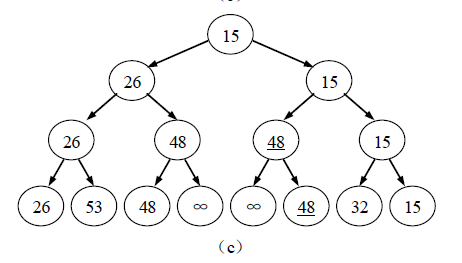
重复上述过程,直到所有元素全部输出为止,则得到按关键字有序的序列。
代码实现
效率分析
时间效率:在树型选择排序过程中为找到关键字最小的元素一共进行了n-1次比较,此后每次找出一个关键字所需要的比较次数等于完全二叉树的高度h,而具有n 个叶子结点的完全二叉树其高度为⎡log n⎤,由此可知除最小关键字外,每选择一个次小关键字需要进行⎡log n⎤次比较,因此树型选择排序的时间复杂度T(n)=(n-1)⎡logn⎤+(n-1)= Ο(nlog n)。
空间效率:与简单选择排序相比,虽然树型选择排序减小的时间复杂度,却使用了更多的辅助空间,在树型选择排序中共使用了n-1 个而外的存储空间存放以前的比较结果。
算法改进思想:树型选择排序的缺点是使用了较多的辅助空间,以及和∞进行多余比较,为弥补树型选择排序的这些缺点,J.W.J.Williams 在1964年提出了进一步的改进方法,即堆排序。
4.3堆排序
堆的定义
堆的定义为:n个元素的序列{k1 , k2 , … , kn},当且仅当满足下列关系时,称之为堆。
(1)ki<=k2i且ki<=k2i+1(1≤i≤ n),或者(2)ki>=k2i且ki>=k2i+1(1≤i≤ n),
若满足条件①,则称为小顶堆,若满足条件②,则称为大顶堆。
如果将序列{k1 , k2 , … , kn}对应为一维数组,且序列中元素的下标与数组中下标一致,即数组中下标为0 的位置不存放数据元素,此时该序列可看成是一颗完全二叉树,则堆的定义说明,在对应的完全二叉树中非终端结点的值均不大于(或不小于)其左右孩子结点的值。由此,若堆是大顶堆,则堆顶元素——完全二叉树的根——必为序列中n个元素的最大值;反之,若是小顶堆,则堆顶元素必为序列中n个元素的最小值。
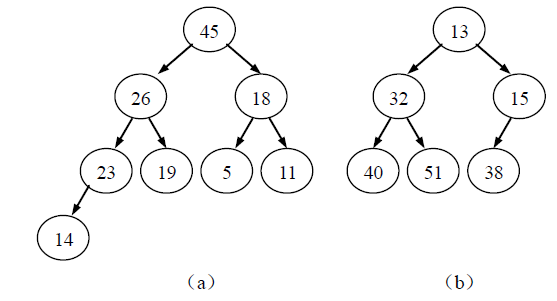
(a)是一个大顶堆,(b)是一个小顶堆。其对应的元素序列分别为{45 , 26 , 18 , 23, 19 , 5 , 11 , 14}、{13 , 32 , 15 , 40, 51 , 38}。
基本思想
设有n 个元素,欲将其按关键字排序。可以首先将这n个元素按关键字建成堆,将堆顶元素输出,得到n个元素中关键字最大(或最小)的元素。然后,再将剩下的n-1个元素重新建成堆,再输出堆顶元素,得到n个元素中关键字次大(或次小)的元素。如此反复执行,直到最后只剩一个元素,则可以得到一个有序序列,这个排序过程称之为堆排序。
实现堆排序时需要解决两个问题
1. 输出堆顶元素后,怎样调整剩余n-1 个元素,使其按关键字成为一个新堆?
设有一个具有m个元素的堆,输出堆顶元素后,剩下m-1个元素。具体的调整方法是:
首先,将堆底元素(最后一个元素)送入堆顶,此时堆被破坏,其原因仅是根结点不满足堆的性质,而根结点的左右子树仍是堆。然后,将根结点与左、右子女中较大(或较小)的进行交换。若与左孩子交换,则左子树堆被破坏,且仅左子树的根结点不满足堆的性质;若与右孩子交换,则右子树堆被破坏,且仅右子树的根结点不满足堆的性质。继续对不满足堆性质的子树进行上述交换操作,直到叶子结点,则堆被重建。我们称这个自根结点到叶子结点的调整过程为筛选。
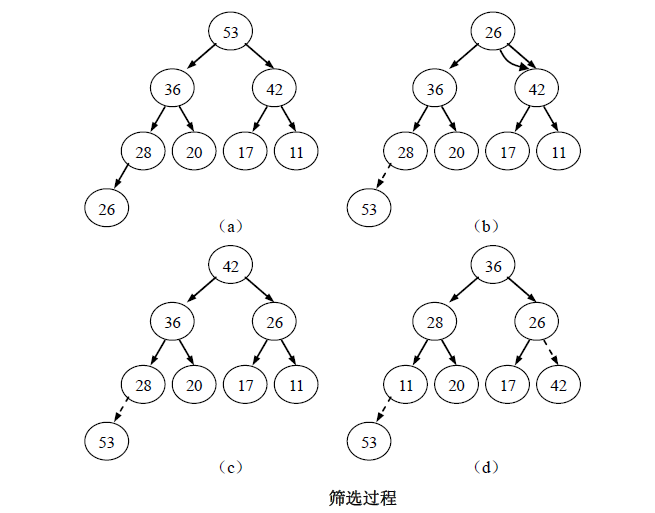
例子
图(a)为一个大顶堆,在输出堆顶元素53之后,将堆底元素26送入堆顶,如图(b)所示;然后将26与36、42中大的元素交换,交换后,以26为根的子树已是一个堆;此时筛选结束,得到一个新堆,如图(c)所示。如果继续输出堆顶元素42,然后重建堆,则结果如图(d)所示。
2 如何由n个元素的初始序列构造一个堆?
实际上建堆的方法是逐层向上对每个非终端结点进行一次筛选即可。
例子:
对于待排序的初始序列{28 , 26 , 17 , 36, 20 , 42 , 11 , 53},初始建堆的过程如图所示。(a)是由初始序列得到的完全二叉树;初始建堆首的过程,以按层从下到上的第一个非叶子结点开始,即从36开始,对36进行调整,过程如图(b)所示,调整结果如图(c)所示;然后对下一个非叶子结点17进行调整,调整过程如图(c),结果如图(d)所示;继续上述过程直到根结点28 为止,对28 进行调整后,即得到一个大顶堆,结果如图(f)所示。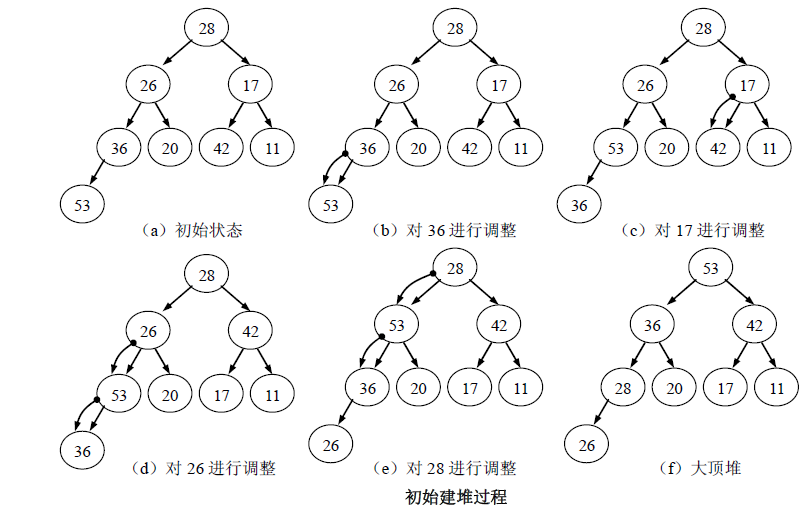
代码实现
//堆排序
public void heapSort(Object[] r){
int n = r.length - 1;
for (int i=n/2; i>=1; i--)
heapAdjust(r,i,n);
for (int i=n; i>1; i--){
Object temp = r[1];
r[1] = r[i];
r[i] = temp;
heapAdjust(r,1,i-1);
}
}
//调整r[low..high]使之成为大顶堆
////已知r[low..high]中除r[low]之外,其余元素均满足堆的定义
private void heapAdjust(Object[] r, int low, int high){
Object temp = r[low];
for (int j=2*low; j<=high; j=j*2){
if (j<high&&strategy.compare(r[j],r[j+1])<0) j++;
if (strategy.compare(temp,r[j])>=0) break;
r[low] = r[j]; low = j;
}
r[low] = temp;
}
效率分析
空间效率:显然堆排序只需要一个辅助空间。
时间效率:首先,对于深度为k的堆,heapAdjust算法中所需执行的比较次数至多为2k次。则在初始建堆的过程中,对于具有n个元素、深度为h的堆而言,由于在i层上最多有2^i个结点,以这些结点为根的二叉树深度最大为h-i,那么⎣n/2⎦次调用heapAdjust时总共进行的关键字比较次数Tinit为: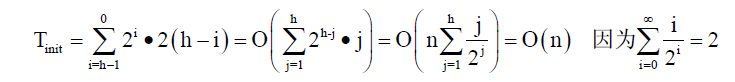
即,初始化需要执行的比较操作的次数为Ο(n)。
其次,在排序过程中,每输出一次堆顶元素需要进行一次调整,而每次调整所需的比较次数为Ο(log n),因此n次输出总共需要的比较次数为Ο(nlogn)。由此,堆排序在任何情况下,其时间复杂度为Ο(nlogn)。这相对于快速排序而言是堆排序的最大优点。
堆排序在元素较少时由于消耗较多时间在初始建堆上,因此不值得提倡,然而当元素较多时还是很有效的排序算法。



