

H.264难点问题分析
2011年4月23日22:22:12
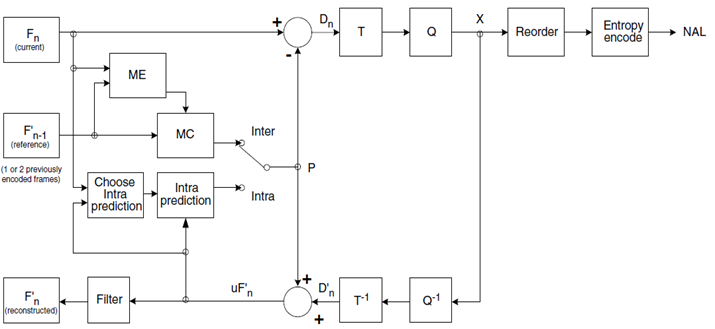
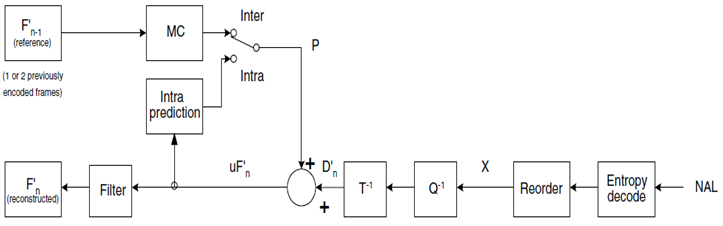
H.264编码后码流的生成

H.264 比较全的编码框架
2011年4月23日22:23:35
H.264中的PB帧编码

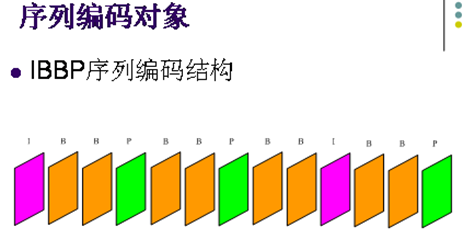

在针对连续动态图像编码时,将连续若干幅图像分成P,B,I三种类型,P帧由在它前面的P帧或者I帧预测而来,它比较与它前面的P帧或者I帧之间的相同信 息或数据,也即考虑运动的特性进行帧间压缩。P帧法是根据本帧与相邻的前一帧(I帧或P帧)的不同点来压缩本帧数据。采取P帧和I帧联合压缩的方法可达到 更高的压缩且无明显的压缩痕迹。
在H.264编码中,I帧是内部编码帧,不需要参考其它帧,P帧需要前向的I帧作为参考,B是双向预测帧,需要前 向和后向的I或者P帧作为其参考帧。由于帧与帧之间的参考关系比较复杂,彼此之间互相关联,对帧编码的简单并行是行不通的。因此,寻找共用参考帧的可编码 帧成为实现帧级并行的关键。
假设编码序列中设置的B帧个数为2,其具体视频编码序列为IBBPBBPBBP…,依照I、P和B帧之间的参考关系, 可以把连续的视频序列按照BBP的样式分割成一个个单元序列。经过分析可以看出一个BBP单元序列中的两个B帧由于共用前后的两个P帧作为参考帧,可以实 施并行。同时,这个BBP单元序列中的P帧又作为下一个BBP单元序列中P帧的参考,因此前一单元序列中的两个B帧加上下一个单元序列中的P帧就可以实施 三帧同时并行。以上是B帧设置参数为2时帧级并行的基本思路,可以得出原本执行一帧的时间现在可以用来执行三帧,理论加速比基本可以达到3,等于B帧设置 参数加1。
当设置编码序列中B帧个数可变时,帧级并行的线程数取决于B帧的个数,B帧数越大,并行加速比越高,在处理器足够的情况下,理论上获得 的最大加速比等于B帧设置参数加1。由于在并行过程中,创建编码线程需要分配内存,线程之间的数据传输也会消耗资源,实际加速比会小于理论加速比,再加上 处理器个数资源的限制,会在某个B帧的个数上获得一个峰值加速比.
2011年4月23日22:26:49
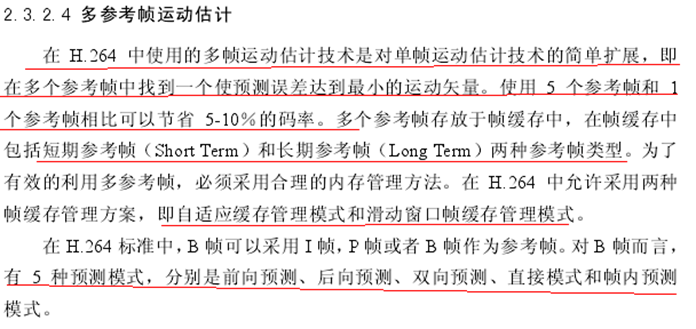
H.264中运动矢量和多参考帧运动估计
一个宏块中的运动矢量

每一个块具有一个运动矢量,这句话我们可以这么理解, 块的大小不定, 从16x16~4X4, 所以,最多可以有16个不同的MV,但是 ,所以对于一个宏块肯定是携带16个MV, 只是可能其中一些MV是相同的.
,所以对于一个宏块肯定是携带16个MV, 只是可能其中一些MV是相同的.
多参考帧运动估计
2011年4月23日22:34:25
关于H264帧间色度块预测的问题
老毕书上在第6章这么写的:

所以帧间色度块不用预测, 
2011年4月23日22:36:14
JM86如何设置编码器分片参数:

2011年4月23日22:43:52
关于SliceMode中的CALLBACK模式的解释


2011年4月23日22:44:02
JM8.6中I帧,P帧的理解


通过下面的代码我们可以发现

对于一帧, 如果设置这一帧进行帧内编码,即intra=1,那么这一帧不会再进行帧间预测,这一帧即为I帧, 但是, 如果设置某一帧要进行帧间预测, 即intra=0,那么这个时候帧内预测和帧间预测都要进行, 从上面的代码可以看出, 进行帧间预测是包含着一个if判断语句中的, 而帧内预测是没有条件的, 是任何情况下都要进行的. 之后jm代码会比较帧内预测与帧间预测两者之间的优劣, 选择一种使率率失真函数最优的方法. 换句话说, 可以认为intra其实是一个标志(flag), 用来标示是否要进行帧间预测. 同样我们也可以看到, 对于p帧中的宏块, 帧内预测和帧间预测都要进行的, 最后也有可能使用帧内预测. 所以p帧内的宏块包括帧内预测和帧间预测的宏块.
对于上面需要一些更正



2011年4月20日15:16:43
JM8.6中对数据分割的一点解释
分析currslice->partarr[partmap[SE_MVD]] (关于数据分割的实现)
Currslice指当前slice
Partarr是一个datapartition数组
Partmap :const int* partmap = assignse2partition[input->partition_mode];
Int * assignse2partition[2] ;

Static int assignse2partition_nodp[SE_MAX_ELEMENTS] = { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 };
Static int assignse2partition_DP[SE_MAX_ELEMENTS] = { 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 2, 2, 2, 2, 0, 0, 0, 0 } ;
Typedef enum {
SE_HEADER,
SE_PTYPE,
SE_MBTYPE,
SE_REFFRAME,
SE_INTRAPREDMODE,
SE_MVD,
SE_CBP_INTRA,
SE_LUM_DC_INTRA,
SE_CHR_DC_INTRA,
SE_LUM_AC_INTRA,
SE_CHR_AC_INTRA,
SE_CBP_INTER,
SE_LUM_DC_INTER,
SE_CHR_DC_INTER,
SE_LUM_AC_INTER,
SE_CHR_AC_INTER,
SE_DELTA_QUANT_INTER,
SE_DELTA_QUANT_INTRA,
SE_BFRAME, SE_EOS,
SE_MAX_ELEMENTS //!< number of maximum syntax elements
} SE_type; // substituting the definitions in elements.h
从上面可以看出SE_type枚举类型里定义了20种句法元素,若存在数据分割,则根据assignse2partition_DP数组来定义句法元素的重要性; 若不存在数据分割情况,则assignse2partition_nodp数组可知把这些句法元素归于一类。
Partmap的作用是把当前的句法元素映射到某一种数据分割类型中,其值为0,1,2,这样就可以形成一个partarr的datapartition数组
当没有数据分割时,这些元素实际全存到了currslice->partarr[0]中。
2011年4月20日15:18:50
关于写比特流的问题
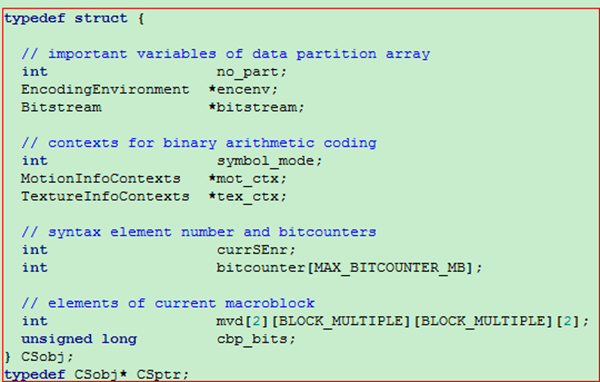



通过上面的对比, 我们可以发现store_coding_state函数和reset_coding_state函数基本上完全一致, 对于cs_mb, store_coding_state函数将img->currentslice变量中的一些需要保存的量存储在cs_mb中, 然后等到进行编码完成后, 要恢复现场, 利用reset_coding_state函数将cs_mb中保存的相关量恢复到变量img->currentslice中, 便于下面的利用.
从上面的截图我们也可以看出, 对于非CABAC编码的状况, 主要是保存的bitstream

而对于CABAC编码的状况, 还需要保存一些相关的上下文信息.
所以, 我们需要看看bitstream结构中所包含的一些量
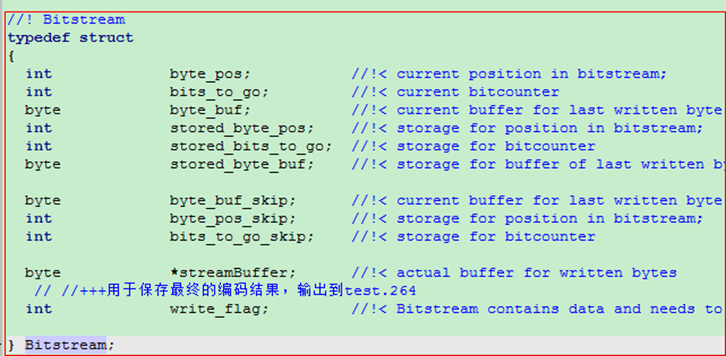



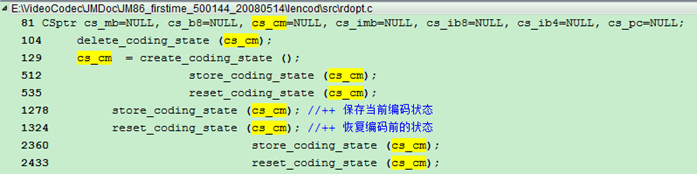




从上面的截图, 我们可以看到cs_mb和cs_b8应该分别是一个宏块和一个8x8块对应的一些bitstream信息, cs_cm更像一个中间量, 其他的量都没有使用过. 一般cs_cm和cs_mb和cs_b8这些存储当前编码状态的变量, 使用的主要原因就是在RDO方式下需要真正的进行一遍编码, 所以需要保存一下当前状态, 等代价计算完毕后,需要恢复现场, 再计算其他模式的代价.
If (valid[P8x8])
{
Cost8x8 = 0;
//===== store coding state of macroblock =====
Store_coding_state (cs_mb); //第一次出现
Store_coding_state
假设现在是第二帧, 现在用来存储比特流的结构体里数据情况如下
Img->currentslice->partarr[0].bitstream->byte_pos 0x00000003
Img->currentslice->partarr[0].bitstream->bits_to_go 0x00000007
在这时候执行store_coding_state (cs_mb),把
Img->currentslice->partarr[0].bitstream的内容赋给了cs_mb->bitstream[0]
接着进入for (cbp8x8=cbp_blk8x8=cnt_nonz_8x8=0, block=0; block<4; block++)循环 1
进入for (min_cost8x8=(1<<20), min_rdcost=1e30, index=(bframe?0:1); index<5; index++)循环 2
在循环2里
执行函数rdcost_for_8x8blocks之前,
执行store_coding_state (cs_cm) 把img->currentslice->partarr[0].bitstream的内容赋给了cs_cm->bitstream[0]
执行rdcost_for_8x8blocks函数之后 //这个函数包含了编码与写比特到img->currentslice->partarr[0].bitstream中
Img->currentslice->partarr[0].bitstream->byte_pos 0x000000012
Img->currentslice->partarr[0].bitstream->bits_to_go 0x00000008

若本模式的率失真更小, 则store_coding_state (cs_b8), 把img->currentslice->partarr[0].bitstream的内容赋给了cs_b8->bitstream[0]
然后reset_coding_state (cs_cm); 把cs_cm->bitstream[0]内容赋给img->currentslice->partarr[0].bitstream 即保证每次比较8*8块的率失真时,将比特流情况设置成
Img->currentslice->partarr[0].bitstream->byte_pos 0x00000003
Img->currentslice->partarr[0].bitstream->bits_to_go 0x00000007
(可以这样看, 在进行rdcost_for_8x8blocks之前, 要保存一下当前的img->currentslice->partarr[0].bitstream到cs_cm中去, 因为在这个函数中有对img->currentslice->partarr[0].bitstream的修改, 所以从rdcost_for_8x8blocks函数返回后, 由于需要计算下一个P8x8模式的rdcost, 所以要恢复成之前的状态, 这样保证了对每种P8x8模式进行计算rdcost之前的img->currentslice->partarr[0].bitstream状态是一样的. 同时, 如果发现当前模式的rdcost比较小, 则需要保存一下bitstream, 保存在了cs_b8中)
由此可见循环2完成后, 本8*8块的最佳比特流将存在cs_b8->bitstream[0]中(其实还包括slice头部比特流和其他的前面的最佳8*8块比特流)
循环2完成后,执行reset_coding_state (cs_b8);

将cs_b8->bitstream[0]内容赋给img->currentslice->partarr[0].bitstream, 保证在把第下个8*8 的最佳比特流放在前一个8*8的最佳比特流之后
如此下来,1和2都循环完之后,一个宏块的最佳编码比特流就存到了img->currentslice->partarr[0].bitstream中
接下来在for (ctr16x16=0, index=0; index<7; index++)循环中
在这个循环之前,执行reset_coding_state (cs_mb); 把cs_mb->bitstream[0]的内容
赋给了img->currentslice->partarr[0].bitstream
此时
Img->currentslice->partarr[0].bitstream->byte_pos 0x00000003
Img->currentslice->partarr[0].bitstream->bits_to_go 0x00000007
即回到未写宏块比特流之前
(for (ctr16x16=0, index=0; index<7; index++)的循环里比较的是0, 1, 2, 3, P8x8, I16MB, I4MB这几种模式
而P8*8的最佳rdcost在for (min_cost8x8=(1<<20), min_rdcost=1e30, index=(bframe?0:1); index<5; index++)里已经比较得到 所以for (ctr16x16=0, index=0; index<7; index++)它实际上是比较Skip,16*16,16*8,8*16,8*8,8*4,4*8,4*4,I4MB,I16MB这些模式的rdcost从而选择出有最小rdcost的模式)
执行if (rdcost_for_macroblocks (lambda_mode, mode, &min_rdcost))
在rdcost_for_macroblocks (lambda_mode, mode, &min_rdcost)里对Skip,16*16,16*8,8*16模式编码(每次循环对不同的模式编码)
编码完成之后, 写比特流之前store_coding_state (cs_cm); 把
Img->currentslice->partarr[0].bitstream的内容赋给了cs_cm->bitstream[0] (a)
之后writembheader (1); writemotioninfo2nal ();writecbpandlumacoeff ();writechromacoeff ();此时
Img->currentslice->partarr[0].bitstream->byte_pos 0x000000037
Img->currentslice->partarr[0].bitstream->bits_to_go 0x00000003
即编完一个宏块模式后的比特流情况
然后reset_coding_state (cs_cm);
把cs_cm->bitstream[0]内容赋给img->currentslice->partarr[0].bitstream (b)
由上可看出,实际上(a)和(b)操作时相反的,最后img->currentslice->partarr[0].bitstream里面实际上只存有slice头部信息
所有store_coding_state和reset_coding_state操作都是为比较率失真而设置的,
在encode_one_macroblock 结束后,img->currentslice->partarr[0].bitstream里实际上只有slice头部信息,但在这个函数里得到了最佳的宏块编码模式,
将宏块编码信息写入img->currentslice->partarr[0].bitstream的是在write_one_macroblock函数 里
Writembheader (0);
// Do nothing more if copy and inter mode
If ((IS_INTERMV (currmb) || IS_INTRA (currmb) ) ||
((img->type==B_SLICE) && currmb->cbp != 0) )
{
Writemotioninfo2nal ();
Writecbpandlumacoeff ();
Writechromacoeff ();
}
实际上是用到的img-> mv[block_x][block_y][list_idx][refindex][mv_mode][X/Y]
在求每种分割模式的最佳运动矢量时,将他们保存到了best8x8fwref[mode][k]中,k=0~3 即best8x8fwref[mode][k]保存了每种模式的最佳参考帧
在对各种模式进行比较时
For (ctr16x16=0, index=0; index<7; index++)
If (valid[mode])
{
Setmodesandrefframeforblocks (mode);
Setmodesandrefframeforblocks中
Enc_picture->ref_idx[LIST_0][img->block_x+i][img->block_y+j] = (IS_FW ? Best8x8fwref[mode][k] : -1);
将本模式的最佳参考帧赋值给enc_picture->ref_idx
在rdcost_for_macroblocks的lumaresidualcoding ()中,将会用到enc_picture->ref_idx求出预测值 [具体来说是利用enc_picture->ref_idx给出的参考帧,可以得到预测值]
在store_macroblock_parameters (mode);中将率失真小的那个模式的最佳参考帧存到frefframe[j][i]中
而后有一个函数set_stored_macroblock_parameters ()
有enc_picture->ref_idx[LIST_0][img->block_x+i][img->block_y+j] = frefframe[j][i];
也就是说最终的最佳模式的最佳参考帧就存到了enc_picture->ref_idx中
Enc_picture->mv[LIST_0][img->block_x+i][img->block_y+j][0] =
Img->all_mv[i][j][LIST_0][frefframe[j][i]][currmb->b8mode[i/2+(j/2)*2]][0]; enc_picture->mv[LIST_0][img->block_x+i][img->block_y+j][1] =
Img->all_mv[i][j][LIST_0][frefframe[j][i]][currmb->b8mode[i/2+(j/2)*2]][1];
最佳的运动矢量也存到了enc_picture->mv中
在write_one_macroblock()中每8x8块的最佳模式是由currmb->b8mode[i]参数来传递的[具体说是函数writemotioninfo2nal()中调用的writereferenceframe的参数],这个参数的值是在void encode_one_macroblock ()中的 set_stored_macroblock_parameters函数中的
For (i=0; i<4; i++)
{
Currmb->b8mode[i] = b8mode[i];求得的,
而b8mode[i]是在
If (rdcost_for_macroblocks (lambda_mode, mode, &min_rdcost))
{
Store_macroblock_parameters (mode);
中记录的那个具有最小的率失真的模式
Distortion的计算是综合了色度和亮度的distortion, 色度部分的计算也是在rdcost_for_macroblocks函数和rdcost_for_8x8blocks函数中的,
但JM8.5中得到色度分量的分像素运动矢量时好像有点问题,在 onecomponentchromaprediction4x4函数中!!
色度分量的运动矢量不需要搜索判决, 是根据亮度分量的运动矢量乘以2得到的(JM85中好像没乘2?)
色度分量的最佳模式是对应亮度分量的最佳模式除以2。 如亮度最佳模式是8*16,则色度最佳模式是4*8。
2011年4月24日9:28:20
2011年4月20日21:22:53
H.264中最优运动矢量残差的输出
最优运动矢量的求解是在encode_one_macroblock函数里面,因此该函数执行完毕运动矢量及分割模式也就相应的确定了,这里我们对这一块作一下简要的分析。
运动矢量的写码流是在write_one_macroblock里的,它的一个大致的函数调用关系是:
write_one_macroblock----->writeMotionInfo2NAL----->writeMotionVector8x8,就是这样了,在writeMotionInfo2NAL里:
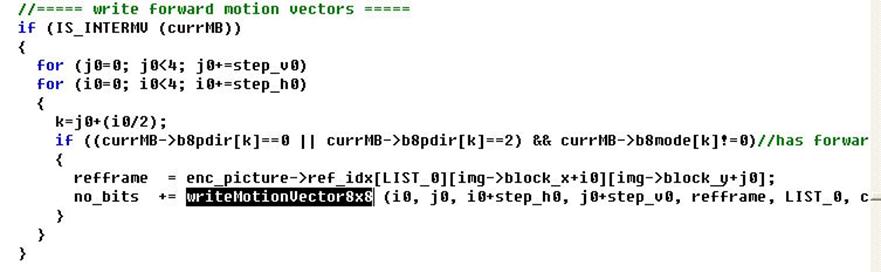
这里的两个循环主要是遍历一个宏块里的大的分割块,分割模式一共有1,2,3,(4,5,5,7)这些种,后四种又统称为P8*8模式,每个宏块的运动矢量数目是这样的,模式1有一个运动矢量,模式2,3有两个,P8*8则根据8*8子块的分割模式细分。我们进writeMotionVector8x8函数去看看。

上面被选中的那一句就是求运动矢量残差了,等号右边的两个也就是相应的最佳运动矢量和预测运动矢量,这里也有两个循环,是循环P8*8模式里的小分块的。
我们只要在这里把curr_mvd输出来就能得到运动矢量残差数据了,若想得到最优运动矢量则输出等号右边一项即可。
这里存在一个问题,如果在writeMotionVector8x8函数里直接输出运动矢量信息当然也是可以的,但在encode_one_macroblock函数里进行模式判决的时候调用了RDCost_for_macroblock以及RDCost_for_8*8block,而这两个函数里也分别调用了writeMotionInfo2NAL,因此在进行模式选择时也把一些其它模式求解出的运动矢量残差数据输出来,这个问题怎么解决呢。
其实在函数RDCost_for_macroblock和函数RDCost_for_8*8block中调用writeMotionInfo2NAL后也进行过写码流的操作(主要是为了得到真正的编码比特数), 但是从总体上看, 利用store_coding_state和reset_coding_state两个函数, 其实最后还是恢复到没有写码流之前的状态.
2011年4月25日20:06:43
JM8.6中对MV的预测
BlockMotionSearch函数对不同帧间模式block type (1-16x16 ... 7-4x4)进行运动搜索.
从该函数中,我们可以发现,有一个局部变量 ,通过下面的语句将img->pred_mv与pred_mv联系了起来,
,通过下面的语句将img->pred_mv与pred_mv联系了起来,

这样其实通过调用函数SetMotionVectorPredictor来计算运动矢量的预测值(MVpred), 代码中向SetMotionVectorPredictor函数传递了pred_mv这个整型指针(指向img->pred_mv具体要保存的地方), 这样在函数SetMotionVectorPredictor中求出运动矢量的预测值,其实就存在了img->pred_mv中了.


具体在函数SetMotionVectorPredictor中预测MV的求解如下:
对水平和垂直两个方向进行循环

具体的计算如下

根据不同的mvPredType计算得出相应的pred_vec, 然后存在pmv[hv]中.
2011年4月21日11:01:18
JM8.6中对上层块模式预测的实现
下面的几个变量是定义的保存上层块预测的结果

上面这个三个数组应该都是和快速搜索有关的.
具体的pred_MV_uplayer是在函数BlockMotionSearch中,如代码:

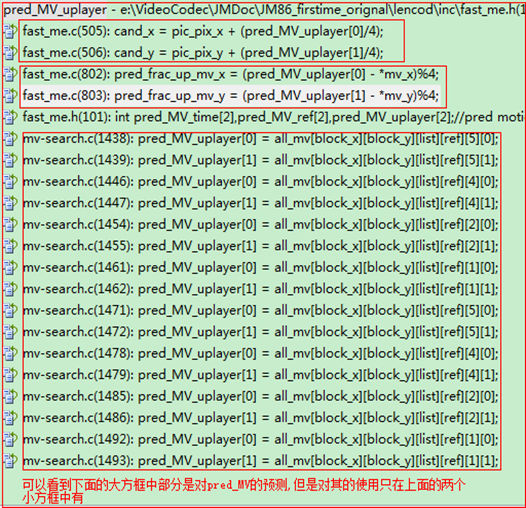
但是看代码可以发现上层块预测只在FMEable的情况下才使用的.在函数BlockMotionSearch中有对各个搜索函数的调用.
由于pred_MV_uplayer是一个全局变量, 所以在函数FastIntegerPelBlockMotionSearch中有使用pred_MV_uplayer,如下

对于模式1[16x16]是没有上层块预测的,所以只有在模式2-7的情况下可以使用的
在函数FastSubPelBlockMotionSearch中也有使用

总结上面的,我们可以发现,在进行求MVD的时候, 我们是使用利用中值预测求出来的MV的预测值, 没有使用上层块预测的结果,而上层块预测的结果是只在运动搜索中使用的.
2011年4月20日9:26:54
dct_luma_16x16流程的问题


2011年4月20日10:03:04
JM8.6与T264码率控制的不同

2011年4月24日17:38:36
率失真曲线
率失真(RD)曲线 反映了不同编码器的编码性能好坏。
一般RD曲线都是以码率(Kbps)做为横坐标,以PSNR(dB)作为纵坐标做出来一条曲线,曲线上的点一般是采用QP=28,32,36,40这四个QP下的编码码率和编码质量 (QPi, butrate,psnr)。
曲线点越高,表明性能越好。
2011年4月25日20:24:30
H.264中的ASO与FMO

ASO指的是片在传输时的先后顺序可以随意变化, 而FMo是指在一帧图像中宏块的属于不同的片的次序比较灵活

2011年5月7日11:08:22
对于listX可以这么理解StorablePicture *listX[6][ref_frame]; 即6是6个参考列表,ref_frame是参考帧的数目,每一个listX[i][j]中存的是StorablePicture*指针
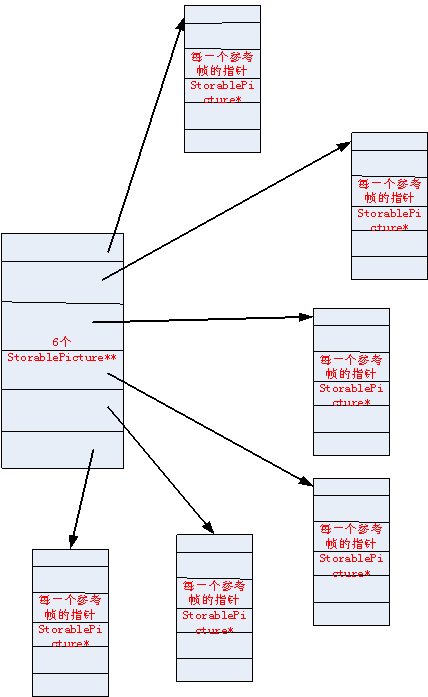
至于6个列表中到底存放了多少个参考帧, 这个是由数组lsitXsize决定的, 这个lsitXsize[6]数组就是用来存储对应列表大小的
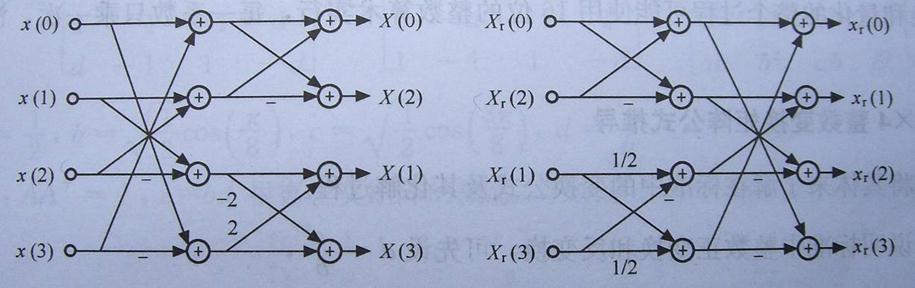


// Horizontal transform水平变换,其实就是左乘Cf,
for (j=0; j < BLOCK_SIZE && !lossless_qpprime; j++)
m5[i]=img->m7[i][j]+img->m7[i1][j];
m5[i1]=img->m7[i][j]-img->m7[i1][j];
// Vertical transform垂直变换,其实就是右乘CfT
for (i=0; i < BLOCK_SIZE && !lossless_qpprime; i++)
m5[j]=img->m7[i][j]+img->m7[i][j1];
m5[j1]=img->m7[i][j]-img->m7[i][j1];
size.total = size.width * size.height;
y = yuv[position.y * size.width + position.x];
u = yuv[(position.y / 2) * (size.width / 2) + (position.x / 2) + size.total];
v = yuv[(position.y / 2) * (size.width / 2) + (position.x / 2) + size.total + (size.total / 4)];
rgb = Y'UV444toRGB888(y, u, v);


 浙公网安备 33010602011771号
浙公网安备 33010602011771号