

Spark机器学习之推荐引擎
一. 最小二乘法建立模型
关于最小二乘法矩阵分解,我们可以参阅:
一、矩阵分解模型。
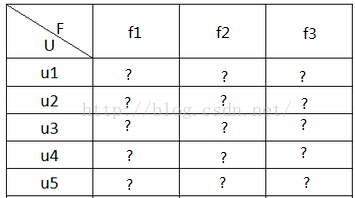
用户对物品的打分行为可以表示成一个评分矩阵A(m*n),表示m个用户对n各物品的打分情况。如下图所示:
其中,A(i,j)表示用户user i对物品item j的打分。但是,ALS 的核心就是下面这个假设:的打分矩阵 A 可以用两个小矩阵
和
的乘积来近似:
。这样我们就把整个系统的自由度从
一下降到了
。我们接下来就聊聊为什么 ALS 的低秩假设是合理的。世上万千事物,人们的喜好各不相同。但。举个例子,我喜欢看略带黑色幽默的警匪电影,那么大家根据这个描述就知道我大概会喜欢昆汀的《低俗小说》、《落水狗》和韦家辉的《一个字头的诞生》。这些电影都符合我对自己喜好的描述,也就是说他们在这个抽象的低维空间的投影和我的喜好相似。再抽象一些,把人们的喜好和电影的特征都投到这个低维空间,一个人的喜好映射到了一个低维向量
,一个电影的特征变成了纬度相同的向量
,那么这个人和这个电影的相似度就可以表述成这两个向量之间的内积
。 我们把打分理解成相似度,那么“打分矩阵A(m*n)”就可以由“用户喜好特征矩阵U(m*k)”和“产品特征矩阵V(n*k)”的乘积
来近似了。矩阵U、矩阵V如下图所示:
U V
二、交替最小二乘法(ALS)。
矩阵分解模型的损失函数为:
有了损失函数之后,下面就开始谈优化方法了,通常的优化方法分为两种:交叉最小二乘法(alternative least squares)和随机梯度下降法(stochastic gradient descent)。本文使用算法的思想就是:我们先随机生成
然后固定它求解
,再固定
求解
,这样交替进行下去,直到取得最优解min(C)。因为每步迭代都会降低误差,并且误差是有下界的,所以 ALS 一定会收敛。但由于问题是非凸的,ALS 并不保证会收敛到全局最优解。但在实际应用中,ALS 对初始点不是很敏感,是不是全局最优解造成的影响并不大。
算法的执行步骤:
1、先随机生成一个
2、固定
此时,损失函数为:
由于C中只有Vj一个未知变量,因此C的最优化问题转化为最小二乘问题,用最小二乘法求解Vj的最优解:
固定j(j=1,2,......,n),则:C的导数
令
,得到:
即:
令
,
,则:
按照上式依次计算v1,v2,......,vn,从而得到
3、固定
此时,损失函数为:
同理,用步骤2中类似的方法,可以计算ui的值:
令
,得到:
即:
令
,
,则:
依照上式依次计算u1,u2,......,um,从而得到
4、循环执行步骤2、3,直到损失函数C的值收敛(或者设置一个迭代次数N,迭代执行步骤2、3 N次后停止)。这样,就得到了C最优解对应的矩阵U、V。
MovieLens 数据
该数据集由用户ID,影片ID,评分,时间戳组成
我们只需要前3个字段
/* Load the raw ratings data from a file. Replace 'PATH' with the path to the MovieLens data */ val rawData = sc.textFile("/PATH/ml-100k/u.data") rawData.first() // 14/03/30 13:21:25 INFO SparkContext: Job finished: first at <console>:17, took 0.002843 s // res24: String = 196 242 3 881250949 /* Extract the user id, movie id and rating only from the dataset */ val rawRatings = rawData.map(_.split("\t").take(3)) rawRatings.first() // 14/03/30 13:22:44 INFO SparkContext: Job finished: first at <console>:21, took 0.003703 s // res25: Array[String] = Array(196, 242, 3)
MLlib ALS模型
MLlib导入ALS模型:
import org.apache.spark.mllib.recommendation.ALS
我们看一下ALS.train函数:
ALS.train /* <console>:13: error: ambiguous reference to overloaded definition, both method train in object ALS of type (ratings: org.apache.spark.rdd.RDD[org.apache.spark.mllib.recommendation.Rating], rank: Int, iterations: Int)org.apache.spark.mllib.recommendation.MatrixFactorizationModel and method train in object ALS of type (ratings: org.apache.spark.rdd.RDD[org.apache.spark.mllib.recommendation.Rating], rank: Int, iterations: Int, lambda: Double)org.apache.spark.mllib.recommendation.MatrixFactorizationModel match expected type ? ALS.train ^ */
我们可以得知train函数需要四个参数:ratings: org.apache.spark.rdd.RDD[org.apache.spark.mllib.recommendation.Rating], rank: Int, iterations: Int, lambda: Double
1. ratings
org.apache.spark.mllib.recommendation.Rating类是对用户ID,影片ID,评分的封装
我们可以这样生成Rating的org.apache.spark.rdd.RDD:
val ratings = rawRatings.map { case Array(user, movie, rating) => Rating(user.toInt, movie.toInt, rating.toDouble) }
ratings.first()
// 14/03/30 13:26:43 INFO SparkContext: Job finished: first at <console>:24, took 0.002808 s
// res28: org.apache.spark.mllib.recommendation.Rating = Rating(196,242,3.0)
2. rank
对应ALS模型中的因子个数,即“两个小矩阵和”中的k
3. iterations
对应运行时的迭代次数
4. lambda:
控制模型的正则化过程,从而控制模型的过拟合情况。
由此,我们可以得到模型:
/* Train the ALS model with rank=50, iterations=10, lambda=0.01 */ val model = ALS.train(ratings, 50, 10, 0.01) // ... // 14/03/30 13:28:44 INFO MemoryStore: ensureFreeSpace(128) called with curMem=7544924, maxMem=311387750 // 14/03/30 13:28:44 INFO MemoryStore: Block broadcast_120 stored as values to memory (estimated size 128.0 B, free 289.8 MB) // model: org.apache.spark.mllib.recommendation.MatrixFactorizationModel = org.apache.spark.mllib.recommendation.MatrixFactorizationModel@7c7fbd3b /* Inspect the user factors */ model.userFeatures // res29: org.apache.spark.rdd.RDD[(Int, Array[Double])] = FlatMappedRDD[1099] at flatMap at ALS.scala:231 /* Count user factors and force computation */ model.userFeatures.count // ... // 14/03/30 13:30:08 INFO SparkContext: Job finished: count at <console>:26, took 5.009689 s // res30: Long = 943 model.productFeatures.count // ... // 14/03/30 13:30:59 INFO SparkContext: Job finished: count at <console>:26, took 0.247783 s // res31: Long = 1682 /* Make a prediction for a single user and movie pair */ val predictedRating = model.predict(789, 123)
二. 使用推荐模型
用户推荐
用户推荐,向给定用户推荐物品。这里,我们给用户789推荐前10个他可能喜欢的电影。我们可以先解析下电影资料数据集
该数据集是由“|”分割,我们只需要前两个字段电影ID和电影名称
val movies = sc.textFile("/PATH/ml-100k/u.item")
val titles = movies.map(line => line.split("\\|").take(2)).map(array => (array(0).toInt, array(1))).collectAsMap()
titles(123)
// res68: String = Frighteners, The (1996)
我们看一下预测的结果:
/* Make predictions for a single user across all movies */ val userId = 789 val K = 10 val topKRecs = model.recommendProducts(userId, K) println(topKRecs.mkString("\n")) /* Rating(789,715,5.931851273771102) Rating(789,12,5.582301095666215) Rating(789,959,5.516272981542168) Rating(789,42,5.458065302395629) Rating(789,584,5.449949837103569) Rating(789,750,5.348768847643657) Rating(789,663,5.30832117499004) Rating(789,134,5.278933936827717) Rating(789,156,5.250959077906759) Rating(789,432,5.169863417126231) */ topKRecs.map(rating => (titles(rating.product), rating.rating)).foreach(println) /* (To Die For (1995),5.931851273771102) (Usual Suspects, The (1995),5.582301095666215) (Dazed and Confused (1993),5.516272981542168) (Clerks (1994),5.458065302395629) (Secret Garden, The (1993),5.449949837103569) (Amistad (1997),5.348768847643657) (Being There (1979),5.30832117499004) (Citizen Kane (1941),5.278933936827717) (Reservoir Dogs (1992),5.250959077906759) (Fantasia (1940),5.169863417126231) */
我们再来看一下实际上的结果是:
val moviesForUser = ratings.keyBy(_.user).lookup(789) // moviesForUser: Seq[org.apache.spark.mllib.recommendation.Rating] = WrappedArray(Rating(789,1012,4.0), Rating(789,127,5.0), Rating(789,475,5.0), Rating(789,93,4.0), ... // ... println(moviesForUser.size) // 33 moviesForUser.sortBy(-_.rating).take(10).map(rating => (titles(rating.product), rating.rating)).foreach(println) /* (Godfather, The (1972),5.0) (Trainspotting (1996),5.0) (Dead Man Walking (1995),5.0) (Star Wars (1977),5.0) (Swingers (1996),5.0) (Leaving Las Vegas (1995),5.0) (Bound (1996),5.0) (Fargo (1996),5.0) (Last Supper, The (1995),5.0) (Private Parts (1997),4.0) */
很遗憾,一个都没对上~不过,这很正常。因为预测的结果恰好都是用户789没看过的电影,其预测的评分都在5.0以上,而实际上的结果是根据用户789已经看过的电影按评分排序获得的,这也体现的推荐系统的作用~
物品推荐
物品推荐,给定一个物品,哪些物品和它最相似。这里我们使用余弦相似度:
Cosine相似度计算
将查询语句的特征词的权值组成向量 a
网页中对应的特征词的权值组成向量 b
查询语句与该网页的Cosine相似度:

/* Compute the cosine similarity between two vectors */ def cosineSimilarity(vec1: DoubleMatrix, vec2: DoubleMatrix): Double = { vec1.dot(vec2) / (vec1.norm2() * vec2.norm2()) }
jblas线性代数库
这里MLlib库需要依赖jblas线性代数库,如果大家编译jblas的jar包有问题,可以到我的百度云上获取。把jar包加到lib文件夹后,记得在spark-env.sh添加配置:
SPARK_DIST_CLASSPATH="$SPARK_DIST_CLASSPATH:$SPARK_LIBRARY_PATH/jblas-1.2.4-SNAPSHOT.jar"
import org.jblas.DoubleMatrix val aMatrix = new DoubleMatrix(Array(1.0, 2.0, 3.0)) // aMatrix: org.jblas.DoubleMatrix = [1.000000; 2.000000; 3.000000]
求各个产品的余弦相似度:
val sims = model.productFeatures.map{ case (id, factor) =>
val factorVector = new DoubleMatrix(factor)
val sim = cosineSimilarity(factorVector, itemVector)
(id, sim)
}
求相似度最高的前10个相识电影。第一名肯定是自己,所以要取前11个,再除去第1个:
val sortedSims2 = sims.top(K + 1)(Ordering.by[(Int, Double), Double] { case (id, similarity) => similarity }) sortedSims2.slice(1, 11).map{ case (id, sim) => (titles(id), sim) }.mkString("\n") /* (Hideaway (1995),0.6932331537649621) (Body Snatchers (1993),0.6898690594544726) (Evil Dead II (1987),0.6897964975027041) (Alien: Resurrection (1997),0.6891221044611473) (Stephen King's The Langoliers (1995),0.6864214133620066) (Liar Liar (1997),0.6812075443259535) (Tales from the Crypt Presents: Bordello of Blood (1996),0.6754663844488256) (Army of Darkness (1993),0.6702643811753909) (Mystery Science Theater 3000: The Movie (1996),0.6594872765176396) (Scream (1996),0.6538249646863378) */
三.推荐模型评估
1.MSE/RMSE
均方差(MSE),就是对各个实际存在评分的项,pow(预测评分-实际评分,2)的值进行累加,在除以项数。而均方根差(RMSE)就是MSE开根号。
我们先用ratings生成(user,product)RDD,作为model.predict()的参数,从而生成以(user,product)为key,value为预测的rating的RDD。然后,用ratings生成以(user,product)为key,实际rating为value的RDD,并join上前者:
val usersProducts = ratings.map{ case Rating(user, product, rating) => (user, product)}
val predictions = model.predict(usersProducts).map{
case Rating(user, product, rating) => ((user, product), rating)
}
val ratingsAndPredictions = ratings.map{
case Rating(user, product, rating) => ((user, product), rating)
}.join(predictions)
ratingsAndPredictions.first()
//res21: ((Int, Int), (Double, Double)) = ((291,800),(2.0,2.052364223387371))
使用MLLib的评估函数,我们要传入一个(actual,predicted)的RDD。actual和predicted左右位置可以交换:
import org.apache.spark.mllib.evaluation.RegressionMetrics val predictedAndTrue = ratingsAndPredictions.map { case ((user, product), (actual, predicted)) => (actual, predicted) } val regressionMetrics = new RegressionMetrics(predictedAndTrue) println("Mean Squared Error = " + regressionMetrics.meanSquaredError) println("Root Mean Squared Error = " + regressionMetrics.rootMeanSquaredError) // Mean Squared Error = 0.08231947642632852 // Root Mean Squared Error = 0.2869137090247319
2. MAPK/MAP
K值平均准确率(MAPK)可以简单的这么理解:
设定推荐K=10,即推荐10个物品。预测该用户评分最高的10个物品ID作为文本1,实际上用户评分过所有物品ID作为文本2,求二者的相关度。(个人认为该评估方法在这里不是很适用)
我们可以按评分排序预测物品ID,再从头遍历,如果该预测ID出现在实际评分过ID的集合中,那么就增加一定分数(当然,排名高的应该比排名低的增加更多的分数,因为前者更能体现推荐的准确性)。最后将累加得到的分数除以min(K,actual.size)
如果是针对所有用户,我们需要把各个用户的累加分数进行累加,在除以用户数。
在MLlib里面,使用的是全局平均准确率(MAP,不设定K)。它需要我们传入(predicted.Array,actual.Array)的RDD。
现在,我们先来生成predicted:
我们先生成产品矩阵:
/* Compute recommendations for all users */ val itemFactors = model.productFeatures.map { case (id, factor) => factor }.collect() val itemMatrix = new DoubleMatrix(itemFactors) println(itemMatrix.rows, itemMatrix.columns) // (1682,50)
以便工作节点能够访问到,我们把该矩阵以广播变量的形式分发出去:
// broadcast the item factor matrix val imBroadcast = sc.broadcast(itemMatrix)
“”,矩阵相乘,计算出评分。scores.data.zipWithIndex,scores.data再按评分排序。生成recommendedIds,构建(userId, recommendedIds)RDD。
val allRecs = model.userFeatures.map{ case (userId, array) =>
val userVector = new DoubleMatrix(array)
val scores = imBroadcast.value.mmul(userVector)
val sortedWithId = scores.data.zipWithIndex.sortBy(-_._1)
val recommendedIds = sortedWithId.map(_._2 + 1).toSeq
(userId, recommendedIds)
}
生成actual:
// next get all the movie ids per user, grouped by user id val userMovies = ratings.map{ case Rating(user, product, rating) => (user, product) }.groupBy(_._1) // userMovies: org.apache.spark.rdd.RDD[(Int, Seq[(Int, Int)])] = MapPartitionsRDD[277] at groupBy at <console>:21
生成(predicted.Array,actual.Array)的RDD,并使用评估函数:
import org.apache.spark.mllib.evaluation.RankingMetrics val predictedAndTrueForRanking = allRecs.join(userMovies).map{ case (userId, (predicted, actualWithIds)) => val actual = actualWithIds.map(_._2) (predicted.toArray, actual.toArray) } val rankingMetrics = new RankingMetrics(predictedAndTrueForRanking) println("Mean Average Precision = " + rankingMetrics.meanAveragePrecision) // Mean Average Precision = 0.07171412913757183
