
论文笔记-Understanding Convolution for Semantic Segmentation
图森和CMU的合作工作。
论文链接[https://arxiv.org/abs/1702.08502](https://arxiv.org/abs/1702.08502)
主要提出DUC(dense upsampling convolution)和HDC(hybrid dilated convolution),其中DUC相当于用通道数来弥补卷积/池化等操作导致的尺寸的损失,HDC为了消除在连续使用dilation convolution时容易出现的gridding effect。
1. DUC

* 标准的bilinear interpolation是没有参数需要学习的,对于像素级的分割任务,会造成部分细节信息丢失。
* DUC模块,则是将所有特征图分成$d^2$个子集(d代表图像的降维比例)。假如原始图像大小为$H*W$,卷积之后变为$H/d*W/d$,用$h*w$代替,具体为:
* 先将原先的$h*w*c$变成$h*w*(d^2*L)$,L为分割的类别数目
* 将此后的输出reshape为$H*W*L$,以此引入多个学习的参数,提升对细节的分割效果
2. HDC
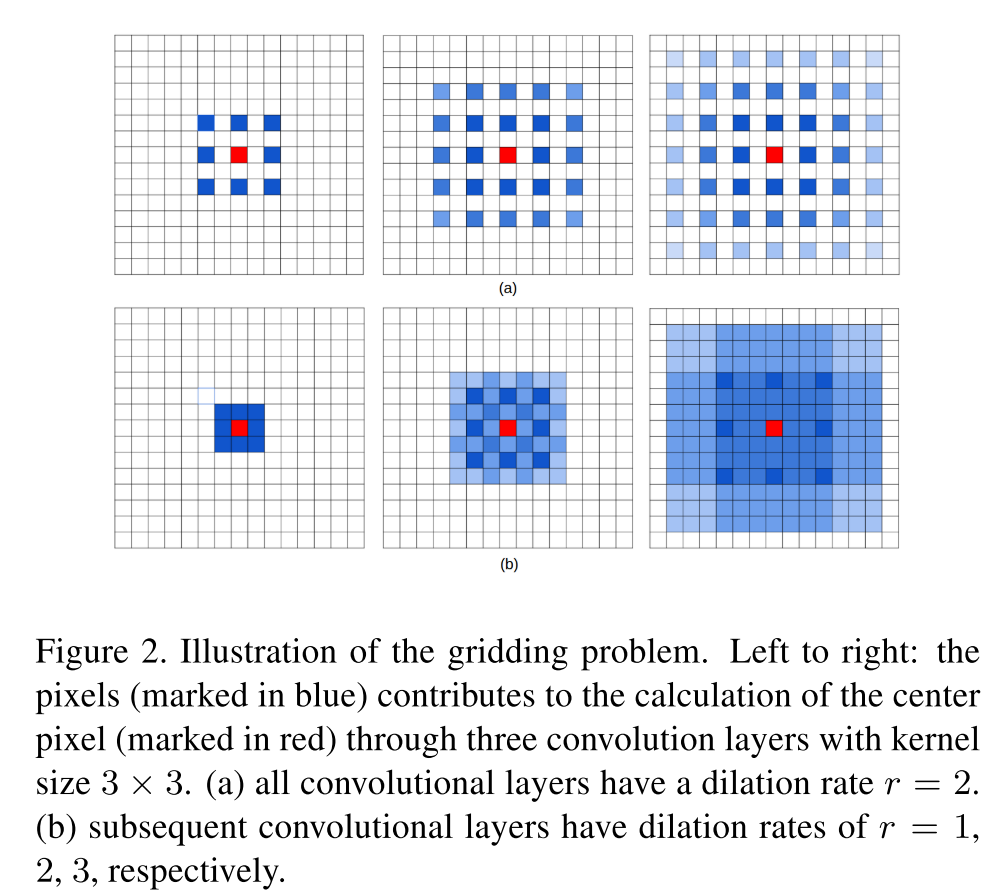
连续使用dilation conv时,dilation rate选择不当,已造成某些像素始终无法参与运算,作者将其描述为gridding现象,如下图。
为此,作者提出多种不同的dilation rate连续、交替使用的方案,即
* 连续使用dilation conv时,dilation rate设计成锯齿状结构,如[1,2,5, 1, 2, 5]
* 叠加的卷积层不要有大于1的公约数
* 满足公式
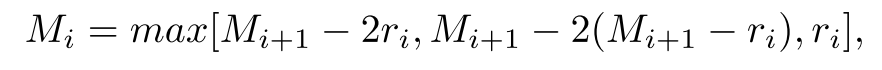
其中,$M_n = r_n$,该公式目标为使得$M_2 \leq K$
3. 实验
该部分,作者以DeepLab_V2为baseline model,并对比多种tricks的效果,如bigger patch size(data augmentation),larger dilation rate等,验证了larger dilation rate对性能的提升。
* 在Deeplab_v3中对dilation rate的使用提出一个思考,当dilation rate过大时,由于图像的边缘效应导致long range information并没有被学习到。
* 个人思考:在网络的底层,不适合使用较大的dilation rate(貌似很多都是用标准卷积),因为底层网络层更多包含底维信息,如果引入大的dilation rate,会导致部分细节的底层信息被忽略掉。
---
参考资料
1. [https://www.zhihu.com/question/54149221](https://www.zhihu.com/question/54149221)
2. [Rethinking Atrous Convolution for Semantic Image Segmentation](https://arxiv.org/abs/1706.05587)
------------恢复内容开始------------
图森和CMU的合作工作。
论文链接[https://arxiv.org/abs/1702.08502](https://arxiv.org/abs/1702.08502)
主要提出DUC(dense upsampling convolution)和HDC(hybrid dilated convolution),其中DUC相当于用通道数来弥补卷积/池化等操作导致的尺寸的损失,HDC为了消除在连续使用dilation convolution时容易出现的gridding effect。
1. DUC
* 标准的bilinear interpolation是没有参数需要学习的,对于像素级的分割任务,会造成部分细节信息丢失。
* DUC模块,则是将所有特征图分成$d^2$个子集(d代表图像的降维比例)。假如原始图像大小为\( H*W \),卷积之后变为\( H/d*W/d \),用\( h*w \)代替,具体为:
* 先将原先的\( h*w*c \)变成\( h*w*(d^2*L) \),L为分割的类别数目
* 将此后的输出reshape为\( H*W*L \),以此引入多个学习的参数,提升对细节的分割效果
2. HDC
连续使用dilation conv时,dilation rate选择不当,已造成某些像素始终无法参与运算,作者将其描述为gridding现象,如下图。
为此,作者提出多种不同的dilation rate连续、交替使用的方案,即
* 连续使用dilation conv时,dilation rate设计成锯齿状结构,如[1,2,5, 1, 2, 5]
* 叠加的卷积层不要有大于1的公约数
* 满足公式
其中,\( M_n = r_n \),该公式目标为使得\( M_2 \leq K \)
3. 实验
该部分,作者以DeepLab_V2为baseline model,并对比多种tricks的效果,如bigger patch size(data augmentation),larger dilation rate等,验证了larger dilation rate对性能的提升。
* 在Deeplab_v3中对dilation rate的使用提出一个思考,当dilation rate过大时,由于图像的边缘效应导致long range information并没有被学习到。
* 个人思考:在网络的底层,不适合使用较大的dilation rate(貌似很多都是用标准卷积),因为底层网络层更多包含底维信息,如果引入大的dilation rate,会导致部分细节的底层信息被忽略掉。
---
参考资料
1. [https://www.zhihu.com/question/54149221](https://www.zhihu.com/question/54149221)
2. [Rethinking Atrous Convolution for Semantic Image Segmentation](https://arxiv.org/abs/1706.05587)
------------恢复内容结束------------

