
nodejs和vue的那些事
- nodejs
>1.旨在提供一种简单的构建可伸缩网络程序的方法
官方网站:http://nodejs.cn/api/
Node.js 是一个基于Chromev8 JavaScript 运行时建立的一个平台, 用来方便地搭建快速的, 易于扩展的网络应用· Node.js 借助事件驱动, 非阻塞 I/O 模型变得轻量和高效
>2特点
\1. 它是一个Javascript运行环境
\2. 依赖于Chrome V8引擎进行代码解释
\3. 事件驱动
\4. 非阻塞I/O
\5. 轻量、可伸缩,适于实时数据交互应用
\6. 单进程,单线程
>3NodeJS的优缺点
优点:
1. 高并发(最重要的优点)
\2. 适合I/O密集型应用
缺点:
1. 不适合CPU密集型应用;CPU密集型应用给Node带来的挑战主要是:由于JavaScript单线程的原因,如果有长时间运行的计算(比如大循环),将会导致CPU时间片不能释放,使得后续I/O无法发起;
解决方案:分解大型运算任务为多个小任务,使得运算能够适时释放,不阻塞I/O调用的发起;
\2. 只支持单核CPU,不能充分利用CPU
\3. 可靠性低,一旦代码某个环节崩溃,整个系统都崩溃
原因:单进程,单线程
>4. 适合NodeJS的场景
\1. RESTful API
这是NodeJS最理想的应用场景,可以处理数万条连接,本身没有太多的逻辑,只需要请求API,组织数据进行返回即可。它本质上只是从某个数据库中查找一些值并将它们组成一个响应。由于响应是少量文本,入站请求也是少量的文本,因此流量不高,一台机器甚至也可以处理最繁忙的公司的API需求。
\2. 统一Web应用的UI层
目前MVC的架构,在某种意义上来说,Web开发有两个UI层,一个是在浏览器里面我们最终看到的,另一个在server端,负责生成和拼接页面。
不讨论这种架构是好是坏,但是有另外一种实践,面向服务的架构,更好的做前后端的依赖分离。如果所有的关键业务逻辑都封装成REST调用,就意味着在上层只需要考虑如何用这些REST接口构建具体的应用。那些后端程序员们根本不操心具体数据是如何从一个页面传递到另一个页面的,他们也不用管用户数据更新是通过Ajax异步获取的还是通过刷新页面。
\3. 大量Ajax请求的应用
例如个性化应用,每个用户看到的页面都不一样,缓存失效,需要在页面加载的时候发起Ajax请求,NodeJS能响应大量的并发请求。 总而言之,NodeJS适合运用在高并发、I/O密集、少量业务逻辑的场景。
2.模块中能放那些东西
function class variable
Node,CommonJS,浏览器甚至是W3C之间有什么关系:
概述
Node 应用由模块组成,采用 CommonJS 模块规范。
每个文件就是一个模块,有自己的作用域。在一个文件里面定义的变量、函数、类,都是私有的,对其他文件不可见。
// example.js
var x = 5;
var addX = function (value) {
return value + x;
};
上面代码中,变量x和函数addX,是当前文件example.js私有的,其他文件不可见。
如果想在多个文件分享变量,必须定义为global对象的属性。
global.warning = true;
上面代码的warning变量,可以被所有文件读取。当然,这样写法是不推荐的。
CommonJS规范规定,每个模块内部,module变量代表当前模块。这个变量是一个对象,它的exports属性(即module.exports)是对外的接口。加载某个模块,其实是加载该模块的module.exports属性。
var x = 5;
var addX = function (value) {
return value + x;
};
module.exports.x = x;
module.exports.addX = addX;
上面代码通过module.exports输出变量x和函数addX。
require方法用于加载模块。
var example = require('./example.js');
console.log(example.x); // 5
console.log(example.addX(1)); // 6
require方法的详细解释参见《Require命令》一节。
CommonJS模块的特点如下。
- 所有代码都运行在模块作用域,不会污染全局作用域。
- 模块可以多次加载,但是只会在第一次加载时运行一次,然后运行结果就被缓存了,以后再加载,就直接读取缓存结果。要想让模块再次运行,必须清除缓存。
- 模块加载的顺序,按照其在代码中出现的顺序。
module对象
Node内部提供一个Module构建函数。所有模块都是Module的实例。
function Module(id, parent) {
this.id = id;
this.exports = {};
this.parent = parent;
// ...
每个模块内部,都有一个module对象,代表当前模块。它有以下属性。
module.id模块的识别符,通常是带有绝对路径的模块文件名。module.filename模块的文件名,带有绝对路径。module.loaded返回一个布尔值,表示模块是否已经完成加载。module.parent返回一个对象,表示调用该模块的模块。module.children返回一个数组,表示该模块要用到的其他模块。module.exports表示模块对外输出的值。
下面是一个示例文件,最后一行输出module变量。
// example.js
var jquery = require('jquery');
exports.$ = jquery;
console.log(module);
执行这个文件,命令行会输出如下信息。
{ id: '.',
exports: { '$': [Function] },
parent: null,
filename: '/path/to/example.js',
loaded: false,
children:
[ { id: '/path/to/node_modules/jquery/dist/jquery.js',
exports: [Function],
parent: [Circular],
filename: '/path/to/node_modules/jquery/dist/jquery.js',
loaded: true,
children: [],
paths: [Object] } ],
paths:
[ '/home/user/deleted/node_modules',
'/home/user/node_modules',
'/home/node_modules',
'/node_modules' ]
}
如果在命令行下调用某个模块,比如node something.js,那么module.parent就是null。如果是在脚本之中调用,比如require('./something.js'),那么module.parent就是调用它的模块。利用这一点,可以判断当前模块是否为入口脚本。
if (!module.parent) {
// ran with `node something.js`
app.listen(8088, function() {
console.log('app listening on port 8088');
})
} else {
// used with `require('/.something.js')`
module.exports = app;
}
module.exports属性
module.exports属性表示当前模块对外输出的接口,其他文件加载该模块,实际上就是读取module.exports变量。
var EventEmitter = require('events').EventEmitter;
module.exports = new EventEmitter();
setTimeout(function() {
module.exports.emit('ready');
}, 1000);
上面模块会在加载后1秒后,发出ready事件。其他文件监听该事件,可以写成下面这样。
var a = require('./a');
a.on('ready', function() {
console.log('module a is ready');
});
exports变量
为了方便,Node为每个模块提供一个exports变量,指向module.exports。这等同在每个模块头部,有一行这样的命令。
var exports = module.exports;
造成的结果是,在对外输出模块接口时,可以向exports对象添加方法。
exports.area = function (r) {
return Math.PI * r * r;
};
exports.circumference = function (r) {
return 2 * Math.PI * r;
};
注意,不能直接将exports变量指向一个值,因为这样等于切断了exports与module.exports的联系。
exports = function(x) {console.log(x)};
上面这样的写法是无效的,因为exports不再指向module.exports了。
下面的写法也是无效的。
exports.hello = function() {
return 'hello';
};
module.exports = 'Hello world';
上面代码中,hello函数是无法对外输出的,因为module.exports被重新赋值了。
这意味着,如果一个模块的对外接口,就是一个单一的值,不能使用exports输出,只能使用module.exports输出。
module.exports = function (x){ console.log(x);};
如果你觉得,exports与module.exports之间的区别很难分清,一个简单的处理方法,就是放弃使用exports,只使用module.exports。
AMD规范与CommonJS规范的兼容性
CommonJS规范加载模块是同步的,也就是说,只有加载完成,才能执行后面的操作。AMD规范则是非同步加载模块,允许指定回调函数。由于Node.js主要用于服务器编程,模块文件一般都已经存在于本地硬盘,所以加载起来比较快,不用考虑非同步加载的方式,所以CommonJS规范比较适用。但是,如果是浏览器环境,要从服务器端加载模块,这时就必须采用非同步模式,因此浏览器端一般采用AMD规范。
AMD规范使用define方法定义模块,下面就是一个例子:
define(['package/lib'], function(lib){
function foo(){
lib.log('hello world!');
}
return {
foo: foo
};
});
AMD规范允许输出的模块兼容CommonJS规范,这时define方法需要写成下面这样:
define(function (require, exports, module){
var someModule = require("someModule");
var anotherModule = require("anotherModule");
someModule.doTehAwesome();
anotherModule.doMoarAwesome();
exports.asplode = function (){
someModule.doTehAwesome();
anotherModule.doMoarAwesome();
};
});
require命令
基本用法
Node使用CommonJS模块规范,内置的require命令用于加载模块文件。
require命令的基本功能是,读入并执行一个JavaScript文件,然后返回该模块的exports对象。如果没有发现指定模块,会报错。
// example.js
var invisible = function () {
console.log("invisible");
}
exports.message = "hi";
exports.say = function () {
console.log(message);
}
运行下面的命令,可以输出exports对象。
var example = require('./example.js');
example
// {
// message: "hi",
// say: [Function]
// }
如果模块输出的是一个函数,那就不能定义在exports对象上面,而要定义在module.exports变量上面。
module.exports = function () {
console.log("hello world")
}
require('./example2.js')()
上面代码中,require命令调用自身,等于是执行module.exports,因此会输出 hello world。
加载规则
require命令用于加载文件,后缀名默认为.js。
var foo = require('foo');
// 等同于
var foo = require('foo.js');
根据参数的不同格式,require命令去不同路径寻找模块文件。
(1)如果参数字符串以“/”开头,则表示加载的是一个位于绝对路径的模块文件。比如,require('/home/marco/foo.js')将加载/home/marco/foo.js。
(2)如果参数字符串以“./”开头,则表示加载的是一个位于相对路径(跟当前执行脚本的位置相比)的模块文件。比如,require('./circle')将加载当前脚本同一目录的circle.js。
(3)如果参数字符串不以“./“或”/“开头,则表示加载的是一个默认提供的核心模块(位于Node的系统安装目录中),或者一个位于各级node_modules目录的已安装模块(全局安装或局部安装)。
举例来说,脚本/home/user/projects/foo.js执行了require('bar.js')命令,Node会依次搜索以下文件。
- /usr/local/lib/node/bar.js
- /home/user/projects/node_modules/bar.js
- /home/user/node_modules/bar.js
- /home/node_modules/bar.js
- /node_modules/bar.js
这样设计的目的是,使得不同的模块可以将所依赖的模块本地化。
(4)如果参数字符串不以“./“或”/“开头,而且是一个路径,比如require('example-module/path/to/file'),则将先找到example-module的位置,然后再以它为参数,找到后续路径。
(5)如果指定的模块文件没有发现,Node会尝试为文件名添加.js、.json、.node后,再去搜索。.js件会以文本格式的JavaScript脚本文件解析,.json文件会以JSON格式的文本文件解析,.node文件会以编译后的二进制文件解析。
(6)如果想得到require命令加载的确切文件名,使用require.resolve()方法。
目录的加载规则
通常,我们会把相关的文件会放在一个目录里面,便于组织。这时,最好为该目录设置一个入口文件,让require方法可以通过这个入口文件,加载整个目录。
在目录中放置一个package.json文件,并且将入口文件写入main字段。下面是一个例子。
// package.json
{ "name" : "some-library",
"main" : "./lib/some-library.js" }
require发现参数字符串指向一个目录以后,会自动查看该目录的package.json文件,然后加载main字段指定的入口文件。如果package.json文件没有main字段,或者根本就没有package.json文件,则会加载该目录下的index.js文件或index.node文件。
模块的缓存
第一次加载某个模块时,Node会缓存该模块。以后再加载该模块,就直接从缓存取出该模块的module.exports属性。
require('./example.js');
require('./example.js').message = "hello";
require('./example.js').message
// "hello"
上面代码中,连续三次使用require命令,加载同一个模块。第二次加载的时候,为输出的对象添加了一个message属性。但是第三次加载的时候,这个message属性依然存在,这就证明require命令并没有重新加载模块文件,而是输出了缓存。
如果想要多次执行某个模块,可以让该模块输出一个函数,然后每次require这个模块的时候,重新执行一下输出的函数。
所有缓存的模块保存在require.cache之中,如果想删除模块的缓存,可以像下面这样写。
// 删除指定模块的缓存
delete require.cache[moduleName];
// 删除所有模块的缓存
Object.keys(require.cache).forEach(function(key) {
delete require.cache[key];
})
注意,缓存是根据绝对路径识别模块的,如果同样的模块名,但是保存在不同的路径,require命令还是会重新加载该模块。
环境变量NODE_PATH
Node执行一个脚本时,会先查看环境变量NODE_PATH。它是一组以冒号分隔的绝对路径。在其他位置找不到指定模块时,Node会去这些路径查找。
可以将NODE_PATH添加到.bashrc。
export NODE_PATH="/usr/local/lib/node"
所以,如果遇到复杂的相对路径,比如下面这样。
var myModule = require('../../../../lib/myModule');
有两种解决方法,一是将该文件加入node_modules目录,二是修改NODE_PATH环境变量,package.json文件可以采用下面的写法。
{
"name": "node_path",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"start": "NODE_PATH=lib node index.js"
},
"author": "",
"license": "ISC"
}
NODE_PATH是历史遗留下来的一个路径解决方案,通常不应该使用,而应该使用node_modules目录机制。
模块的循环加载
如果发生模块的循环加载,即A加载B,B又加载A,则B将加载A的不完整版本。
// a.js
exports.x = 'a1';
console.log('a.js ', require('./b.js').x);
exports.x = 'a2';
// b.js
exports.x = 'b1';
console.log('b.js ', require('./a.js').x);
exports.x = 'b2';
// main.js
console.log('main.js ', require('./a.js').x);
console.log('main.js ', require('./b.js').x);
上面代码是三个JavaScript文件。其中,a.js加载了b.js,而b.js又加载a.js。这时,Node返回a.js的不完整版本,所以执行结果如下。
$ node main.js
b.js a1
a.js b2
main.js a2
main.js b2
修改main.js,再次加载a.js和b.js。
// main.js
console.log('main.js ', require('./a.js').x);
console.log('main.js ', require('./b.js').x);
console.log('main.js ', require('./a.js').x);
console.log('main.js ', require('./b.js').x);
执行上面代码,结果如下。
$ node main.js
b.js a1
a.js b2
main.js a2
main.js b2
main.js a2
main.js b2
上面代码中,第二次加载a.js和b.js时,会直接从缓存读取exports属性,所以a.js和b.js内部的console.log语句都不会执行了。
require.main
require方法有一个main属性,可以用来判断模块是直接执行,还是被调用执行。
直接执行的时候(node module.js),require.main属性指向模块本身。
require.main === module
// true
调用执行的时候(通过require加载该脚本执行),上面的表达式返回false。
模块的加载机制
CommonJS模块的加载机制是,输入的是被输出的值的拷贝。也就是说,一旦输出一个值,模块内部的变化就影响不到这个值。请看下面这个例子。
下面是一个模块文件lib.js。
// lib.js
var counter = 3;
function incCounter() {
counter++;
}
module.exports = {
counter: counter,
incCounter: incCounter,
};
上面代码输出内部变量counter和改写这个变量的内部方法incCounter。
然后,加载上面的模块。
// main.js
var counter = require('./lib').counter;
var incCounter = require('./lib').incCounter;
console.log(counter); // 3
incCounter();
console.log(counter); // 3
上面代码说明,counter输出以后,lib.js模块内部的变化就影响不到counter了。
require的内部处理流程
require命令是CommonJS规范之中,用来加载其他模块的命令。它其实不是一个全局命令,而是指向当前模块的module.require命令,而后者又调用Node的内部命令Module._load。
Module._load = function(request, parent, isMain) {
// 1. 检查 Module._cache,是否缓存之中有指定模块
// 2. 如果缓存之中没有,就创建一个新的Module实例
// 3. 将它保存到缓存
// 4. 使用 module.load() 加载指定的模块文件,
// 读取文件内容之后,使用 module.compile() 执行文件代码
// 5. 如果加载/解析过程报错,就从缓存删除该模块
// 6. 返回该模块的 module.exports
};
上面的第4步,采用module.compile()执行指定模块的脚本,逻辑如下。
Module.prototype._compile = function(content, filename) {
// 1. 生成一个require函数,指向module.require
// 2. 加载其他辅助方法到require
// 3. 将文件内容放到一个函数之中,该函数可调用 require
// 4. 执行该函数
};
上面的第1步和第2步,require函数及其辅助方法主要如下。
require(): 加载外部模块require.resolve():将模块名解析到一个绝对路径require.main:指向主模块require.cache:指向所有缓存的模块require.extensions:根据文件的后缀名,调用不同的执行函数
一旦require函数准备完毕,整个所要加载的脚本内容,就被放到一个新的函数之中,这样可以避免污染全局环境。该函数的参数包括require、module、exports,以及其他一些参数。
(function (exports, require, module, __filename, __dirname) {
// YOUR CODE INJECTED HERE!
});
Module._compile方法是同步执行的,所以Module._load要等它执行完成,才会向用户返回module.exports的值。
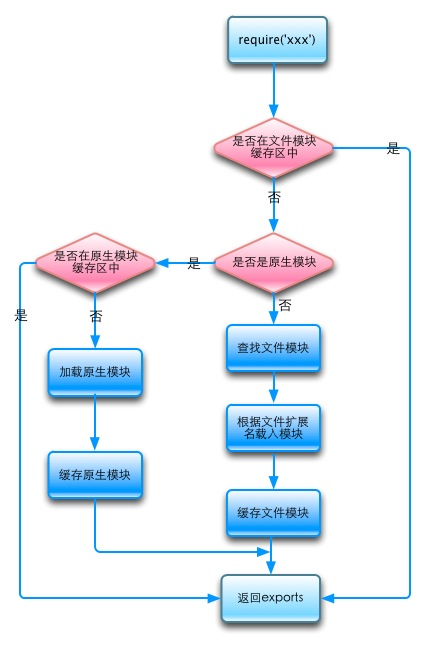
require方法接受以下几种参数的传递:
1. http、fs、path等,原生模块。
2. ./mod或../mod,相对路径的文件模块。
3. /pathtomodule/mod,绝对路径的文件模块。
4. mod,非原生模块的文件模块。
当require一个文件模块时,从当前文件目录开始查找node_modules目录;然后依次进入父目录,查找父目录下的
node_modules目录;依次迭代,直到根目录下的node_modules目录。
简而言之,如果require绝对路径的文件,查找时不会去遍历每一个node_modules目录,其速度最快。其余
流程如下:
从module path数组中取出第一个目录作为查找基准。
1. 直接从目录中查找该文件,如果存在,则结束查找。如果不存在,则进行下一条查找。
2. 尝试添加.js、.json、.node后缀后查找,如果存在文件,则结束查找。如果不存在,则进行下一条。
3. 尝试将require的参数作为一个包来进行查找,读取目录下的package.json文件,取得main参数指定的文件。
4. 尝试查找该文件,如果存在,则结束查找。如果不存在,则进行第3条查找
5. 如果继续失败,则取出module path数组中的下一个目录作为基准查找,循环第1至5个步骤。
6. 如果继续失败,循环第1至6个步骤,直到module path中的最后一个值。
7. 如果仍然失败,则抛出异常。
module.exports还是exports
一个模块可以通过module.exports或exports将函数、变量等导出,以使其它JavaScript脚本通过require()函数引
入并使用。
如果你想你的模块是一个特定的类型就用module.exports。如果你想的模块是一个典型
的”实例化对象”就用exports。
require返回的其实是module.exports这个方法,exports其实是指向module.exports的一个引用
二、Node.js的Path对象
NodeJS中的Path对象,用于处理目录的对象,提高开发效率。 用NodeJS的Path命令,与使用Linux下的shell脚本
命令相似。
引入path对象:
var path = require('path');
比较实用的方法:
1. path.normalize(p) : 格式化路径
特点:将不符合规范的路径格式化,简化开发人员中处理各种复杂的路径判断
2. path.join([path1], [path2], […]) : 路径合并
特点:将所有名称用path.seq串联起来,然后用normailze格式化
3. path.resolve([from …], to) : 路径寻航
特点:相当于不断的调用系统的cd命令
示例:
path.normalize('/foo/bar//baz/asdf/quux/..');
=> '/foo/bar/baz/asdf'
示例:
path.join('///foo', 'bar', '//baz/asdf', 'quux', '..');
=>'/foo/bar/baz/asdf'
4. path.relative(from, to) : 相对路径
特点:返回某个路径下相对于另一个路径的相对位置串,相当于:path.resolve(from, path.relative(from,
to)) == path.resolve(to)
5. path.dirname(p) : 文件夹名称
特点:返回路径的所在的文件夹名称
6. path.basename(p, [ext]) : 文件名称
6. path.basename(p, [ext]) : 文件名称
特点:返回指定的文件名,返回结果可排除[ext]后缀字符串
7. 扩展名称 path.extname(p)
示例:
path.resolve('foo/bar', '/tmp/file/', '..', 'a/../subfile')
//相当于:
cd foo/bar
cd /tmp/file/
cd ..
cd a/../subfile
pwd
示例:
path.relative('C:\\orandea\\test\\aaa', 'C:\\orandea\\impl\\bbb')
=>'..\\..\\impl\\bbb'
path.relative('/data/orandea/test/aaa', '/data/orandea/impl/bbb')
=>'../../impl/bbb'
示例:
path.dirname('/foo/bar/baz/asdf/quux')
=>'/foo/bar/baz/asdf'
示例
path.basename('/foo/bar/baz/asdf/quux.html')
=>'quux.html'
path.basename('/foo/bar/baz/asdf/quux.html', '.html')
=>'quux'
特点:返回指定文件名的扩展名称
8. 特定平台的文件分隔符 path.sep
特点:获取文件路径的分隔符,主要是与操作系统相关
9. 特定平台的路径分隔符 path.delimiter
特定平台的路径分隔符, ‘;‘ 或者 ‘:‘.
Linux 上的例子:
Windows 上的例子:
示例:
path.extname('index.html')
=>'.html'
path.extname('index.')
=>'.'
path.extname('index')
=>''
示例:
linux:
'foo/bar/baz'.split(path.sep)
=>['foo', 'bar', 'baz']
window:
'foo\\bar\\baz'.split(path.sep)
=>['foo', 'bar', 'baz']
process.env.PATH.split(path.delimiter)
// returns
['/usr/bin', '/bin', '/usr/sbin', '/sbin', '/usr/local/bin']
console.log(process.env.PATH)
// 'C:\Windows\system32;C:\Windows;C:\Program Files\nodejs\'
process.env.PATH.split(path.delimiter)
// returns
['C:\Windows\system32', 'C:\Windows', 'C:\Program Files\nodejs\']
process.env.PATH.split(path.delimiter)
// returns
['C:\Windows\system32', 'C:\Windows', 'C:\Program Files\nodejs\']
nodejs 全局变量
1. module.filename:开发期间,该行代码所在的文件。
2. __filename:始终等于 module.filename。
3. __dirname:开发期间,该行代码所在的目录。
4. process.cwd():运行node的工作目录,可以使用 cd /d 修改工作目录。
5. require.main.filename:用node命令启动的module的filename, 如 node xxx,这里的filename就是这个
xxx。
require()方法的坐标路径是:module.filename;
fs.readFile()的坐标路径是:process.cwd()。
异步(async)和同步(sync)
Nodejs中Api一般都是异步的接口,如果调用同步的只需要在后面加上xxxSync()。
Node.js 文件系统(fs 模块)模块中的方法均有异步和同步版本,例如读取文件内容的函数有异步的
fs.readFile() 和同步的 fs.readFileSync()。
Node文件系统:目录操作
1. 判断文件路径是否存在: fs.exists(path, callback)
参数说明:
2. 创建目录 fs.mkdir/mkdirSync(path[, mode], callback)
var fs = require("fs");
//异步读取文件
fs.readFile('input.txt', function (err, data) {
if (err) {
return console.error(err);
}
console.log("Asynchronous read: " + data.toString());
});
// /同步读取文件
var data = fs.readFileSync('input.txt');
console.log("Synchronous read: " + data.toString());
console.log("Program Ended");
path 欲检测的文件路径
callback 回调
fs.exists("test",function(exists){
console.log(exists);
})
path - 文件路径 ; mode - 设置目录权限,默认为0777 callback - 回调函数
3. 查看目录 fs.readdir(path, callback(err, files))
path - 文件路径。
callback - 回调函数,回调函数带有两个参数err, files,err 为错误信息,files 为 目录下的文件数组列表
返回结果: [ 'note.txt' ]
4. 删除目录 fs.rmdir(path, callback)
参数使用说明如下:
path - 文件路径。 callback - 回调函数,没有参数。
注意:只能删除空的目录,有文件的目录会报错:
[Error: ENOTEMPTY: directory not empty, rmdir 'F:\FullStack-Cource-2017\Nodejs-Laravel-Action\03-
Node模块-FileSystem\test']
Node文件模块:文件操作说明
1. 写入文件 fs.writeFile(filename, data[, options], callback)
如果文件存在,写入的内容会覆盖旧文件内容
参数使用说明如下:
var fs = require("fs");
fs.mkdir("test",function(error){
if (err) return console.error(err);
console.log('目录创建成功');
})
fs.readdir("test",function(error,files){
console.log(files);
})
fs.rmdir("test",function(error){
console.log(error);
})
2. 文件读取 fs.readFile( url , code , callback);
1. 异步读取文件
fs.readFile("test/1.txt","utf-8",function(error,data){ console.log(data); })
2. 异步读取文件
var data =fs.readFileSync("test/1.txt","utf-8"); console.log(data);
3. 向文件中追加写入 fs.appendFile(name,str,encode,callback);
参数说明:
name : 文件名 str : 添加的字段 encode : 设置编码 callback : 回调函数
栗子
fs.appendFile("test/1.txt",'窗前明月光,疑是地上霜','utf8',function(eror){
})
4. 改变文件名 : fs.rename(old文件名,新文件名,callback(传递一个err
参数))
fs.rename("test/1.txt","test/a.txt",function(error){
})
5. 查看文件状态 fs.stat(fileaddr,callback(error,stats))
在fs模块中,可以使用 fs.stat() 方法或 fs.lstat() 方法查看一个文件或目录的信息,如文件的大小、创建时
间、权限等信息。这两个方法的唯一区别是当查看符号链接文件的信息时,必须使用 fs.lstat() 方法。
var fs = require("fs"); var path = require("path");
path - 文件路径。
data - 要写入文件的数据,可以是 String(字符串) 或 Buffer(流) 对象。
options - 该参数是一个对象,包含 {encoding, mode, flag}。默认编码为 utf8, 模式为 0666 ,flag 为
'w'
callback - 回调函数,回调函数只包含错误信息参数(err),在写入失败时返回。
var fs = require("fs");
fs.writeFile("test/1.txt","hello file",function(error){
console.log(error);
})
var fileaddr = path.resolve(__dirname,"file/note.txt");
/**
* fileaddr: 需要查看状态的相对,或者绝对地址
fs.Stats对象的方法如下:
stats.isFile() : 判断被查看对象是否是一个文件。如果是标准文件,返回true。是目录、套接字、符号连
接、或设备等返回false。
stats. isDirectory() : 判断被查看对象是否是一个目录。如果是目录,返回true。
stats. isBlockDevice() : 判断被查看对象是否是一个块设备文件。 如果是块设备,返回true,大多数情况下
类UNIX系统的块设备都位于/dev目录下。
stats. isCharacterDevice() : 判断被查看对象是否是一个字符设备文件。如果是字符设备,返回true。
stats. isSymbolicLink() : 判断被查看对象是否是一个符号链接文件。如果是符号连接,返回true。该方法仅
在fs.lstat()方法的回调函数中有效。
stats.isFIFO() : 判断被查看对象是否是一个FIFO文件。如果是FIFO,返回true。FIFO是UNIX中的一种特殊
类型的命令管道。该方法仅在LINUX系统下有效。
stats.isSocket() : 判断被查看对象是否是一个socket文件。 如果是UNIX套接字,返回true。该方法仅在
LINUX系统下有效。
fs.Stats对象的属性如下:
dev : 文件或目录所在的设备ID。该属性值在UNIX系统下有效;
mode : 文件或目录的权限标志,采用数值形式表示;
nlink : 文件或目录的的硬连接数量;
uid : 文件或目录的所有者的用户ID。该属性值在UNIX系统下有效;
gid : 文件或目录的所有者的用户组ID。该属性值在UNIX系统下有效;
rdev : 字符设备文件或块设备文件所在设备ID。该属性值在UNIX系统下有效;**
ino : 文件或目录的索引编号。该属性值仅在UNIX系统下有效;
size : 文件的字节数;
* callback(error,stats): error:返回的错误信息
* stats:返回的成功信息
*/
fs.stat(fileaddr,function(error,stats){
if(error){
console.log(error)
}else{
console.log(stats);
console.log(stats.isFile());
console.log(stats.isDirectory());
console.log(stats.isCharacterDevice());
console.log(stats.isSymbolicLink());
console.log(stats.isFIFO());
console.log(stats.isSocket());
console.log(stats.isBlockDevice());
}
})
atime : 文件或目录的访问时间;
mtime : 文件或目录的最后修改时间;
ctime : 文件或目录状态的最后修改时间;
birthtime : 文件创建时间,文件创建时生成。在一些不提供文件
birthtime 的文件系统中,这个字段会使用 ctime 或 1970-01-01T00:00Z 来填充;
6. 删除文件 fs.unlink(path, callback)
参数说明
path - 文件路径 callback - 回调函数,无参
fs.unlink("test/a.txt",function(){})
url
┌─────────────────────────────────────────────────────────────────────────────────────────────┐ │ href │ ├──────────┬──┬─────────────────────┬─────────────────────┬───────────────────────────┬───────┤ │ protocol │ │ auth │ host │ path │ hash │ │ │ │ ├──────────────┬──────┼──────────┬────────────────┤ │ │ │ │ │ hostname │ port │ pathname │ search │ │ │ │ │ │ │ │ ├─┬──────────────┤ │ │ │ │ │ │ │ │ │ query │ │ " https: // user : pass @ sub.host.com : 8080 /p/a/t/h ? query=string #hash " │ │ │ │ │ hostname │ port │ │ │ │ │ │ │ │ ├──────────────┴──────┤ │ │ │ │ protocol │ │ username │ password │ host │ │ │ │ ├──────────┴──┼──────────┴──────────┼─────────────────────┤ │ │ │ │ origin │ │ origin │ pathname │ search │ hash │ ├─────────────┴─────────────────────┴─────────────────────┴──────────┴────────────────┴───────┤ │ href │ └─────────────────────────────────────────────────────────────────────────────────────────────┘
http服务器端 :http.server的事件
1、http.Server 的事件
http.Server 是一个基于事件的 HTTP 服务器,所有的请求都被封装为独立的事件,开发者只需要对它的事件编写
响应函数即可实现 HTTP 服务器的所有功能。它继承自EventEmitter,提供了以下几个事件。
①request:当客户端请求到来时,该事件被触发,提供两个参数 req 和res,分别是http.ServerRequest 和
http.ServerResponse 的实例,表示请求和响应信息。
request.post('http://service.com/upload', {form:{key:'value'}})
request.post('http://service.com/upload').form({key:'value'})
var r = request.post('http://service.com/upload')
var form = r.form()
form.append('my_field', 'my_value')
form.append('my_buffer', new Buffer([1, 2, 3]))
form.append('my_file', fs.createReadStream(path.join(__dirname, 'doodle.png'))
form.append('remote_file', request('http://google.com/doodle.png'))
var server =new http.Server();
server.on("request",function(request,response){
//用于接收客户端post过来的数据
var reqJson="";
request.on("data",function(chunk){
reqJson +=chunk;
});
request.on("end",function(){
console.log(reqJson);
response.writeHead(200,{
'Content-Type':'text/html'
});
//对接收的数据处理后返回
response.end(reqJson);
})
});
② connection:当 TCP 连接建立时,该事件被触发,提供一个参数 socket,为net.Socket 的实例。
connection 事件的粒度要大于 request,因为客户端在Keep-Alive 模式下可能会在同一个连接内发送多次请
求。
③close :当服务器关闭时,该事件被触发。注意不是在用户连接断开时。除此之外还有 checkContinue、
upgrade、clientError 事件,通常我们不需要关心,只有在实现复杂的 HTTP 服务器的时候才会用到。
在这些事件中, 最常用的就是 request 了, 因此 http 提供了一个捷径:
http.createServer([requestListener]) , 功能是创建一个 HTTP 服务器并将requestListener 作为 request 事
件的监听函数,这也是我们前面例子中使用的方法。
var http = require('http');
/**
* 创建服务器的两种写法,第一种写法如下
* 由于server已经继承了EventEmitter的事件功能,所以可以使用高级函数编写方式监控事件
* @param {Function} request event
*/
var server = http.createServer(function(req,res)
{
//这里的req为http.serverRequest
res.writeHeader(200,{'Content-Type':'text/plain'});
res.end('hello world');
});
/**
* 说明:创建服务器的第二种写法
* 有关server对象的事件监听
* @param {Object} req 是http.IncomingMessag的一个实例,在keep-alive连接中支持多个请求
* @param {Object} res 是http.ServerResponse的一个实例
*/
var server = new http.Server();
server.on('request',function(req,res){
res.writeHeader(200,{'Content-Type':'text/plain'});
res.end('hello world');
});
/**
* 说明:新的TCP流建立时出发。 socket是一个net.Socket对象。 通常用户无需处理该事件。
* 特别注意,协议解析器绑定套接字时采用的方式使套接字不会出发readable事件。 还可以通过
request.connection访问socket。
* @param {Object} socket
*/
server.on('connection',function(socket){});
/**
* 源API: Event: 'close'
* 说明:关闭服务器时触发
*/
server.on('close',function(){});
/**
* 说明:每当收到Expect: 100-continue的http请求时触发。 如果未监听该事件,服务器会酌情自动发送100
Continue响应。
* 处理该事件时,如果客户端可以继续发送请求主体则调用response.writeContinue, 如果不能则生成合适的HTTP
响应(例如,400 请求无效)
* 需要注意到, 当这个事件触发并且被处理后, request 事件将不再会触发.
* @param {Object} req
* @param {Object} req
*/
server.on('checkContinue',function(req,res){});
/**
* 说明:如果客户端发起connect请求,如果服务器端没有监听,那么于客户端请求的该连接将会被关闭
* @param {Object} req 是该HTTP请求的参数,与request事件中的相同。
* @param {Object} socket 是服务端与客户端之间的网络套接字。需要自己写一个data事件监听数据流
* @param {Object} head 是一个Buffer实例,隧道流的第一个包,该参数可能为空。
*/
server.on('connect',function(req,socket,head){});
/**
* 说明:这个事件主要是对HTTP协议升级为其他协议后的事件监听,如果服务器端没有监听,那么于客户端请求的该连
接将会被关闭
* @param {Object} req 是该HTTP请求的参数,与request事件中的相同。
* @param {Object} socket 是服务端与客户端之间的网络套接字。需要自己写一个data事件监听数据流
* @param {Object} head 是一个Buffer实例,升级后流的第一个包,该参数可能为空。
*/
server.on('upgrade',function(req,socket,head){});
/**
* 说明:如果一个客户端连接触发了一个 'error' 事件, 它就会转发到这里
* @param {Object} exception
* @param {Object} socket
*/
server.on('clientError',function(exception,socket){});
/**
* 源API:server.listen(port, [hostname], [backlog], [callback])
* 说明:监听一个 unix socket, 需要提供一个文件名而不是端口号和主机名。
* @param {Number} port 端口
* @param {String} host 主机
* @param {Number} backlog 等待队列的最大长度,决定于操作系统平台,默认是511
* @param {Function} callback 异步回调函数
*/
//server.listen(3000,'localhost',100,function(){});
/**
* 源API:server.listen(path, [callback])
* 说明:启动一个 UNIX 套接字服务器在所给路径 path 上监听连接。
* 可能用处:多路径或渠道数据来源监听分隔
* @param {String} path
* @param {Function} callback
*/
//server.listen('path',function(){})
/**
* 源API:server.listen(handle, [callback])
* 说明:Windows 不支持监听一个文件描述符。
* @param {Object} handle 变量可以被设置为server 或者 socket
* @param {Function} callback
*/
//server.listen({},function(){});
/**
* 说明:最大请求头数目限制, 默认 1000 个. 如果设置为0, 则代表不做任何限制.
* @type {number}
*/
server.maxHeadersCount = 1000;
/**
* 源API:server.setTimeout(msecs, callback)
* 说明:为套接字设定超时值。如果一个超时发生,那么Server对象上会分发一个'timeout'事件,同时将套接字作为
参数传递。
* 设置为0将阻止之后建立的连接的一切自动超时行为
* @param {Number} msecs
* @param
*/
server.setTimeout(1000,function(){});
/**
* 说明:一个套接字被判断为超时之前的闲置毫秒数。 默认 120000 (2 分钟)
* @type {number}
*/
server.timeout = 120000;
/**
* 说明:这里的主机将是本地
* @param {Number} port 端口
* @param {Function} callback 异步回调函数
*/
server.listen(3000,function(){
console.log('Listen port 3000');
});
var https = require('https');
var zlib = require('zlib');
var post_data="………………";//请求数据
var reqdata = JSON.stringify(post_data);
var options = {
hostname: '10.225.***.***',
port: '8443',
path: '/data/table/list',
method: 'POST',
rejectUnauthorized: false,
requestCert: true,
nodejs 简单http 文件上传
auth: 'admin:123456************',
headers: {
'username': 'admin',
'password': '123456************',
'Cookie': 'locale=zh_CN',
'X-BuildTime': '2015-01-01 20:04:11',
'Autologin': '4',
'Accept-Encoding': 'gzip, deflate',
'X-Timeout': '3600000',
'Content-Type': 'Application/json',
"Content-Length":reqdata.length
}
};
var req = https.request(options, function (res) {
});
req.write(reqdata);
req.on('response', function (response) {
switch (response.headers['content-encoding']) {
case 'gzip':
var body = '';
var gunzip = zlib.createGunzip();
response.pipe(gunzip);
gunzip.on('data', function (data) {
body += data;
});
gunzip.on('end', function () {
var returndatatojson= JSON.parse(body);
req.end();
});
gunzip.on('error', function (e) {
console.log('error' + e.toString());
req.end();
});
break;
case 'deflate':
var output = fs.createWriteStream("d:temp.txt");
response.pipe(zlib.createInflate()).pipe(output);
req.end();
break;
default:req.end();
break;
}
});
req.on('error', function (e) {
console.log(new Error('problem with request: ' + e.message));
req.end();
setTimeout(cb, 10);
});
// 这是一个简单的Node HTTP,能处理当前目录的文件
// 并能实现良种特殊的URL用于测试
// 用http://localhost:8000 或http://127.0.0.1:8000 连接这个服务器
// 首先,加载所有要用的模块
var http = require('http'); // HTTP服务器API
var fs = require('fs'); // 文件系统API
var server = new http.Server(); // 创建新的HTTP服务器
var port = 8000;
server.listen(port); // 在端口8000伤运行它
var log = require('util').log;
log('Http Server is listening ' + port + ' port.');
// Node使用'on'方法注册事件处理程序
// 当服务器收到新请求,则运行函数处理它
server.on('request', function(request, response) {
var filename = null;
// 解析请求的URL
var url = require('url').parse(request.url);
switch(url.pathname) {
case '/upload':
var _fileName = request.headers['file-name'];
log(_fileName);
request.once('data', function(data) {
// 大文件
// var fis = fs.createWriteStream('/txt.txt');
// fis.write(data);
// fis.end();
fs.writeFile(_fileName, data);
response.end();
});
break;
case '/' || '/index.html' :
filename = 'index.html';
default:
filename = filename || url.pathname.substring(1); // 去掉前导'/'
// 基于其扩展名推测内容类型
var type = (function(_type) {
switch(_type) { // 扩展名
case 'html':
case 'htm': return 'text/html; charset=UTF-8';
case 'js': return 'application/javascript; charset=UTF-8';
case 'css': return 'text/css; charset=UTF-8';
case 'txt': return 'text/plain; charset=UTF-8';
case 'manifest': return 'text/cache-manifest; charset=UTF-8';
default: return 'application/octet-stream';
}
}(filename.substring(filename.lastIndexOf('.') + 1)));
// 异步读取文件,并将内容作为单独的数据块传回给回调函数
// 对于确实很大的文件,使用API fs.createReadStream()更好
fs.readFile(filename, function(err, content) {
if (err) { // 如果由于某些原因无法读取文件
response.writeHead(404, {'Content-type' : 'text/plain; charset=UTF-8'});
response.write(err.message);
} else { // 否则读取文件成功
response.writeHead(200, {'Content-type' : type});
response.write(content); // 把文件内容作为响应主体
}
response.end();
});
}
});
2、http.ServerRequest
http.ServerRequest 是 HTTP 请求的信息,是后端开发者最关注的内容。它一般由http.Server 的 request
事件发送,作为第一个参数传递,通常简称 request 或 req。
HTTP 请求一般可以分为两部分:请求头(Request Header)和请求体(Requset Body)。以上内容由于长
度较短都可以在请求头解析完成后立即读取。而请求体可能相对较长,需要一定的时间传输。
http.ServerRequest 提供了以下3个事件用于控制请求体传输。
data :当请求体数据到来时,该事件被触发。该事件提供一个参数 chunk,表示接收到的数据。如果该事件
没有被监听,那么请求体将会被抛弃。该事件可能会被调用多次。
end :当请求体数据传输完成时,该事件被触发,此后将不会再有数据到来。
close: 用户当前请求结束时,该事件被触发。不同于 end,如果用户强制终止了传输,也还是调用close。

