

分布式缓存
一 介绍下出现分布式缓存的背景
现在的程序开发越来越复杂,功能多,拆分为各个微服务板块。然后并发量大,每个服务板块又有配置集群。分布式缓存是为了解决web服务器与数据库服务器之间的瓶颈,如果访问流量大,那么这个瓶颈就越大,数据库的读取压力将会非常大,即使此时数据库已经做了读写分离。那么为了分担数据库的压力,我们需要将数据缓存起来,这是可以在业务层,缓存数据。
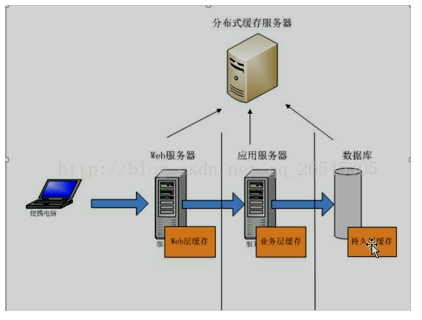
其实在MVC每一个层次都会有缓存系统,
1.web层一般采用静态页面的缓存,比如localstorage(同一浏览器内共享),sessionstorage(同一浏览器不同页面不能共享),cookie还有些前端框架带有的缓存,比如VueX.但是这个有问题,就是数据不安全性
2.业务层采用内存nosql的数据库,比如redis,memcache
3.数据层,一般持久层框架比如hibernate,mybatis都有自己的缓存系统,介绍一下mybatis的缓存,它有一级缓存和二级缓存。
一级缓存是在sqlSession级别的,执行不一样的sql他的缓存不一样。
二级缓存是在命名空间mapper级别的,同一个mapper的缓存是共享的。顺序是写拿一级缓存再拿二级缓存。如果upate或insert的话,缓存都会被清空。
二 .采用redis实现分布式缓存
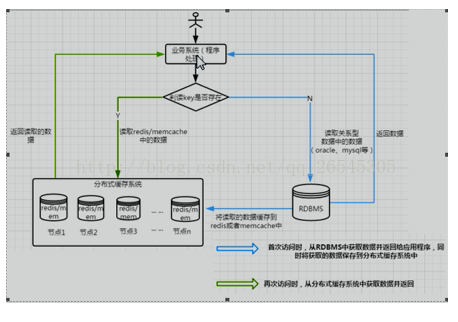
一般缓存都有这么个逻辑
1.查找先查缓存中,有就取出来,没有去差数据库,查到后添加到缓存中
2.添加或修改时,清空对于key的缓存。
大型应用中,单利的redis肯定是不行的。所以会带来redis的集群。
其实redis环境的搭建使用有很多模式
1.分片模式:多个redis节点,采用redis池的模式,将多个redis节点组合起来,根据hash一致性算法hash(key)存储对对应的节点上,缺点是一个节点宕机会影响这个分片系统
2.哨兵模式:有监控和转移系统,如果一个节点宕机,哨兵会进行选举机制,选出另外一台机器作为主机工作。缺点:需要消耗资源部署哨兵系统,哨兵个数一般为奇数
3集群模式:也是多个节点构成一个集群系统,节点之间相互通信,每个节点都有2中节点身份,主节点,从节点。一般配置2主4从,3主6从模式。
主节点负责存储,从节点复制主节点数据,防止主节点宕机后,数据丢失。(数据持久化策略AOF与RDB)
RDB:redis会再一定时间范围内,进行数据备份(将内存数据持久化到磁盘中RDB文件),宕机后从当前节点的rdb文件进行同步。
默认持久化策略
A save 900 1 900秒内发生一次set操作时执行
B save 300 10
C save 60 10000’
优点:定时备份,消耗资源少
缺点:不能保证数据完整性,比如采用B策略,300内进行了8次set,突然宕机了,数据就没有写入磁盘
AOF:appendonly 改为yes 就会采用AOF配置模式
EverySec:每秒备份一次
Always:只要进行set操作就备份
No:30分钟备份一次
集群的节点分配:集群将内存分配为16384个插槽,同样根据hash(key)将数据存储到固定的插槽。
集群内置有类似哨兵的性质,可以实现高可用,监控选举的特点。
三 使用缓存时会遇到很多不同的情况
1.缓存穿透:取数据时,缓存和数据库中都没有数据。
比如当攻击者传入查询参数id为-1,这时缓存中没有数据,去数据库中查找,会对数据造成很大的压力,因为数据中并没有这条数据,但是进行了全局查找
解决方法:业务层进行条件判断,比如 id<=0 直接拦截,拦截不符合逻辑的查询条件
2.缓存击穿:一般查询同一条数据的时候,并发量比较高,缓存中的数据过期了或者没有数据。会加大数据的压力
解决方法:设置热点数据永不过期
查询添加双锁校验机制(有点类似分布式锁的实现过程,但不一样)。这样会牺牲用户的响应时间

3.缓存雪崩:缓存中含有大量过期的数据,与缓存击穿不同的时 这些并不是同一条数据。这样同样会造成数据库的压力大
解决方法:设置热点数据永不过期
不同数据设置不同过期时间,随机时间,防止同一时间出现过期现象
采用分布式缓存数据部署,将不同热点数据部署在不同的节点的缓存数据库中

