

分析《人民的名义》的观众评论及总结
我们都知道 《人民的名义》 这部反腐大戏,湖南卫视不惜花费二亿多人民币买断了它的独播权。《人民的名义》上映不久,引起大家的广泛关注,观看率直线上升,并且好多观众都反映更新的太慢(后面会给出证据),网上都出现了全集审评版的《人民的名义》,引起了诸多的问题。这值得我们思考以下几个问题?
1. 这部戏主要讲的内容是什么,有哪些主要的角色?
2. 这部戏为什么会这么火呢?
3. 观众都有怎样的评论呢?
4. 这些评论观众的地区分布情况?
下面我从数据分析的角度去思考以上几个问题,为此我做了如下2件事:
1. 从书本网上,爬去《人民的名义》这本小说,然后对它做了一些简单的文本分析(上一篇博客)
2. 从豆瓣网上,爬去观众的评论,从评论数据中去发现问题,寻找答案,并启发我们去思考一些社会问题。
一、数据的爬去
我们要分析数据,首先是要获得数据,到今天为止豆瓣上共有十三万多观众参与了评价,相比于国产片目前评分排名第一的《大明王朝》与《走向共和》,与早就上映的评分9.4的1986年版《西游记》来说,《人们的名义》的参与评论观众人数远大于它们。上映不到一个月,这数据是貌似豆瓣上史无前例的,从中我们可以预测在未来的国产剧中,肯定会上映类似的电视剧。


十三万多观众的数据是如何统计的呢, 豆瓣将数据分为三大类:看过(collections),想看(wishes),在看(doings). 每一类数据,豆瓣会随机更新呈现出200条评论,为了抓取这些不重复的数据,我开始保存在.txt文件中,发现每次只能抓取200条观众评论数据,当数据再次更新时再爬去数据时,如果改保存的文件名话,这样会导致两个文件保存的数据可能会重复。为了方便处理与保存这些数据,自己决定把它们保存在MySQL数据库中,通过python爬去数据,每次插入新的数据时,使用“insert ignore into table_name values( )”命令与定义数据库的键,这样只要我每运行一次程序就可以得到最新的数据。分别爬去了每个观众的网址、昵称、地址、评论时间、评论星级,评论内容。如下数据只获取了最近三天的数据,一共有1345条数据,其中由于collections这类观众的数据更新较快,爬去的数据也比较多。

在爬去过程中,发现有些观众没有地址,没有评语,或者没有评论星级,这给爬去数据带来了一些麻烦(主要通过BeautifulSoup,re模块解决), 具体的代码后续给出。

为了关注观众的热门讨论话题,在豆瓣上有一个讨论区,到目前为止已有3100+讨论话题。同样把这些数据保存在MySQL数据库中,分别抓取了每个热门话题的标题、发起者,回应条数,更新时间与话题对应的网址,如下表:

二、数据的处理与分析
1.单变量的分析
首先考虑的是统计评论者的地区分布情况(假定每个评论者的地址正确),直至目前为止共统计了1658条数据,发现有226个城市参加了评论,我们只给出评论数大于3的城市,如下图所示:
 图中“不明地址”表示评论者没有给出自己所在地址,大约有130左右。从图中,我们可以发现大部分评论者主要分布在北京,上海,杭州,深圳,广州,成都,南京。
图中“不明地址”表示评论者没有给出自己所在地址,大约有130左右。从图中,我们可以发现大部分评论者主要分布在北京,上海,杭州,深圳,广州,成都,南京。
我们可以分析一下这数据背后的一些东西,假定评论者越多的城市,说明该城市顾客的参与度越高,商品潜在的需求量就越大,创业成功率就高;所以如果你有一颗创业的心,就多
去这些大城市,万一就实现了呢。 除北上广深外,我们发现杭州、成都,南京的评论观众占比也很大;所在国外的评论者数目排名前四是:纽约,伦敦,旧金山,新加波;从这个角
度是否可以说明这四个城市相对其他海外城市中国人较多呢?
下面我们分析一下观众的评星状况,豆瓣评分系统给出,力推(5五颗星),推荐(4颗星),,,很差(1颗星),未评星,这六种选择。豆瓣是如何处理这些不给评星的数
据? 如何打出最后得分?(条目的评分是将豆瓣成员的评价数据加权平均计算后的结果,通过算法的调校,使得海量用户主观喜好的聚合能够更客观准确地反映条目本身的价值。)
google发现豆瓣如何具体计算评分不仅仅使用的IMDB评分规则,它其实是个很复杂的过程。因此,在这里只给出了最近四天的统计数据,如下图: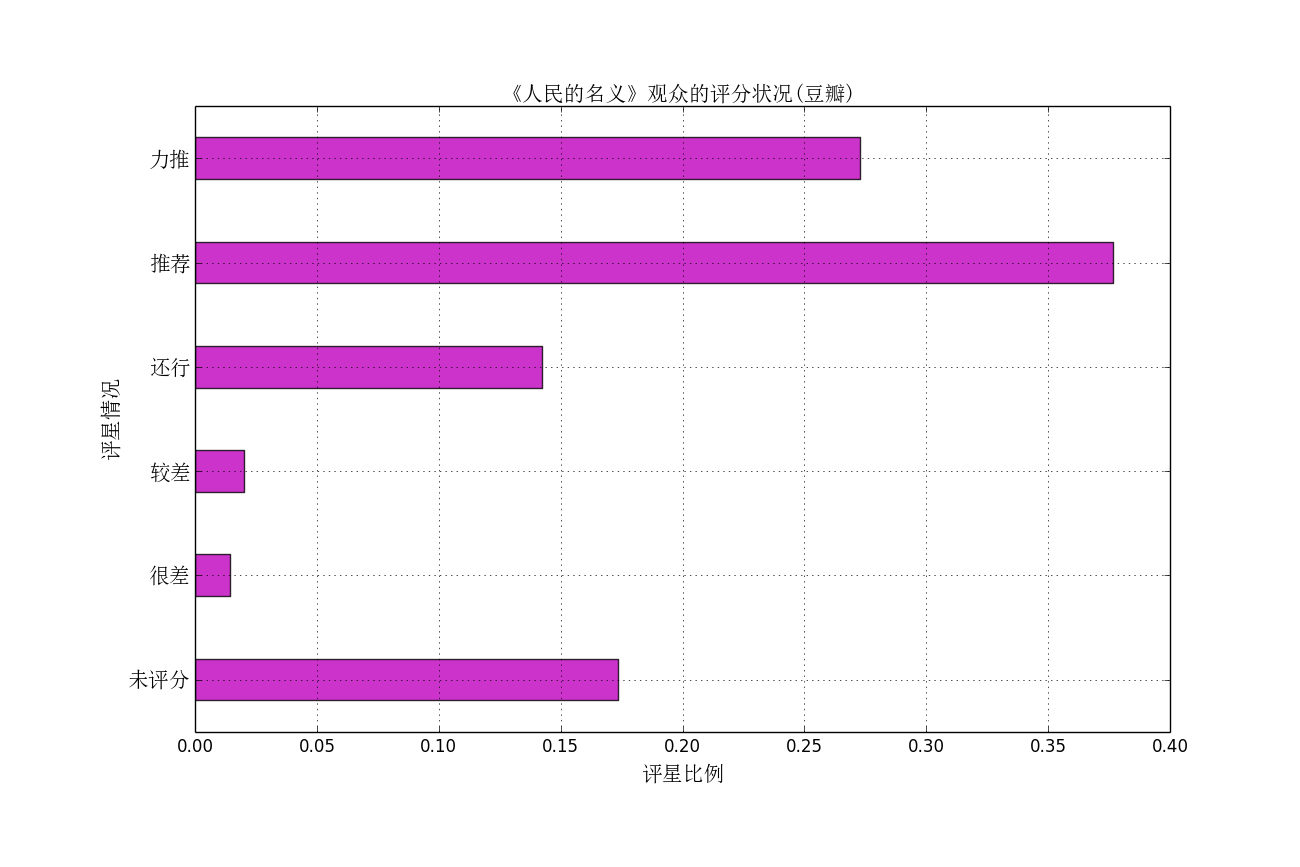
这与豆瓣网上给出的数据有些差别,自己分析主要的原因是:1、统计的数据不全,只统计了最近四天的数据;2、有些观众未评分。
下面我们看看,这些评论观众是如何给出评语的?看如下云词图:


第一幅云词图是已经看过的观众评论语关键字提取,第二幅是正在看的观众评语的关键字。这两幅云词中都有:演技、陆毅、祁同伟,拖沓,老骨戏,李大康等这些显目的词汇。
下面给出一些观众评语:



观众回应数排名前十大热门讨论话题:

其实还有好多东西可以值得我们去分析,由于时间原因,我今天就分享到这里。关于一些爬虫、字体编码等技术问题,下次再给出新的博文说明。欢迎大家查看,谢谢!!

