
必懂知识——HashMap的实现原理
HashMap的底层数据结构
-
1.7之前是:数组+链表
数组的元素是Map.Entiry对象
当出现哈希碰撞的时候,使用链表解决,
先计算出key对应的数组的下标,这个数组的这个位置上为空,直接放入,
如果不为空而且出现哈希碰撞,就把元素添加到链表的头部的,
new Entry(key,value,table[i]);这样这个Entry就是链表的头部了,然后放到数组的index位置上。 -
1.8是:数组+链表+红黑树
数组的元素是Map.Node对象继承Map.Entry包含属性有:
当前node对象的hash值,
当前node对象的key,
当前node对象的下一个节点对象next,
当前node对象的value -
1.8为什么使用数组+链表+红黑树?
因为如果一个hashmap在同一个数组位置上出现hash碰撞过多,那么这个链表的长度会很长,
插入块,但是查询因为使用的遍历所以会比较慢。
HashMap的大致结构
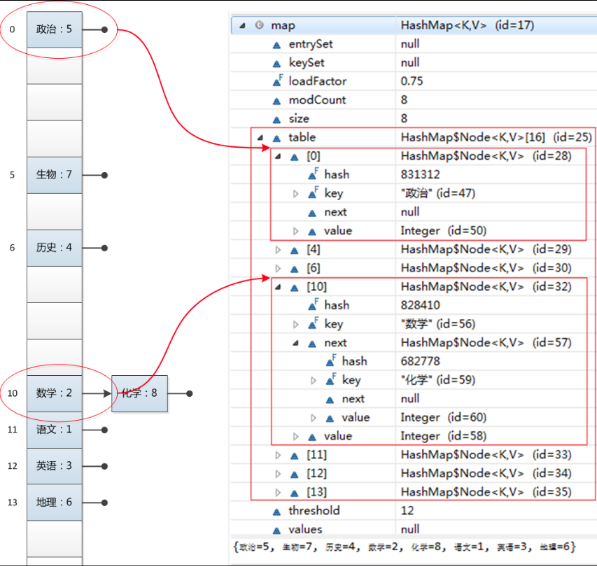
HashMap的关键属性有哪些?
- 数组的默认大小16
- 数组的最大为2的30次方
- 扩容因子0.75
- threshold
- 当前数组的大小
初始大小或者扩容的数组大小为什么一定是2的次幂?
因为计算key的下标的时候使用的是:key的hashcode值 &(按位与) 数组的长度-1 ,
固定为2的次幂能保证碰撞几率小。
怎么通过key计算得到数组的下标的?
key的hashcode值 & 数组的长度-1 ;
& (与运算)
hashMap的大小是怎么计算的?
- 有一个全局变量size,每次put的时候++,remove的时候--;
HashMap中Put方法的工作原理
- 获取key的hashCode()值,计算得到下标(通过位运算)。
- 如果该位置上为空直接放入该数组的下标位置。
- 如果不为空出现了碰撞,利用key的equal()方法判断是否相同,如果相同就覆盖,不相同就放到链表的尾部。
- 如果碰撞导致链表过长,长度大于等于8,就把链表转换成红黑树;
- 如果数组的容量超过了总容量*负载因子的值,就要resize。
HashMap中Get方法的工作原理
bucket里的第一个节点,直接命中;
如果有冲突,则通过key.equals(k)去查找对应的entry
若为树,则在树中通过key.equals(k)查找,O(logn);
若为链表,则在链表中通过key.equals(k)查找,O(n)。
什么是哈希冲突?
哈希表在新增元素的时候首先会根据hash函数算出这个元素存放的数组的位置,
但是,有可能存在不同的key值得到相同的数组位置(两个元素的HashCode值相同),这个时候就是哈希冲突。
HashMap怎么处理哈希冲突(哈希碰撞的)
动态数组+链表(单向)的方式。

如果某个位置上的链表很长,会影响检索,JDK1.8引入了当链表的长度大于8的时候会将链表动态替换为一个红黑树,增加了搜索性能。
等于说由:数组+链表

变成了数组+链表+红黑树
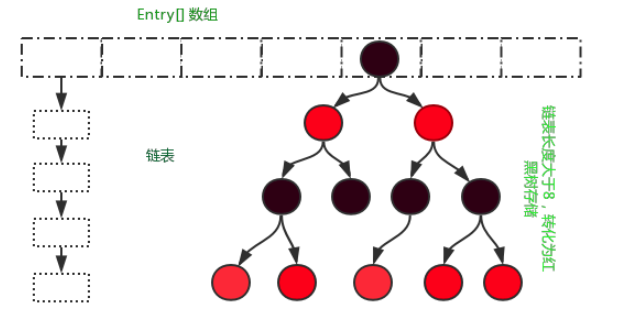
HashMap中的数组什么时候扩容(rehash)
当HashMapde的长度超出了负载因子与当前容量的乘积(默认16*0.75=12)时,
通过调用resize方法重新创建一个原来HashMap大小的2倍的newTable数组,
并将原先table的元素全部移到newTable里面,重新计算hash,然后再重新根据hash分配位置,,最大扩容为2的30次方+1。
负载因子默认是:0.75

你了解重新调整HashMap大小存在什么问题吗
多线程环境下,有可能多个线程同时进行resize,在这过程中,可能产生死锁或者死循环。
具体原因不清楚。
多线程下的HashMap
HashMap是线程不安全的,所以在多线程的环境中我们需要寻找替代方案:
- 使用Map m = Collections.synchronizedMap(new HashMap(...));实现同步
- 使用java.util.HashTable,效率最低(因为所有的方法都是同步的,几乎被淘汰了)
- 使用java.util.concurrent.ConcurrentHashMap,相对安全,效率高(建议使用)
Fail-Fast 机制
Fail-fast 机制是 java 集合(Collection)中的一种错误机制,
java.util.HashMap 不是线程安全的,如果在使用迭代器的过程中有其他线程修改了 map,
那么将抛出 ConcurrentModificationException,这就是所谓 fail-fast 策略
这一策略在源码中的实现是通过 modCount 也就是修改次数实现的。
与之关联的面试题:
遇到过ConcurrentModficationException(并发修改异常)异常吗?为什么会出现?如何解决?
HashMap和Hashtable的区别
- 主要区别:Hashtable是线程安全,而HashMap则非线程安全。
- HashMap可以使用null作为key,而Hashtable则不允许null作为key
- HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的
就是当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException - 由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢

