
【SqlServer系列】聚合函数
1 概述
本篇文章简要回顾SQL Server 聚合函数,MAX,MIN,SUM,AVG,SUM,CHECKSUM_EGG,COUNT,STDEV,STDEVP,VAR,VARP。
2 具体内容
2.1 AVG (Transact-SQL)
返回组中值的平均值。空值被忽略。
2.1.1 定义
1 AVG ( [ ALL | DISTINCT ] expression )
2 OVER ( [ partition_by_clause ] order_by_clause )
2.1.2 参数
ALL
将聚合函数应用于所有值。ALL是默认值。
DISTINCT
指定仅对值的每个唯一实例执行AVG,而不管该值发生多少次。
表达式
是位数据类型除外的精确数字或近似数值数据类型类别的表达式。不允许使用聚合函数和子查询。
OVER ( [ partition_by_clause ] order_by_clause )
partition_by_clause将FROM子句生成的结果集划分为应用该函数的分区。如果未指定,则该函数将查询结果集的所有行视为单个组。order_by_clause确定执行操作的逻辑顺序。order_by_clause是必需的。
2.1.3 返回类型
返回类型由表达式的评估结果的类型决定。

2.1.4 小结
a.If the data type of expression is an alias data type, the return type is also of the alias data type. However, if the base data type of the alias data type is promoted, for example from tinyint to int, the return value is of the promoted data type and not the alias data type.
译文:如果表达式的数据类型是别名数据类型,则返回类型也是别名数据类型。但是,如果别名数据类型的基本数据类型被提升,例如从tinyint到int,则返回值是升级数据类型,而不是别名数据类型。
b.AVG () computes the average of a set of values by dividing the sum of those values by the count of nonnull values. If the sum exceeds the maximum value for the data type of the return value an error will be returned.
译文:AVG()通过将这些值的总和除以非空值的计数来计算一组值的平均值。如果sum超过返回值的数据类型的最大值,则返回错误。
c.AVG is a deterministic function when used without the OVER and ORDER BY clauses. It is nondeterministic when specified with the OVER and ORDER BY clauses. For more information, see Deterministic and Nondeterministic Functions.
译文:当没有OVER和ORDER BY子句时,AVG是一个确定性函数。当用OVER和ORDER BY子句指定时,它是非确定性的。有关更多信息,请参阅确定性和非确定性函数。
2.2 CHECKSUM_EGG
返回组中值的校验和。空值被忽略。可以跟随OVER子句。
2.2.1 定义
1 CHECKSUM_AGG ( [ ALL | DISTINCT ] expression )
参数
ALL
将聚合函数应用于所有值。ALL是默认值。
DISTINCT
指定CHECKSUM_AGG返回唯一值的校验和。
expression
是一个整数表达式。不允许使用聚合函数和子查询。
返回类型
将所有表达式值的校验和返回为int。
2.2.2 小结
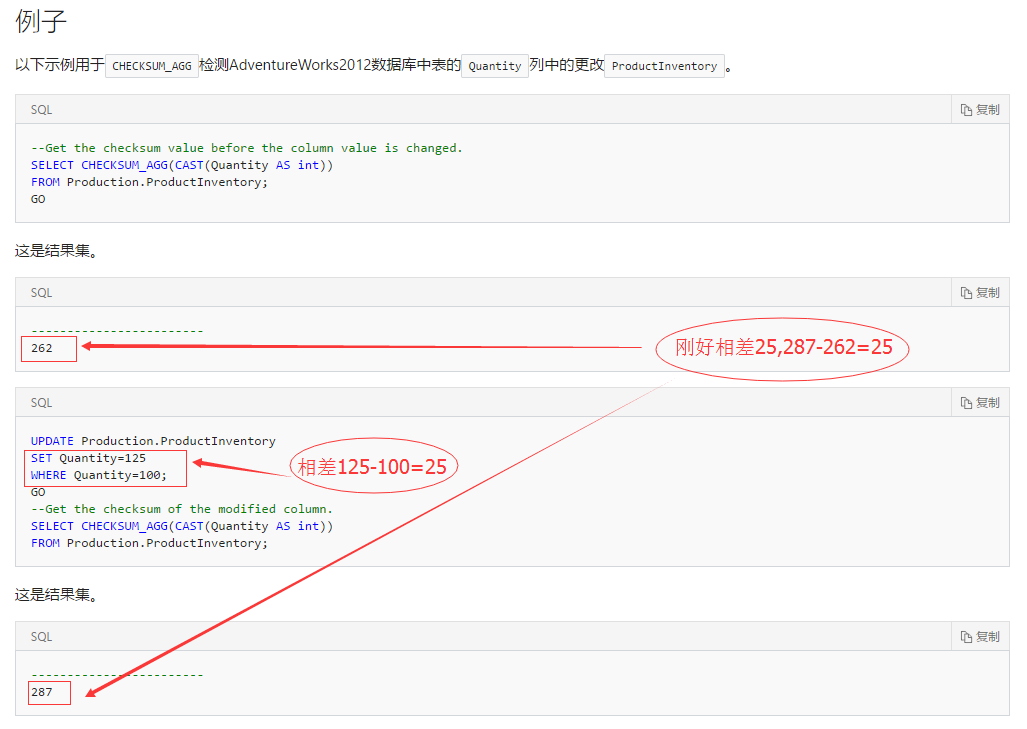
a.CHECKSUM_AGG可用于检测表中的更改。
b.表中行的顺序不影响CHECKSUM_AGG的结果。此外,CHECKSUM_AGG函数可以与DISTINCT关键字和GROUP BY子句一起使用。
b.如果表达式列表中的其中一个值更改,则列表的校验和也通常会更改。但是,校验和几乎不会改变。
d.CHECKSUM_AGG具有与其他聚合函数类似的功能。有关更多信息,请参阅聚合函数(Transact-SQL)。
2.2.3 例子
2.3 COUNT
返回组中的项目数。COUNT的作用类似于COUNT_BIG的功能。两个函数之间的唯一区别是它们的返回值。COUNT始终返回一个int数据类型值。COUNT_BIG总是返回一个bigint数据类型的值。
2.3.1 定义
1 -- Syntax for SQL Server and Azure SQL Database
2
3 COUNT ( { [ [ ALL | DISTINCT ] expression ] | * } )
4 [ OVER (
5 [ partition_by_clause ]
6 [ order_by_clause ]
7 [ ROW_or_RANGE_clause ]
8 ) ]
参数
ALL
将聚合函数应用于所有值。ALL是默认值。
DISTINCT
指定COUNT返回唯一非空值的数量。
expression
是除text,image或ntext之外的任何类型的表达式。不允许使用聚合函数和子查询。
*
指定应计算所有行以返回表中的总行数。COUNT(*)不带参数,不能与DISTINCT一起使用。COUNT(*)不需要表达式参数,因为根据定义,它不使用有关任何特定列的信息。COUNT(*)返回指定表中的行数,而不会摆脱重复。它分别计算每一行。这包括包含空值的行。
OVER ( [ partition_by_clause ] [ order_by_clause ] [ ROW_or_RANGE_clause ] )
partition_by_clause将FROM子句生成的结果集划分为应用该函数的分区。如果未指定,则该函数将查询结果集的所有行视为单个组。order_by_clause确定执行操作的逻辑顺序。有关更多信息,请参阅OVER子句(Transact-SQL)。
返回类型
INT
2.3.2 小结
COUNT(*)返回组中的项目数。这包括NULL值和重复。
COUNT(ALL 表达式)计算组中每一行的表达式,并返回非空值的数量。
COUNT(DISTINCT 表达式)计算组中每一行的表达式,并返回唯一的非空值。
对于大于2 ^ 31-1的返回值,COUNT会产生错误。改用COUNT_BIG。
在没有OVER和ORDER BY子句的情况下使用COUNT是一个确定性函数。当用OVER和ORDER BY子句指定时,它是非确定性的。有关更多信息,请参阅确定性和非确定性函数。
2.4 COUNT_BIGG
返回组中的项目数。COUNT_BIG的作用类似于COUNT功能。两个函数之间的唯一区别是它们的返回值。COUNT_BIG总是返回一个bigint数据类型的值。COUNT始终返回一个int数据类型值。
2.5 GROUPING
指示GROUP BY列表中指定的列表达式是否聚合。GROUPING返回1为聚合,0为未聚合的结果集。在指定GROUP BY时,GROUPING只能在SELECT <select>列表,HAVING和ORDER BY子句中使用。
2.5.1 定义
1 GROUPING ( <column_expression> )
参数
<column_expression>
是包含GROUP BY子句中的列的列或表达式。
返回类型
TINYINT
2.5.2 小结
GROUPING用于区分ROLLUP,CUBE或GROUPING SETS从标准空值返回的空值。作为ROLLUP,CUBE或GROUPING SETS操作的结果返回的NULL是NULL的特殊用途。这作为结果集中的列占位符,意味着全部。
2.6 GROUPING_ID
是计算分组级别的函数。当指定GROUP BY时,GROUPING_ID只能在SELECT <select>列表,HAVING或ORDER BY子句中使用。
2.6.1 定义
GROUPING_ID ( <column_expression>[ ,...n ] )
参数
<column_expression>
是一个column_expression在GROUP BY子句。
返回类型
INT
2.6.2 小结
GROUPING_ID <column_expression>必须与GROUP BY列表中的表达式完全匹配。例如,如果您按DATEPART(yyyy,< column name >)进行分组,请使用GROUPING_ID(DATEPART(yyyy,< column name >)); 或者如果您使用< column name > 进行分组,请使用GROUPING_ID(< column name >)。
2.7 MAX
2.7.1 定义
1 -- Syntax for SQL Server and Azure SQL Database
2
3 MAX ( [ ALL | DISTINCT ] expression )
4 OVER ( [ partition_by_clause ] order_by_clause )
参数
ALL
将聚合函数应用于所有值。ALL是默认值。
DISTINCT
指定每个唯一值被考虑。DISTINCT对MAX无效,仅适用于ISO兼容性。
表达式
是常量,列名称或函数,以及算术,按位和字符串运算符的任意组合。MAX可以与数字,字符,唯一标识符和datetime列一起使用,但不能与位列一起使用。不允许使用聚合函数和子查询。
有关更多信息,请参阅表达式(Transact-SQL)。
OVER ( [ partition_by_clause ] order_by_clause )
partition_by_clause将FROM子句生成的结果集划分为应用该函数的分区。如果未指定,则该函数将查询结果集的所有行视为单个组。order_by_clause确定执行操作的逻辑顺序。order_by_clause是必需的。有关更多信息,请参阅OVER子句(Transact-SQL)。
返回类型
返回与表达式相同的值。
2.7.2 小结
MAX忽略任何空值。
对于字符列,MAX找到整理顺序中的最高值。
使用时,MAX不是OVER和ORDER BY子句的确定性函数。当用OVER和ORDER BY子句指定时,它是非确定性的。有关更多信息,请参阅确定性和非确定性函数。
2.8 MIN
返回表达式中的最小值。可能之后是OVER子句。
2.8.1定义:
1 -- Syntax for SQL Server and Azure SQL Database
2
3 MIN ( [ ALL | DISTINCT ] expression )
4 OVER ( [ partition_by_clause ] order_by_clause )
参数
ALL
将聚合函数应用于所有值。ALL是默认值。
DISTINCT
指定每个唯一值被考虑。DISTINCT对MIN无效,仅适用于ISO兼容性。
表达式
是常量,列名称或函数,以及算术,按位和字符串运算符的任意组合。MIN可以与numeric,char,varchar,uniqueidentifier或datetime列一起使用,但不能与位列一起使用。不允许使用聚合函数和子查询。
有关更多信息,请参阅表达式(Transact-SQL)。
OVER ( [ partition_by_clause ] order_by_clause )
partition_by_clause将FROM子句生成的结果集划分为应用该函数的分区。如果未指定,则该函数将查询结果集的所有行视为单个组。order_by_clause确定执行操作的逻辑顺序。order_by_clause是必需的。有关更多信息,请参阅OVER子句(Transact-SQL)。
返回类型
返回与表达式相同的值。
2.8.2 小结
MIN忽略任何空值。
使用字符数据列,MIN找到排序顺序中最低的值。
在不使用OVER和ORDER BY子句的情况下,MIN是一个确定性函数。当用OVER和ORDER BY子句指定时,它是非确定性的。有关更多信息,请参阅确定性和非确定性函数。
2.9 STDEV
返回指定表达式中所有值的统计标准偏差。
2.9.1 定义
1 -- Syntax for SQL Server and Azure SQL Database
2
3 STDEV ( [ ALL | DISTINCT ] expression )
4 OVER ( [ partition_by_clause ] order_by_clause )
参数
ALL
将该功能应用于所有值。ALL是默认值。
DISTINCT
指定每个唯一值被考虑。
expression
是一个数字表达式。不允许使用聚合函数和子查询。表达式是精确的数字或近似数字数据类型类别的表达式,除了位数据类型。
OVER ( [ partition_by_clause ] order_by_clause )
partition_by_clause将FROM子句生成的结果集划分为应用该函数的分区。如果未指定,则该函数将查询结果集的所有行视为单个组。order_by_clause确定执行操作的逻辑顺序。order_by_clause是必需的。有关更多信息,请参阅OVER子句(Transact-SQL)。
返回类型
浮点
2.9.2 小结
如果STDEV用于SELECT语句中的所有项目,则结果集中的每个值都包含在计算中。STDEV只能用于数字列。空值被忽略。
当没有OVER和ORDER BY子句时,STDEV是一个确定性函数。当用OVER和ORDER BY子句指定时,它是非确定性的。有关更多信息,请参阅确定性和非确定性函数。
2.10 STDEP
返回指定表达式中所有值的总体统计标准偏差。
2.11 SUM
求和
2.12 VAR
返回指定表达式中所有值的统计方差。可能之后是OVER子句。
2.13 VARP
返回指定表达式中所有值的总体统计方差。
3 参考文献
【01】https://msdn.microsoft.com/zh-cn/library
【02】https://docs.microsoft.com/zh-cn/sql/t-sql/functions/functions
4 版权
- 感谢您的阅读,若有不足之处,欢迎指教,共同学习、共同进步。
- 博主网址:http://www.cnblogs.com/wangjiming/。
- 极少部分文章利用读书、参考、引用、抄袭、复制和粘贴等多种方式整合而成的,大部分为原创。
- 如您喜欢,麻烦推荐一下;如您有新想法,欢迎提出,邮箱:2016177728@qq.com。
- 可以转载该博客,但必须著名博客来源。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号