

SVM学习——核函数
还记得上篇末提到的对于优化问题:
的求解需要计算这个内积,而如果输入样本线性不可分的话,我们采取的方法是通过
函数映射将输入样本映射到另外一个高维空间并使其线性可分。
以库克定律为例(http://zh.wikipedia.org/zh-cn/%E9%9D%99%E7%94%B5%E5%8A%9B):
一个电量为 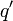 的点电荷作用于另一个电量为
的点电荷作用于另一个电量为 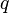 的点电荷,其静电力
的点电荷,其静电力  的大小,可以用方程表达为:
的大小,可以用方程表达为:
 ,其中,
,其中, 是两个点电荷之间的距离,
是两个点电荷之间的距离,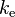 是库仑常数。
是库仑常数。
显然这个定律无法用线性学习器来表达,看到乘积想到ln函数,对原始形式两边取ln,得到:
,令
,
,
,
,
,那么就得到一个线性学习器:
这个过程可以用下图说明:

这样就将内积就变成了
。
求可以有两种方法:
1、先找到这种映射,然后将输入空间中的样本映射到新的空间中,最后在新空间中去求内积;
2、或者是找到某种方法,它不需要显式的将输入空间中的样本映射到新的空间中而能够在输入空间中直接计算出内积。
先看第一种方法,以多项式 为例,对其进行变换,
,
,
,
,得到:
,也就是说通过把输入空间从二维向四维映射后,样本由线性不可分变成了线性可分,但是这种转化带来的直接问题是维度变高了,这意味着,首先可能导致后续计算变复杂,其次可能出现维度之咒,对于学习器而言就是:特征空间维数可能最终无法计算,而它的泛化能力(学习器对训练样本以外数据的适应性)会随着维度的增长而大大降低,这也违反了“奥坎姆的剃刀”,最终可能会使得内积
无法求出,于是也就失去了这种转化的优势了;
再看第二种方法,它其实是对输入空间向高维空间的一种隐式映射,它不需要显式的给出那个映射,在输入空间就可以计算,这就是传说中的核函数方法:
定义1:核是一个函数,对于所有的
满足,
,这里的
为从
到内积特征空间
的映射。
于是输入空间的标准内积就被推广了。
什么时候才是核函数呢?
假设有输入空间且
为对称函数,那么对于所有样本得到下面矩阵:
,显然,这个是个对称矩阵,那么对于对称矩阵一定存在一个正交矩阵,使得
,这里
是包含k的特征值
的对角矩阵,特征值
对应的特征向量为
,其中n为样本数,对输入空间做如下映射
:
于是有,(其中
为特征向量组成的矩阵,
为相应特征值组成的三角矩阵),也就是说K是对应于映射
的核函数。
例子:有,由
解得特征值:
,
,对2重特征根4求
的基础解系、正交化、单位化后得到特征向量:
和
,对
的特征向量单位化后得到
,于是有
,满足
,对所有输入样本做映射得:
;
;
。
随便选两个做内积,如。
由此可见:就是对应于特征映射
的核函数,也就得到下面的结论:
定理1:存在有限输入空间,
为
上的对称函数,那么
是核函数的充要条件是矩阵
半正定,此时相当于对输入空间向特征空间进行了隐式的
映射。对于上面的映射
,令
,于是
,进而
。
定理3:设是
的一个紧子集(闭合且有界子集),
为
上的对称函数,如果它在希尔伯特空间上的积分算子
满足:
这里指的是由满足条件
的所有函数
组成的空间。
在上扩展
到一个一致收敛的序列,该序列由
的特征函数
构成,归一化使得
,且所有特征值
,则核函数
可以被特征分解为:
在核方法中有一个相当重要的、不得不说的概念(先打个标记):
定义2:设是希尔伯特函数空间,其元素是某个抽象集合
上的实值或复值函数,如果对于任何
,
作为
的函数都是
中的元素,而且对于任何
及
取内积有:
则称为为再生核希尔伯特空间(Reproducing Kernel Hilbert Space,RKHS);称
为再生核空间
的再生核(简称RK)。
定理4:对于定义在域上的每一个
核
,存在一个定义在
上的函数的再生希尔伯特空间
,其中
是再生核。反过来,对于线性有界函数的任意希尔伯特空间,存在再生核这个命题也成立。
当然也可以利用核函数来构造核函数,有时候这种构造会很有效的解决问题:
条件:设、
是
上的核,
,
是
上的实值函数,
,
是
上的核,
是一个对称半正定矩阵,则下面的函数都是核:
1、;
2、;
3、;
4、;
5、;
6、。
核的选择对于支持向量机至关重要,选定核后,原问题就变成了:
这个优化问题有最优解么?记得核要满足Mercer条件,即矩阵在所有训练集上半正定,这说明这个优化是凸优化,于是这个条件保证了最大化间隔优化问题有唯一解,简直是天作之合啊,配合的天衣无缝;最后求的
和
,那么从输入空间向特征空间隐式映射后得到的最大间隔超平面也就出来了:
,且有几何间隔
。
常用核函数总结如下:
线性核函数:
多项式核函数:
高斯核函数:
核函数:
下面这个链接收集了若干核函数:
http://www.shamoxia.com/html/y2010/2292.html
关于核方法的理论部分涉及到泛函分析、微积分等等,水比较深,我推荐一本书:《Kernel Methods for Pattern Analysis》(模式分析的核方法),作者是:John Shawe-Taylor和Nello Cristianini 。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号