

在网上上看到一篇文章,用到sphinx的分布式特性来提高搜索性能,就做了个简单的测试。
1. sphinx配置.
配置加粗部分是核心,让sphinx支持分布式。
source multi1 { type = mysql sql_host = 127.0.0.1 sql_user = root sql_pass = passwd sql_db = cs sql_port = 3306 sql_query = select id,title,content from fts_index where id%2=0
sql_ranged_throttle = 0 } source multi2{ type = mysql sql_host = 127.0.0.1 sql_user = root sql_pass = passwd sql_db = cs sql_port = 3306 sql_query = select id,title,content from fts_index where id%2=1
sql_ranged_throttle = 0 } index multi1{ source = multi1 path = /usr/local/coreseek/var/data/multi1} index multi2{ source = multi2 path = /usr/local/coreseek/var/data/multi2} index search { type = distributed local = multi1 local = multi2
}
没有分布式的配置,这个么什么好说的
source main
{
type = mysql
sql_host = 127.0.0.1
sql_user = root
sql_pass = passwd
sql_db = cs
sql_port = 3306
sql_query = select id,title,content from fts_index sql_ranged_throttle = 0
}
index search{
source = main
path = /usr/local/coreseek/var/data/search
}
2. 测试数据(fts_index表里的数据是96664)
3. 创建索引。multi1和multi2分别索引了48332条记录,文档大小79.3+78.7=158m

一次创建所有的96664,总大小158m
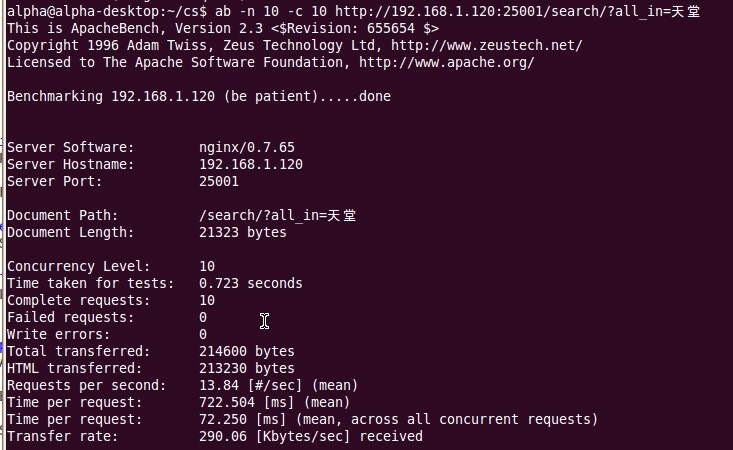
3. 开启searchd服务,基于之前的应用,用ab做压力测试(ab -n 10 -c 10 http://192.168.1.120:8000/search/?all_in=天堂)。rps是13.84。而在这期间,我机器上2颗cpu的都标得很高。可见,确实用多核。(在客户端做查询的时候需要设置索引client.AddQuery(q,index),这里index为search)
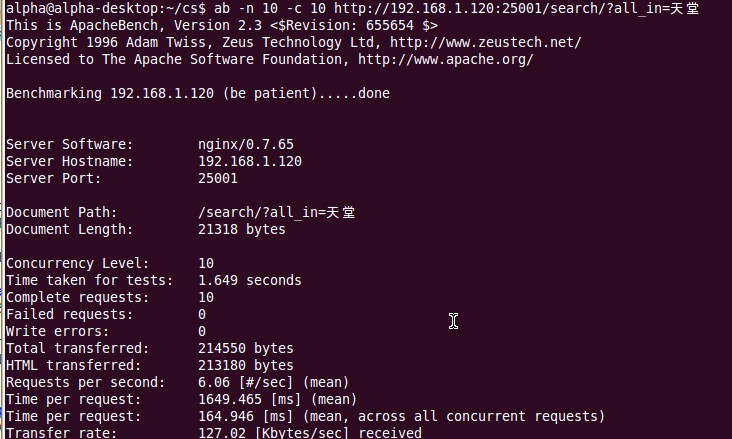
单个index,rps6.06。在测试过程中,确实只有一颗cpu到过99%,另外一颗很稳定。
测试结果很明显,利用了sphinx的分布式特性的完胜。整个过程内存变化不是太多,而cpu一般都能到99%。

