环境篇:Zeppelin
环境篇:Zeppelin
Zeppelin 是什么
Apache Zeppelin 是一个让交互式数据分析变得可行的基于网页的开源框架。Zeppelin提供了数据分析、数据可视化等功能。
Zeppelin 是一个提供交互数据分析且基于Web的笔记本。方便你做出可数据驱动的、可交互且可协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等等。



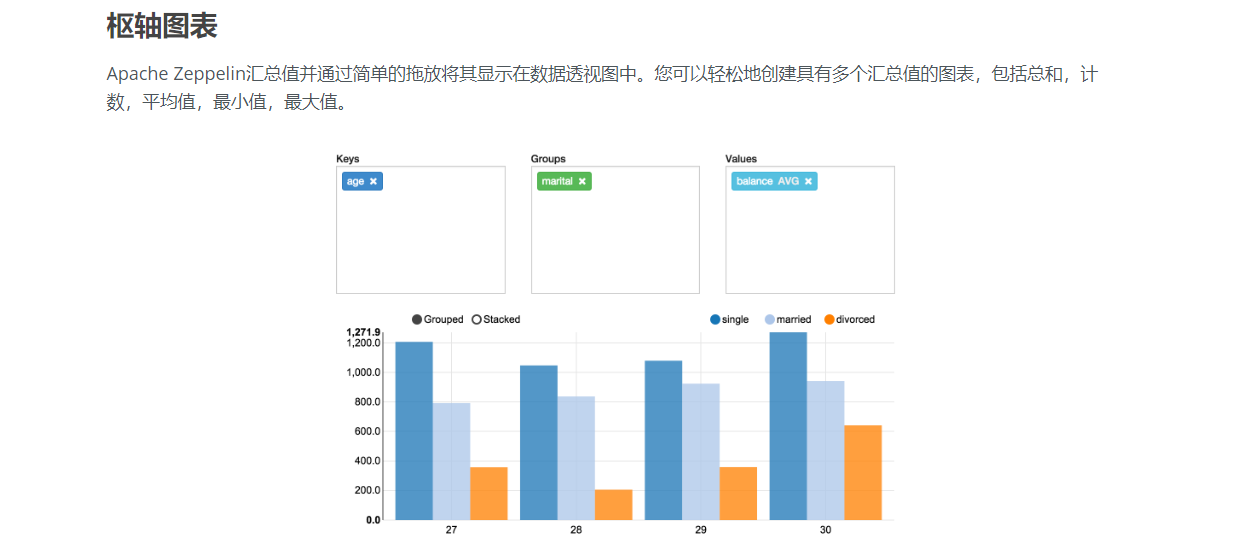
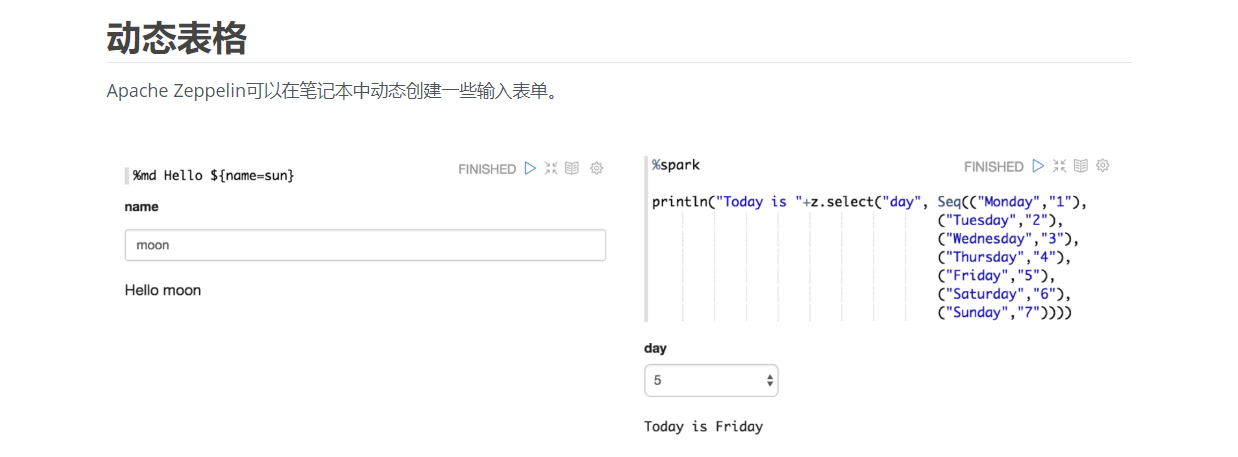
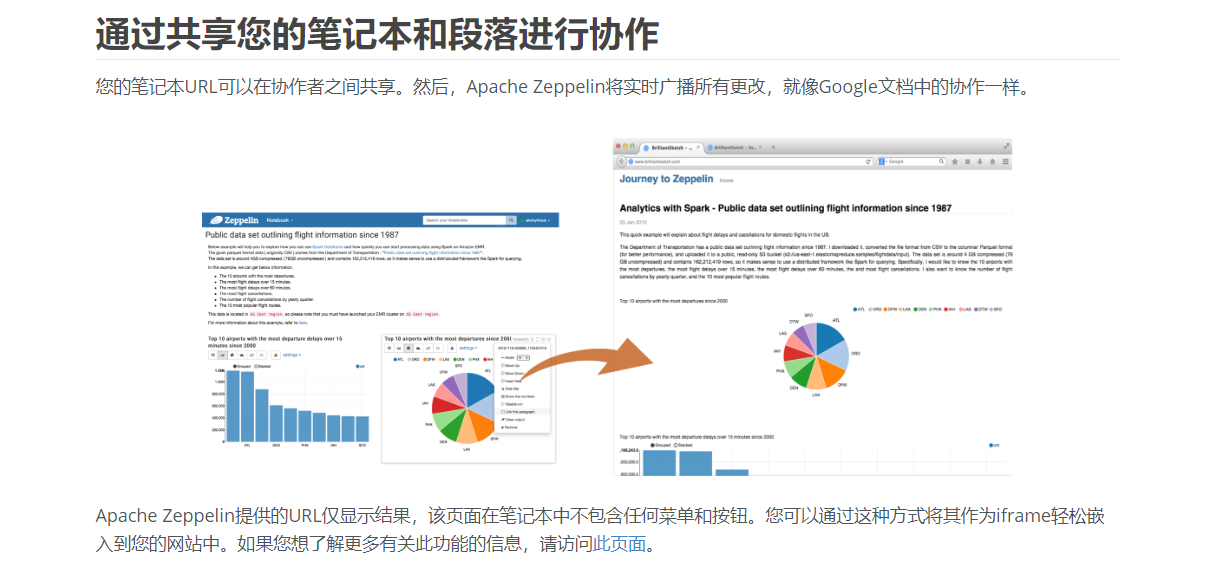
如果没有Zeppelin?
数据分析师在数仓中提取数据时,需要自行整理sql,并且不能以图形展示,而且记录需要自己保存,对于常用的一些操作,每天需要去整理一些笔记,做很多繁杂的工作,包括开发工程师在定位问题后也很难将定位过程记录下来,而且在协同工作上需要借助通讯工具传来传去。这个时候就有了Zeppelin,其实就是一个超级笔记本啦。
1 安装
1.1 下载
zeppelin-0.8.2-bin-all
1.2 上传服务器
mkdir /usr/local/src/zeppelin
cd /usr/local/src/zeppelin

1.3 安装
tar -zxvf zeppelin-0.8.2-bin-all.tgz
#修改配置文件
cd zeppelin-0.8.2-bin-all/conf
cp zeppelin-env.sh.template zeppelin-env.sh
vim zeppelin-env.sh
#--->
#修改javahome
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
#修改IP端口
export ZEPPELIN_ADDR=192.168.192.10
export ZEPPELIN_PORT=8080
#修改SPARK_HOME(如果使用本地模式即可不配置)
export MASTER=spark://cdh01.cm:7077
export SPARK_HOME=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark
#修改HBASE_HOME
export HBASE_HOME=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hbase
export HBASE_CONF_DIR=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hbase/conf
#---<
1.4 启动停止
/usr/local/src/zeppelin/zeppelin-0.8.2-bin-all/bin/zeppelin-daemon.sh start
# /usr/local/src/zeppelin/zeppelin-0.8.2-bin-all/bin/zeppelin-daemon.sh stop
1.5 访问IP:8080端口
2 简单使用
2.1 对接解释器,以hive为例

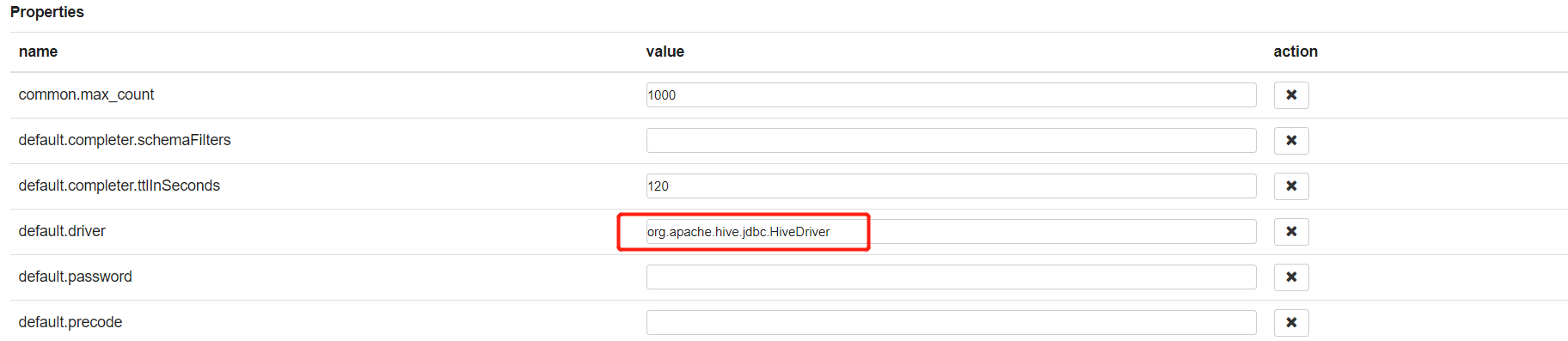
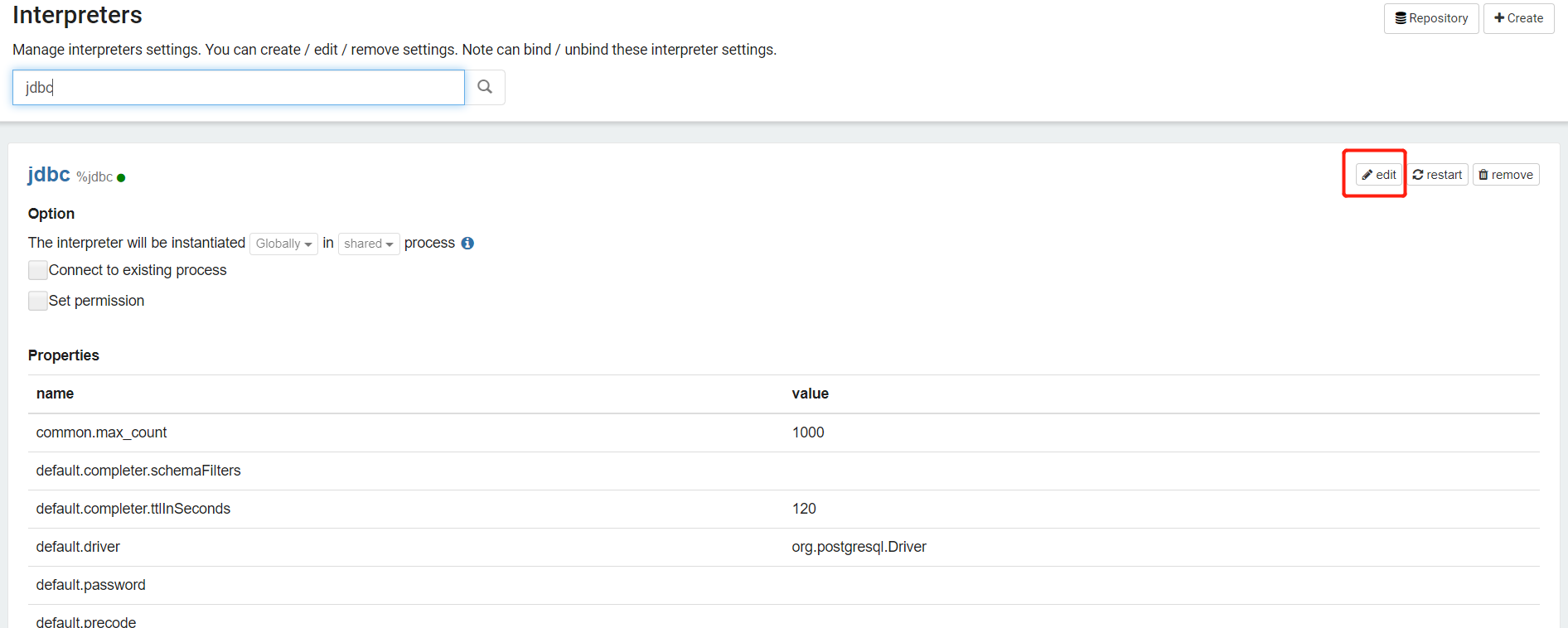

/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/lib/hive-jdbc.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/lib/hive-service-rpc.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/lib/hive-cli.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/lib/hive-service.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/lib/hive-common.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/lib/hive-serde.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/lib/guava-14.0.1.jar
- 使用
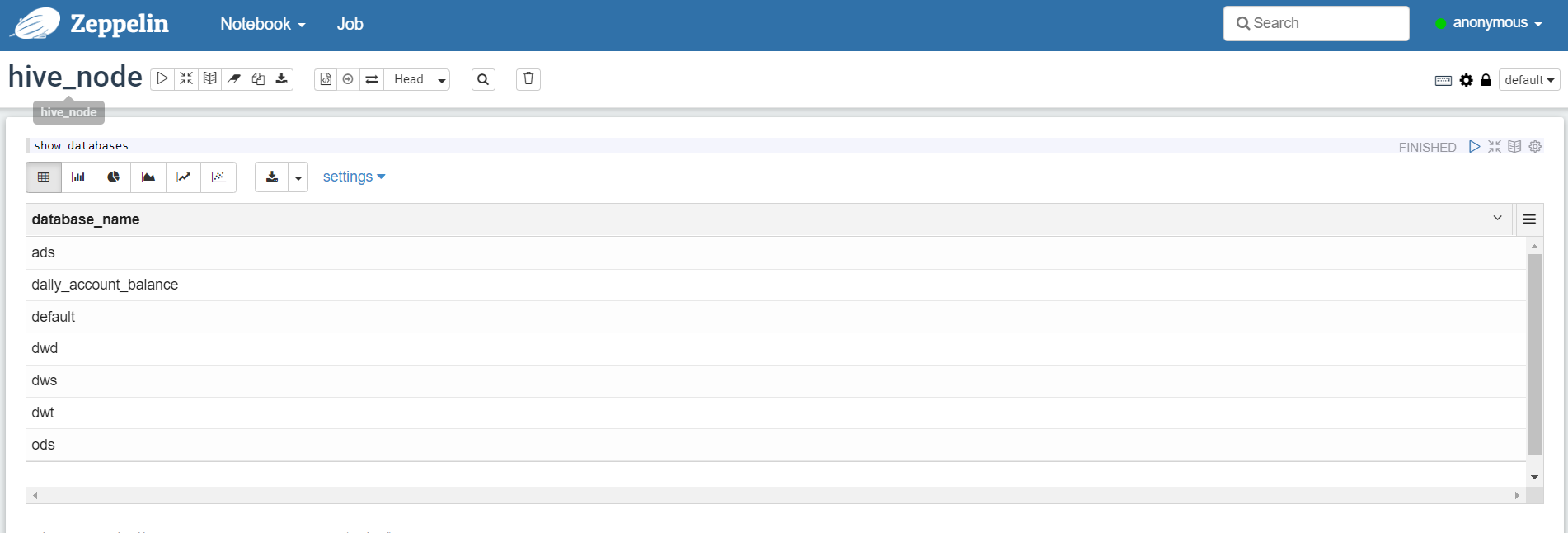
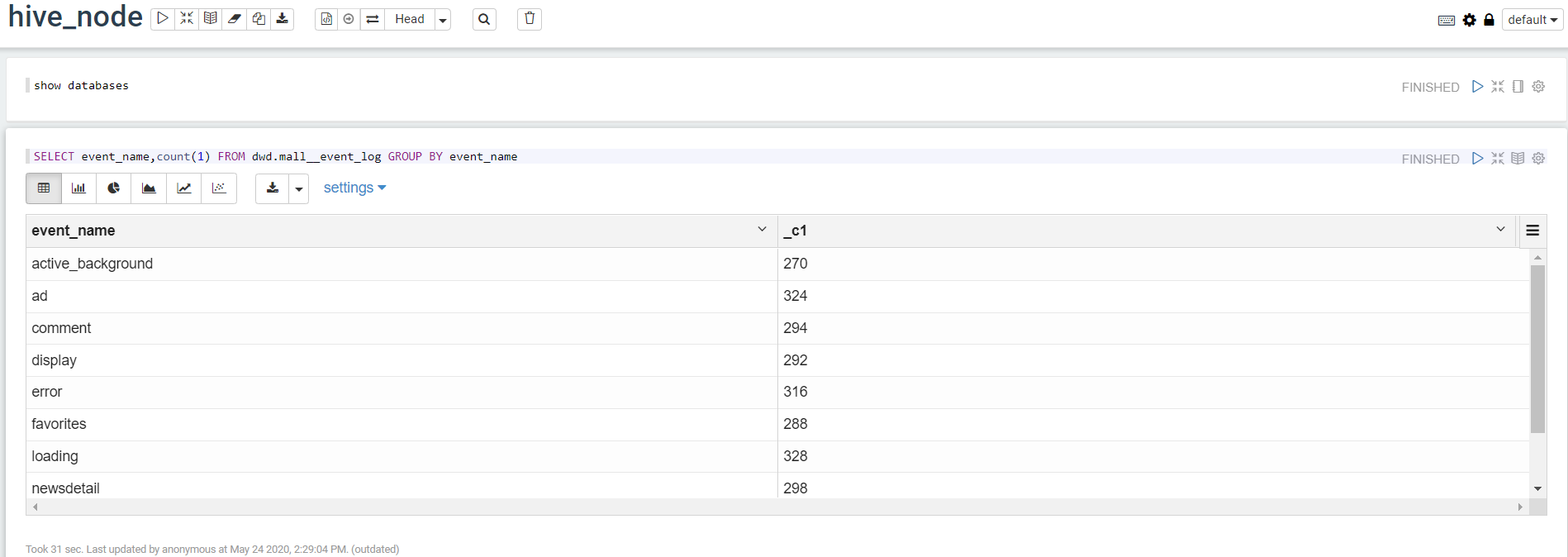
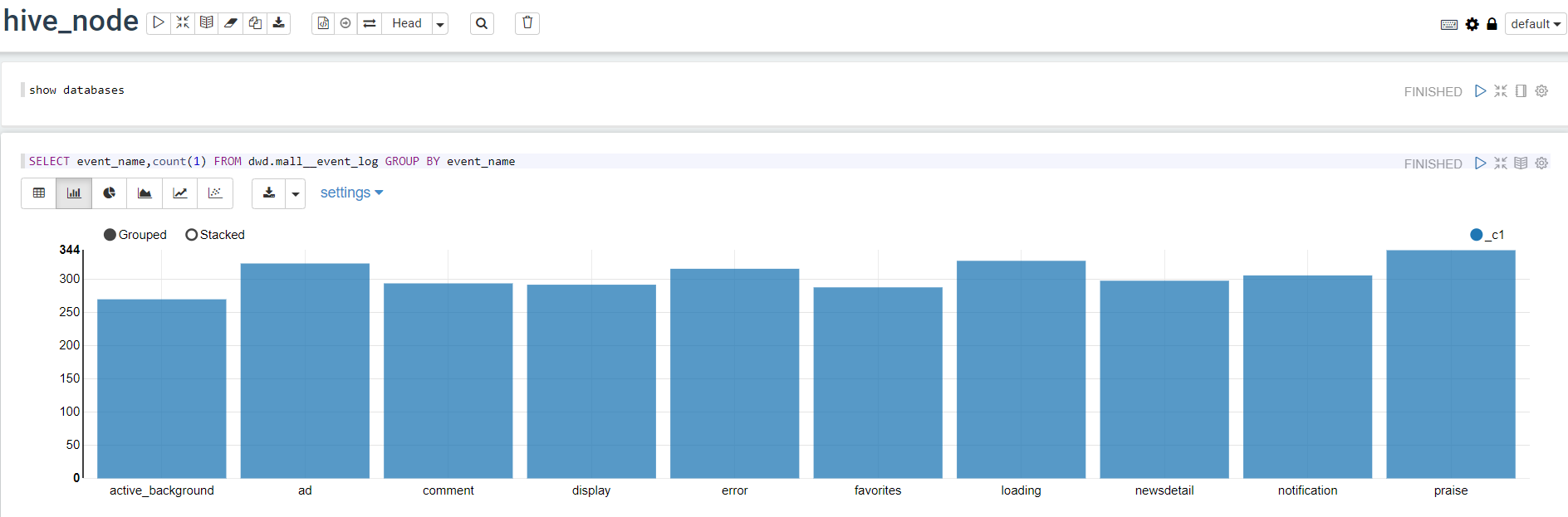
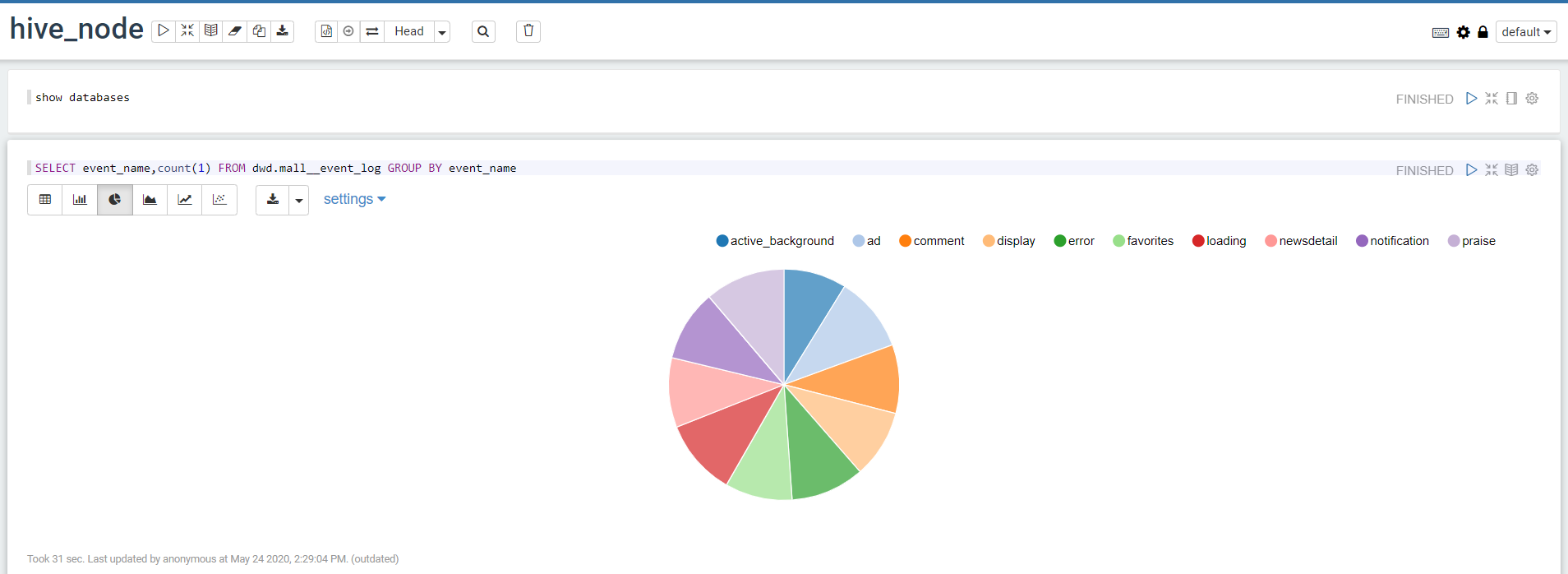



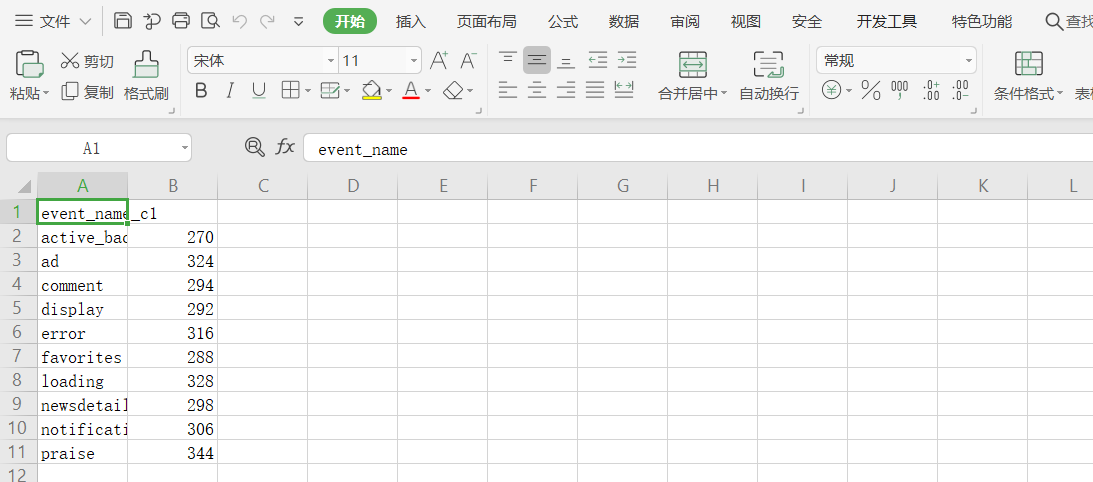
2.2 对接解释器,以Spark为例
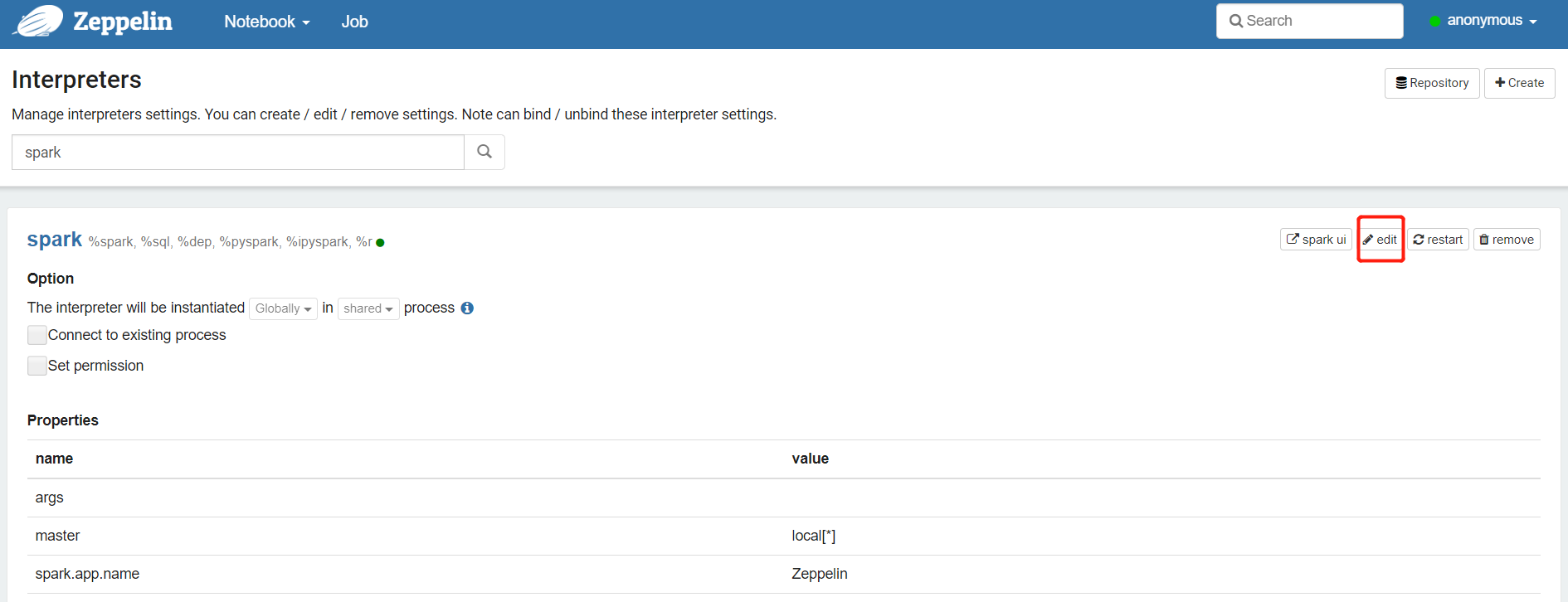
如需要使用集群模式配置
master yarn
spark.submit.deployMode cluster
spark.yarn.queue 列队名
spark.executor.memory 1g

- 使用
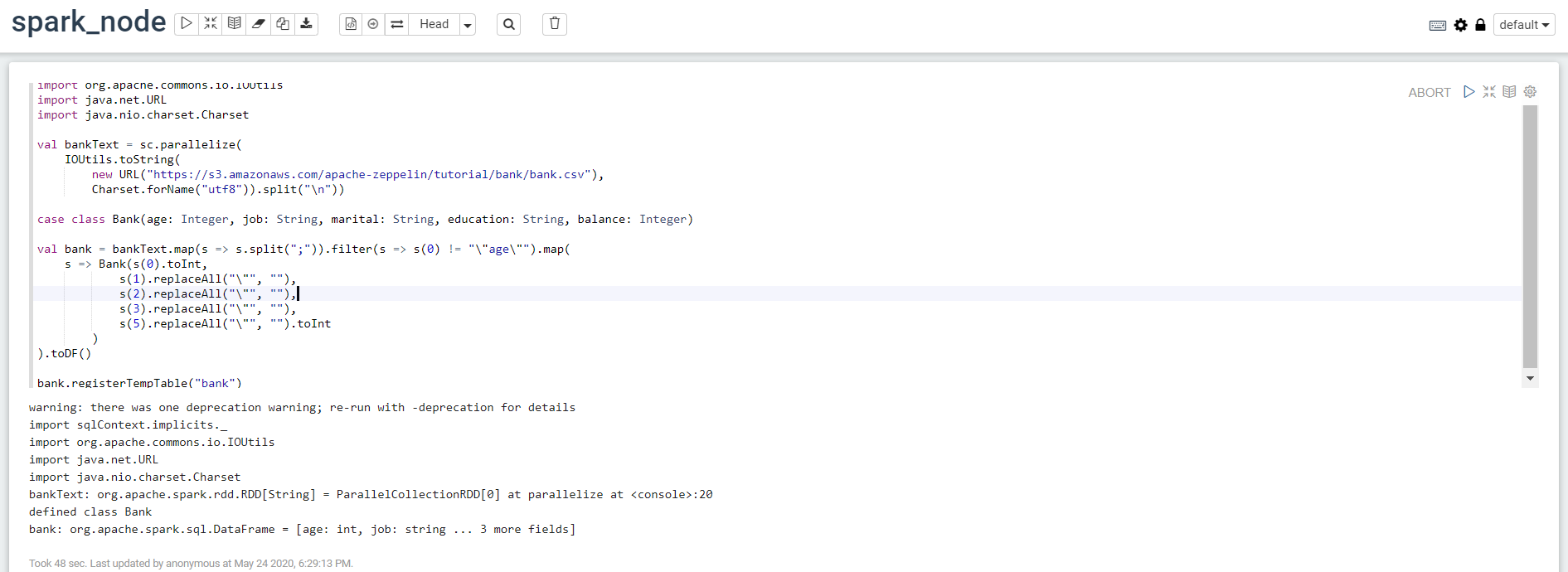
import org.apache.commons.io.IOUtils
import java.net.URL
import java.nio.charset.Charset
val bankText = sc.parallelize(
IOUtils.toString(
new URL("https://s3.amazonaws.com/apache-zeppelin/tutorial/bank/bank.csv"),
Charset.forName("utf8")).split("\n"))
case class Bank(age: Integer, job: String, marital: String, education: String, balance: Integer)
val bank = bankText.map(s => s.split(";")).filter(s => s(0) != "\"age\"").map(
s => Bank(s(0).toInt,
s(1).replaceAll("\"", ""),
s(2).replaceAll("\"", ""),
s(3).replaceAll("\"", ""),
s(5).replaceAll("\"", "").toInt
)
).toDF()
bank.registerTempTable("bank")
%sql
select age,count(1)
from bank
where age < ${maxAge=30}
group by age
order by age
%sql
select age, count(1) value
from bank
where age < 30
group by age
order by age
%sql
select age, count(1) value
from bank
where marital="${marital=single,single|divorced|married}"
group by age
order by age

2.3 对接解释器,以Kylin为例
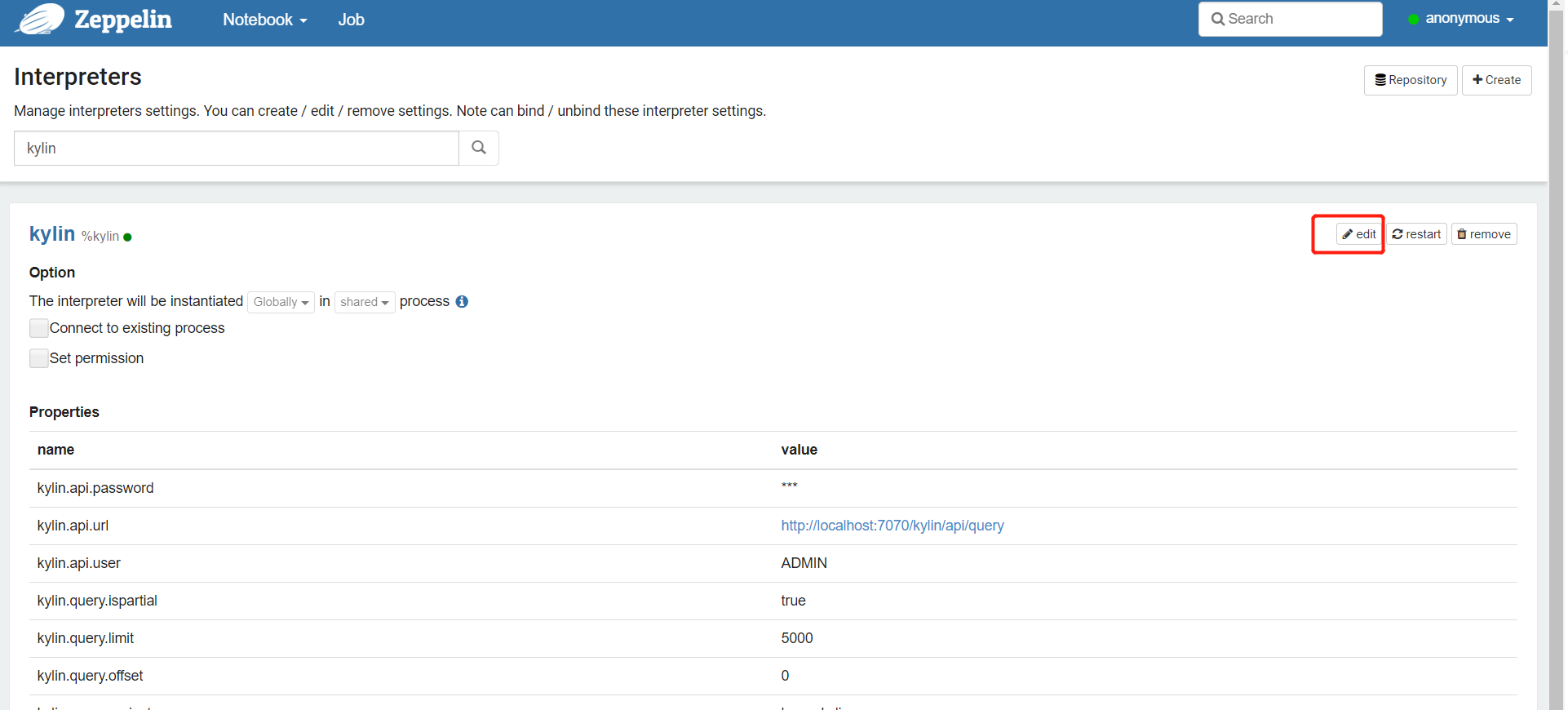
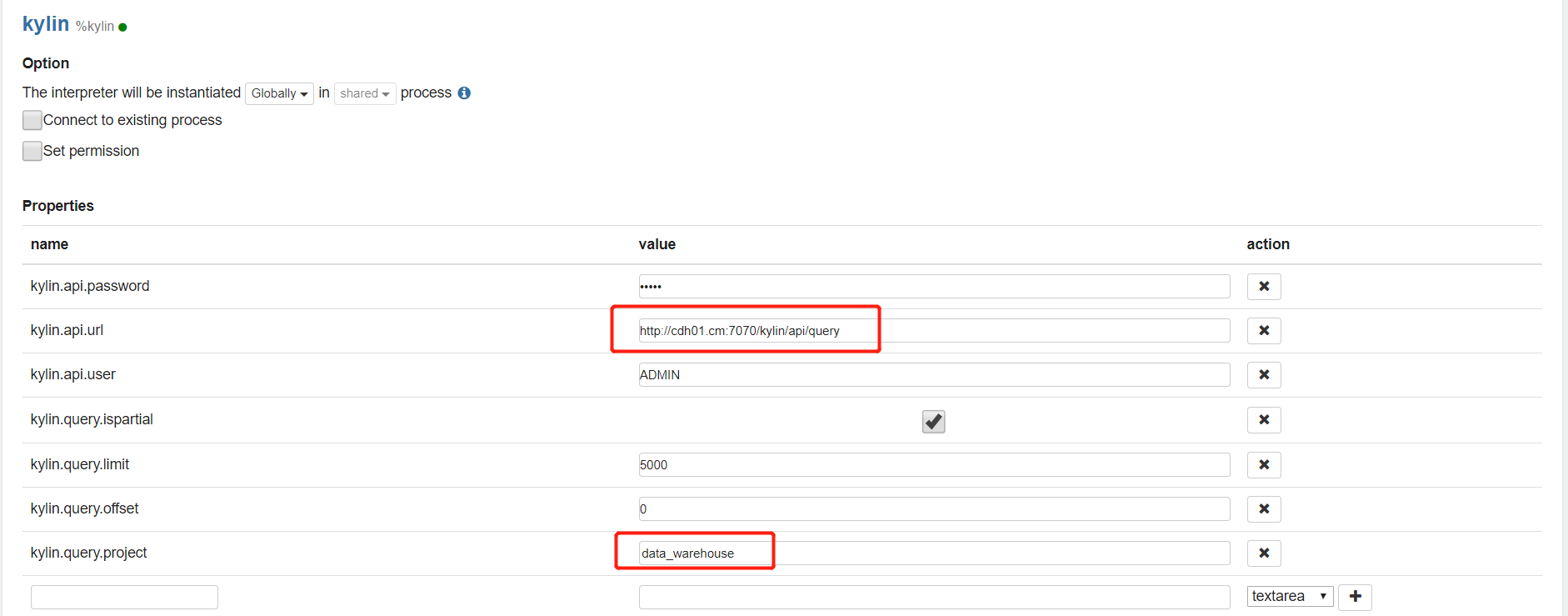
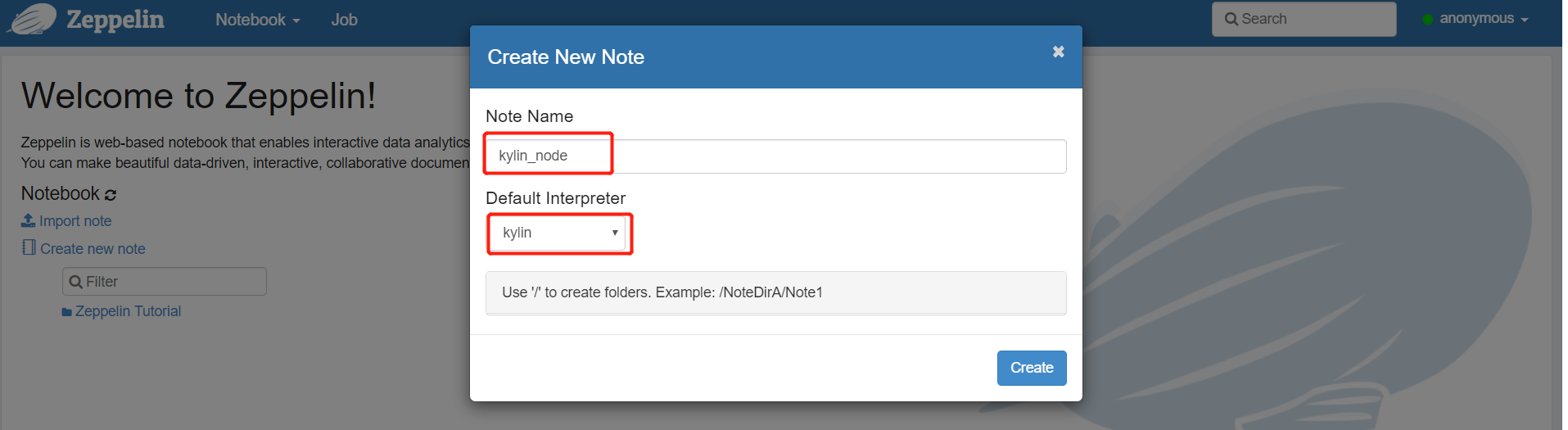
- 创建笔记,以下以麒麟为例
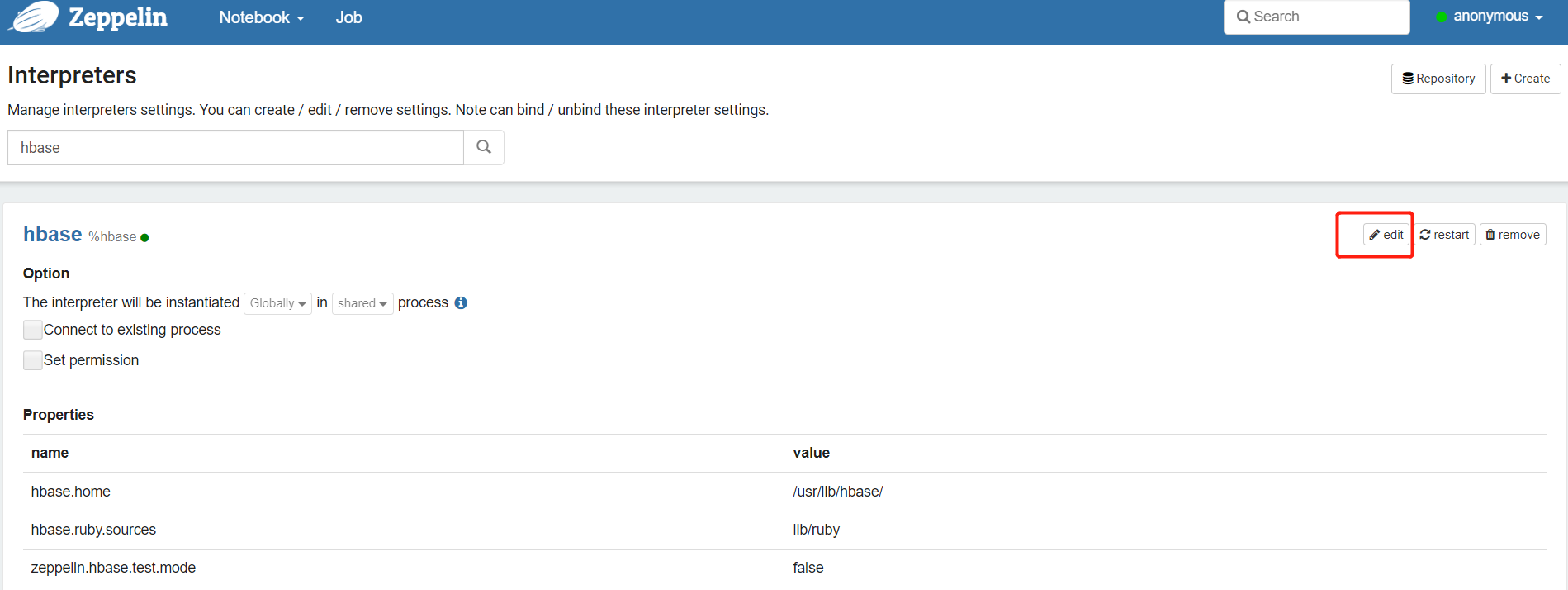
2.4 对接解释器,以Hbase为例
#将hbase配置文件copy到zeppelin下
cp /etc/hbase/conf/hbase-site.xml /usr/local/src/zeppelin/zeppelin-0.8.2-bin-all/conf/
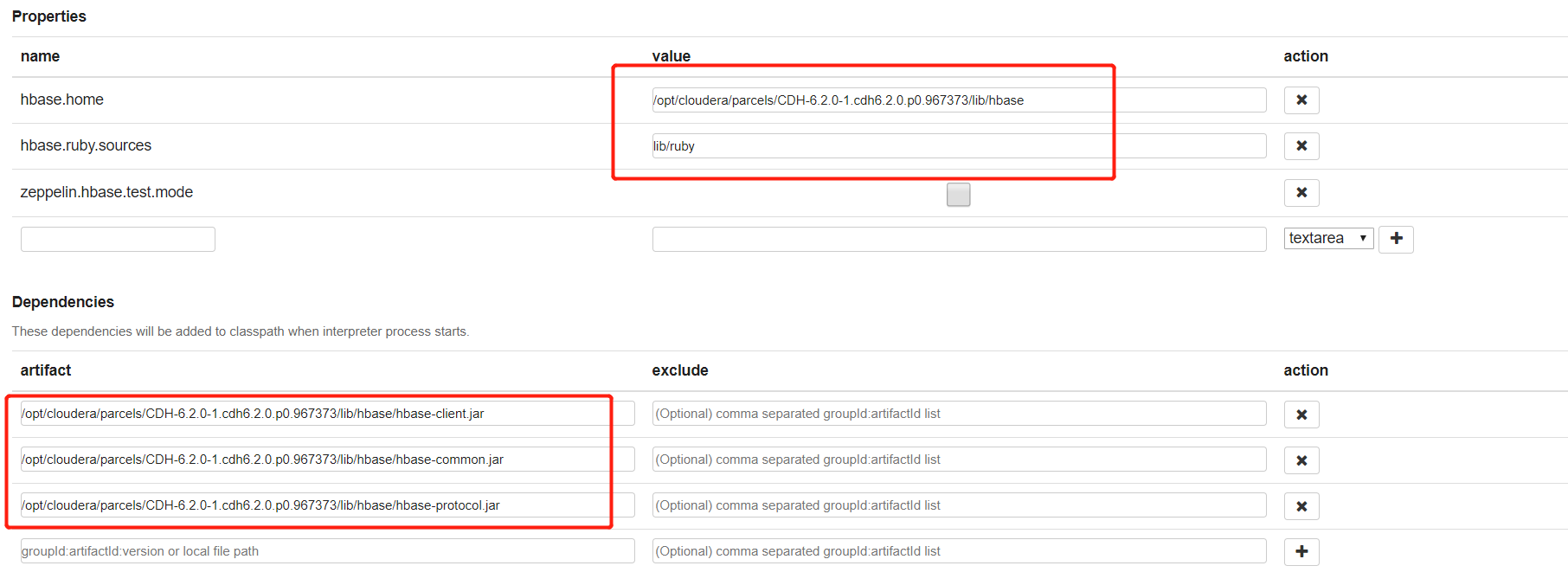
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hbase/hbase-client.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hbase/hbase-common.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hbase/hbase-protocol.jar
- 使用

您的资助是我最大的动力!
金额随意,欢迎来赏!

