

Eclipse下使用Stanford CoreNLP的方法
源码下载地址:CoreNLP官网。
目前release的CoreNLP version 3.5.0版本仅支持java-1.8及以上版本,因此有时需要为Eclipse添加jdk-1.8配置,配置方法如下:
- 首先,去oracle官网下载java-1.8,下载网址为:java下载,安装完成后。
- 打开Eclipse,选择Window -> Preferences -> Java –> Installed JREs 进行配置:
点击窗体右边的“add”,然后添加一个“Standard VM”(应该是标准虚拟机的意思),然后点击“next”;在”JRE HOME”那一行点击右边的“Directory…”找到你java 的安装路径,比如“C:Program Files/Java/jdk1.8”
这样你的Eclipse就已经支持jdk-1.8了。
1. 新建java工程,注意编译环境版本选择1.8

2. 将官网下载的源码解压到工程下,并导入所需jar包
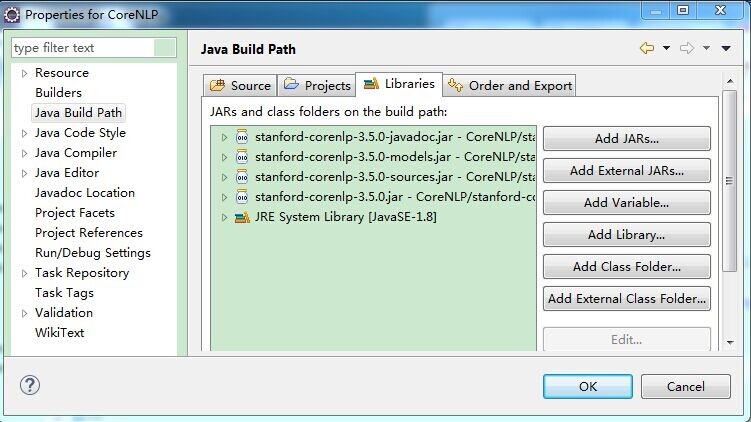
如导入stanford-corenlp-3.5.0.jar、stanford-corenlp-3.5.0-javadoc.jar、stanford-corenlp-3.5.0-models.jar、stanford-corenlp-3.5.0-sources.jar、xom.jar等
导入jar包过程为:项目右击->Properties->Java Build Path->Libraries,点击“Add JARs”,在路径中选取相应的jar包即可。
3. 新建TestCoreNLP类,代码如下
1 package Test; 2 3 import java.util.List; 4 import java.util.Map; 5 import java.util.Properties; 6 7 import edu.stanford.nlp.dcoref.CorefChain; 8 import edu.stanford.nlp.dcoref.CorefCoreAnnotations.CorefChainAnnotation; 9 import edu.stanford.nlp.ling.CoreAnnotations.LemmaAnnotation; 10 import edu.stanford.nlp.ling.CoreAnnotations.NamedEntityTagAnnotation; 11 import edu.stanford.nlp.ling.CoreAnnotations.PartOfSpeechAnnotation; 12 import edu.stanford.nlp.ling.CoreAnnotations.SentencesAnnotation; 13 import edu.stanford.nlp.ling.CoreAnnotations.TextAnnotation; 14 import edu.stanford.nlp.ling.CoreAnnotations.TokensAnnotation; 15 import edu.stanford.nlp.ling.CoreLabel; 16 import edu.stanford.nlp.pipeline.Annotation; 17 import edu.stanford.nlp.pipeline.StanfordCoreNLP; 18 import edu.stanford.nlp.semgraph.SemanticGraph; 19 import edu.stanford.nlp.semgraph.SemanticGraphCoreAnnotations.CollapsedCCProcessedDependenciesAnnotation; 20 import edu.stanford.nlp.sentiment.SentimentCoreAnnotations; 21 import edu.stanford.nlp.trees.Tree; 22 import edu.stanford.nlp.trees.TreeCoreAnnotations.TreeAnnotation; 23 import edu.stanford.nlp.util.CoreMap; 24 25 public class TestCoreNLP { 26 public static void main(String[] args) { 27 // creates a StanfordCoreNLP object, with POS tagging, lemmatization, NER, parsing, and coreference resolution 28 Properties props = new Properties(); 29 props.put("annotators", "tokenize, ssplit, pos, lemma, ner, parse, dcoref"); 30 StanfordCoreNLP pipeline = new StanfordCoreNLP(props); 31 32 // read some text in the text variable 33 String text = "Add your text here:Beijing sings Lenovo"; 34 35 // create an empty Annotation just with the given text 36 Annotation document = new Annotation(text); 37 38 // run all Annotators on this text 39 pipeline.annotate(document); 40 41 // these are all the sentences in this document 42 // a CoreMap is essentially a Map that uses class objects as keys and has values with custom types 43 List<CoreMap> sentences = document.get(SentencesAnnotation.class); 44 45 System.out.println("word\tpos\tlemma\tner"); 46 for(CoreMap sentence: sentences) { 47 // traversing the words in the current sentence 48 // a CoreLabel is a CoreMap with additional token-specific methods 49 for (CoreLabel token: sentence.get(TokensAnnotation.class)) { 50 // this is the text of the token 51 String word = token.get(TextAnnotation.class); 52 // this is the POS tag of the token 53 String pos = token.get(PartOfSpeechAnnotation.class); 54 // this is the NER label of the token 55 String ne = token.get(NamedEntityTagAnnotation.class); 56 String lemma = token.get(LemmaAnnotation.class); 57 58 System.out.println(word+"\t"+pos+"\t"+lemma+"\t"+ne); 59 } 60 // this is the parse tree of the current sentence 61 Tree tree = sentence.get(TreeAnnotation.class); 62 63 // this is the Stanford dependency graph of the current sentence 64 SemanticGraph dependencies = sentence.get(CollapsedCCProcessedDependenciesAnnotation.class); 65 } 66 // This is the coreference link graph 67 // Each chain stores a set of mentions that link to each other, 68 // along with a method for getting the most representative mention 69 // Both sentence and token offsets start at 1! 70 Map<Integer, CorefChain> graph = document.get(CorefChainAnnotation.class); 71 } 72 }
PS:该代码的思想是将text字符串交给Stanford CoreNLP处理,StanfordCoreNLP的各个组件(annotator)按“tokenize(分词), ssplit(断句), pos(词性标注), lemma(词元化), ner(命名实体识别), parse(语法分析), dcoref(同义词分辨)”顺序进行处理。
处理完后List<CoreMap> sentences = document.get(SentencesAnnotation.class);中包含了所有分析结果,遍历即可获知结果。
这里简单的将单词、词性、词元、是否实体打印出来。其余的用法参见官网(如sentiment、parse、relation等)。
4. 执行结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号