
最左前缀原则;复合索引;索引;cpu占用高,threads高;硬解析;查询缓存;mysql性能优化,追踪排查。
http://www.zhihu.com/question/22002813
CPU占用过高和磁盘I/O没有必然联系。如果数据库I/O繁忙CPU反而利用率上不去,因为CPU处于I/O wait状态。
数据库CPU高主要有2个原因,第一个是内存latch,第二个是硬解析。所以我觉得LZ应该从这两方面去排查问题,优化I/O是错误的方向。
================================
http://www.phpxun.com/post/15.html
MySQL prepare 原理:
Prepare的出现就是为了优化硬解析的问题。Prepare在服务器端的执行过程如下
1) Prepare 接收客户端带”?”的sql, 硬解析得到语法树(stmt->Lex), 缓存在线程所在的preparestatement cache中。此cache是一个HASH MAP. Key为stmt->id. 然后返回客户端stmt->id等信息。
2) Execute 接收客户端stmt->id和参数等信息。注意这里客户端不需要再发sql过来。服务器根据stmt->id在preparestatement cache中查找得到硬解析后的stmt, 并设置参数,就可以继续后面的优化和执行了。
Prepare在execute阶段可以节省硬解析的时间。如果sql只执行一次,且以prepare的方式执行,那么sql执行需两次与服务器交互(Prepare和execute), 而以普通(非prepare)方式,只需要一次交互。这样使用prepare带来额外的网络开销,可能得不偿失。我们再来看同一sql执行多次的情况,比如以prepare方式执行10次,那么只需要一次硬解析。这时候 额外的网络开销就显得微乎其微了。因此prepare适用于频繁执行的SQL。
Prepare的另一个作用是防止sql注入,不过这个是在客户端jdbc通过转义实现的,跟服务器没有关系。
思考
1 开启cachePrepStmts的问题,前面谈到每个连接都有一个缓存,是以sql为唯一标识的LRU cache. 在分表较多,大连接的情况下,可能会个应用服务器带来内存问题。这里有个前提是ibatis是默认使用prepare的。 在mybatis中,标签statementType可以指定某个sql是否是使用prepare.
statementType Any one of STATEMENT, PREPARED or CALLABLE. This causes MyBatis to use Statement, PreparedStatement orCallableStatement respectively. Default: PREPARED.
这样可以精确控制只对频率较高的sql使用prepare,从而控制使用prepare sql的个数,减少内存消耗。遗憾的是目前集团貌似大多使用的是ibatis 2.0版本,不支持statementType
标签。
2 服务器端prepare cache是一个HASH MAP. Key为stmt->id,同时也是每个连接都维护一个。因此也有可能出现内存问题,待实际测试。如有必要需改造成Key为sql的全局cache,这样不同连接的相同prepare sql可以共享。
3 oracle prepare与mysql prepare的区别:
mysql与oracle有一个重大区别是mysql没有oracle那样的执行计划缓存。前面我们讲到SQL执行过程包括以下阶段 词法分析->语法分析->语义分析->执行计划优化->执行。oracle的prepare实际上包括以下阶段:词法分析->语法分析->语义分析->执行计划优化,也就是说oracle的prepare做了更多的事情,execute只需要执行即可。因此,oracle的prepare比mysql更高效。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
|
<?php class timer { public $StartTime = 0; public $StopTime = 0; public $TimeSpent = 0; function start(){ $this->StartTime = microtime(); } function stop(){ $this->StopTime = microtime(); } function spent() { if ($this->TimeSpent) { return $this->TimeSpent; } else { $StartMicro = substr($this->StartTime,0,10); $StartSecond = substr($this->StartTime,11,10); $StopMicro = substr($this->StopTime,0,10); $StopSecond = substr($this->StopTime,11,10); $start = floatval($StartMicro) + $StartSecond; $stop = floatval($StopMicro) + $StopSecond; $this->TimeSpent = $stop - $start; return round($this->TimeSpent,8).'秒'; } } } $timer = new timer; $timer->start(); $mysql = new mysqli('localhost','root','root','test'); /* //普通mysql查询 $query = $mysql->query("select username,email from uc_members where uid < 100000"); $result = array(); while($result = $query->fetch_array()) { $result[] = array('name'=>$result['username'],'email'=>$result['email']); } */ //prepare预mysql查询 $query_prepare = $mysql->prepare("select username,email from uc_members where uid < ?"); $id = 100000; $query_prepare->bind_param("i",$id); $query_prepare->execute(); $query_prepare->bind_result($username,$email); $result = array(); while($query_prepare->fetch()) { $result[] = array('name'=>$username,'email'=>$email); } $timer->stop(); echo '</br>预查询mysql运行100000条数据时间为: '.$timer->spent(); unset($timer); //var_dump($result); //测试运行结果如下:普通mysql运行1000条数据时间为: 0.011621秒普通mysql运行10000条数据时间为: 0.07766891秒普通mysql运行100000条数据时间为: 0.10834217秒 预查询mysql运行1000条数据时间为: 0.00963211秒预查询mysql运行10000条数据时间为: 0.04614592秒预查询mysql运行100000条数据时间为: 0.05989885秒 |
=======================
...............
http://www.niubua.com/?p=1383
我的MYSQL学习心得(九) 索引
这一篇《我的MYSQL学习心得(九)》将会讲解MYSQL的索引
索引是在存储引擎中实现的,因此每种存储引擎的索引都不一定完全相同,并且每种存储引擎也不一定支持所有索引类型。
根据存储引擎定义每个表的最大索引数和最大索引长度。所有存储引擎支持每个表至少16个索引,总索引长度至少为256字节。
大多数存储引擎有更高的限制。MYSQL中索引的存储类型有两种:BTREE和HASH,具体和表的存储引擎相关;
MYISAM和InnoDB存储引擎只支持BTREE索引;MEMORY和HEAP存储引擎可以支持HASH和BTREE索引
索引的优点:
1、通过创建唯一索引,保证数据库表每行数据的唯一性
2、大大加快数据查询速度
3、在使用分组和排序进行数据查询时,可以显著减少查询中分组和排序的时间
索引的缺点:
1、维护索引需要耗费数据库资源
2、索引需要占用磁盘空间,索引文件可能比数据文件更快达到最大文件尺寸
3、当对表的数据进行增删改的时候,因为要维护索引,速度会受到影响
索引的分类
1、普通索引和唯一索引
主键索引是一种特殊的唯一索引,不允许有空值
2、单列索引和复合索引
单列索引只包含单个列
复合索引指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用复合索引时遵循最左前缀集合
3、全文索引
全文索引类型为FULLTEXT,在定义索引的列上支持值的全文查找,允许在这些索引列中插入重复值和空值。全文索引可以在
CHAR、VARCHAR、TEXT类型列上创建。MYSQL只有MYISAM存储引擎支持全文索引
4、空间索引
空间索引是对空间数据类型的字段建立的索引,MYSQL中的空间数据类型有4种,
分别是GEOMETRY、POINT、LINESTRING、POLYGON。
MYSQL使用SPATIAL关键字进行扩展,使得能够用于创建正规索引类型的语法创建空间索引。创建空间索引的列,必须
将其声明为NOT NULL,空间索引只能在存储引擎为MYISAM的表中创建
以上的索引在SQLSERVER里都支持
CREATE TABLE table_name[col_name data type] [unique|fulltext|spatial][index|key][index_name](col_name[length])[asc|desc]
unique|fulltext|spatial为可选参数,分别表示唯一索引、全文索引和空间索引;
index和key为同义词,两者作用相同,用来指定创建索引
col_name为需要创建索引的字段列,该列必须从数据表中该定义的多个列中选择;
index_name指定索引的名称,为可选参数,如果不指定,MYSQL默认col_name为索引值;
length为可选参数,表示索引的长度,只有字符串类型的字段才能指定索引长度;
asc或desc指定升序或降序的索引值存储
普通索引
CREATE TABLE book ( bookid INT NOT NULL, bookname VARCHAR (255) NOT NULL, AUTHORS VARCHAR (255) NOT NULL, info VARCHAR (255) NULL, COMMENT VARCHAR (255) NULL, year_publication YEAR NOT NULL, INDEX (year_publication) ) ;
使用SHOW CREATE TABLE查看表结构
CREATE TABLE `book` ( `bookid` INT(11) NOT NULL, `bookname` VARCHAR(255) NOT NULL, `authors` VARCHAR(255) NOT NULL, `info` VARCHAR(255) DEFAULT NULL, `comment` VARCHAR(255) DEFAULT NULL, `year_publication` YEAR(4) NOT NULL, KEY `year_publication` (`year_publication`) ) ENGINE=MYISAM DEFAULT CHARSET=latin1
可以发现,book表的year_publication字段成功建立了索引其索引名字为year_publication
我们向表插入一条数据,然后使用EXPLAIN语句查看索引是否有在使用
INSERT INTO BOOK VALUES(12,'NIHAO','NIHAO','文学','henhao',1990) EXPLAIN SELECT * FROM book WHERE year_publication=1990
因为语句比较简单,系统判断有可能会用到索引或者全文扫描

EXPLAIN语句输出结果的各个行的解释如下:
select_type: 表示查询中每个select子句的类型(简单 OR复杂)
type:表示MySQL在表中找到所需行的方式,又称“访问类型”,常见类型如下:(从上至下,效果依次变好)
possible_keys :指出MySQL能使用哪个索引在表中找到行,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用
key: 显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL
key_len :表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度
ref :表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
rows :表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数
Extra :包含不适合在其他列中显示但十分重要的额外信息 如using where,using index
参考:MySQL学习系列2–MySQL执行计划分析EXPLAIN
唯一索引
唯一索引列的值必须唯一,但允许有空值。如果是复合索引则列值的组合必须唯一
建表
CREATE TABLE t1 ( id INT NOT NULL, NAME CHAR(30) NOT NULL, UNIQUE INDEX UniqIdx(id)
SHOW CREATE TABLE t1 查看表结构
SHOW CREATE TABLE t1
CREATE TABLE `t1` (
`id` int(11) NOT NULL,
`name` char(30) NOT NULL, UNIQUE KEY `UniqIdx` (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
可以看到id字段上已经成功建立了一个名为UniqIdx的唯一索引
创建复合索引
CREATE TABLE t3 ( id INT NOT NULL, NAME CHAR(30) NOT NULL, age INT NOT NULL, info VARCHAR (255), INDEX MultiIdx (id, NAME, age (100)) )
SHOW CREATE TABLE t3 CREATE TABLE `t3` (
`id` int(11) NOT NULL,
`NAME` char(30) NOT NULL,
`age` int(11) NOT NULL,
`info` varchar(255) DEFAULT NULL, KEY `MultiIdx` (`id`,`NAME`,`age`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
由结果可以看到id,name,age字段上已经成功建立了一个名为MultiIdx的复合索引
我们向表插入两条数据
INSERT INTO t3(id ,NAME,age,info) VALUES(1,'小明',12,'nihao'),(2,'小芳',16,'nihao')
使用EXPLAIN语句查看索引使用情况
EXPLAIN SELECT * FROM t3 WHERE id=1 AND NAME='小芳'
可以看到 possible_keys和 key 为MultiIdx证明使用了复合索引
id select_type table type possible_keys key key_len ref rows Extra ------ ----------- ------ ------ ------------- -------- ------- ----------- ------ ----------- 1 SIMPLE t3 ref MultiIdx MultiIdx 94 const,const 1 Using where
如果我们只指定name而不指定id
EXPLAIN SELECT * FROM t3 WHERE NAME='小芳'
id select_type table type possible_keys key key_len ref rows Extra ------ ----------- ------ ------ ------------- ------ ------- ------ ------ ----------- 1 SIMPLE t3 ALL (NULL) (NULL) (NULL) (NULL) 2 Using where
结果跟SQLSERVER一样,也是不走索引, possible_keys和key都为NULL
全文索引
FULLTEXT索引可以用于全文搜索。只有MYISAM存储引擎支持FULLTEXT索引,并且只支持CHAR、VARCHAR和TEXT类型
全文索引不支持过滤索引。
CREATE TABLE t4 ( id INT NOT NULL, NAME CHAR(30) NOT NULL, age INT NOT NULL, info VARCHAR (255), FULLTEXT INDEX FulltxtIdx (info) ) ENGINE = MYISAM
由于MYSQL5.6默认存储引擎为InnoDB,这里创建表的时候要修改表的存储引擎为MYISAM,不然创建索引会出错
SHOW CREATE TABLE t4
Table Create Table ------ ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- t4 CREATE TABLE `t4` (
`id` int(11) NOT NULL,
`name` char(30) NOT NULL,
`age` int(11) NOT NULL,
`info` varchar(255) DEFAULT NULL,
FULLTEXT KEY `FulltxtIdx` (`info`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
由结果可以看到,info字段上已经成功建立名为FulltxtIdx的FULLTEXT索引。
全文索引非常适合大型数据集合
在SQLSERVER里使用全文索引比MYSQL还要复杂
详细可以参考下面两篇文章:
空间索引
空间索引必须在 MYISAM类型的表中创建,而且空间类型的字段必须为非空
建表t5
CREATE TABLE t5 (g GEOMETRY NOT NULL ,SPATIAL INDEX spatIdx(g))ENGINE=MYISAM
SHOW CREATE TABLE t5 TABLE CREATE TABLE ------ --------------------------------------------------------------------------------------------------------------- t5 CREATE TABLE `t5` (
`g` GEOMETRY NOT NULL,
SPATIAL KEY `spatIdx` (`g`)
) ENGINE=MYISAM DEFAULT CHARSET=utf8
可以看到,t5表的g字段上创建了名称为spatIdx的空间索引。注意创建时指定空间类型字段值的非空约束
并且表的存储引擎为MYISAM
已经存在的表上创建索引
在已经存在的表中创建索引,可以使用ALTER TABLE或者CREATE INDEX语句
1、使用ALTER TABLE语句创建索引,语法如下
ALTER TABLE table_name ADD [UNIQUE|FULLTEXT|SPATIAL][INDEX|KEY]
[index_name](col_name[length],…)[ASC|DESC]
与创建表时创建索引的语法不同,在这里使用了ALTER TABLE和ADD关键字,ADD表示向表中添加索引
在t1表中的name字段上建立NameIdx普通索引
ALTER TABLE t1 ADD INDEX NameIdx(NAME)
添加索引之后,使用SHOW INDEX语句查看指定表中创建的索引
SHOW INDEX FROM t1 TABLE Non_unique Key_name Seq_in_index Column_name COLLATION Cardinality Sub_part Packed NULL Index_type COMMENT Index_comment ------ ---------- -------- ------------ ----------- --------- ----------- -------- ------ ------ ---------- ------- ------------- t1 0 UniqIdx 1 id A 0 (NULL) (NULL) BTREE t1 1 NameIdx 1 NAME A (NULL) (NULL) (NULL) BTREE
各个参数的含义
1、TABLE:要创建索引的表
2、Non_unique:索引非唯一,1代表是非唯一索引,0代表唯一索引
3、Key_name:索引的名称
4、Seq_in_index:该字段在索引中的位置,单列索引该值为1,复合索引为每个字段在索引定义中的顺序
5、Column_name:定义索引的列字段
6、Sub_part:索引的长度
7、NULL:该字段是否能为空值
8、Index_type:索引类型
可以看到,t1表已经存在了一个唯一索引
在t3表的age和info字段上创建复合索引
ALTER TABLE t3 ADD INDEX t3AgeAndInfo(age,info)
使用SHOW INDEX查看表中的索引
SHOW INDEX FROM t3
Table Non_unique Key_name Seq_in_index Column_name Collation Cardinality Sub_part Packed Null Index_type Comment Index_comment ------ ---------- ------------ ------------ ----------- --------- ----------- -------- ------ ------ ---------- ------- ------------- t3 1 MultiIdx 1 id A (NULL) (NULL) (NULL) BTREE t3 1 MultiIdx 2 NAME A (NULL) (NULL) (NULL) BTREE t3 1 MultiIdx 3 age A (NULL) (NULL) (NULL) BTREE t3 1 t3AgeAndInfo 1 age A (NULL) (NULL) (NULL) BTREE t3 1 t3AgeAndInfo 2 info A (NULL) (NULL) (NULL) YES BTREE
可以看到表中的字段的顺序,第一个位置是age,第二个位置是info,info字段是可空字段


创建表t6,在t6表上创建全文索引
CREATE TABLE t6 ( id INT NOT NULL, info CHAR(255) )ENGINE= MYISAM;
注意修改ENGINE参数为MYISAM,MYSQL默认引擎InnoDB不支持全文索引
使用ALTER TABLE语句在info字段上创建全文索引
ALTER TABLE t6 ADD FULLTEXT INDEX infoFTIdx(info)
使用SHOW INDEX查看索引情况
SHOW INDEX FROM t6
Table Non_unique Key_name Seq_in_index Column_name Collation Cardinality Sub_part Packed Null Index_type Comment Index_comment ------ ---------- --------- ------------ ----------- --------- ----------- -------- ------ ------ ---------- ------- ------------- t6 1 infoFTIdx 1 info (NULL) (NULL) (NULL) (NULL) YES FULLTEXT
创建表t7,并在空间数据类型字段g上创建名称为spatIdx的空间索引
CREATE TABLE t7(g GEOMETRY NOT NULL)ENGINE=MYISAM;
使用ALTER TABLE在表t7的g字段建立空间索引
ALTER TABLE t7 ADD SPATIAL INDEX spatIdx(g)
使用SHOW INDEX查看索引情况
SHOW INDEX FROM t7
Table Non_unique Key_name Seq_in_index Column_name Collation Cardinality Sub_part Packed Null Index_type Comment Index_comment ------ ---------- -------- ------------ ----------- --------- ----------- -------- ------ ------ ---------- ------- ------------- t7 1 spatIdx 1 g A (NULL) 32 (NULL) SPATIAL
2、使用CREATE INDEX语句创建索引,语法如下
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
ON table_name(col_name[length],…) [ASC|DESC]
可以看到CREATE INDEX语句和ALTER INDEX语句的基本语法一样,只是关键字不同。
我们建立一个book表
CREATE TABLE book ( bookid INT NOT NULL, bookname VARCHAR (255) NOT NULL, AUTHORS VARCHAR (255) NOT NULL, info VARCHAR (255) NULL, COMMENT VARCHAR (255) NULL, year_publication YEAR NOT NULL )
建立普通索引
CREATE INDEX BkNameIdx ON book(bookname)
建立唯一索引
CREATE UNIQUE INDEX UniqidIdx ON book(bookId)
建立复合索引
CREATE INDEX BkAuAndInfoIdx ON book(AUTHORS(20),info(50))
建立全文索引,我们drop掉t6表,重新建立t6表
DROP TABLE IF EXISTS t6 CREATE TABLE t6 ( id INT NOT NULL, info CHAR(255) )ENGINE= MYISAM; CREATE FULLTEXT INDEX infoFTIdx ON t6(info);
建立空间索引,我们drop掉t7表,重新建立t7表
DROP TABLE IF EXISTS t7 CREATE TABLE t7(g GEOMETRY NOT NULL)ENGINE=MYISAM; CREATE SPATIAL INDEX spatIdx ON t7(g)
删除索引
MYSQL中使用ALTER TABLE或者DROP INDEX语句来删除索引,两者实现相同功能
1、使用ALTER TABLE删除索引
语法
ALTER TABLE table_name DROP INDEX index_name
ALTER TABLE book DROP INDEX UniqidIdx
SHOW CREATE TABLE book
Table Create Table ------ ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ book CREATE TABLE `book` (
`bookid` int(11) NOT NULL,
`bookname` varchar(255) NOT NULL,
`authors` varchar(255) NOT NULL,
`info` varchar(255) DEFAULT NULL,
`comment` varchar(255) DEFAULT NULL,
`year_publication` year(4) NOT NULL, KEY `BkNameIdx` (`bookname`), KEY `BkAuAndInfoIdx` (`authors`(20),`info`(50))
) ENGINE=MyISAM DEFAULT CHARSET=utf8
可以看到,book表中已经没有名为UniqidIdx的唯一索引,删除索引成功
注意:AUTO_INCREMENT约束字段的唯一索引不能被删除!!
2、使用DROP INDEX 语句删除索引
DROP INDEX index_name ON table_name
DROP INDEX BkAuAndInfoIdx ON book
SHOW CREATE TABLE book; Table Create Table ------ --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- book CREATE TABLE `book` (
`bookid` int(11) NOT NULL,
`bookname` varchar(255) NOT NULL,
`authors` varchar(255) NOT NULL,
`info` varchar(255) DEFAULT NULL,
`comment` varchar(255) DEFAULT NULL,
`year_publication` year(4) NOT NULL, KEY `BkNameIdx` (`bookname`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
可以看到,复合索引BkAuAndInfoIdx已经被删除了
提示:删除表中的某列时,如果要删除的列为索引的组成部分,则该列也会从索引中删除。
如果索引中的所有列都被删除,则整个索引将被删除!!
总结
这一节介绍了MYSQL中的索引,索引语句的创建和删除和一些简单用法,希望对大家有帮助
http://wulijun.github.io/2012/08/21/mysql-index-implementation-and-optimization.html
[转]MYSQL索引结构原理、性能分析与优化
第一部分:基础知识
索引
官方介绍索引是帮助MySQL高效获取数据的数据结构。笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里, 不用一页一页查阅找出需要的资料。
唯一索引(unique index)
强调唯一,就是索引值必须唯一。
创建索引: create unique index 索引名 on 表名(列名); alter table 表名 add unique index 索引名 (列名);
删除索引: drop index 索引名 on 表名; alter table 表名 drop index 索引名;
主键
主键就是唯一索引的一种,主键要求建表时指定,一般用auto_increment列,关键字是primary key
主键创建: creat table test2 (id int not null primary key auto_increment);
全文索引
InnoDB不支持,MyISAM支持性能比较好,一般在 CHAR、VARCHAR 或 TEXT 列上创建。 Create table 表名( id int not null primary key anto_increment, title varchar(100),FULLTEXT(title) )type=MyISAM;
单列索引与多列索引
索引可以是单列索引也可以是多列索引(也叫复合索引)。按照上面形式创建出来的索引是单列索引,现在先看看创建多列索引: create table test3 ( id int not null primary key auto_increment, uname char(8) not null default '', password char(12) not null, INDEX(uname,password) )type=MyISAM; 注意:INDEX(a, b, c)可以当做a或(a, b)的索引来使用,但不能当作b、c或(b,c)的索引来使用。这是一个最左前缀的 优化方法,在后面会有详细的介绍,你只要知道有这样两个概念。
聚簇索引
一种索引,该索引中键值的逻辑顺序决定了表中相应行的物理顺序。 聚簇索引确定表中数据的物理顺序。Mysql中MyISAM 表是没有聚簇索引的,innodb有(主键就是聚簇索引),聚簇索引在下面介绍innodb结构的时有详细介绍。
查看表的索引
通过命令:Show index from 表名 如: mysql> show index from test3;
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+----+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+----+ | test3 | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+ Table:表名 Key_name:什么类型索引(这里是主键) Column_name:索引列的字段名 Cardinality:索引基数,很关键的一个参数,平均数值组=索引基数/表总数据行,平均数值组越接近1就越有可能利用索引 Index_type:如果索引是全文索引,则是fulltext,这里是b+tree索引,b+tree也是这篇文章研究的重点之一
第二部分:MyISAM和INNODB索引结构
简单介绍B-tree B+ tree树
B-tree结构视图
一棵m阶的B-tree树,则有以下性质
- Ki表示关键字值,上图中,k1<k2<…<ki<k0<Kn(可以看出,一个节点的左子节点关键字值<该关键字值<右子节点关键字值)
- Pi表示指向子节点的指针,左指针指向左子节点,右指针指向右子节点。即是:p1[指向值]<k1<p2[指向值]<k2……
- 所有关键字必须唯一值(这也是创建MyISAM 和innodb表必须要主键的原因),每个节点包含一个说明该节点多少个关键字,如上图第二行的i和n
- 节点:
- 每个节点最可以有m个子节点。
- 根节点若非叶子节点,至少2个子节点,最多m个子节点
- 每个非根,非叶子节点至少[m/2]子节点或叫子树([]表示向上取整),最多m个子节点
- 关键字:
- 根节点的关键字个数1~m-1
- 非根非叶子节点的关键字个数[m/2]-1~m-1,如m=3,则该类节点关键字个数:2-1~2
- 关键字数k和指向子节点个数指针p的关系:
- k+1=p ,注意根据储存数据的具体需求,左右指针为空时要有标志位表示没有 B+tree结构示意图如下:
B+树是B-树的变体,也是一种多路搜索树: * 非叶子结点的子树指针与关键字个数相同 * 为所有叶子结点增加一个链指针(红点标志的箭头)
MyISAM索引结构
MyISAM索引用的B+ tree来储存数据,MyISAM索引的指针指向的是键值的地址,地址存储的是数据,如下图:
结构讲解:上图3阶树,主键是Col2,Col值就是改行数据保存的物理地址,其中红色部分是说明标注。
- 1标注部分也许会迷惑,前面不是说关键字15右指针的指向键值要大于15,怎么下面还有15关键字?因为B+tree的所有叶子节点 包含所有关键字且是按照升序排列(主键索引唯一,辅助索引可以不唯一),所以等于关键字的数据值在右子树
- 2标注是相应关键字存储对应数据的物理地址,注意这也是之后和InnoDB索引不同的地方之一
- 2标注也是一个所说MyISAM表的索引和数据是分离的,索引保存在”表名.MYI”文件内,而数据保存在“表名.MYD”文件内,2标注 的物理地址就是“表名.MYD”文件内相应数据的物理地址。(InnoDB表的索引文件和数据文件在一起)
- 辅助索引和主键索引没什么大的区别,辅助索引的索引值是可以重复的(但InnoDB辅助索引和主键索引有很明显的区别,这里 先提醒注意一下)
Innode索引结构
(1)首先有一个表,内容和主键索引结构如下两图:
|
Col1 |
Col2 |
Col3 |
|
1 |
15 |
phpben |
|
2 |
20 |
mhycoe |
|
3 |
23 |
phpyu |
|
4 |
25 |
bearpa |
|
5 |
40 |
phpgoo |
|
6 |
45 |
phphao |
|
7 |
48 |
phpxue |
|
…… |
||
结构上:由上图可以看出InnoDB的索引结构很MyISAM的有很明显的区别
- MyISAM表的索引和数据是分开的,用指针指向数据的物理地址,而InnoDB表中索引和数据是储存在一起。看红框1可看出一行 数据都保存了。
- 还有一个上图多了三行的隐藏数据列(虚线表),这是因为MyISAM不支持事务,InnoDB处理事务在性能上并发控制上比较好, 看图中的红框2中的DB_TRX_ID是事务ID,自动增长;db_roll_ptr是回滚指针,用于事务出错时数据回滚恢复;db_row_id 是记录行号,这个值其实在主键索引中就是主键值,这里标出重复是为了容易介绍,还有的是若不是主键索引(辅助索引), db_row_id会找表中unique的列作为值,若没有unique列则系统自动创建一个。关于InnoDB跟多事务MVCC点 此:http://www.phpben.com/?post=72
(2)加入上表中Col1是主键(下图标错),而Col2是辅助索引,则相应的辅助索引结构图:
可以看出InnoDB辅助索引并没有保存相应的所有列数据,而是保存了主键的键值(图中1、2、3….)这样做利弊也是很明显:
- 在已有主键索引,避免数据冗余,同时在修改数据的时候只需修改辅助索引值。
- 但辅助索引查找数据事要检索两次,先找到相应的主键索引值然后在去检索主键索引找到对应的数据。这也是网上很多 mysql性能优化时提到的“主键尽可能简短”的原因,主键越长辅助索引也就越大,当然主键索引也越大。
MyISAM索引与InnoDB索引相比较
- MyISAM支持全文索引(FULLTEXT)、压缩索引,InnoDB不支持
- InnoDB支持事务,MyISAM不支持
- MyISAM顺序储存数据,索引叶子节点保存对应数据行地址,辅助索引很主键索引相差无几;InnoDB主键节点同时保存数据行,其他辅助索引保存的是主键索引的值
- MyISAM键值分离,索引载入内存(key_buffer_size),数据缓存依赖操作系统;InnoDB键值一起保存,索引与数据一起载入InnoDB缓冲池
- MyISAM主键(唯一)索引按升序来存储存储,InnoDB则不一定
- MyISAM索引的基数值(Cardinality,show index 命令可以看见)是精确的,InnoDB则是估计值。这里涉及到信息统计的知识,MyISAM统计信息是保存磁盘中,在alter表或Analyze table操作更新此信息,而InnoDB则是在表第一次打开的时候估计值保存在缓存区内
- MyISAM处理字符串索引时用增量保存的方式,如第一个索引是‘preform’,第二个是‘preformence’,则第二个保存是‘7,ance‘,这个明显的好处是缩短索引,但是缺陷就是不支持倒序提取索引,必须顺序遍历获取索引
第三部分:MYSQL优化
mysql优化是一个重大课题之一,这里会重点详细的介绍mysql优化,包括表数据类型选择,sql语句优化,系统配置与维护优化三类。
表数据类型选择
- 能小就用小。表数据类型第一个原则是:使用能正确的表示和存储数据的最短类型。这样可以减少对磁盘空间、内存、cpu缓存的使用。
- 避免用NULL,这个也是网上优化技术博文传的最多的一个。理由是额外增加字节,还有使索引,索引统计和值更复杂。很多还忽略一 个count(列)的问题,count(列)是不会统计列值为null的行数。更多关于NULL可参考:http://www.phpben.com/?post=71
- 字符串如何选择char和varchar?一般phper能想到就是char是固定大小,varchar能动态储存数据。这里整理一下这两者的区别:
|
属性 |
Char |
Varchar |
|
值域大小 |
最长字符数是255(不是字节),不管什么编码,超过此值则自动截取255个字符保存并没有报错。 |
65535个字节,开始两位存储长度,超过255个字符,用2位储存长度,否则1位,具体字符长度根据编码来确定,如utf8 则字符最长是21845个 |
|
如何处理字符串末尾空格 |
去掉末尾空格,取值出来比较的时候自动加上进行比较 |
Version<=4.1,字符串末尾空格被删掉,version>5.0则保留 |
|
储存空间 |
固定空间,比喻char(10)不管字符串是否有10个字符都分配10个字符的空间 |
Varchar内节约空间,但更新可能发生变化,若varchar(10),开始若储存5个字符,当update成7个时有MyISAM可能把行拆开,innodb可能分页,这样开销就增大 |
|
适用场合 |
适用于存储很短或固定或长度相似字符,如MD5加密的密码char(33)、昵称char(8)等 |
当最大长度远大于平均长度并且发生更新的时候。 |
注意当一些英文或数据的时候,最好用每个字符用字节少的类型,如latin1
-
整型、整形优先原则
Tinyint、smallint、mediumint、int、bigint,分别需要8、16、24、32、64。
值域范围:-2n-1~ 2n-1-1
很多程序员在设计数据表的时候很习惯的用int,压根不考虑这个问题
笔者建议:能用tinyint的绝不用smallint
误区:int(1) 和int(11)是一样的,唯一区别是mysql客户端显示的时候显示多少位。
整形优先原则:能用整形的不用其他类型替换,如ip可以转换成整形保存,如商品价格‘50.00元’则保存成50 - 精确度与空间的转换。在存储相同数值范围的数据时,浮点数类型通常都会比DECIMAL类型使用更少的空间。FLOAT字段使用4 字节存储 数据。DOUBLE类型需要8 个字节并拥有更高的精确度和更大的数值范围,DECIMAL类型的数据将会转换成DOUBLE类型。
sql语句优化
mysql> create table one (
id smallint(10) not null auto_increment primary key,
username char(8) not null,
password char(4) not null,
`level` tinyint (1) default 0,
last_login char(15) not null,
index (username,password,last_login)
) engine=innodb;
这是test表,其中id是主键,多列索引(username,password,last_login),里面有10000多条数据. | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+ | one | 0 | PRIMARY | 1 | id | A |20242 | NULL | NULL | | BTREE | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+ | one | 1 | username | 1 | username | A |10121 | NULL | NULL | | BTREE | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+ | one | 1 | username | 2 | password | A |10121 | NULL | NULL | YES | BTREE | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+ | one | 1 | username | 3 | last_login | A |20242 | NULL | NULL | | BTREE | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+
最左前缀原则
定义:最左前缀原则指的的是在sql where 子句中一些条件或表达式中出现的列的顺序要保持和多索引的一致或以多列索引顺序出现,只要 出现非顺序出现、断层都无法利用到多列索引。
举例说明:上面给出一个多列索引(username,password,last_login),当三列在where中出现的顺序如(username,password,last_login)、 (username,password)、(username)才能用到索引,如下面几个顺序(password,last_login)、(passwrod)、(last_login)---这三者不 从username开始,(username,last_login)---断层,少了password,都无法利用到索引。因为B+tree多列索引保存的顺序是按照索引创 建的顺序,检索索引时按照此顺序检索
测试:以下测试不精确,这里只是说明如何才能正确按照最左前缀原则使用索引。还有的是以下的测试用的时间0.00sec看不出什么时间区 别,因为数据量只有20003条,加上没有在实体机上运行,很多未可预知的影响因素都没考虑进去。当在大数据量,高并发的时候,最左前 缀原则对与提高性能方面是不可否认的。
Ps:最左前缀原则中where字句有or出现还是会遍历全表
能正确的利用索引
-
Where子句表达式 顺序是(username)
mysql> explain select * from one where username='abgvwfnt';
+----+-------------+-------+------+---------------+----------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref |rows | Extra |
+----+-------------+-------+------+---------------+----------+---------+-------+------+-------------+
| 1 | SIMPLE | one | ref | username | username | 24 | const |5 | Using where |
+----+-------------+-------+------+---------------+----------+---------+-------+------+-------------+
1 row in set (0.00 sec) -
Where子句表达式 顺序是(username,password)
mysql> explain select * from one where username='abgvwfnt' and password='123456';
+----+-------------+-------+------+---------------+----------+---------+-------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+----------+---------+-------------+------+-------------+
| 1 | SIMPLE | one | ref | username | username | 43 | const,const | 1 | Using where |
+----+-------------+-------+------+---------------+----------+---------+-------------+------+-------------+
1 row in set (0.00 sec) -
Where子句表达式 顺序是(username,password, last_login)
mysql> explain select * from one where username='abgvwfnt' and password='123456'and last_login='1338251170';
+----+-------------+-------+------+---------------+----------+---------+-------------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref| rows | Extra |
+----+-------------+-------+------+---------------+----------+---------+-------------------+------+-------------+
| 1 | SIMPLE | one | ref | username | username | 83 | const,const,const | 1 | Using where |
+----+-------------+-------+------+---------------+----------+---------+-------------------+------+-------------+
1 row in set (0.00 sec)
上面可以看出type=ref 是多列索引,key_len分别是24、43、83,这说明用到的索引分别是(username), (username,password), (username,password, last_login );row分别是5、1、1检索的数据行都很少,因为这三个查询都按照索引前缀原则,可以利用到 索引。
不能正确的利用索引
-
Where子句表达式 顺序是(password, last_login)
mysql> explain select * from one where password='123456'and last_login='1338251170';
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows| Extra |
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
| 1 | SIMPLE | one | ALL | NULL | NULL | NULL | NULL | 20146 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
1 row in set (0.00 sec) -
Where 子句表达式顺序是(last_login)
mysql> explain select * from one where last_login='1338252525';
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows| Extra |
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
| 1 | SIMPLE | one | ALL | NULL | NULL | NULL | NULL | 20146 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
1 row in set (0.00 sec)
以上的两条语句都不是以username开始,这样是用不了索引,通过type=all(全表扫描),key_len=null,rows都很大20146
Ps:one表里只有20003条数据,为什么出现20146,这是优化器对表的一个估算值,不精确的。 -
Where 子句表达式虽然顺序是(username,password, last_login)或(username,password)但第一个是有范围’<’、’>’,’<=’, ’>=’等出现
mysql> explain select * from one where username>'abgvwfnt' and password ='123456'and last_login='1338251170';
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows| Extra |
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
| 1 | SIMPLE | one | ALL | username | NULL | NULL | NULL | 20146 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
1 row in set (0.00 sec)
这个查询很明显是遍历所有表,一个索引都没用到,非第一列出现范围(password列或last_login列),则能利用索引到首先出 现范围的一列,也就是“where username='abgvwfnt' and password >'123456'and last_login='1338251170';”或 “where username='abgvwfnt' and password >'123456'and last_login<'1338251170';”索引长度ref_len=43,索引检索到 password列,所以考虑多列索引的时候把那些查询语句用的比较的列放在最后(或非第一位)。 -
断层,即是where顺序(username, last_login)
mysql> explain select * from one where username='abgvwfnt' and last_login='1338252525';
+----+-------------+-------+------+---------------+----------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+----------+---------+-------+------+-------------+
| 1 | SIMPLE | one | ref | username | username | 24 | const |5 | Using where |
+----+-------------+-------+------+---------------+----------+---------+-------+------+-------------+
1 row in set (0.00 sec)
注意这里的key_len=24=8*3(8是username的长度,3是utf8编码),rows=5,和下面一条sql语句搜索出来一样mysql> select * from one where username='abgvwfnt';
+-------+----------+----------+-------+------------+
| id | username | password | level | last_login |
+-------+----------+----------+-------+------------+
| 3597 | abgvwfnt | 234567 | 0 | 1338251420 |
| 7693 | abgvwfnt | 456789 | 0 | 1338251717 |
| 11789 | abgvwfnt | 456789 | 0 | 1338251992 |
| 15885 | abgvwfnt | 456789 | 0 | 1338252258 |
| 19981 | abgvwfnt | 456789 | 0 | 1338252525 |
+-------+----------+----------+-------+------------+
5 rows in set (0.00 sec)mysql> select * from one where username='abgvwfnt' and last_login='1338252525';
+-------+----------+----------+-------+------------+
| id | username | password | level | last_login |
+-------+----------+----------+-------+------------+
| 19981 | abgvwfnt | 456789 | 0 | 1338252525 |
+-------+----------+----------+-------+------------+
1 row in set (0.00 sec)
这个就是要的返回结果,所以可以知道断层(username,last_login),这样只用到username索引,把用到索引的数据再重新检查 last_login条件,这个相对全表查询来说还是有性能上优化,这也是很多sql优化文章中提到的where 范围查询要放在最后 (这不绝对,但可以利用一部分索引) -
如果一个查询where子句中确实不需要password列,那就用“补洞”。
mysql> select distinct(password) from one;
+----------+
| password |
+----------+
| 234567 |
| 345678 |
| 456789 |
| 123456 |
+----------+
4 rows in set (0.08 sec)可以看出password列中只有这几个值,当然在现实中不可能密码有这么多一样的,再说数据也可能不断更新,这里只是举例说明补 洞的方法
mysql> explain select * from one where username='abgvwfnt' and password in('123456','234567','345678','456789') and last_login='1338251170';
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+
| 1 | SIMPLE | one | range | username | username| 83 | NULL |4 | Using where |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+
1 row in set (0.00 sec)
可以看出ref=83 所有的索引都用到了,type=range是因为用了in子句。 这个被“补洞”列中的值应该是有限的,可预知的,如性别,其值只有男和女(加多一个不男不女也无妨)。 “补洞”方法也有瓶颈,当很多列,且需要补洞的相应列(可以多列)的值虽有限但很多(如中国城市)的时候,优化器在优化时组合 起来的数量是很大,这样的话就要做好基准测试和性能分析,权衡得失,取得一个合理的优化方法。 -
like
mysql> explain select * from one where username like 'abgvwfnt%';
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref |
rows | Extra |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+
| 1 | SIMPLE | one | range | username | username | 24 | NULL | 5 | Using where |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+
1 row in set (0.00 sec)mysql> explain select * from one where username like '%abgvwfnt%';
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows| Extra |
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
| 1 | SIMPLE | one | ALL | NULL | NULL | NULL | NULL | 20259 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
1 row in set (0.01 sec)
对比就知道like操作abgvwfnt%能用到索引,%abgvwfnt%用不到
ORDER BY 优化
-
filesort优化算法
在mysql version()<4.1之前,优化器采用的是filesort第一种优化算法,先提取键值和指针,排序后再去提取数据,前后要搜索数据 两次,第一次若能使用索引则使用,第二次是随机读(当然不同引擎也不同)。mysql version()>=4.1,更新了一个新算法,就是在第 一次读的时候也把selcet的列也读出来,然后在sort_buffer_size中排序(不够大则建临时表保存排序顺序),这算法只需要一次读 取数据。所以有这个广为人传的一个优化方法,那就是增大sort_buffer_size。Filesort第二种算法要用到更多空间, sort_buffer_size不够大反而会影响速度,所以mysql开发团队定了个变量max_length_for_sort_data,当算法中读出来的需要列 的数据的大小超过该变量的值才使用,所以一般性能分析的时候会尝试把max_length_for_sort_data改小。
-
单独order by 用不了索引,索引考虑加where 或加limit
先建一个索引(last_login),建的过程就不给出了
mysql> explain select * from one order by last_login desc;
+----+-------------+-------+------+---------------+------+---------+------+-------+----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows
| Extra |
+----+-------------+-------+------+---------------+------+---------+------+-------+----------------+
| 1 | SIMPLE | one | ALL | NULL | NULL | NULL | NULL | 2046
3 | Using filesort |
+----+-------------+-------+------+---------------+------+---------+------+-------+----------------+
1 row in set (0.00 sec)mysql> explain select * from one order by last_login desc limit 10;
+----+-------------+-------+-------+---------------+------------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref
| rows | Extra |
+----+-------------+-------+-------+---------------+------------+---------+------+------+-------+
| 1 | SIMPLE | one | index | NULL | last_login | 4 | NULL
| 10 | |
+----+-------------+-------+-------+---------------+------------+---------+------+------+-------+
1 row in set (0.00 sec)
开始没limit查询是遍历表的,加了limit后,索引可以使用,看key_len 和key -
where + orerby 类型,where满足最左前缀原则,且orderby的列和where子句用到的索引的列的子集。即是(a,b,c)索引, where满足最左前缀原则且order by中列a、b、c的任意组合
mysql> explain select * from one where username='abgvwfnt' and password ='123456
' and last_login='1338251001' order by password desc,last_login desc;
+----+-------------+-------+------+---------------+----------+---------+-------------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+----------+---------+-------------------+------+-------------+
| 1 | SIMPLE | one | ref | username | username | 83 | const,const,const | 1 | Using where |
+----+-------------+-------+------+---------------+----------+---------+-------------------+------+-------------+
1 row in set (0.00 sec)mysql> explain select * from one where username='abgvwfnt' and password ='123456
' and last_login='1338251001' order by password desc,level desc;
+----+-------------+-------+------+---------------+----------+---------+-------------------+------+----------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref| rows | Extra |
+----+-------------+-------+------+---------------+----------+---------+-------------------+------+-----------------------------+
| 1 | SIMPLE | one | ref | username | username | 83 | const,const,const | 1 | Using where; Using filesort |
+----+-------------+-------+------+---------------+----------+---------+-------------------+------+-----------------------------+1 row in set (0.00 sec)
上面两条语句明显的区别是多了一个非索引列level的排序,在extra这列对了Using filesort。 笔者测试结果:where满足最左前缀且order by中的列是该多列索引的子集时(也就是说orerby中没最左前缀原则限制),不管是否 有asc ,desc混合出现,都能用索引来满足order by。因为篇幅比较大,这里就不一一列出。Ps:很优化博文都说order by中的列要where中出现的列(是索引)的顺序一致,笔者认为不够严谨。
-
where + orerby+limit
这个其实也差不多,只要where最左前缀,orderby也正确,limit在此影响不大
如何考虑ORDER BY来建索引
这个回归到创建索引的问题来,在比较常用的oder by的列和where中常用的列建立多列索引,这样优化起来的广度和扩张性都比较好, 当然如果要考虑UNION、JOIN、COUNT、IN等进来就复杂很多了
隔离列
隔离列是只查询语句中把索引列隔离出来,也就是说不能在语句中把列包含进表达式中,如id+1=2、inet_aton('210.38.196.138')--- ip转换成整数、convert(123,char(3))---数字转换成字符串、date函数等mysql内置的大多函数。
非隔离列影响性能很大甚至是致命的,这也就是赶集网石展的《三十六军规》中的一条,虽然他没说明是隔离列。 以下就测试一下:
首先建立一个索引(last_login ),这里就不给出建立的代码了,且把last_login改成整型(这里只是为了方便测试,并不是影响条件) mysql> explain select * from one where last_login = 8388605;
+----+-------------+-------+------+---------------+------------+---------+-------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------------+---------+-------+-------+-------------+
| 1 | SIMPLE | one | ref | last_login | last_login | 3 | const | 1 | Using where |
+----+-------------+-------+------+---------------+------------+---------+-------+-------+-------------+
1 row in set, 1 warning (0.00 sec)
容易看出建的索引已起效
mysql> explain select * from one where last_login +1= 8388606 ;
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
| 1 | SIMPLE | one | ALL | NULL | NULL | NULL | NULL | 2049
7 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
1 row in set (0.00 sec)
last_login +1=8388608非隔离列的出现导致查找的列20197,说明是遍历整张表且索引不能使用。
这是因为这条语句要找出所有last_login的数据,然后+1再和20197比较,优化器在这方面比较差,性能很差。
所以要尽可能的把列隔离出来,如last_login +1= 8388606改成login_login=8388607,或者把计算、转换等操作先用php函数处理
过再传递给mysql服务器
OR、IN、UNION ALL,可以尝试用UNION ALL
-
or会遍历表就算有索引
mysql> explain select * from one where username = 'abgvwfnt' or password='123456';
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows| Extra |
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
| 1 | SIMPLE | one | ALL | username | NULL | NULL | NULL | 20259 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
1 row in set (0.00 sec) -
对于in,这个是有争议的,网上很多优化方案中都提到尽量少用in,这不全面,其实在in里面如果是常量的话,可一大胆的用in, 这个也是赶集网石展、阿里hellodab的观点(笔者从微博中获知)。应用hellodab一句话“MySQL用IN效率不好,通常是指in中 嵌套一个子查询,因为MySQL的查询重写可能会产生一个不好的执行计划,而如果in里面是常量的话,我认为性能没有任何问题, 可以放心使用”---------当然对于这个比较的话,没有实战数据的话很难辩解,就算有,影响性能的因素也很多,也许会每个 dba都有不同的测试结果.这也签名最左前缀中“补洞”一个方法
-
UNION All 直接返回并集,可以避免去重的开销。之所说“尝试”用UNION All 替代 OR来优化sql语句,因为这不是一直能优化的了, 这里只是作为一个方法去尝试。
索引选择性
索引选择性是不重复的索引值也叫基数(cardinality)表中数据行数的比值,索引选择性=基数/数据行,基数可以通过 “show index from 表名”查看。高索引选择性的好处就是mysql查找匹配的时候可以过滤更多的行,唯一索引的选择性最佳,值为1。 那么对于非唯一索引或者说要被创建索引的列的数据内容很长,那就要选择索引前缀。这里就简单说明一下: mysql> select count(distinct(username))/count() from one;
+------------------------------------+
| count(distinct(username))/count() |
+------------------------------------+
| 0.2047 |
+------------------------------------+
1 row in set (0.09 sec)
count(distinct(username))/count()就是索引选择性,这里0.2太小了。假如username列数据很长,则可以通过 select count(distinct(concat(first_name, left(last_name, N))/count() from one;测试出接近1的索引选择性, 其中N是索引的长度,穷举法去找出N的值,然后再建索引。
重复或多余索引
很多phper开始都以为建索引相对多点性能就好点,压根没考虑到有些索引是重复的,比如建一个(username),(username,password), (username,password,last_login),很明显第一个索引是重复的,因为后两者都能满足其功能。要有个意识就是,在满足功能需求的 情况下建最少索引。对于INNODB引擎的索引来说,每次修改数据都要把主键索引,辅助索引中相应索引值修改,这可能会出现大量数 据迁移,分页,以及碎片的出现。
系统配置与维护优化
重要的一些变量
- key_buffer_size索引块缓存区大小, 针对MyISAM存储引擎,该值越大,性能越好.但是超过操作系统能承受的最大值,反而会使mysql变得不稳定. ----这是很重要的参数
- sort_buffer_size 这是索引在排序缓冲区大小,若排序数据大小超过该值,则创建临时文件,注意和MyISAM_sort_buffer_size的区别----这是很重要的参数
- read_rnd_buffer_size当排序后按排序后的顺序读取行时,则通过该缓冲区读取行,避免搜索硬盘。将该变量设置为较大的值可以大大改进ORDER BY的性能。但是,这是为每个客户端分配的缓冲区,因此你不应将全局变量设置为较大的值。相反,只为需要运行大查询的客户端更改会话变量
- join_buffer_size用于表间关联(join)的缓存大小
- tmp_table_size缓存表的大小
- table_cache允许 MySQL 打开的表的最大个数,并且这些都cache在内存中
- delay_key_write针对MyISAM存储引擎,延迟更新索引.意思是说,update记录时,先将数据up到磁盘,但不up索引,将索引存在内存里,当表关闭时,将内存索引,写到磁盘
更多参数查看:http://www.phpben.com/?post=70
OPTIMIZE、ANALYZE、CHECK、REPAIR维护操作
-
optimize 数据在插入,更新,删除的时候难免一些数据迁移,分页,之后就出现一些碎片,久而久之碎片积累起来影响性能, 这就需要DBA定期的优化数据库减少碎片,这就通过optimize命令。如对MyISAM表操作:optimize table 表名
对于InnoDB表是不支持optimize操作,否则提示“Table does not support optimize, doing recreate + analyze instead”, 当然也可以通过命令:alter table one type=innodb; 来替代。
- Analyze 用来分析和存储表的关键字的分布,使得系统获得准确的统计信息,影响 SQL 的执行计划的生成。对于数据基本没有发生 变化的表,是不需要经常进行表分析的。但是如果表的数据量变化很明显,用户感觉实际的执行计划和预期的执行计划不 同的时候, 执行一次表分析可能有助于产生预期的执行计划。Analyze table 表名
- Check检查表或者视图是否存在错误,对 MyISAM 和 InnoDB 存储引擎的表有作用。对于 MyISAM 存储引擎的表进行表检查, 也会同时更新关键字统计数据
- Repair optimize需要有足够的硬盘空间,否则可能会破坏表,导致不能操作,那就要用上repair,注意INNODB不支持repair操作
以上的操作出现的都是如下这是check +----------+-------+--------------+-------------+
| Table | Op | Msg_type| Msg_text |
+----------+-------+--------------+-------------+
| test.one | check | status | OK |
+----------+-------+--------------+-------------+
其中op是option 可以是repair check optimize,msg_type 表示信息类型,msg_text 表示信息类型,这里就说明表的状态正常。 如在innodb表使用repair就出现note | The storage engine for the table doesn't support repair
注意:以上操作最好在数据库访问量最低的时候操作,因为涉及到很多表锁定,扫描,数据迁移等操作,否则可能导致一些功能无法 正常使用甚至数据库崩溃。
表结构的更新与维护
- 改表结构。当要在数据量千万级的数据表中使用alter更改表结构的时候,这是一个棘手问题。一种方法是在低并发低访问量的时 候用平常的alter更改表。另外一种就是建另一个与要修改的表,这个表除了要修改的结构属性外其他的和原表一模一样,这样就 能得到一个相应的.frm文件,然后用flush with read lock 锁定读,然后覆盖用新建的.frm文件覆盖原表的.frm, 最后unlock table 释放表。
- 建立新的索引。一般方法这里不说。
- 创建没索引的a表,导入数据形成.MYD文件。
- 创建包括索引b表,形成.FRM和.MYI文件
- 锁定读写
- 把b表的.FRM和.MYI文件改成a表名字
- 解锁
- 用repair创建索引。
这个方法对于大表也是很有效的。这也是为什么很多dba坚持说“先导数据库在建索引,这样效率更快”
- 定期检查mysql服务器 定期使用show status、show processlist等命令检查数据库。这里就不细说,这说起来也篇幅是比较大的,笔者对这个也不是很了解
第四部分:图说mysql查询执行流程
1. 查询缓存,判断sql语句是否完全匹配,再判断是否有权限,两个判断为假则到解析器解析语句,为真则提取数据结果返回给用户。 2. 解析器解析。解析器先词法分析,语法分析,检查错误比如引号有没闭合等,然后生成解析树。 3. 预处理。预处理解决解析器无法决解的语义,如检查表和列是否存在,别名是否有错,生成新的解析树。 4. 优化器做大量的优化操作。 5. 生成执行计划。 6. 查询执行引擎,负责调度引擎获取相应数据 7. 返回结果。
原文链接:http://www.phpben.com/?post=74
参考:
http://www.cnblogs.com/hustcat/archive/2009/10/28/1591648.htmlhttp://www.cnblogs.com/oldhorse/archive/2009/11/16/1604009.htmlhttp://blog.csdn.net/zuiaituantuan/article/details/5909334 http://www.codinglabs.org/html/theory-of-mysql-index.html http://isky000.com/database/mysql_order_by_implementhttp://dev.mysql.com/doc/refman/5.0/en/server-system-variables.html http://www.docin.com/p-211669085.html
http://database.51cto.com/art/200910/156685.htm
索引是快速搜索的关键。MySQL索引的建立对于MySQL的高效运行是很重要的。下面介绍几种常见的MySQL索引类型。
在数据库表中,对字段建立索引可以大大提高查询速度。假如我们创建了一个 mytable表:
- CREATE TABLE mytable(
- ID INT NOT NULL,
- username VARCHAR(16) NOT NULL
- );
我们随机向里面插入了10000条记录,其中有一条:5555, admin。
在查找username="admin"的记录 SELECT * FROM mytable WHERE username='admin';时,如果在username上已经建立了索引,MySQL无须任何扫描,即准确可找到该记录。相反,MySQL会扫描所有记录,即要查询10000条记录。
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索包含多个列。
MySQL索引类型包括:
(1)普通索引
这是最基本的索引,它没有任何限制。它有以下几种创建方式:
◆创建索引
- CREATE INDEX indexName ON mytable(username(length));
如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length,下同。
◆修改表结构
- ALTER mytable ADD INDEX [indexName] ON (username(length))
◆创建表的时候直接指定
- CREATE TABLE mytable(
- ID INT NOT NULL,
- username VARCHAR(16) NOT NULL,
- INDEX [indexName] (username(length))
- );
删除索引的语法:
- DROP INDEX [indexName] ON mytable;
(2)唯一索引
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。它有以下几种创建方式:
◆创建索引
- CREATE UNIQUE INDEX indexName ON mytable(username(length))
◆修改表结构
- ALTER mytable ADD UNIQUE [indexName] ON (username(length))
◆创建表的时候直接指定
- CREATE TABLE mytable(
- ID INT NOT NULL,
- username VARCHAR(16) NOT NULL,
- UNIQUE [indexName] (username(length))
- );
(3)主键索引
它是一种特殊的唯一索引,不允许有空值。一般是在建表的时候同时创建主键索引:
- CREATE TABLE mytable(
- ID INT NOT NULL,
- username VARCHAR(16) NOT NULL,
- PRIMARY KEY(ID)
- );
当然也可以用 ALTER 命令。记住:一个表只能有一个主键。
(4)组合索引
为了形象地对比单列索引和组合索引,为表添加多个字段:
- CREATE TABLE mytable(
- ID INT NOT NULL,
- username VARCHAR(16) NOT NULL,
- city VARCHAR(50) NOT NULL,
- age INT NOT NULL
- );
为了进一步榨取MySQL的效率,就要考虑建立组合索引。就是将 name, city, age建到一个索引里:
- ALTER TABLE mytable ADD INDEX name_city_age (name(10),city,age);
建表时,usernname长度为 16,这里用 10。这是因为一般情况下名字的长度不会超过10,这样会加速索引查询速度,还会减少索引文件的大小,提高INSERT的更新速度。
如果分别在 usernname,city,age上建立单列索引,让该表有3个单列索引,查询时和上述的组合索引效率也会大不一样,远远低于我们的组合索引。虽然此时有了三个索引,但MySQL只能用到其中的那个它认为似乎是最有效率的单列索引。
建立这样的组合索引,其实是相当于分别建立了下面三组组合索引:
- usernname,city,age
- usernname,city
- usernname
为什么没有 city,age这样的组合索引呢?这是因为MySQL组合索引“最左前缀”的结果。简单的理解就是只从最左面的开始组合。并不是只要包含这三列的查询都会用到该组合索引,下面的几个SQL就会用到这个组合索引:
- SELECT * FROM mytable WHREE username="admin" AND city="郑州"
- SELECT * FROM mytable WHREE username="admin"
而下面几个则不会用到:
- SELECT * FROM mytable WHREE age=20 AND city="郑州"
- SELECT * FROM mytable WHREE city="郑州"
(5)建立索引的时机
到这里我们已经学会了建立索引,那么我们需要在什么情况下建立索引呢?一般来说,在WHERE和JOIN中出现的列需要建立索引,但也不完全如此,因为MySQL只对<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE才会使用索引。例如:
- SELECT t.Name
- FROM mytable t LEFT JOIN mytable m
- ON t.Name=m.username WHERE m.age=20 AND m.city='郑州'
此时就需要对city和age建立索引,由于mytable表的userame也出现在了JOIN子句中,也有对它建立索引的必要。
刚才提到只有某些时候的LIKE才需建立索引。因为在以通配符%和_开头作查询时,MySQL不会使用索引。例如下句会使用索引:
- SELECT * FROM mytable WHERE username like'admin%'
而下句就不会使用:
- SELECT * FROM mytable WHEREt Name like'%admin'
因此,在使用LIKE时应注意以上的区别。
(6)索引的不足之处
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:
◆虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
◆建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快。
索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询语句。
(7)使用索引的注意事项
使用索引时,有以下一些技巧和注意事项:
◆索引不会包含有NULL值的列
只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。
◆使用短索引
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
◆索引列排序
MySQL查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
◆like语句操作
一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引而like “aaa%”可以使用索引。
◆不要在列上进行运算
- select * from users where YEAR(adddate)<2007;
将在每个行上进行运算,这将导致索引失效而进行全表扫描,因此我们可以改成
- select * from users where adddate<‘2007-01-01’;
◆不使用NOT IN和<>操作
以上,就对其中MySQL索引类型进行了介绍。
http://blog.csdn.net/aeolus_pu/article/details/9041487
由于开发人员对索引认识不深或忽略,还有版本不同等问题,在生产环境中创建表失败,引发了一些问题。归纳了一下
测试环境
mysql> select version();
+------------+
| version() |
+------------+
| 5.5.31-log |
+------------+
1 row in set (0.01 sec)
innodb 引擎
mysql> CREATE TABLE `meta_topic_scan` ( `domain` varchar(257) NOT NULL, `topic_name` varchar(200) NOT NULL, `topic_url` varchar(200) NOT NULL, `topic_pv` int(11) DEFAULT'0', `topic_uv` int(11) DEFAULT '0', PRIMARY KEY (`domain`,`topic_url`) ) ENGINE=innodb DEFAULT CHARSET=utf8;
ERROR 1071 (42000): Specified key was too long; max key length is 767 bytes
innodb 单列索引长度不能超过767 bytes,联合索引限制是3072 bytes 。对于创建innodb的组合索引中,如果各个列中的长度有单个超过767 bytes,也会创建失败;
myisam 引擎
创建复合索引:
mysql> CREATE TABLE `meta_topic_scan` (
-> `domain` varchar(200) NOT NULL,
-> `topic_name` varchar(200) NOT NULL,
-> `topic_url` varchar(200) NOT NULL,
-> `topic_pv` int(11) DEFAULT '0',
-> `topic_uv` int(11) DEFAULT '0',
-> PRIMARY KEY (`domain`,`topic_name`,`topic_url`)
-> ) ENGINE=myisam DEFAULT CHARSET=utf8 ;
ERROR 1071 (42000): Specified key was too long; max key length is 1000 bytes
创建单列索引:
mysql> CREATE TABLE `meta_topic_scan` (
-> `domain` varchar(334) NOT NULL,
-> `topic_name` varchar(200) NOT NULL,
-> `topic_url` varchar(200) NOT NULL,
-> `topic_pv` int(11) DEFAULT '0',
-> `topic_uv` int(11) DEFAULT '0',
-> PRIMARY KEY (`domain`)
-> ) ENGINE=myisam DEFAULT CHARSET=utf8 ;
ERROR 1071 (42000): Specified key was too long; max key length is 1000 bytes
由此可知:myisam 单列索引长度、所创建的复合索引长度和都不能超过1000 bytes,否则会报错,创建失败。
另外不同字符集占用不同字节:latin一个字符占1 bytes,utf8存储一个字符占3 bytes, gbk存储一个字符2 bytes
扩展: innodb复合索引长度为什么是3072
我们知道InnoDB一个page的默认大小是16k。由于是Btree组织,要求叶子节点上一个page至少要包含两条记录(否则就退化链表了)。
所以一个记录最多不能超过8k。
又由于InnoDB的聚簇索引结构,一个二级索引要包含主键索引,因此每个单个索引不能超过4k (极端情况,pk和某个二级索引都达到这个限制)。
由于需要预留和辅助空间,扣掉后不能超过3500,取个“整数”就是(1024*3)。
单列索引限制
上面有提到单列索引限制767,起因是256×3-1。这个3是字符最大占用空间(utf8)。但是在5.5以后,开始支持4个字节的uutf8。255×4>767, 于是增加了一个参数叫做 innodb_large_prefix。
这个参数默认值是OFF。当改为ON时,允许列索引最大达到3072。
如下效果(5.5):

扩展参考资料 http://dinglin.iteye.com/blog/1681332
http://leyteris.iteye.com/blog/825799
最近对两个开源系统进行反向工程ER图生成后,对比发现一个系统其中一个表中的复合索引的列个数对查询的效率有较大的影响~~
于是上网查了下相关的资料:(关于复合索引优化的)
两个或更多个列上的索引被称作复合索引。
利用索引中的附加列,您可以缩小搜索的范围,但使用一个具有两列的索引不同于使用两个单独的索引。复合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按名字对有相同姓氏的人进行排序。如果您知道姓,电话簿将非常有用;如果您知道姓和名,电话簿则更为有用,但如果您只知道名不姓,电话簿将没有用处。
所以说创建复合索引时,应该仔细考虑列的顺序。对索引中的所有列执行搜索或仅对前几列执行搜索时,复合索引非常有用;仅对后面的任意列执行搜索时,复合索引则没有用处。
如:建立 姓名、年龄、性别的复合索引。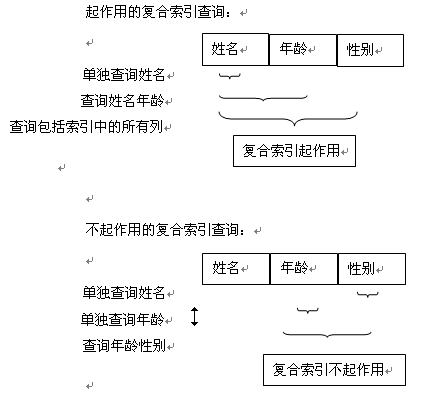
复合索引的建立原则:
如果您很可能仅对一个列多次执行搜索,则该列应该是复合索引中的第一列。如果您很可能对一个两列索引中的两个列执行单独的搜索,则应该创建另一个仅包含第二列的索引。
如上图所示,如果查询中需要对年龄和性别做查询,则应当再新建一个包含年龄和性别的复合索引。
包含多个列的主键始终会自动以复合索引的形式创建索引,其列的顺序是它们在表定义中出现的顺序,而不是在主键定义中指定的顺序。在考虑将来通过主键执行的搜索,确定哪一列应该排在最前面。
请注意,创建复合索引应当包含少数几个列,并且这些列经常在select查询里使用。在复合索引里包含太多的列不仅不会给带来太多好处。而且由于使用相当多的内存来存储复合索引的列的值,其后果是内存溢出和性能降低。
复合索引对排序的优化:
复合索引只对和索引中排序相同或相反的order by 语句优化。
在创建复合索引时,每一列都定义了升序或者是降序。如定义一个复合索引:
- CREATE INDEX idx_example
- ON table1 (col1 ASC, col2 DESC, col3 ASC)
其中 有三列分别是:col1 升序,col2 降序, col3 升序。现在如果我们执行两个查询
1:Select col1, col2, col3 from table1 order by col1 ASC, col2 DESC, col3 ASC
和索引顺序相同
2:Select col1, col2, col3 from table1 order by col1 DESC, col2 ASC, col3 DESC
和索引顺序相反
查询1,2 都可以别复合索引优化。
如果查询为:
Select col1, col2, col3 from table1 order by col1 ASC, col2 ASC, col3 ASC
排序结果和索引完全不同时,此时的 查询不会被复合索引优化。
查询优化器在在where查询中的作用:
如果一个多列索引存在于 列 Col1 和 Col2 上,则以下语句:Select * from table where col1=val1 AND col2=val2 查询优化器会试图通过决定哪个索引将找到更少的行。之后用得到的索引去取值。
1. 如果存在一个多列索引,任何最左面的索引前缀能被优化器使用。所以联合索引的顺序不同,影响索引的选择,尽量将值少的放在前面。
如:一个多列索引为 (col1 ,col2, col3)
那么在索引在列 (col1) 、(col1 col2) 、(col1 col2 col3) 的搜索会有作用。
- SELECT * FROM tb WHERE col1 = val1
- SELECT * FROM tb WHERE col1 = val1 and col2 = val2
- SELECT * FROM tb WHERE col1 = val1 and col2 = val2 AND col3 = val3
2. 如果列不构成索引的最左面前缀,则建立的索引将不起作用。
如:
- SELECT * FROM tb WHERE col3 = val3
- SELECT * FROM tb WHERE col2 = val2
- SELECT * FROM tb WHERE col2 = val2 and col3=val3
3. 如果一个 Like 语句的查询条件不以通配符起始则使用索引。
如:%车 或 %车% 不使用索引。
车% 使用索引。
索引的缺点:
1. 占用磁盘空间。
2. 增加了插入和删除的操作时间。一个表拥有的索引越多,插入和删除的速度越慢。如 要求快速录入的系统不宜建过多索引。
下面是一些常见的索引限制问题
1、使用不等于操作符(<>, !=)
下面这种情况,即使在列dept_id有一个索引,查询语句仍然执行一次全表扫描
select * from dept where staff_num <> 1000;
但是开发中的确需要这样的查询,难道没有解决问题的办法了吗?
有!
通过把用 or 语法替代不等号进行查询,就可以使用索引,以避免全表扫描:上面的语句改成下面这样的,就可以使用索引了。
- select * from dept shere staff_num < 1000 or dept_id > 1000;
2、使用 is null 或 is not null
使用 is null 或is nuo null也会限制索引的使用,因为数据库并没有定义null值。如果被索引的列中有很多null,就不会使用这个索引(除非索引是一个位图索引,关于位图索引,会在以后的blog文章里做详细解释)。在sql语句中使用null会造成很多麻烦。
解决这个问题的办法就是:建表时把需要索引的列定义为非空(not null)
3、使用函数
如果没有使用基于函数的索引,那么where子句中对存在索引的列使用函数时,会使优化器忽略掉这些索引。下面的查询就不会使用索引:
- select * from staff where trunc(birthdate) = '01-MAY-82';
但是把函数应用在条件上,索引是可以生效的,把上面的语句改成下面的语句,就可以通过索引进行查找。
- select * from staff where birthdate < (to_date('01-MAY-82') + 0.9999);
4、比较不匹配的数据类型
比较不匹配的数据类型也是难于发现的性能问题之一。
下面的例子中,dept_id是一个varchar2型的字段,在这个字段上有索引,但是下面的语句会执行全表扫描。
- select * from dept where dept_id = 900198;
这是因为oracle会自动把where子句转换成to_number(dept_id)=900198,就是3所说的情况,这样就限制了索引的使用。
把SQL语句改为如下形式就可以使用索引
- select * from dept where dept_id = '900198';
恩,这里还有要注意的:
来自老王的博客(http://hi.baidu.com/thinkinginlamp/blog/item/9940728be3986015c8fc7a85.html)
比方说有一个文章表,我们要实现某个类别下按时间倒序列表显示功能:
SELECT * FROM articles WHERE category_id = ... ORDER BY created DESC LIMIT ...
这样的查询很常见,基本上不管什么应用里都能找出一大把类似的SQL来,学院派的读者看到上面的SQL,可能会说SELECT *不好,应该仅仅查询需要的字段,那我们就索性彻底点,把SQL改成如下的形式:
SELECT id FROM articles WHERE category_id = ... ORDER BY created DESC LIMIT ...
我们假设这里的id是主键,至于文章的具体内容,可以都保存到memcached之类的键值类型的缓存里,如此一来,学院派的读者们应该挑不出什么毛病来了,下面我们就按这条SQL来考虑如何建立索引:
不考虑数据分布之类的特殊情况,任何一个合格的WEB开发人员都知道类似这样的SQL,应该建立一个”category_id, created“复合索引,但这是最佳答案不?不见得,现在是回头看看标题的时候了:MySQL里建立索引应该考虑数据库引擎的类型!
如果我们的数据库引擎是InnoDB,那么建立”category_id, created“复合索引是最佳答案。让我们看看InnoDB的索引结构,在InnoDB里,索引结构有一个特殊的地方:非主键索引在其BTree的叶节点上会额外保存对应主键的值,这样做一个最直接的好处就是Covering Index,不用再到数据文件里去取id的值,可以直接在索引里得到它。
如果我们的数据库引擎是MyISAM,那么建立"category_id, created"复合索引就不是最佳答案。因为MyISAM的索引结构里,非主键索引并没有额外保存对应主键的值,此时如果想利用上Covering Index,应该建立"category_id, created, id"复合索引。
唠完了,应该明白我的意思了吧。希望以后大家在考虑索引的时候能思考的更全面一点,实际应用中还有很多类似的问题,比如说多数人在建立索引的时候不从Cardinality(SHOW INDEX FROM ...能看到此参数)的角度看是否合适的问题,Cardinality表示唯一值的个数,一般来说,如果唯一值个数在总行数中所占比例小于20%的话,则可以认为Cardinality太小,此时索引除了拖慢insert/update/delete的速度之外,不会对select产生太大作用;还有一个细节是建立索引的时候未考虑字符集的影响,比如说username字段,如果仅仅允许英文,下划线之类的符号,那么就不要用gbk,utf-8之类的字符集,而应该使用latin1或者ascii这种简单的字符集,索引文件会小很多,速度自然就会快很多。这些细节问题需要读者自己多注意,我就不多说了。
http://itindex.net/detail/44489-mysql-%E7%B4%A2%E5%BC%95
B+树是一种经典的数据结构,由平衡树和二叉查找树结合产生,它是为磁盘或其它直接存取辅助设备而设计的一种平衡查找树,在B+树中,所有的记录节点都是按键值大小顺序存放在同一层的叶节点中,叶节点间用指针相连,构成双向循环链表,非叶节点(根节点、枝节点)只存放键值,不存放实际数据。下面看一个2层B+树的例子:
保持树平衡主要是为了提高查询性能,但为了维护树的平衡,成本也是巨大的,当有数据插入或删除时,需采用拆分节点、左旋、右旋等方法。B+树因为其高扇出性,所以具有高平衡性,通常其高度都在2~3层,查询时可以有效减少IO次数。B+树索引可以分为聚集索引(clustered index)和非聚集索引(即辅助索引,secondary index)。
聚集索引
InnoDB表时索引组织表,即表中数据按主键B+树存放,叶子节点直接存放数据,每张表只能有一个聚集索引。
辅助索引
索引组织表 VS 堆表
复合索引
alter table t add key idx_a_b(a,b);
=======================================
http://blog.csdn.net/signmem/article/details/12972127
query cache, mysql 5 开始附带的一个功能, 与引擎无关, 只与数据查询语法相关。
测试描述: 当前使用中是 MySQL-5.6.14 Linux RHEL6 64 位系统产生环境, 使用 INNODB 引擎, 分配 innodb 2g 内存空间
[root@TiYanPlat ~]# uname -a
Linux TiYanPlat 2.6.32-358.el6.x86_64 #1 SMP Tue Jan 29 11:47:41 EST 2013 x86_64 x86_64x86_64 GNU/Linux
mysql> select version();
+-----------+
| version() |
+-----------+
| 5.6.14 |
+-----------+
1 row in set (0.00 sec)
mysql> show variables like 'innodb_buffer_pool_size';
+-------------------------+------------+
| Variable_name | Value |
+-------------------------+------------+
| innodb_buffer_pool_size | 2147483648 |
+-------------------------+------------+
1 row in set (0.01 sec)
Query cache 功能:
利用 qeury_cache_size 定义内存大小, 内存用于把用户 SQL 放入内存中, 包括 SQL 语句, 包括SQL 语句执行的结果
假如下一次查询时使用相同的 SQL 语句, 则直接从内存中获得结果, 不再进行 SQL 分析, 不在进行磁盘 I/O 读数据。加速数据查询返回结果。
实现目标,开启 QCACHE 功能, 如 my.cnf 定义
query-cache-size=16777216
query-cache-type=ON
查询数据库中是否使用当前功能
mysql> show status like '%qcache%';
+-------------------------+----------+
| Variable_name | Value |
+-------------------------+----------+
| Qcache_free_blocks | 440 |
| Qcache_free_memory | 12306960 |
| Qcache_hits | 13176 |
| Qcache_inserts | 29777 |
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 45862 |
| Qcache_queries_in_cache | 2098 |
| Qcache_total_blocks | 4701 |
+-------------------------+----------+
8 rows in set (0.02 sec)
参数返回结果不再一一详细描述, 自行参考官方文档, 从上返回结果可以看到,使用中的数据库 SQL 命中率 (Qcache_hits) 并不理想,原因与业务有关。
SQL 分析一, 使用了 QUERY CACHE 的好处
原理, 利用 EXPLAIN 分析当前 SQL 执行计划, 利用 PROFILE 功能分析当前 SQL 执行计划,过程
执行下面语句进行分析
mysql> explain select tbcrbtnumb0_.id as id41_, tbcrbtnumb0_.business_ring_id as business2_41_, tbcrbtnumb0_.application_no as applicat3_41_, tbcrbtnumb0_.mobile as mobile41_ from tb_crbt_numbers_load tbcrbtnumb0_ where 1=1 and tbcrbtnumb0_.business_ring_id=11024;
+----+-------------+--------------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | tbcrbtnumb0_ | ALL | NULL | NULL | NULL | NULL |180182 | Using where |
+----+-------------+--------------+------+---------------+------+---------+------+--------+-------------+
1 row in set (0.00 sec)
当前语法执行的是全表扫描,另外,需要从 180182 行中扫描相关结果
SQL 分析二, 判断第一次执行该 SQL 时候的执行过程
mysql> set profiling=1;
mysql> select tbcrbtnumb0_.id as id41_, tbcrbtnumb0_.business_ring_id as business2_41_, tbcrbtnumb0_.application_no as applicat3_41_, tbcrbtnumb0_.mobile as mobile41_ from tb_crbt_numbers_load tbcrbtnumb0_ where 1=1 and tbcrbtnumb0_.business_ring_id=11024;
+-------+---------------+---------------+-------------+
| id41_ | business2_41_ | applicat3_41_ | mobile41_ |
+-------+---------------+---------------+-------------+
| 30838 | 11024 | TH20121127229 | 02038688592 |
+-------+---------------+---------------+-------------+
1 row in set (0.30 sec)
mysql> show profile; +--------------------------------+----------+
| Status | Duration |
+--------------------------------+----------+
| starting | 0.000191 |
| Waiting for query cache lock | 0.000023 |
| init | 0.000090 |
| checking query cache for query | 0.000499 |
| checking permissions | 0.000030 |
| Opening tables | 0.000131 |
| init | 0.000277 |
| System lock | 0.000042 |
| Waiting for query cache lock | 0.000005 |
| System lock | 0.000443 |
| optimizing | 0.000364 |
| statistics | 0.000107 |
| preparing | 0.000059 |
| executing | 0.000019 |
| Sending data | 0.290067 |
| end | 0.000483 |
| query end | 0.000169 |
| closing tables | 0.000158 |
| freeing items | 0.000252 |
| Waiting for query cache lock | 0.000063 |
| freeing items | 0.000305 |
| Waiting for query cache lock | 0.000015 |
| freeing items | 0.000095 |
| storing result in query cache | 0.000145 |
| cleaning up | 0.000330 |
+--------------------------------+----------+
25 rows in set, 1 warning (0.01 sec)
从上面看出, 第一次执行该 SQL, MySQL 需要对 SQL 进行锁缓存,初始化,从缓存中查询是否具备之前缓存过的 SQL,检查用户权限, 表权限,打开表,锁定内存,定制执行计划,执行语句,把数据从磁盘中放入内存中操作,关闭表,锁定数据, 缓存数据等操作, 工作原理与 ORACLE 类似
按照 QUERY CACHE 原则, 假如 SQL 语句改变 (tbcrbtnumb0_.business_ring_id=11024) 替换该变量值, 那么该 SQL 会被看作为一个新的 SQL, 这个时候, MySQL 将会对整个 SQL 做一次全新的操作, 如上(黄线标注描述)
分析 SQL 三
mysql> select tbcrbtnumb0_.id as id41_, tbcrbtnumb0_.business_ring_id as business2_41_, tbcrbtnumb0_.application_no as applicat3_41_, tbcrbtnumb0_.mobile as mobile41_ from tb_crbt_numbers_load tbcrbtnumb0_ where 1=1 and tbcrbtnumb0_.business_ring_id=11021;
+-------+---------------+---------------+-------------+
| id41_ | business2_41_ | applicat3_41_ | mobile41_ |
+-------+---------------+---------------+-------------+
| 30835 | 11021 | TH20121127259 | 02038688592 |
+-------+---------------+---------------+-------------+
1 row in set (0.34 sec)
mysql> show profile;
+--------------------------------+----------+
| Status | Duration |
+--------------------------------+----------+
| starting | 0.000795 |
| Waiting for query cache lock | 0.000077 |
| init | 0.000045 |
| checking query cache for query | 0.000337 |
| checking permissions | 0.000040 |
| Opening tables | 0.000113 |
| init | 0.000488 |
| System lock | 0.000050 |
| Waiting for query cache lock | 0.000030 |
| System lock | 0.000289 |
| optimizing | 0.000512 |
| statistics | 0.000278 |
| preparing | 0.000078 |
| executing | 0.000028 |
| Sending data | 0.322662 |
| end | 0.004777 |
| query end | 0.001703 |
| closing tables | 0.000526 |
| freeing items | 0.000874 |
| Waiting for query cache lock | 0.000311 |
| freeing items | 0.001809 |
| Waiting for query cache lock | 0.000105 |
| freeing items | 0.000184 |
| storing result in query cache | 0.000966 |
| cleaning up | 0.000678 |
+--------------------------------+----------+
25 rows in set, 1 warning (0.00 sec)
上 SQL二,三结果可以看到, 当 WHERE 条件改变, MySQL 会把这两个 SQL 识别为一个新的 SQL, 需要重新操作。
SQL 分析四, 假如我们重新执行 SQL 三操作,看看结果如何?(注意,这个时候 QUERY CACHE 真正发挥作用)
mysql> select tbcrbtnumb0_.id as id41_, tbcrbtnumb0_.business_ring_id as business2_41_, tbcrbtnumb0_.application_no as applicat3_41_, tbcrbtnumb0_.mobile as mobile41_ from tb_crbt_numbers_load tbcrbtnumb0_ where 1=1 and tbcrbtnumb0_.business_ring_id=11021;
+-------+---------------+---------------+-------------+
| id41_ | business2_41_ | applicat3_41_ | mobile41_ |
+-------+---------------+---------------+-------------+
| 30835 | 11021 | TH20121127259 | 02038688592 |
+-------+---------------+---------------+-------------+
1 row in set (0.00 sec)
mysql> show profile; +--------------------------------+----------+
| Status | Duration |
+--------------------------------+----------+
| starting | 0.001367 |
| Waiting for query cache lock | 0.000071 |
| init | 0.000027 |
| checking query cache for query | 0.000163 |
| checking privileges on cached | 0.000129 |
| checking permissions | 0.000386 |
| sending cached result to clien | 0.000164|
| cleaning up | 0.000079 |
+--------------------------------+----------+
8 rows in set, 1 warning (0.01 sec)
参考 SQL 分析三,四,数据查询需要使用的时间(绿色标注部分)很明显, SQL 分析四返回速度块了很多,另外,从系统返回的 SQL 分析看出来,系统直接从缓存中返回数据给客户, 没有重复进行 SQL 分析及磁盘 I/O 操作。(蓝色标注部分) 因此, QEURY CACHE 明显加速了 SQL 返回结果。
但必须注意,只有两个 SQL 相同的情况下,才能够获得 QUERY CACHE 的优点。
参数化查询
参数化查询能够在一定情况下避免了 SQL 注入, 而 ORACLE 也比较推荐使用参数化查询, ORACLE 每次执行 SQL (无论 SQL 是否语法一致)都存在 SQL 分析,
假如SQL语法不一样,则进行硬解析,需要重新定制执行计划
假如SQL语法不一致则进行软解析,避免重复定制执行计划,减少 CPU 消耗,增加 SQL 语句返回时间。
MySQL 官方文档中并没有提出到这点。
对 MySQL 进行参数化查询分析
SQL 参数化分析一
mysql> set @num=11204;
mysql> select tbcrbtnumb0_.id as id41_, tbcrbtnumb0_.business_ring_id as business2_41_, tbcrbtnumb0_.application_no as applicat3_41_, tbcrbtnumb0_.mobile as mobile41_ from tb_crbt_numbers_load tbcrbtnumb0_ where 1=1 and tbcrbtnumb0_.business_ring_id=@num;
+-------+---------------+---------------+-----------+
| id41_ | business2_41_ | applicat3_41_ | mobile41_ |
+-------+---------------+---------------+-----------+
| 31051 | 11204 | 1222570 | 85237810 |
| 31052 | 11204 | 1222570 | 82685386 |
| 31053 | 11204 | 1222570 | 82783689 |
| 31054 | 11204 | 1222570 | 82685106 |
| 31055 | 11204 | 1222570 | 38880051 |
+-------+---------------+---------------+-----------+
5 rows in set (0.37 sec)
mysql> show profile; +--------------------------------+----------+
| Status | Duration |
+--------------------------------+----------+
| starting | 0.001858 |
| Waiting for query cache lock | 0.000089 |
| init | 0.000150 |
| checking query cache for query | 0.001143 |
| checking permissions | 0.000970 |
| Opening tables | 0.000544 |
| init | 0.000743 |
| System lock | 0.000170 |
| optimizing | 0.000332 |
| statistics | 0.000293 |
| preparing | 0.000134 |
| executing | 0.000057 |
| Sending data | 0.438626 |
| end | 0.000694 |
| query end | 0.000221 |
| closing tables | 0.000300 |
| freeing items | 0.000521 |
| cleaning up | 0.000360 |
+--------------------------------+----------+
18 rows in set, 1 warning (0.01 sec)
变量值不变情况下,重复执行该 SQL 语句
mysql> select tbcrbtnumb0_.id as id41_, tbcrbtnumb0_.business_ring_id as business2_41_, tbcrbtnumb0_.application_no as applicat3_41_, tbcrbtnumb0_.mobile as mobile41_ from tb_crbt_numbers_load tbcrbtnumb0_ where 1=1 and tbcrbtnumb0_.business_ring_id=@num;
+-------+---------------+---------------+-----------+
| id41_ | business2_41_ | applicat3_41_ | mobile41_ |
+-------+---------------+---------------+-----------+
| 31051 | 11204 | 1222570 | 85237810 |
| 31052 | 11204 | 1222570 | 82685386 |
| 31053 | 11204 | 1222570 | 82783689 |
| 31054 | 11204 | 1222570 | 82685106 |
| 31055 | 11204 | 1222570 | 38880051 |
+-------+---------------+---------------+-----------+
5 rows in set (0.34 sec)
mysql> show profile; +--------------------------------+----------+
| Status | Duration |
+--------------------------------+----------+
| starting | 0.001188 |
| Waiting for query cache lock | 0.000052 |
| init | 0.000030 |
| checking query cache for query | 0.001791 |
| checking permissions | 0.000172 |
| Opening tables | 0.000614 |
| init | 0.001346 |
| System lock | 0.000268 |
| optimizing | 0.000626 |
| statistics | 0.000674 |
| preparing | 0.000439 |
| executing | 0.000028 |
| Sending data | 0.327278 |
| end | 0.000649 |
| query end | 0.000217 |
| closing tables | 0.000408 |
| freeing items | 0.000692 |
| cleaning up | 0.000570 |
+--------------------------------+----------+
18 rows in set, 1 warning (0.01 sec)
分析结果
从数据返回时间上看来(蓝色标注), 使用参数化查询,并没有在时间返回上获得优势。
从SQL执行计划上看来(紫色标注), 相同 SQL 语句使用参数化查询,系统同样会重新定制执行计划,产生磁盘I/O, 并没有想 ORACLE 一样获得性能上的优化。
另外,参数化查询是不会在 query cache 内存块中取结果的。
可以看做每次使用参数化查询都会被认为是一个全新的 SQL 进行分析, (没有学习到 ORACLE 的精髓,比较失望)
注意,使用参数化查询时, 即时使用 SQL_cache 语法, 也无法使用 query cache 功能。
常见开发下有几种选择
1. 直接把 SQL 变量值提交至 MySQL API 执行,(可利用 QUERY CACHE 功能,有部分 SQL 能够进行数据加速)但可能会遇到 SQL 注入, 升级程序麻烦。
2. 利用 procudure, function 等功能先吧 SQL 进行打包然后再调用执行, 类似参数化查询, 无法获得 QUERY CACHE 功能, 令程序清晰, 程序升级,修改比较方便, 并且有效防止了 SQL 注入。
http://www.jb51.net/article/30003.htm
对于mysql的query_cache认识的误区
下面我们通过实验及源码具体分析。首先,我们先试验一下:
首先,我们看一下mysql query_cache的状态:

首先,我们可以确认,mysql的query_cache功能是打开的。
其次,我们看一下状态:

因为这个db是新的db,所以hits,inset都为0,现在我们执行一条select语句:
状态变为:

可以看到,执行一条select后,现在的qcache状态为,insert+1,这样我们就可以推断出,现在刚才那条select语句已经加入了qcache中。那我们现在再将刚才那条sql前面加上空格,看看会怎样呢?

请注意,这条sql,比刚才那条sql前面多了一个空格。
按照网上的理论,这条sql应该会作为另一个键而插入另一个cache,不会复用先前的cache,但结果呢?

我们可以看到,hits变为了1,而inserts根本没变,这就说明了,这条在前面加了空格的query命中了没有空格的query的结果集。从这,我们就可以得出结论,网上先前流传的说法,是不严谨的。
那究竟是怎么回事呢?到底应该如何呢?为什么前面有空格的会命中了没有空格的query的结果集。其实,这些我们可以通过源码获得答案。
翻看下mysql的源码,我这翻看的是5.1的,在send_result_to_client(这个函数既是mysql调用query_cache的函数)这个函数里面有这样一段,这段代码,、
/*
Test if the query is a SELECT
(pre-space is removed in dispatch_command).
First '/' looks like comment before command it is not
frequently appeared in real life, consequently we can
check all such queries, too.
*/
if ((my_toupper(system_charset_info, sql[i]) != 'S' ||
my_toupper(system_charset_info, sql[i + 1]) != 'E' ||
my_toupper(system_charset_info, sql[i + 2]) != 'L') &&
sql[i] != '/')
{
DBUG_PRINT("qcache", ("The statement is not a SELECT; Not cached"));
goto err;
}
是在检验语句是否为select语句,重点是上面那段注释。特别是括弧中的,pre-space is removed in dispatch_command,也就是说,在语句开始之前的多余的空格已经被处理过了,在dispache_command这个函数中去掉了。
我们看下dispache_command这个方法,在这个方法里有这样一段:
if (alloc_query(thd, packet, packet_length))
break; // fatal error is set
char *packet_end= thd->query() + thd->query_length();
/* 'b' stands for 'buffer' parameter', special for 'my_snprintf' */
const char* end_of_stmt= NULL;
在这里,会调用alloc_query方法,我们看下这个方法的内容:
bool alloc_query(THD *thd, const char *packet, uint packet_length)
{
char *query;
/* Remove garbage at start and end of query */
while (packet_length > 0 && my_isspace(thd->charset(), packet[0]))
{
packet++;
packet_length--;
}
const char *pos= packet + packet_length; // Point at end null
while (packet_length > 0 &&
(pos[-1] == ';' || my_isspace(thd->charset() ,pos[-1])))
{
pos--;
packet_length--;
}
/* We must allocate some extra memory for query cache
The query buffer layout is:
buffer :==
<statement> The input statement(s)
'\0' Terminating null char (1 byte)
<length> Length of following current database name (size_t)
<db_name> Name of current database
<flags> Flags struct
*/
if (! (query= (char*) thd->memdup_w_gap(packet,
packet_length,
1 + sizeof(size_t) + thd->db_length +
QUERY_CACHE_FLAGS_SIZE)))
return TRUE;
query[packet_length]= '\0';
/*
Space to hold the name of the current database is allocated. We
also store this length, in case current database is changed during
execution. We might need to reallocate the 'query' buffer
*/
char *len_pos = (query + packet_length + 1);
memcpy(len_pos, (char *) &thd->db_length, sizeof(size_t));
thd->set_query(query, packet_length);
/* Reclaim some memory */
thd->packet.shrink(thd->variables.net_buffer_length);
thd->convert_buffer.shrink(thd->variables.net_buffer_length);
return FALSE;
}
这个方法在一开始就会对query进行处理(代码第4行),将开头和末尾的garbage remove掉。
看到这里,我们基本已经明了了,mysql会对输入的query进行预处理,将空格等东西给处理掉,所以不会开头的空格不会影响到query_cache,因为对mysql来说,就是一条query。
sql_no_cache意思是查询的时候不缓存查询结果。
sql_buffer_result意思是说,在查询语句中,将查询结果缓存到临时表中。
这三者正好配套使用。sql_buffer_result将尽快释放表锁,这样其他sql就能够尽快执行。
使用 FLUSH QUERY CACHE 命令,你可以整理查询缓存,以更好的利用它的内存。这个命令不会从缓存中移除任何查询。FLUSH TABLES 会转储清除查询缓存。
RESET QUERY CACHE 使命从查询缓存中移除所有的查询结果。
--------------------------------------------------
那么mysql到底是怎么决定到底要不要把查询结果放到查询缓存中呢?
是根据query_cache_type这个变量来决定的。
这个变量有三个取值:0,1,2,分别代表了off、on、demand。
mysql默认为开启 on
意思是说,如果是0,那么query cache 是关闭的。
如果是1,那么查询总是先到查询缓存中查找,即使使用了sql_no_cache仍然查询缓存,因为sql_no_cache只是不缓存查询结果,而不是不使用查询结果。
select count(*) from innodb;
1 row in set (1.91 sec)
select sql_no_cache count(*) from innodb;
1 row in set (0.25 sec)
如果是2,DEMAND。
在my.ini中增加一行
query_cache_type=2
重启mysql服务
select count(*) from innodb;
1 row in set (1.56 sec)
select count(*) from innodb;
1 row in set (0.28 sec)
没有使用sql_cache,好像仍然使用了查询缓存
select sql_cache count(*) from innodb;
1 row in set (0.28 sec)
使用sql_cache查询时间也一样,因为sql_cache只是将查询结果放入缓存,没有使用sql_cache查询也会先到查询缓存中查找数据
结论:只要query_cache_type没有关闭,sql查询总是会使用查询缓存,如果缓存没有命中则开始查询的执行计划到表中查询数据。
| 分类: PHP |
MySQL query cache从4.1版本开始提供了,不过值今天本人才对其进行研究。默认配置下,MySQL的该功能是没有启动的,可能你通过show variables like ‘%query_cache%’;会发现其变量have_query_cache的值是yes,MYSQL初学者很容易以为这个参数为YES就代表开启了 查询缓存,实际上是不对的,该参数表示当前版本的MYSQL是否支持Query Cache,实际上是否开启查询缓存是看另外一个参数的值:query_cache_size ,该值为0,表示禁用query cache,而默认配置正是配置为0。
配置方法:
在MYSQL的配置文件my.ini或my.cnf中找到如下内容:
# Query cache is used to cache SELECT results and later return them
# without actual executing the same query once again. Having the query
# cache enabled may result in significant speed improvements, if your
# have a lot of identical queries and rarely changing tables. See the
# “Qcache_lowmem_prunes” status variable to check if the current value
# is high enough for your load.
# Note: In case your tables change very often or if your queries are
# textually different every time, the query cache may result in a
# slowdown instead of a performance improvement.
query_cache_size=0
以 上信息是默认配置,其注释意思是说,MYSQL的查询缓存用于缓存select查询结果,并在下次接收到同样的查询请求时,不再执行实际查询处理而直接返 回结果,有这样的查询缓存能提高查询的速度,使查询性能得到优化,前提条件是你有大量的相同或相似的查询,而很少改变表里的数据,否则没有必要使用此功 能。可以通过Qcache_lowmem_prunes变量的值来检查是否当前的值满足你目前系统的负载。注意:如果你查询的表更新比较频繁,而且很少有 相同的查询,最好不要使用查询缓存。
具体配置方法:
1. 将query_cache_size设置为具体的大小,具体大小是多少取决于查询的实际情况,但最好设置为1024的倍数,参考值32M。
2. 增加一行:query_cache_type=1
query_cache_type参数用于控制缓存的类型,注意这个值不能随便设置,必须设置为数字,可选项目以及说明如下:

如果设置为0,那么可以说,你的缓存根本就没有用,相当于禁用了。但是这种情况下query_cache_size设置的大小系统是否要为其分配呢,这个问题有待于测试?
如果设置为1,将会缓存所有的结果,除非你的select语句使用SQL_NO_CACHE禁用了查询缓存。
如果设置为2,则只缓存在select语句中通过SQL_CACHE指定需要缓存的查询。
OK,配置完后的部分文件如下:
query_cache_size=128M
query_cache_type=1
保存文件,重新启动MYSQL服务,然后通过如下查询来验证是否真正开启了:
mysql> show variables like ‘%query_cache%’;
+——————————+———–+
| Variable_name | Value |
+——————————+———–+
| have_query_cache | YES |
| query_cache_limit | 1048576 |
| query_cache_min_res_unit | 4096 |
| query_cache_size | 134217728 |
| query_cache_type | ON |
| query_cache_wlock_invalidate | OFF |
+——————————+———–+
6 rows in set (0.00 sec)
主要看query_cache_size和query_cache_type的值是否跟我们设的一致:
这里query_cache_size的值是134217728,我们设置的是128M,实际是一样的,只是单位不同,可以自己换算下:134217728 = 128*1024*1024。
query_cache_type设置为1,显示为ON,这个前面已经说过了。
总之,看到上边的显示表示设置正确,但是在实际的查询中是否能够缓存查询,还需要手动测试下,我们可以通过show status like ‘%Qcache%’;语句来测试,现在我们开启了查询缓存功能,在执行查询前,我们先看看相关参数的值:
mysql> show status like ‘%Qcache%’;
+————————-+———–+
| Variable_name | Value |
+————————-+———–+
| Qcache_free_blocks | 1 |
| Qcache_free_memory | 134208800 |
| Qcache_hits | 0 |
| Qcache_inserts | 0 |
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 2 |
| Qcache_queries_in_cache | 0 |
| Qcache_total_blocks | 1 |
+————————-+———–+
8 rows in set (0.00 sec)
这里顺便解释下这个几个参数的作用:
Qcache_free_blocks:表示查询缓存中目前还有多少剩余的blocks,如果该值显示较大,则说明查询缓存中的内存碎片过多了,可能在一定的时间进行整理。
Qcache_free_memory:查询缓存的内存大小,通过这个参数可以很清晰的知道当前系统的查询内存是否够用,是多了,还是不够用,DBA可以根据实际情况做出调整。
Qcache_hits:表示有多少次命中缓存。我们主要可以通过该值来验证我们的查询缓存的效果。数字越大,缓存效果越理想。
Qcache_inserts: 表示多少次未命中然后插入,意思是新来的SQL请求在缓存中未找到,不得不执行查询处理,执行查询处理后把结果insert到查询缓存中。这样的情况的次 数,次数越多,表示查询缓存应用到的比较少,效果也就不理想。当然系统刚启动后,查询缓存是空的,这很正常。
Qcache_lowmem_prunes:该参数记录有多少条查询因为内存不足而被移除出查询缓存。通过这个值,用户可以适当的调整缓存大小。
Qcache_not_cached: 表示因为query_cache_type的设置而没有被缓存的查询数量。
Qcache_queries_in_cache:当前缓存中缓存的查询数量。
Qcache_total_blocks:当前缓存的block数量。
下边我们测试下:
比如执行如下查询语句
mysql> select * from user where id = 2;
+—-+——-+
| id | name |
+—-+——-+
| 2 | test2 |
+—-+——-+
1 row in set (0.02 sec)
然后执行show status like ‘%Qcache%’,看看有什么变化:
mysql> show status like ‘%Qcache%’;
+————————-+———–+
| Variable_name | Value |
+————————-+———–+
| Qcache_free_blocks | 1 |
| Qcache_free_memory | 134207264 |
| Qcache_hits | 0 |
| Qcache_inserts | 1 |
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 3 |
| Qcache_queries_in_cache | 1 |
| Qcache_total_blocks | 4 |
+————————-+———–+
8 rows in set (0.00 sec)
对比前面的参数值,我们发现Qcache_inserts变化了。Qcache_hits没有变,下边我们在执行同样的查询
select * from user where id = 2,按照前面的理论分析:Qcache_hits应该等于1,而Qcache_inserts应该值不变(其他参数的值变化暂时不关注,读者可以自行测试),再次执行:
show status like ‘%Qcache%’,看看有什么变化:
mysql> show status like ‘%Qcache%’;
+————————-+———–+
| Variable_name | Value |
+————————-+———–+
| Qcache_free_blocks | 1 |
| Qcache_free_memory | 134207264 |
| Qcache_hits | 1 |
| Qcache_inserts | 1 |
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 4 |
| Qcache_queries_in_cache | 1 |
| Qcache_total_blocks | 4 |
+————————-+———–+
8 rows in set (0.00 sec)
OK,果然跟我们分析的完全一致。
...............
